Ansluta till SAP HANA-datakällor med DirectQuery i Power BI
Du kan ansluta till SAP HANA-datakällor direkt med DirectQuery, vilket ofta krävs för stora datamängder som överskrider tillgängliga resurser för att stödja importmodeller. Det finns två metoder för att ansluta till SAP HANA i DirectQuery-läge, var och en med olika funktioner:
Behandla SAP HANA som en flerdimensionell källa (standard): I det här fallet liknar beteendet när Power BI ansluter till andra flerdimensionella källor som SAP Business Warehouse eller Analysis Services. När du ansluter till SAP HANA som en flerdimensionell källa väljs en enda analys- eller beräkningsvy och alla mått, hierarkier och attribut i den vyn är tillgängliga i fältlistan. Du kan inte lägga till beräknade kolumner eller andra dataanpassningar i den semantiska modellen. När visuella objekt skapas hämtas aggregerade data direkt från SAP HANA. Behandla SAP HANA som en flerdimensionell källa är standardvärdet för nya DirectQuery-rapporter via SAP HANA.
Behandla SAP HANA som relationskälla: I det här fallet behandlar Power BI SAP HANA som en relationsdatakälla. Den här metoden ger större flexibilitet. Du kan bland annat lägga till beräknade kolumner och inkludera data från andra källor, men du måste vara noga med att se till att måtten aggregeras som förväntat. Undvik icke-additiva mått. Se också till att du använder enkla vyer med få kolumner och kopplingar för att undvika prestandaproblem. Överväg att återskapa mått i den semantiska modellen, men kom ihåg att komplexa mått kanske inte viks. SAP HANA-hierarkier är inte tillgängliga när du använder SAP HANA som relationskälla.
Anslutningsmetoden bestäms av ett globalt verktygsalternativ, som anges genom att välja Fil>Alternativ och inställningar och sedan Alternativ>DirectQueryoch sedan välja alternativet Behandla SAP HANA som en relationskälla, enligt följande bild.
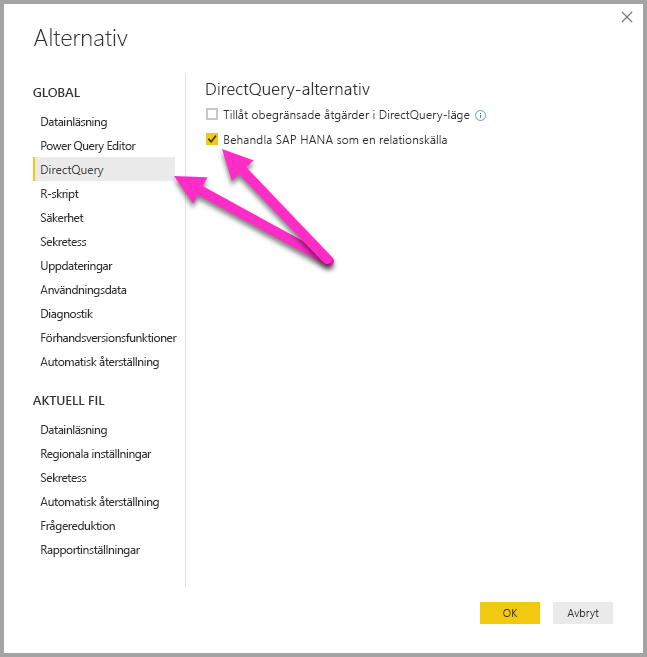
Alternativet att behandla SAP HANA som en relationskälla styr anslutningsmetoden för alla nya rapporter med DirectQuery via SAP HANA. Det har ingen effekt på några befintliga SAP HANA-anslutningar i den aktuella rapporten eller på anslutningar i andra rapporter som öppnas. Så om alternativet för närvarande är avmarkerat, så när du lägger till en ny anslutning till SAP HANA med hjälp av Hämta data, behandlar anslutningen SAP HANA som en flerdimensionell källa. Men om en annan rapport öppnas som även ansluter till SAP HANA fortsätter rapporten att fungera enligt det alternativ som angavs när den skapades. Det innebär att alla rapporter som ansluter till SAP HANA som relationskälla fortsätter att behandla SAP HANA som en relationskälla även om alternativet nu är avmarkerat.
