Migrering: Dedikerade SQL-pooler i Azure Synapse Analytics till Fabric
Gäller för: ![]() Warehouse i Microsoft Fabric
Warehouse i Microsoft Fabric
Den här artikeln beskriver strategi, överväganden och metoder för migrering av datalager i dedikerade SQL-pooler i Azure Synapse Analytics till Microsoft Fabric Warehouse.
Introduktion till migrering
Som Microsoft introducerade Microsoft Fabric, en allt-i-ett SaaS-analyslösning för företag som erbjuder en omfattande uppsättning tjänster, inklusive Data Factory, Data Engineering, Data Warehousing, Data Science, Realtidsinformation och Power BI.
Den här artikeln fokuserar på alternativ för schemamigrering (DDL), databaskodmigrering (DML) och datamigrering. Microsoft erbjuder flera alternativ, och här diskuterar vi varje alternativ i detalj och ger vägledning om vilka av dessa alternativ du bör överväga för ditt scenario. I den här artikeln används TPC-DS-branschriktmärket för bild- och prestandatestning. Ditt faktiska resultat kan variera beroende på många faktorer, till exempel typ av data, datatyper, bredd på tabeller, svarstid för datakällor osv.
Förbereda för migrering
Planera migreringsprojektet noggrant innan du kommer igång och se till att ditt schema, din kod och dina data är kompatibla med Fabric Warehouse. Det finns vissa begränsningar som du behöver tänka på. Kvantifiera refaktoriseringsarbetet för de inkompatibla objekten samt andra resurser som behövs före migreringsleveransen.
Ett annat viktigt mål med planering är att justera din design för att säkerställa att din lösning drar full nytta av de höga frågeprestanda som Fabric Warehouse är utformat för att tillhandahålla. Design av informationslager för skalning introducerar unika designmönster, så traditionella metoder är inte alltid de bästa. Granska riktlinjerna för infrastrukturlagerprestanda, eftersom vissa designjusteringar kan göras efter migreringen, men om du gör ändringar tidigare i processen sparar du tid och arbete. Migrering från en teknik/miljö till en annan är alltid ett stort arbete.
Följande diagram visar migreringslivscykeln som visar de viktigaste pelarna som består av utvärdera och utvärdera, planera och utforma, migrera, övervaka och styra, optimera och modernisera pelare med associerade uppgifter i varje pelare för att planera och förbereda för smidig migrering.

Runbook för migrering
Tänk på följande aktiviteter som en planeringsrunbook för migreringen från Synapse-dedikerade SQL-pooler till Fabric Warehouse.
- Utvärdera och utvärdera
- Identifiera mål och motivationer. Upprätta tydliga önskade resultat.
- Identifiera, utvärdera och baslinje för den befintliga arkitekturen.
- Identifiera viktiga intressenter och sponsorer.
- Definiera omfånget för vad som ska migreras.
- Starta små och enkla, förbered dig för flera små migreringar.
- Börja övervaka och dokumentera alla faser i processen.
- Skapa en inventering av data och processer för migrering.
- Definiera ändringar i datamodellen (om det finns några).
- Konfigurera arbetsytan Infrastruktur.
- Vad är din kompetensuppsättning/inställning?
- Automatisera när det är möjligt.
- Använd inbyggda Azure-verktyg och funktioner för att minska migreringsarbetet.
- Utbilda personalen tidigt på den nya plattformen.
- Identifiera kompetensbehov och utbildningstillgångar, inklusive Microsoft Learn.
- Planera och utforma
- Definiera önskad arkitektur.
- Välj metoden /verktygen för migreringen för att utföra följande uppgifter:
- Dataextrahering från källan.
- Schemakonvertering (DDL), inklusive metadata för tabeller och vyer
- Datainmatning, inklusive historiska data.
- Om det behövs kan du återskapa datamodellen med hjälp av nya plattformsprestanda och skalbarhet.
- Migrering av databaskod (DML).
- Migrera eller omstrukturera lagrade procedurer och affärsprocesser.
- Inventera och extrahera säkerhetsfunktioner och objektbehörigheter från källan.
