Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
Översättningar som inte är engelska tillhandahålls endast för enkelhetens skull. Se versionen EN-US av det här dokumentet för bindningsversionen.
Den här artikeln innehåller information om hur data som tillhandahålls av dig bearbetas, används och lagras av Azure AI Speech text till tal. Som en viktig påminnelse ansvarar du för din användning och implementeringen av den här tekniken och måste få alla nödvändiga behörigheter, inklusive, om tillämpligt, från röst- och avatartalanger (och, om tillämpligt, användare av din personliga röstintegrering)) för bearbetning av deras röst, bild, likhet och/eller andra data för att utveckla syntetiska röster och/eller avatarer.
Du ansvarar också för att erhålla licenser, behörigheter eller andra rättigheter som krävs för det innehåll som du matar in till text-till-tal-tjänsten för att generera ljud-, bild- och/eller videoutdata. Vissa jurisdiktioner kan införa särskilda rättsliga krav för insamling, bearbetning och lagring av vissa kategorier av data, till exempel biometriska data, och mandat att avslöja användningen av syntetiska röster, bilder och/eller videor för användare. Innan du använder text till tal för att bearbeta och lagra data av något slag och, om tillämpligt, för att skapa anpassade modeller för neural röst, personlig röst eller anpassad avatar, måste du se till att du uppfyller alla juridiska krav som kan gälla för dig.
Vilka data bearbetar text-till-tal-tjänster?
Fördefinierad neural röst och fördefinierad avatar bearbetar följande typer av data:
- Textinmatning för talsyntes. Det här är den text som du väljer och skickar till text till taltjänsten för att generera ljudutdata med hjälp av en uppsättning fördefinierade neurala röster, eller för att generera en fördefinierad avatar som yttrar ljud som genererats från antingen fördefinierade eller anpassade neurala röster.
Inspelad erkännandefil för röstartister. Kunder måste ladda upp ett specifikt inspelat uttalande som talas av rösttalangen där de bekräftar att du kommer att använda deras röst för att skapa syntetiska röst(er).
Anmärkning
När du förbereder inspelningsskriptet måste du inkludera den bekräftelse som krävs för att rösttalangen ska spela in. Du hittar instruktionen på flera språk här. Bekräftelseuttalandets språk måste vara detsamma som språket för ljudinspelningsträningsdata.
Träningsdata (inklusive ljudfiler och relaterade textavskrifter). Detta inkluderar ljudinspelningar från rösttalangen som har gått med på att använda sin röst för modellträning och relaterade textavskrifter. I ett anpassat neuralt voice pro-projekt kan du tillhandahålla egna textranskriptioner av ljud eller använda den automatiserade transkriptionsfunktionen för taligenkänning som är tillgänglig i Speech Studio för att generera en textavskrift av ljudet. Både ljudinspelningarna och textavskriftsfilerna används som träningsdata för röstmodeller. I ett anpassat neuralt röst lite-projekt uppmanas du att spela in rösten som talar det Microsoft-definierade skriptet i Speech Studio. Textavskrifter krävs inte för personliga röstfunktioner.
Text som testskript. Du kan ladda upp dina egna textbaserade skript för att utvärdera och testa kvaliteten på den anpassade neurala röstmodellen genom att generera ljudexempel för talsyntes. Detta gäller inte för personliga röstfunktioner.
Textinmatning för talsyntes. Det här är den text du väljer och skickar till text-till-tal-tjänsten för att generera ljudutdata med din anpassade neurala röst.
Hur bearbetar text till taltjänster data?
Fördefinierad neural röst
Diagrammet nedan illustrerar hur dina data bearbetas för syntes med en förbyggd neural röst. Indata är text och utdata är ljud. Observera att varken indatatext eller utdataljudinnehåll kommer att lagras i Microsoft-loggar.