De två SAP HANA-anslutningsmetoderna utgör ett annat beteende och det går inte att växla en befintlig rapport från en anslutningsmetod till den andra.
Behandla SAP HANA som en flerdimensionell källa (standard)
Alla nya anslutningar till SAP HANA använder den här anslutningsmetoden som standard och behandlar SAP HANA som en flerdimensionell källa. När du ansluter till SAP HANA som en flerdimensionell källa gäller följande överväganden:
I Hämta datanavigeringkan du välja en enda SAP HANA-vy. Det går inte att välja enskilda mått eller attribut. Det finns ingen fråga som definierats vid tidpunkten för anslutningen, vilket skiljer sig från att importera data eller när du använder DirectQuery vid behandling av SAP HANA som relationskälla. Det här övervägandet innebär också att det inte går att använda en SAP HANA SQL-fråga direkt när du väljer den här anslutningsmetoden.
Alla mått, hierarkier och attribut för den valda vyn visas i fältlistan.
När ett mått används i ett visuellt objekt efterfrågas SAP HANA för att hämta måttvärdet på den aggregeringsnivå som krävs för det visuella objektet. När du hanterar icke-additiva mått, till exempel räknare och förhållanden, utförs alla aggregeringar av SAP HANA och ingen ytterligare aggregering utförs av Power BI.
För att säkerställa att rätt mängdvärden alltid kan hämtas från SAP HANA måste vissa begränsningar införas. Det går till exempel inte att lägga till beräknade kolumner eller kombinera data från flera SAP HANA-vyer i samma rapport. Det går inte heller att ta bort kolumner eller ändra deras datatyper.
Att behandla SAP HANA som en flerdimensionell källa ger mindre flexibilitet än den alternativa relationella metod, men det är enklare. Den här anslutningsmetoden säkerställer korrekta aggregeringsvärden när du hanterar mer komplexa SAP HANA-mått och ger vanligtvis högre prestanda.
Listan Field innehåller alla mått, attribut och hierarkier från SAP HANA-vyn. Observera följande beteenden som gäller när du använder den här anslutningsmetoden:
Alla attribut som ingår i minst en hierarki döljs som standard. De kan dock visas om det behövs genom att välja Visa dolda från snabbmenyn i fältlistan. Från samma snabbmeny kan de göras synliga om det behövs.
I SAP HANA kan ett attribut definieras för att använda ett annat attribut som etikett. Till exempel kan Product, med värden
1,2,3och så vidare använda ProductName, med värdenBike,Shirt,Glovesoch så vidare, som etikett. I det här fallet visas ett enda fält Product i fältlistan, vars värden är etiketternaBike,Shirt,Glovesoch så vidare, men som sorteras efter, och med unikhet som bestäms av, nyckelvärdena1,2,3. En dold kolumn Product.Key skapas också, vilket ger åtkomst till de underliggande nyckelvärdena om det behövs.
Alla variabler som definierats i den underliggande SAP HANA-vyn visas vid tidpunkten för anslutningen och de nödvändiga värdena kan anges. Dessa värden kan senare ändras genom att välja Transformera data från menyfliksområdet och sedan Redigera parametrar från den nedrullningsbara menyn som visas.
De modelleringsåtgärder som tillåts är mer restriktiva än i det allmänna fallet när du använder DirectQuery, med tanke på behovet av att säkerställa att rätt aggregerade data alltid kan hämtas från SAP HANA. Det är dock fortfarande möjligt att göra vissa tillägg och ändringar, inklusive att definiera mått, byta namn på och dölja fält och definiera visningsformat. Alla sådana ändringar bevaras vid uppdatering och eventuella icke-motstridiga ändringar som görs i SAP HANA-vyn tillämpas.