- Utforma och planera att ersätta/ändra befintliga ETL/ELT-processer för inkrementell belastning.
- Skapa parallella ETL/ELT-processer till den nya miljön.
- Förbered en detaljerad migreringsplan.
- Mappa aktuellt tillstånd till nytt önskat tillstånd.
- Migrera
- Utför schema, data, kodmigrering.
- Dataextrahering från källan.
- Schemakonvertering (DDL)
- Datainmatning
- Migrering av databaskod (DML).
- Om det behövs skalar du upp de dedikerade SQL-poolresurserna tillfälligt för att underlätta migreringens hastighet.
- Tillämpa säkerhet och behörigheter.
- Migrera befintliga ETL/ELT-processer för inkrementell belastning.
- Migrera eller omstrukturera inkrementella inläsningsprocesser för ETL/ELT.
- Testa och jämföra parallella inkrementella inläsningsprocesser.
- Anpassa detaljmigreringsplanen efter behov.
- Utför schema, data, kodmigrering.
- Övervaka och styra
- Kör parallellt, jämför med källmiljön.
- Testa program, business intelligence-plattformar och frågeverktyg.
- Prestandatesta och optimera frågeprestanda.
- Övervaka och hantera kostnader, säkerhet och prestanda.
- Styrningsmått och utvärdering.
- Kör parallellt, jämför med källmiljön.
- Optimera och modernisera
- När verksamheten är bekväm kan du överföra program och primära rapporteringsplattformar till Infrastrukturresurser.
- Skala upp/ned resurser när arbetsbelastningen flyttas från Azure Synapse Analytics till Microsoft Fabric.
- Skapa en repeterbar mall från upplevelsen för framtida migreringar. Iterera.
- Identifiera möjligheter till kostnadsoptimering, säkerhet, skalbarhet och driftskvalitet
- Identifiera möjligheter att modernisera din dataegendom med de senaste funktionerna i Infrastrukturresurser.
- När verksamheten är bekväm kan du överföra program och primära rapporteringsplattformar till Infrastrukturresurser.
"Lift and shift" eller modernisera?
I allmänhet finns det två typer av migreringsscenarier, oavsett syftet med och omfattningen av den planerade migreringen: lift and shift as-is, eller en stegvis metod som omfattar arkitektur- och kodändringar.
Lift and Shift
I en lift and shift-migrering migreras en befintlig datamodell med mindre ändringar i det nya infrastrukturlagret. Den här metoden minimerar risken och migreringstiden genom att minska det nya arbete som krävs för att utnyttja fördelarna med migreringen.
Lift and Shift-migrering passar bra för följande scenarier:
- Du har en befintlig miljö med ett litet antal data marts att migrera.
- Du har en befintlig miljö med data som redan finns i ett väldesignad star- eller snowflake-schema.
- Du är under tids- och kostnadstryck för att flytta till Infrastrukturlager.
Sammanfattningsvis fungerar den här metoden bra för de arbetsbelastningar som är optimerade med din aktuella Synapse-dedikerade SQL-poolmiljö och därför inte kräver större ändringar i Infrastrukturresurser.
Modernisera i en stegvis metod med arkitekturändringar
Om ett äldre informationslager har utvecklats under en lång tidsperiod kan du behöva återskapa det för att upprätthålla de prestandanivåer som krävs.
Du kanske också vill göra om arkitekturen för att dra nytta av de nya motorerna och funktionerna som är tillgängliga på arbetsytan Infrastruktur.
Designskillnader: Synapse-dedikerade SQL-pooler och Infrastrukturlager
Överväg följande skillnader i Azure Synapse- och Microsoft Fabric-informationslager och jämför dedikerade SQL-pooler med Fabric Warehouse.
Tabellöverväganden
När du migrerar tabeller mellan olika miljöer migreras vanligtvis endast rådata och metadata fysiskt. Andra databaselement från källsystemet, till exempel index, migreras vanligtvis inte eftersom de kan vara onödiga eller implementerade på olika sätt i den nya miljön.
Prestandaoptimeringar i källmiljön, till exempel index, anger var du kan lägga till prestandaoptimering i en ny miljö, men nu tar Fabric hand om det automatiskt åt dig.