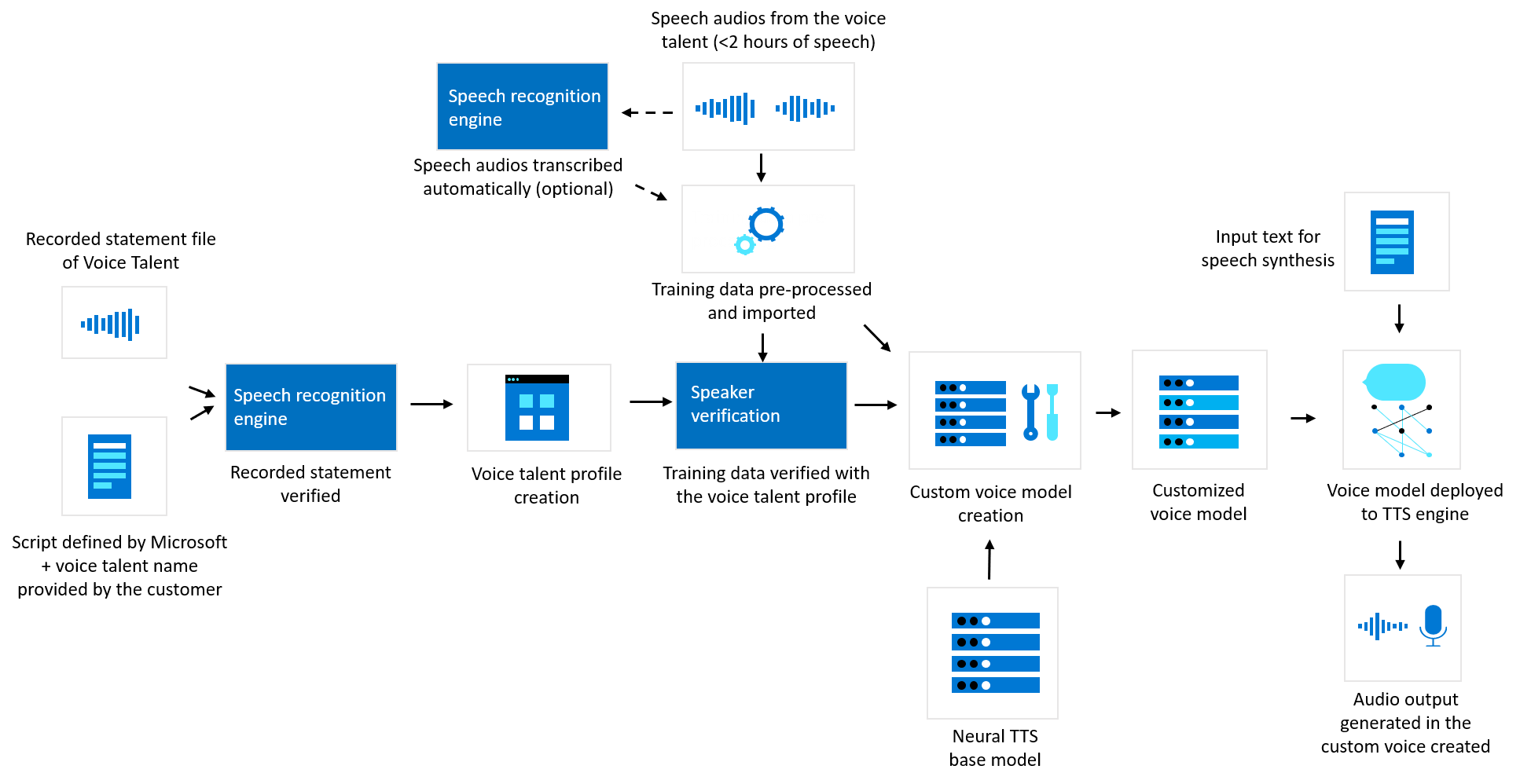
Anpassad neuroröst
Diagrammet nedan visar hur dina data bearbetas för anpassad neural röst. Det här diagrammet beskriver tre olika typer av bearbetning: hur Microsoft verifierar inspelade uttrycksfiler för rösttalanger före anpassad neural röstmodellträning, hur Microsoft skapar en anpassad neural röstmodell med dina träningsdata och hur text till tal bearbetar textinmatningen för att generera ljudinnehåll.
Text-till-tal-avatar
Diagrammet nedan visar hur dina data bearbetas för syntes med fördefinierad text till tal-avatar. Det finns tre komponenter i ett avatarinnehållsgenereringsarbetsflöde: textanalys, TTS-ljudsyntesen och TTS-avatarvideosyntesen. För att generera avatarvideo matas text först in i textanalysatorn, vilket ger utdata i form av fonetiksekvens. Sedan förutsäger TTS-ljudsyntesen de akustiska funktionerna i indatatexten och syntetiserar rösten. Dessa två delar tillhandahålls av text-till-tal-röstmodeller. Neural text to speech Avatar-modellen förutsäger därefter en läppsynkroniserad bild med hjälp av akustiska funktioner, så att en syntetisk video kan genereras.
![]()
Videoöversättning (förhandsversion)
Diagrammet nedan visar hur dina data bearbetas med videoöversättning. Kunden laddar upp video som indata för videoöversättning, dialogljud extraheras och tal till text transkriberar ljudet till textinnehåll. Sedan översätts textinnehållet till målspråkets innehåll och med hjälp av text till tal-funktionen sammanfogas det översatta ljudet med ursprungligt videoinnehåll som videoutdata.

Verifiering av inspelat bekräftelseuttryck
Microsoft kräver att kunderna laddar upp en ljudfil till Speech Studio med en inspelad instruktion av rösttalangen som bekräftar att kunden kommer att använda sin röst för att skapa en syntetisk röst. Microsoft kan använda Microsofts teknik för tal-till-text- och taligenkänning för att transkribera denna inspelade bekräftelseuttryck till text och kontrollera att innehållet i inspelningen matchar det fördefinierade skriptet som tillhandahålls av Microsoft. Detta bekräftelseuttalande, tillsammans med den talanginformation som du tillhandahåller med ljudet, används för att skapa en röstprofil. Du måste associera träningsdata med relevant rösttalangprofil när du initierar anpassad neural röstträning.
Microsoft kan också bearbeta biometriska röstsignaturer från den inspelade bekräftelsemeddelandefilen för rösttalangen och från randomiserat ljud från träningsdatauppsättningarna för att bekräfta att röstsignaturen i inspelningen av bekräftelseutdraget och inspelningarna av träningsdata matchar med rimligt förtroende med hjälp av Azure AI-talarverifiering. En röstsignatur kan också kallas för en "röstmall" eller "röstavtryck" och är en numerisk vektor som representerar en individs röstegenskaper som extraheras från ljudinspelningar av en person som talar. Detta tekniska skydd är avsett att förhindra missbruk av anpassad neural röst, till exempel genom att hindra kunder från att träna röstmodeller med ljudinspelningar och använda modellerna för att förfalska en persons röst utan deras vetskap eller medgivande.
Röstsignaturerna används av Microsoft enbart för talarverifiering eller på annat sätt nödvändigt för att undersöka missbruk av tjänsterna.
Microsoft Products and Services Data Protection Addendum ("DPA") beskriver kundernas och Microsofts skyldigheter när det gäller bearbetning och säkerhet för kunddata och personuppgifter i samband med Azure och införlivas med referens i kundernas enterprise-avtal för Azure-tjänster. Microsofts databehandling i det här avsnittet styrs under avsnittet Legitima intressen affärsåtgärder i tillägget dataskydd.
Träna en anpassad neural röstmodell
De träningsdata (talljud) som kunder skickar till Speech Studio bearbetas i förväg med hjälp av automatiserade verktyg för kvalitetskontroll, inklusive kontroll av dataformat, uttalsbedömning, brusidentifiering, skriptmappning osv. Träningsdata importeras sedan till modellträningskomponenten för den anpassade röstplattformen. Under träningsprocessen delas träningsdata (både röstljud- och textavskrifter) upp i detaljerade mappningar av röstakustik och text, till exempel en sekvens av fonem. Genom ytterligare komplexa maskinorienterade modellering bygger tjänsten en röstmodell, som sedan kan användas för att generera ljud som låter ungefär som rösttalangen och till och med kan genereras på olika språk från inspelningen av träningsdata. Röstmodellen är en modell för text till tal-dator som kan efterlikna unika röstegenskaper hos en viss talare. Den representerar en uppsättning parametrar i binärt format som inte är läsbara för människor och som inte innehåller ljudinspelningar.
En kunds träningsdata används endast för att utveckla kundens anpassade röstmodeller och används inte av Microsoft för att träna eller förbättra microsofts text till talröstmodeller.
Talsyntes/ljudinnehållsgenerering
När röstmodellen har skapats kan du använda den för att skapa ljudinnehåll via text till tal-tjänsten med två olika alternativ.
För talsyntes i realtid skickar du indatatexten till den text-till-tal-tjänsten via TTS SDK eller RESTful API. Text till tal bearbetar indatatexten och returnerar utdatafiler för ljudinnehåll i realtid till programmet som gjorde begäran.
För asynkron syntes av långt ljud (batchsyntes) skickar du inmatningstextfilerna till tjänsten för batchsyntes av text till tal via Long Audio API för att skapa ljud asynkront som är längre än 10 minuter (till exempel ljudböcker eller föreläsningar). Till skillnad från syntes som utförs med text till tal-API returneras inte svar i realtid med API:et för långt ljud. Ljud skapas asynkront och du kan komma åt och ladda ned syntetiserade ljudfiler när de görs tillgängliga från batchsyntestjänsten.
Du kan också använda din anpassade röstmodell för att generera ljudinnehåll via ett verktyg för att skapa ljudinnehåll utan kod och välja att spara textindata eller mata ut ljudinnehåll med verktyget i Azure Storage.
Databearbetning för anpassad Neural Voice Lite (förhandsversion)
Anpassad neural röst lite är en projekttyp i offentlig förhandsversion som gör att du kan spela in 20–50 röstexempel i Speech Studio och skapa en lättanpassad neural röstmodell i demonstrations- och utvärderingssyfte. Både inspelningsskriptet och testskriptet är fördefinierade av Microsoft. En syntetisk röstmodell som du skapar med anpassad neural röst lätt kan endast distribueras och användas mer allmänt om du ansöker om och får fullständig åtkomst till anpassad neural röst (enligt tillämpliga villkor).
