Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
I den här självstudien bygger du vidare på arbete av en Power BI-analytiker som lagras som semantiska modeller (Power BI-datauppsättningar). Genom att använda SemPy (förhandsversion) i Synapse Data Science-upplevelsen i Microsoft Fabric analyserar du funktionella beroenden i DataFrame-kolumner. Den här analysen hjälper dig att identifiera subtila datakvalitetsproblem för att få mer exakta insikter.
I den här handledningen lär du dig hur du:
- Använd domänkunskap för att formulera hypoteser om funktionella beroenden i en semantisk modell.
- Bekanta dig med komponenter i Semantic Links Python-bibliotek (SemPy) som integreras med Power BI och hjälper till att automatisera datakvalitetsanalys. Dessa komponenter omfattar:
- FabricDataFrame – Pandas-liknande struktur utökad med ytterligare semantisk information
- Funktioner som hämtar semantiska modeller från en Infrastruktur-arbetsyta till din notebook-fil
- Funktioner som utvärderar funktionella beroendehypoteser och identifierar relationsöverträdelser i dina semantiska modeller
Förutsättningar
Skaffa en Microsoft Fabric-prenumeration. Eller registrera dig för en kostnadsfri Microsoft Fabric-utvärderingsversion.
Logga in på Microsoft Fabric.
Växla till Fabric genom att använda upplevelseväxlaren längst ned till vänster på startsidan.

Välj Arbetsytor i navigeringsfönstret för att hitta och välja din arbetsyta. Den här arbetsytan blir din aktuella arbetsyta.
Ladda ned filen Customer Profitability Sample.pbix från GitHub-lagringsplatsen fabric-samples.
På arbetsytan väljer du Importera>rapport eller paginerad rapport>från den här datorn för att ladda upp filen Customer Profitability Sample.pbix till din arbetsyta.
Följ med i anteckningsboken
Den powerbi_dependencies_tutorial.ipynb notebook-filen medföljer denna självstudie.
För att öppna den medföljande notebooken för den här självstudien, följ anvisningarna i Förbered ditt system för självstudier inom datavetenskapen för att importera notebooken till din arbetsyta.
Om du hellre kopierar och klistrar in koden från den här sidan kan du skapa en ny notebook-fil.
Se till att ansluta en lakehouse till notebooken innan du börjar köra kod.
Konfigurera anteckningsboken
Konfigurera en notebook-miljö med de moduler och data du behöver.
Använd
%pipför att installera SemPy från PyPI i notebook-filen.%pip install semantic-linkImportera de moduler du behöver.
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
Läsa in och förbearbeta data
I den här självstudien används en standardexempel på en semantisk modell av Customer Profitability Sample.pbix. En beskrivning av semantikmodellen finns i exempel på kundlönsamhet för Power BI-.
Läs in Power BI-data i en
FabricDataFramemed hjälpfabric.read_tableav funktionen .dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()Läs in tabellen
Statei enFabricDataFrame.state = fabric.read_table(dataset, "State") state.head()Även om utdata ser ut som en Pandas DataFrame initierar den här koden en datastruktur som kallas för en
FabricDataFramesom lägger till åtgärder ovanpå Pandas.Kontrollera datatypen
customerför .type(customer)Utdata visar att
customerärsempy.fabric._dataframe._fabric_dataframe.FabricDataFrame.Koppla objekten
customerochstateDataFrame.customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
Identifiera funktionella beroenden
Ett funktionellt beroende är en en-till-många-relation mellan värden i två eller flera kolumner i en DataFrame. Använd dessa relationer för att automatiskt identifiera datakvalitetsproblem.
Kör SemPys
find_dependenciesfunktion på den sammanfogadeDataFrameför att identifiera funktionella beroenden mellan kolumnvärden.dependencies = customer_state_df.find_dependencies() dependenciesVisualisera beroendena med hjälp av SemPys
plot_dependency_metadatafunktion.plot_dependency_metadata(dependencies)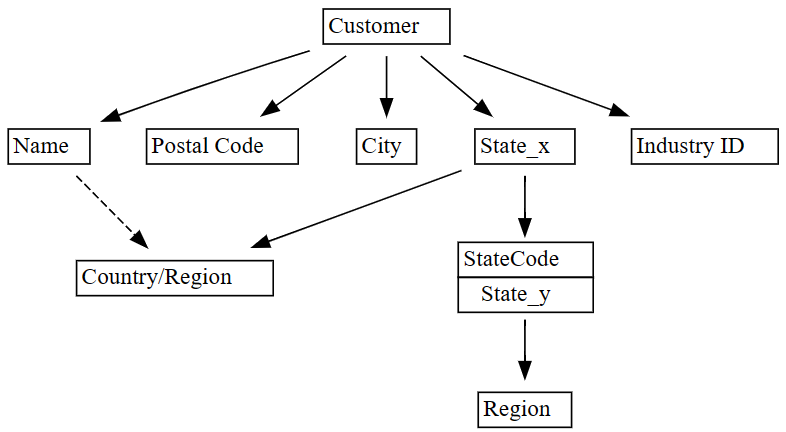
Diagrammet funktionella beroenden visar att
Customerkolumnen bestämmer kolumner somCity,Postal CodeochName.Diagrammet visar inte något funktionellt beroende mellan
CityochPostal Code, sannolikt eftersom det finns många överträdelser i relationen mellan kolumnerna. Använd SemPysplot_dependency_violationsfunktion för att visualisera beroendeöverträdelser mellan specifika kolumner.