T-SQL-överväganden
Det finns flera skillnader i DML-syntax (Data Manipulation Language) att känna till. Se T-SQL-ytan i Microsoft Fabric. Överväg även en kodutvärdering när du väljer metoder för migrering för databaskoden (DML).
Beroende på paritetsskillnaderna vid tidpunkten för migreringen kan du behöva skriva om delar av din T-SQL DML-kod.
Skillnader i datatypsmappning
Det finns flera skillnader mellan datatyper i Infrastrukturlager. Mer information finns i Datatyper i Microsoft Fabric.
Följande tabell innehåller mappning av datatyper som stöds från Synapse-dedikerade SQL-pooler till Fabric Warehouse.
| Synapse-dedikerade SQL-pooler | Infrastrukturlager |
|---|---|
| money | decimal(19,4) |
| smallmoney | decimal(10,4) |
| smalldatetime | datetime2 |
| datetime | datetime2 |
| nchar | char |
| nvarchar | varchar |
| tinyint | smallint |
| binary | varbinary |
| datetimeoffset* | datetime2 |
* Datetime2 lagrar inte den extra tidszonsförskjutningsinformation som lagras i. Eftersom datatypen datetimeoffset för närvarande inte stöds i Infrastrukturlager, måste tidszonens förskjutningsdata extraheras till en separat kolumn.
Schema-, kod- och datamigreringsmetoder
Granska och identifiera vilka av dessa alternativ som passar ditt scenario, personalens kompetensuppsättningar och egenskaperna för dina data. Vilka alternativ som väljs beror på din erfarenhet, dina preferenser och fördelarna med vart och ett av verktygen. Vårt mål är att fortsätta utveckla migreringsverktyg som minskar friktionen och manuella åtgärder för att göra migreringen smidig.
Den här tabellen sammanfattar information för dataschema (DDL), databaskod (DML) och datamigreringsmetoder. Vi expanderar ytterligare på varje scenario senare i den här artikeln, länkad i kolumnen Alternativ .
| Alternativnummer | Alternativ | Vad den gör | Skicklighet/inställning | Scenario |
|---|---|---|---|---|
| 1 | Data Factory | Schemakonvertering (DDL) Dataextrahering Datainsamling |
ADF/Pipeline | Förenklat allt i ett schema (DDL) och datamigrering. Rekommenderas för dimensionstabeller. |
| 2 | Data Factory med partition | Schemakonvertering (DDL) Dataextrahering Datainsamling |
ADF/Pipeline | Använd partitioneringsalternativ för att öka läs-/skrivparallellitet med 10x dataflöde jämfört med alternativ 1, vilket rekommenderas för faktatabeller. |
| 3 | Data Factory med accelererad kod | Schemakonvertering (DDL) | ADF/Pipeline | Konvertera och migrera schemat (DDL) först och använd sedan CETAS för att extrahera och KOPIERA/Data Factory för att mata in data för optimal övergripande inmatningsprestanda. |
| 4 | Accelererad kod för lagrade procedurer | Schemakonvertering (DDL) Dataextrahering Kodutvärdering |
T-SQL | SQL-användare som använder IDE med mer detaljerad kontroll över vilka uppgifter de vill arbeta med. Använd COPY/Data Factory för att mata in data. |
| 5 | SQL Database-projekttillägg för Azure Data Studio | Schemakonvertering (DDL) Dataextrahering Kodutvärdering |
SQL-projekt | SQL Database Project för distribution med integrering av alternativ 4. Använd COPY eller Data Factory för att mata in data. |
| 6 | SKAPA EXTERN TABELL SOM SELECT (CETAS) | Dataextrahering | T-SQL | Kostnadseffektiva och högpresterande dataextrahering i Azure Data Lake Storage (ADLS) Gen2. Använd COPY/Data Factory för att mata in data. |
| 7 | Migrera med hjälp av dbt | Schemakonvertering (DDL) konvertering av databaskod (DML) |
dbt | Befintliga dbt-användare kan använda dbt Fabric-adaptern för att konvertera DDL och DML. Du måste sedan migrera data med hjälp av andra alternativ i den här tabellen. |
Välj en arbetsbelastning för den första migreringen
När du bestämmer var du ska börja med migreringsprojektet synapse dedikerad SQL-pool till Infrastrukturlager väljer du ett arbetsbelastningsområde där du kan:
- Bevisa hur bra det är att migrera till Fabric Warehouse genom att snabbt leverera fördelarna med den nya miljön. Starta små och enkla, förbered dig för flera små migreringar.