Ytterligare modelleringsbegränsningar
Förutom de ovan nämnda begränsningarna bör du vara medveten om följande modelleringsbegränsningar när du ansluter till SAP HANA som en flerdimensionell källa:
- Inget stöd för beräknade kolumner: Möjligheten att skapa beräknade kolumner är inaktiverad. Det innebär också att gruppering och klustring, som förlitar sig på beräknade kolumner, inte är tillgängliga.
- Ytterligare begränsningar för mått: Det finns andra begränsningar för DAX-uttryck som kan användas i mått för att återspegla den supportnivå som erbjuds av SAP HANA. Det går till exempel inte att använda en aggregeringsfunktion över en tabell.
- Inget stöd för att definiera relationer: Endast en enda vy kan efterfrågas i en rapport, och därför finns det inget stöd för att definiera relationer.
- Ingen tabellvy: Tabellvyn visar normalt informationsnivådata i tabellerna. Med tanke på typen av flerdimensionella källor är den här vyn inte tillgänglig när du använder SAP HANA som en flerdimensionell källa.
- Kolumn- och måttinformation är fasta: Kolumnerna och måtten i fältlistan bestäms av den underliggande källan och kan inte ändras. Det går till exempel inte att ta bort en kolumn eller ändra dess datatyp. Den kan dock byta namn.
Ytterligare visualiseringsbegränsningar
Det finns begränsningar i visuella objekt när du ansluter till SAP HANA som en flerdimensionell källa:
- Ingen aggregering av kolumner: Det går inte att ändra aggregeringen för en kolumn på en visualisering och det är alltid Sammanfatta ej.
Behandla SAP HANA som en relationskälla
För att kunna ansluta till SAP HANA som relationskälla måste du välja Fil>Alternativ och inställningar och sedan Alternativ>DirectQueryoch sedan välja alternativet Behandla SAP HANA som en relationskälla.
När du använder SAP HANA som relationskälla är viss extra flexibilitet tillgänglig. Du kan till exempel skapa beräknade kolumner, inkludera data från flera SAP HANA-vyer och skapa relationer mellan de resulterande tabellerna. Det finns dock skillnader från beteendet vid anslutning till SAP HANA som en flerdimensionell källa, särskilt när SAP HANA-vyn innehåller icke-additiva mått, till exempel distinkta antal eller medelvärden, snarare än enkla summor. Icke-additiva mått kan ge felaktiga resultat. Måtten kan också minska effektiviteten för frågeplansoptimering i SAP HANA och resultera i dåliga frågeprestanda och tidsgränser.
Förstå SAP HANA som relationskälla
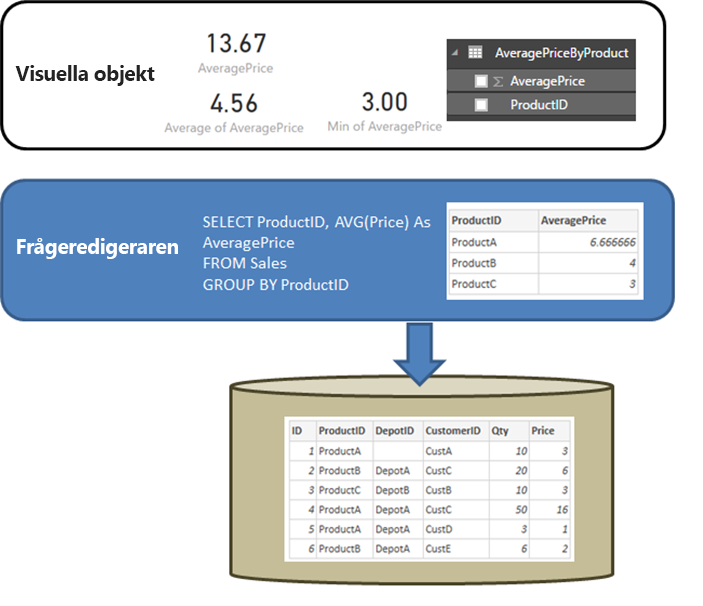
Det är användbart att börja med att klargöra beteendet för en relationskälla, till exempel SQL Server, när frågan som definieras i Hämta data eller Power Query-redigeraren utför en aggregering. I exemplet nedan returnerar en fråga som definierats i Power Query-redigeraren det genomsnittliga priset efter ProductID-.