Utforska data för kvalitetsproblem
Rita ett diagram med SemPys
plot_dependency_violationsvisualiseringsfunktion.customer_state_df.plot_dependency_violations('Postal Code', 'City')
Diagrammet över beroendeöverträdelser visar värden för
Postal Codetill vänster och värden förCitypå höger sida. En kant ansluter enPostal Codetill vänster med enCitytill höger om det finns en rad som innehåller dessa två värden. Kanterna kommenteras med antalet sådana rader. Det finns till exempel två rader med postnummer 20004, en med staden "North Tower" och den andra med staden "Washington".Diagrammet visar också några överträdelser och många tomma värden.
Bekräfta antalet tomma värden för
Postal Code:customer_state_df['Postal Code'].isna().sum()50 rader har NA för
Postal Code.Släpp rader med tomma värden. Leta sedan reda på beroenden med hjälp av funktionen
find_dependencies. Observera den extra parameternverbose=1som ger en inblick i det interna arbetet i SemPy:customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)Villkorsstyrd entropi för
Postal CodeochCityär 0,049. Det här värdet anger att det finns funktionella beroendeöverträdelser. Innan du åtgärdar överträdelserna höjer du tröskelvärdet för villkorsstyrd entropi från standardvärdet för0.01till0.05, bara för att se beroendena. Lägre tröskelvärden resulterar i färre beroenden (eller högre selektivitet).Höj tröskelvärdet för villkorsstyrd entropi från standardvärdet för
0.01till0.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))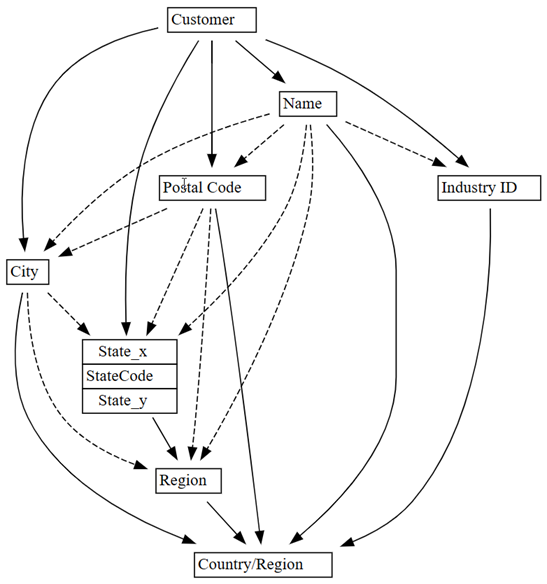
Om du använder domänkunskap om vilken entitet som avgör värdena för andra entiteter verkar det här beroendediagrammet vara korrekt.
Utforska fler problem med datakvalitet som har identifierats. En streckad pil kopplar till exempel
CityochRegion, vilket indikerar att beroendet bara är ungefärligt. Den här ungefärliga relationen kan innebära att det finns ett partiellt funktionellt beroende.customer_state_df.list_dependency_violations('City', 'Region')Ta en närmare titt på varje fall där ett icke-tomt
Region-värde orsakar en överträdelse.customer_state_df[customer_state_df.City=='Downers Grove']Resultatet visar staden Downers Grove i Illinois och Nebraska. Downers Grove är dock en stad i Illinois, inte Nebraska.
Ta en titt på staden Fremont:
customer_state_df[customer_state_df.City=='Fremont']Det finns en stad som heter Fremont i Kalifornien. Men för Texas returnerar sökmotorn Premont, inte Fremont.
Det är också suspekt med överträdelser av beroendet mellan
NameochCountry/Region, vilket framgår av den streckade linjen i den ursprungliga grafen över beroendeöverträdelser (innan rader med tomma värden tas bort).customer_state_df.list_dependency_violations('Name', 'Country/Region')En kund, SDI Design, visas i två regioner – USA och Kanada. Det här fallet kanske inte är en semantisk överträdelse, bara ovanligt. Ändå är det värt en närmare titt:
Ta en närmare titt på kundens SDI Design:
customer_state_df[customer_state_df.Name=='SDI Design']Ytterligare inspektion visar två olika kunder från olika branscher med samma namn.

Undersökande dataanalys och datarensning är iterativa. Vad du hittar beror på dina frågor och perspektiv. Semantic Link ger dig nya verktyg för att få ut mer av dina data.
Relaterat innehåll
Kolla in andra självstudier för semantisk länk och SemPy:
- Självstudie: Rensa data med funktionella beroenden
- Självstudie: Extrahera och beräkna Power BI-mått från en Jupyter Notebook-
- Självstudie: Identifiera relationer i en semantisk modell med hjälp av semantisk länk
- Självstudie: Identifiera relationer i Synthea-datauppsättningen med hjälp av semantisk länk
- Självstudie: Verifiera data med SemPy och Great Expectations (GX)