- Ge din interna tekniska personal tid att få relevant erfarenhet av de processer och verktyg som de använder när de migrerar till andra områden.
- Skapa en mall för ytterligare migreringar som är specifika för synapse-källmiljön och de verktyg och processer som finns för att hjälpa till.
Dricks
Skapa en inventering av objekt som måste migreras och dokumentera migreringsprocessen från början till slut, så att den kan upprepas för andra dedikerade SQL-pooler eller arbetsbelastningar.
Mängden migrerade data i en inledande migrering bör vara tillräckligt stor för att demonstrera funktionerna och fördelarna med infrastrukturlagermiljön, men inte för stor för att snabbt kunna visa värde. En storlek på 1–10 terabyte är typisk.
Migrering med Fabric Data Factory
I det här avsnittet diskuterar vi alternativen med Data Factory för den persona med låg kod/ingen kod som är bekant med Azure Data Factory och Synapse Pipeline. Det här alternativet för att dra och släppa användargränssnittet är ett enkelt steg för att konvertera DDL och migrera data.
Fabric Data Factory kan utföra följande uppgifter:
- Konvertera schemat (DDL) till Fabric Warehouse-syntaxen.
- Skapa schemat (DDL) på Infrastrukturlager.
- Migrera data till Infrastrukturlager.
Alternativ 1. Schema-/datamigrering – Kopieringsguiden och Kopieringsaktivitet för ForEach
Den här metoden använder Data Factory Copy Assistant för att ansluta till den dedikerade SQL-källpoolen, konvertera DDL-syntaxen för den dedikerade SQL-poolen till Infrastrukturresurser och kopiera data till Infrastrukturlager. Du kan välja 1 eller flera måltabeller (för TPC-DS-datauppsättning finns det 22 tabeller). Den genererar ForEach för att loopa igenom listan över tabeller som valts i användargränssnittet och skapa 22 parallella kopieringsaktivitetstrådar.
- 22 SELECT-frågor (en för varje vald tabell) genererades och kördes i den dedikerade SQL-poolen.
- Kontrollera att du har rätt DWU- och resursklass för att tillåta att de frågor som genereras körs. I det här fallet behöver du minst DWU1000 med
staticrc10för att högst 32 frågor ska kunna hantera 22 skickade frågor. - Data Factory-direktkopiering av data från den dedikerade SQL-poolen till Fabric Warehouse kräver mellanlagring. Inmatningsprocessen bestod av två faser.
- Den första fasen består av att extrahera data från den dedikerade SQL-poolen till ADLS och kallas mellanlagring.
- Den andra fasen består av att mata in data från mellanlagring till Infrastrukturlager. Det mesta av datainmatningstidpunkten är i mellanlagringsfasen. Sammanfattningsvis har mellanlagring en enorm inverkan på inmatningsprestanda.
Rekommenderad användning
Med hjälp av kopieringsguiden för att generera en ForEach får du ett enkelt användargränssnitt för att konvertera DDL och mata in de valda tabellerna från den dedikerade SQL-poolen till Fabric Warehouse i ett steg.
Det är dock inte optimalt med det totala dataflödet. Kravet på att använda mellanlagring, behovet av att parallellisera läsning och skrivning för steget "Källa till steg" är de viktigaste faktorerna för prestandafördröjningen. Vi rekommenderar att du endast använder det här alternativet för dimensionstabeller.
Alternativ 2. DDL/datamigrering – Datapipeline med partitionsalternativ
För att förbättra dataflödet för att läsa in större faktatabeller med fabric-datapipelinen rekommenderar vi att du använder Kopieringsaktivitet för varje faktatabell med partitionsalternativ. Detta ger bästa prestanda med kopieringsaktivitet.
Du kan välja att använda den fysiska källtabellens fysiska partitionering, om det är tillgängligt. Om tabellen inte har fysisk partitionering måste du ange partitionskolumnen och ange min/max-värden för att använda dynamisk partitionering. I följande skärmbild anger källalternativen för datapipelinen ett dynamiskt intervall med partitioner baserat på ws_sold_date_sk kolumnen.
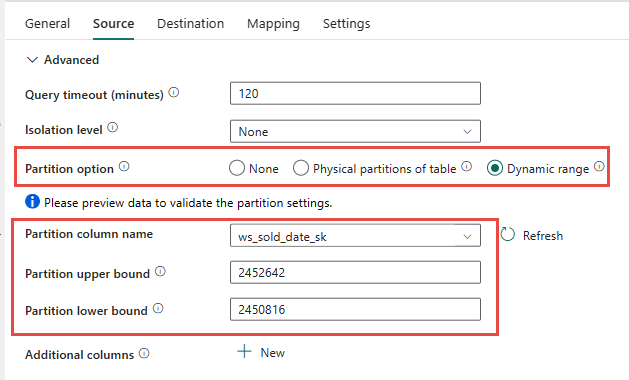
När du använder partition kan öka dataflödet med mellanlagringsfasen finns det överväganden för att göra lämpliga justeringar:
- Beroende på partitionsintervallet kan det potentiellt använda alla samtidighetsfack eftersom det kan generera över 128 frågor i den dedikerade SQL-poolen.
- Du måste skala till minst DWU6000 så att alla frågor kan köras.
- För TPC-DS-tabellen
web_salesskickades till exempel 163 frågor till den dedikerade SQL-poolen. Vid DWU6000 kördes 128 frågor medan 35 frågor köades. - Dynamisk partition väljer automatiskt intervallpartitionen. I det här fallet ett intervall på 11 dagar för varje SELECT-fråga som skickas till den dedikerade SQL-poolen. Till exempel:
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
Rekommenderad användning
För faktatabeller rekommenderar vi att du använder Data Factory med partitioneringsalternativet för att öka dataflödet.
De ökade parallelliserade läsningarna kräver dock dedikerad SQL-pool för att skala till högre DWU för att tillåta att extraheringsfrågorna körs. Genom att utnyttja partitionering förbättras hastigheten 10x över inget partitionsalternativ. Du kan öka DWU för att få ytterligare dataflöde via beräkningsresurser, men den dedikerade SQL-poolen har högst 128 aktiva frågor som tillåts.
Alternativ 3. DDL-migrering – Kopieringsguiden Förkopiera kopieringsaktivitet
De två tidigare alternativen är bra alternativ för datamigrering för mindre databaser. Men om du behöver högre dataflöde rekommenderar vi ett alternativt alternativ:
- Extrahera data från den dedikerade SQL-poolen till ADLS, vilket minskar prestandakostnaderna för stadiet.
- Använd antingen Data Factory eller COPY-kommandot för att mata in data i Fabric Warehouse.
Rekommenderad användning
Du kan fortsätta att använda Data Factory för att konvertera ditt schema (DDL). Med hjälp av guiden Kopiera kan du välja den specifika tabellen eller Alla tabeller. Avsiktligt migrerar detta schemat och data i ett steg och extraherar schemat utan några rader, med hjälp av det falska villkoret, TOP 0 i frågeuttryck.
Följande kodexempel omfattar schemamigrering (DDL) med Data Factory.
Kodexempel: Schemamigrering (DDL) med Data Factory
Du kan använda Infrastrukturdatapipelines för att enkelt migrera över DDL (scheman) för tabellobjekt från valfri Azure SQL Database-källa eller dedikerad SQL-pool. Den här datapipelinen migreras över schemat (DDL) för källdedikerade SQL-pooltabeller till Fabric Warehouse.
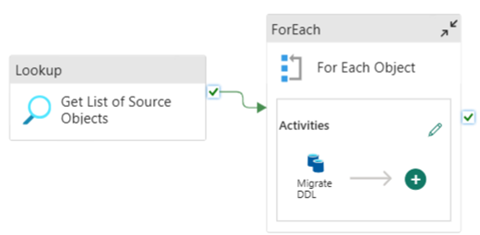
Pipelinedesign: parametrar
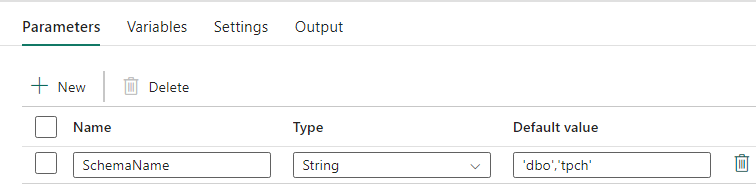
Den här datapipelinen accepterar en parameter SchemaName, som gör att du kan ange vilka scheman som ska migreras över. Schemat dbo är standard.
I fältet Standardvärde anger du en kommaavgränsad lista över tabellscheman som anger vilka scheman som ska migreras: 'dbo','tpch' för att tillhandahålla två scheman dbo och tpch.
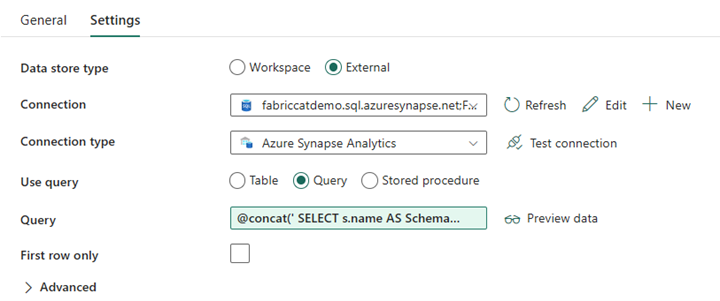
Pipelinedesign: Uppslagsaktivitet
Skapa en uppslagsaktivitet och ställ in anslutningen så att den pekar på källdatabasen.
På fliken Inställningar :
Ange Datalagringstyp till Extern.
Anslutningen är din dedikerade SQL-pool i Azure Synapse. Anslutningstyp är Azure Synapse Analytics.
Använd frågan är inställd på Fråga.
Fältet Fråga måste skapas med ett dynamiskt uttryck, vilket gör att parametern SchemaName kan användas i en fråga som returnerar en lista över målkälltabeller. Välj Fråga och välj sedan Lägg till dynamiskt innehåll.
Det här uttrycket i LookUp-aktiviteten genererar en SQL-instruktion för att fråga systemvyerna för att hämta en lista över scheman och tabeller. Refererar till parametern SchemaName för att tillåta filtrering på SQL-scheman. Utdata för detta är en matris med SQL-schema och tabeller som ska användas som indata i ForEach-aktiviteten.
Använd följande kod för att returnera en lista över alla användartabeller med deras schemanamn.
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
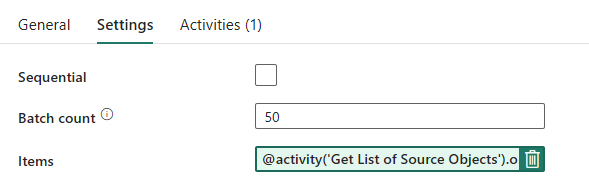
Pipelinedesign: ForEach-loop
För ForEach-loopen konfigurerar du följande alternativ på fliken Inställningar :
- Inaktivera Sekventiell så att flera iterationer kan köras samtidigt.
- Ange Batch-antal till
50, vilket begränsar det maximala antalet samtidiga iterationer. - Fältet Objekt måste använda dynamiskt innehåll för att referera till utdata från uppslagsaktiviteten. Använd följande kodfragment:
@activity('Get List of Source Objects').output.value
Pipelinedesign: Kopiera aktivitet i ForEach-loopen
Lägg till en kopieringsaktivitet i ForEach-aktiviteten. Den här metoden använder dynamiskt uttrycksspråk i datapipelines för att skapa en SELECT TOP 0 * FROM <TABLE> för att migrera endast schemat utan data till ett infrastrukturlager.
På fliken Källa :
- Ange Datalagringstyp till Extern.
- Anslutningen är din dedikerade SQL-pool i Azure Synapse. Anslutningstyp är Azure Synapse Analytics.
- Ange Använd fråga till Fråga.
- I fältet Fråga klistrar du in frågan med dynamiskt innehåll och använder det här uttrycket som returnerar noll rader, endast tabellschemat:
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)

På fliken Mål :
- Ange Datalagertyp till Arbetsyta.
- Datalagertypen Arbetsyta är Informationslager och informationslagret är inställt på Infrastrukturlager.
- Måltabellens schema och tabellnamn definieras med dynamiskt innehåll.
- Schema refererar till den aktuella iterationens fält, SchemaName med kodfragmentet:
@item().SchemaName - Tabellen refererar till TableName med kodfragmentet:
@item().TableName
- Schema refererar till den aktuella iterationens fält, SchemaName med kodfragmentet:

Pipelinedesign: Mottagare
För Mottagare pekar du på ditt lager och refererar till källschemat och tabellnamnet.
När du har kört den här pipelinen visas informationslagret fyllt med varje tabell i källan, med rätt schema.
Migrering med lagrade procedurer i synapse-dedikerad SQL-pool
Det här alternativet använder lagrade procedurer för att utföra infrastrukturmigreringen.
Du kan hämta kodexemplen vid microsoft/fabric-migrering på GitHub.com. Den här koden delas som öppen källkod, så du kan gärna bidra till att samarbeta och hjälpa communityn.
Vad lagrade procedurer för migrering kan göra:
- Konvertera schemat (DDL) till Fabric Warehouse-syntaxen.
- Skapa schemat (DDL) på Infrastrukturlager.
- Extrahera data från synapse-dedikerad SQL-pool till ADLS.
- Flagga infrastruktursyntax som inte stöds för T-SQL-koder (lagrade procedurer, funktioner, vyer).
Rekommenderad användning
Detta är ett bra alternativ för dem som:
- Är bekanta med T-SQL.
- Vill du använda en integrerad utvecklingsmiljö som SQL Server Management Studio (SSMS).
- Vill ha mer detaljerad kontroll över vilka uppgifter de vill arbeta med.
Du kan köra den specifika lagrade proceduren för schemakonverteringen (DDL), dataextraktet eller T-SQL-kodutvärderingen.
För datamigreringen måste du använda antingen COPY INTO eller Data Factory för att mata in data i Fabric Warehouse.
Migrering med SQL Database Project
Microsoft Fabric Data Warehouse stöds i SQL Database Projects-tillägget som är tillgängligt i Azure Data Studio och Visual Studio Code.
Det här tillägget är tillgängligt i Azure Data Studio och Visual Studio Code. Den här funktionen möjliggör funktioner för källkontroll, databastestning och schemavalidering.
Rekommenderad användning
Det här är ett bra alternativ för dem som föredrar att använda SQL Database Project för distributionen. Det här alternativet integrerade i stort sett lagrade procedurer för infrastrukturmigrering i SQL Database-projektet för att ge en sömlös migreringsupplevelse.
Ett SQL Database-projekt kan:
- Konvertera schemat (DDL) till Fabric Warehouse-syntaxen.
- Skapa schemat (DDL) på Infrastrukturlager.
- Extrahera data från synapse-dedikerad SQL-pool till ADLS.
- Flagga syntax som inte stöds för T-SQL-koder (lagrade procedurer, funktioner, vyer).
För datamigreringen använder du antingen COPY INTO eller Data Factory för att mata in data i Fabric Warehouse.
Microsoft Fabric CAT-teamet har lagt till stöd för Azure Data Studio i Fabric och har tillhandahållit en uppsättning PowerShell-skript för att hantera extrahering, skapande och distribution av schema (DDL) och databaskod (DML) via ett SQL Database-projekt. En genomgång av hur du använder SQL Database-projektet med våra användbara PowerShell-skript finns i microsoft/fabric-migration på GitHub.com.
Mer information om SQL Database Projects finns i Komma igång med SQL Database Projects-tillägget och Skapa och publicera ett projekt.
Migrering av data med CETAS
Kommandot T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) ger den mest kostnadseffektiva och optimala metoden för att extrahera data från Synapse-dedikerade SQL-pooler till Azure Data Lake Storage (ADLS) Gen2.