Om data importerades till Power BI i stället för att använda DirectQuery skulle följande situation uppstå:
- Data importeras på den aggregeringsnivå som definieras av frågan som skapades i Power Query-redigeraren. Till exempel genomsnittligt pris per produkt. Detta resulterar i en tabell med de två kolumnerna ProductID och AveragePrice som kan användas i visuella objekt.
- I ett visuellt objekt utförs alla efterföljande aggregeringar, till exempel Sum, Average, Minoch andra, över dessa importerade data. Till exempel, genom att inkludera AveragePrice- i en visualisering använder man automatiskt summering med Summa och beräknar därmed summan av AveragePrice- för varje ProductID, i det här exemplet 13,67. Samma sak gäller för alla alternativa aggregeringsfunktioner, till exempel Min eller Medelvärde, som används i det visuella elementet. Till exempel returnerar Genomsnitt för AveragePrice genomsnittet av 6,66, 4 och 3, vilket ger 4,56, och inte genomsnittet av Pris på de sex posterna i den underliggande tabellen, vilket är 5,17.
Om DirectQuery över samma relationskälla används i stället för Import gäller samma semantik och resultatet blir exakt detsamma:
Med samma fråga visas exakt samma data logiskt för rapporteringslagret – även om data faktiskt inte importeras.
I ett visuellt objekt utförs alla efterföljande aggregeringar, till exempel Sum, Averageoch Min, igen över den logiska tabellen från frågan. Och återigen returnerar ett visuellt objekt som innehåller genomsnittlig för AveragePrice samma 4,56.
Tänk på SAP HANA när anslutningen behandlas som en relationskälla. Power BI kan fungera med både analysvyer och beräkningsvyer i SAP HANA, som båda kan innehålla mått. Men i dag följer metoden för SAP HANA samma principer som beskrivs tidigare i det här avsnittet: frågan som definieras i Hämta data eller Power Query-redigeraren avgör vilka data som är tillgängliga, och sedan är alla efterföljande aggregeringar i ett visuellt objekt över dessa data, och detsamma gäller för både Import och DirectQuery. Med tanke på naturen hos SAP HANA är frågeställningen som definierades i den första Hämta data-dialogrutan eller Power Query Editor alltid en aggregeringsfråga och innehåller i allmänhet mått, där de faktiska aggregeringarna definieras av SAP HANA-vyn.
Motsvarigheten till det tidigare SQL Server-exemplet är att det finns en SAP HANA-vy som innehåller ID, ProductID, DepotIDoch mått, inklusive AveragePrice, som definieras i vyn som Average of Price.
I Hämta data upplevelsen, om valen som gjordes var för ProductID och måttet AveragePrice, definierar det en fråga över vyn som begär aggregerade data. I det tidigare exemplet används pseudo-SQL för enkelhetens skull som inte matchar den exakta syntaxen för SAP HANA SQL. Sedan aggregeringar som definierats i ett visuellt objekt ytterligare aggregerar resultatet av en sådan fråga. Återigen, som beskrivits tidigare för SQL Server, gäller det här resultatet både för fallet Import och DirectQuery. I DirectQuery-fallet används frågan från Hämta data eller Power Query-redigeraren i ett underval i en enda fråga som skickas till SAP HANA, och därför är det faktiskt inte så att alla data skulle läsas in innan du aggregerar ytterligare.
Alla dessa överväganden och beteenden kräver följande viktiga överväganden när du använder DirectQuery via SAP HANA som relationskälla:
All ytterligare aggregering som utförs i visuella objekt måste uppmärksammas när måttet i SAP HANA inte är additivt, till exempel inte en enkel Sum, Mineller Max.
I Hämta data eller Power Query-redigeraren ska endast nödvändiga kolumner inkluderas för att hämta nödvändiga data, vilket återspeglar det faktum att resultatet är en fråga som måste vara en rimlig fråga som kan skickas till SAP HANA. Om till exempel dussintals kolumner har valts i tron att de kan behövas i framtida visualiseringar, innebär även vid användning av DirectQuery att ett enkelt visuellt objekt kan betyda att den sammanställningsfråga som används i subselect innehåller dessa dussintals kolumner, vilket i allmänhet presterar dåligt och kan resultera i timeouts.