Den syntetiska rösten och den relaterade ljudinspelningen som du skickar via Speech Studio tas automatiskt bort inom 90 dagar om du inte får fullständig åtkomst till anpassad neural röst och väljer att distribuera den syntetiska rösten, i vilket fall du kommer att kontrollera varaktigheten för dess kvarhållning. Om rösttalangen vill att den syntetiska rösten och de relaterade ljudinspelningarna ska tas bort före 90 dagar kan de ta bort dem direkt på portalen eller kontakta företaget för att göra det.
Innan du kan distribuera någon syntetisk röstmodell som skapats med hjälp av ett anpassat neuralt röst lite-projekt måste rösttalangen dessutom tillhandahålla en ytterligare inspelning där de bekräftar att den syntetiska rösten kommer att användas för ytterligare syften utöver demonstration och utvärdering.
Databearbetning för personligt röst-API (förhandsversion)
Med personlig röst kan kunderna skapa en syntetisk röst med ett kort mänskligt röstexempel. Den verbala bekräftelseuttalandefilen som beskrivs ovan krävs från varje användare som använder integrationen i din applikation. Microsoft kan bearbeta biometriska röstsignaturer från den inspelade röstmeddelandefilen för varje användare och deras inspelade träningsexempel (t.ex. uppmaningen) för att bekräfta att röstsignaturen i inspelning av bekräftelseuttryck och inspelning av träningsdata matchar med rimligt förtroende med hjälp av Azure AI-talarverifiering.
Träningsexemplet används för att skapa röstmodellen. Röstmodellen kan sedan användas för att generera tal med textindata som tillhandahålls till tjänsten via API:et, utan ytterligare distribution krävs.
Datalagring och kvarhållning
Alla taltjänster
Textinmatning för talsyntes: Microsoft behåller eller lagrar inte den text som du anger med realtidssyntestexten till tal-API:et. Skript som tillhandahålls via Long Audio API för text till tal eller via batch-API för text till tal-avatar lagras i Azure Storage för att bearbeta batchsyntesbegäran. Indatatexten kan när som helst tas bort via borttagnings-API:et.
Mata ut ljud- och videoinnehåll: Microsoft lagrar inte ljud- eller videoinnehåll som genereras med API:et för realtidssyntes. Om du använder Videoöversättning eller Long Audio API för batch-API för text till tal-avatar lagras utdataljud- eller videoinnehållet i Azure Storage. Dessa ljud eller videor kan när som helst tas bort via borttagningsåtgärden .
Inspelad bekräftelse och talarverifieringsdata: Röstsignaturerna används av Microsoft enbart för talarverifiering eller på annat sätt nödvändigt för att undersöka missbruk av tjänsterna. Röstsignaturerna behålls endast under den tid som krävs för att utföra talarverifiering, vilket kan inträffa då och då. Microsoft kan kräva den här verifieringen innan du kan träna eller träna om anpassade neurala röstmodeller i Speech Studio, eller om det annars är nödvändigt. Microsoft behåller data för den inspelade bekräftelseuttrycksfilen och rösttalangprofilen så länge som det behövs för att bevara säkerheten och integriteten för Azure AI Speech.
Anpassade neurala röstmodeller: Även om du behåller de exklusiva användningsrättigheterna till din anpassade neurala röstmodell kan Microsoft oberoende behålla en kopia av anpassade neurala röstmodeller så länge som det behövs. Microsoft kan använda din anpassade neurala röstmodell enbart för att skydda säkerheten och integriteten för Microsoft Azure AI-tjänster.
Microsoft skyddar och lagrar kopior av varje rösttalangs inspelade bekräftelseinstruktur och anpassade neurala röstmodeller med samma säkerhet på hög nivå som de använder för sina andra Azure-tjänster. Läs mer i Microsoft Trust Center.
Träningsdata: Du skickar röstträningsdata för rösttalanger för att generera röstmodeller via Speech Studio, som behålls och lagras som standard i Azure Storage (mer information finns i Azure Storage-kryptering för data i REST ). Du kan komma åt och ta bort någon av träningsdata som används för att skapa röstmodeller via Speech Studio.
Du kan hantera lagring av dina träningsdata via BYOS (Bring Your Own Storage). Med den här lagringsmetoden kan träningsdata endast nås för röstmodellträning och lagras i övrigt via BYOS.
Anmärkning
Personlig röst stöder inte BYOS. Dina data lagras i Azure Storage som hanteras av Microsoft. Du kan komma åt och ta bort någon av träningsdata (prompt audio) som används för att skapa röstmodeller via API. Microsoft kan oberoende behålla en kopia av personliga röstmodeller så länge som det behövs. Microsoft kan använda din personliga röstmodell enbart för att skydda säkerheten och integriteten för Microsoft Azure AI-tjänster.