Vad CETAS kan göra:
- Extrahera data till ADLS.
- Det här alternativet kräver att användarna skapar schemat (DDL) på Infrastrukturlager innan data matas in. Överväg alternativen i den här artikeln för att migrera schema (DDL).
Fördelarna med det här alternativet är:
- Endast en enskild fråga per tabell skickas mot den dedikerade SQL-källpoolen för Synapse. Detta använder inte alla samtidighetsfack och blockerar därför inte samtidig kundproduktions-ETL/frågor.
- Skalning till DWU6000 krävs inte eftersom endast en enda samtidighetsfack används för varje tabell, så att kunderna kan använda lägre DWU:er.
- Extraktet körs parallellt över alla beräkningsnoder, och detta är nyckeln till att förbättra prestandan.
Rekommenderad användning
Använd CETAS för att extrahera data till ADLS som Parquet-filer. Parquet-filer ger fördelen med effektiv datalagring med kolumnkomprimering som tar mindre bandbredd för att flytta över nätverket. Eftersom Fabric lagrade data som Delta parquet-format blir datainmatningen dessutom 2,5 gånger snabbare jämfört med textfilformatet, eftersom det inte finns någon konvertering till deltaformatets omkostnader under inmatningen.
Så här ökar du CETAS-dataflödet:
- Lägg till parallella CETAS-åtgärder, vilket ökar användningen av samtidighetsfack men tillåter mer dataflöde.
- Skala DWU på synapse-dedikerad SQL-pool.
Migrering via dbt
I det här avsnittet diskuterar vi dbt-alternativet för de kunder som redan använder dbt i sin aktuella Synapse-dedikerade SQL-poolmiljö.
Vad dbt kan göra:
- Konvertera schemat (DDL) till Fabric Warehouse-syntaxen.
- Skapa schemat (DDL) på Infrastrukturlager.
- Konvertera databaskod (DML) till infrastrukturresurssyntax.
Dbt-ramverket genererar DDL och DML (SQL-skript) i farten med varje körning. Med modellfiler som uttrycks i SELECT-instruktioner kan DDL/DML omedelbart översättas till valfri målplattform genom att ändra profilen (niska veze) och adaptertypen.
Rekommenderad användning
Dbt-ramverket är kod-första metoden. Data måste migreras med hjälp av alternativ som anges i det här dokumentet, till exempel CETAS eller COPY/Data Factory.
Dbt-adaptern för Microsoft Fabric Synapse Data Warehouse tillåter att befintliga dbt-projekt som riktar in sig på olika plattformar, till exempel Synapse-dedikerade SQL-pooler, Snowflake, Databricks, Google Big Query eller Amazon Redshift, migreras till ett infrastrukturlager med en enkel konfigurationsändring.
Information om hur du kommer igång med ett dbt-projekt som riktar sig mot Infrastrukturlager finns i Självstudie: Konfigurera dbt för Fabric Data Warehouse. Det här dokumentet visar också ett alternativ för att flytta mellan olika lager/plattformar.
Datainmatning till infrastrukturlager
För inmatning till Fabric Warehouse använder du COPY INTO eller Fabric Data Factory, beroende på vad du föredrar. Båda metoderna är de rekommenderade och bäst presterande alternativen, eftersom de har motsvarande prestandadataflöde, med tanke på förutsättningen att filerna redan extraheras till Azure Data Lake Storage (ADLS) Gen2.
Flera faktorer att tänka på så att du kan utforma din process för maximal prestanda:
- Med Infrastruktur finns det ingen resurskonkurrens när du läser in flera tabeller från ADLS till Fabric Warehouse samtidigt. Därför uppstår ingen prestandaförsämring vid inläsning av parallella trådar. Det maximala dataflödet för inmatning begränsas endast av beräkningskraften för din Infrastrukturkapacitet.
- Arbetsbelastningshantering för infrastrukturresurser ger separation av resurser som allokerats för belastning och frågor. Det finns ingen resurskonkurration när frågor och datainläsning körs samtidigt.
Relaterat innehåll
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för