I följande exempel väljer du fem kolumner (CalendarQuarter, Color, LastName, ProductLine, SalesOrderNumber) i dialogrutan Hämta data. tillsammans med måttet OrderQuantityinnebär det att senare skapa ett enkelt visuellt objekt som innehåller Min OrderQuantity resulterar i följande SQL-fråga till SAP HANA. Den skuggade är underurvalet som innehåller frågan från Hämta data/Power Query Editor. Om denna subfråga ger ett resultat med hög kardinalitet, är det troligt att SAP HANA-prestandan blir dålig eller drabbas av tidsbegränsningar. Prestandapåverkan beror inte på att Power BI begär alla fält i undersökningen; de flesta av dessa fält projiceras bort av den yttre frågan. Effekten beror snarare på att åtgärder i underurvalet tvingar den att materialiseras i HANA-servern.

På grund av det här beteendet rekommenderar vi att de objekt som valts i Hämta data eller Power Query-redigeraren begränsas till de objekt som behövs, samtidigt som det resulterar i en rimlig fråga för SAP HANA. Om möjligt bör du överväga att återskapa alla nödvändiga mått i semantikmodellen och använda SAP HANA mer som en traditionell relationskälla.
Metodtips
För båda metoderna för att ansluta till SAP HANA följer du de allmänna rekommendationerna för att använda DirectQuery, särskilt rekommendationer som rör att säkerställa bra frågeprestanda. För mer information, se med DirectQuery i Power BI.
Överväganden och begränsningar
I följande lista beskrivs alla SAP HANA-funktioner som inte stöds fullt ut, eller funktioner som fungerar annorlunda när du använder Power BI.
- Hierarkier med överordnade och underordnade: Hierarkier med överordnade och underordnade visas inte i Power BI. Det beror på att Power BI har åtkomst till SAP HANA via SQL-gränssnittet och över- och underordnade hierarkier inte kan nås fullt ut via SQL.
- Andra hierarkimetadata: Den grundläggande strukturen för hierarkier visas i Power BI, men vissa hierarkimetadata, till exempel att styra beteendet för ojämna hierarkier, har ingen effekt. Detta beror återigen på begränsningar som införts av SQL-gränssnittet.
- Anslutning med SSL: Du kan ansluta med import och flerdimensionell med TLS, men kan inte ansluta till SAP HANA-instanser som konfigurerats för att använda TLS för relationsanslutningsmetoden.
- Stöd för attributvyer: Power BI kan ansluta till analys- och beräkningsvyer, men kan inte ansluta direkt till attributvyer.
- Stöd för katalogobjekt: Power BI kan inte ansluta till katalogobjekt.
- Ändra till variabler efter publicering: Du kan inte ändra värdena för några SAP HANA-variabler direkt i Power BI-tjänsten när rapporten har publicerats.
Kända problem
I följande lista beskrivs alla kända problem vid anslutning till SAP HANA (DirectQuery) med Power BI.
SAP HANA-problem vid frågan om räknare och andra mått: Felaktiga data returneras från SAP HANA om anslutning sker till en analysvy och ett räknarmått samt ett annat förhållandemått ingår i samma visuella objekt. Det här problemet omfattas av SAP Note 2128928 (oväntade resultat när du kör frågor mot en beräknad kolumn och en räknare). Ratio-måttet är felaktigt i det här fallet.
Flera Power BI-kolumner från en enda SAP HANA-kolumn: För vissa beräkningsvyer, där en SAP HANA-kolumn används i mer än en hierarki, exponerar SAP HANA kolumnen som två separata attribut. Den här metoden resulterar i att två kolumner skapas i Power BI. Dessa kolumner är dock dolda som standard och alla frågor som rör hierarkierna, eller kolumnerna direkt, fungerar korrekt.
Relaterat innehåll
Mer information om DirectQuery finns i följande resurser: