DirectQuery i Power BI
I Power BI Desktop eller Power BI-tjänst kan du ansluta till många olika datakällor på olika sätt. Du kan importera data till Power BI, vilket är det vanligaste sättet att hämta data. Du kan också ansluta direkt till vissa data i den ursprungliga källlagringsplatsen, som kallas DirectQuery. I den här artikeln beskrivs främst DirectQuery-funktioner.
I den här artikeln beskrivs:
- De olika alternativen för Power BI-dataanslutning.
- Vägledning om när du ska använda DirectQuery i stället för import.
- Begränsningar och konsekvenser av att använda DirectQuery.
- Rekommendationer för att använda DirectQuery.
- Så här diagnostiserar du prestandaproblem med DirectQuery.
Artikeln fokuserar på DirectQuery-arbetsflödet när du skapar en rapport i Power BI Desktop, men omfattar även anslutning via DirectQuery i Power BI-tjänst.
Kommentar
DirectQuery är också en funktion i SQL Server Analysis Services. Den funktionen delar många detaljer med Direct Query i Power BI, men det finns också viktiga skillnader. Den här artikeln beskriver främst DirectQuery med Power BI, inte SQL Server Analysis Services.
Mer information om hur du använder DirectQuery med SQL Server Analysis Services finns i Använda DirectQuery för Power BI-semantiska modeller och Analysis Services (förhandsversion). Du kan också ladda ned PDF DirectQuery i SQL Server 2016 Analysis Services.
Power BI-dataanslutningslägen
Power BI ansluter till ett stort antal olika datakällor, till exempel:
- Onlinetjänster som Salesforce och Dynamics 365.
- Databaser som SQL Server, Access och Amazon Redshift.
- Enkla filer i Excel, JSON och andra format.
- Andra datakällor som Spark, webbplatser och Microsoft Exchange.
Du kan importera data från dessa källor till Power BI. För vissa källor kan du också ansluta med DirectQuery. En sammanfattning av de källor som stöder DirectQuery finns i Datakällor som stöds av DirectQuery. DirectQuery-aktiverade källor är främst källor som kan leverera bra interaktiva frågeprestanda.
Du bör importera data till Power BI där det är möjligt. Import drar nytta av power BI:s högpresterande frågemotor och ger en mycket interaktiv, fullständigt aktuell upplevelse.
Om du inte kan uppfylla dina mål genom att importera data, till exempel om data ändras ofta och rapporter måste återspegla de senaste data, bör du överväga att använda DirectQuery. DirectQuery är endast möjligt när den underliggande datakällan kan ge interaktiva frågeresultat på mindre än fem sekunder för en typisk mängdfråga och kan hantera den genererade frågebelastningen. Överväg noggrant begränsningarna och konsekvenserna av att använda DirectQuery.
Power BI-import- och DirectQuery-funktioner utvecklas över tid. Med ändringar som ger större flexibilitet när du använder importerade data kan du importera oftare och eliminera några av nackdelarna med att använda DirectQuery. Oavsett förbättringar är prestanda för den underliggande datakällan ett stort övervägande när du använder DirectQuery. Om en underliggande datakälla är långsam förblir det omöjligt att använda DirectQuery för den källan.
Följande avsnitt beskriver de tre alternativen för att ansluta till data: import, DirectQuery och live-anslutning. Resten av artikeln fokuserar på DirectQuery.
Importera anslutningar
När du ansluter till en datakälla som SQL Server och importerar data i Power BI Desktop uppstår följande resultat:
När du först hämtar data definierar varje uppsättning tabeller som du väljer en fråga som returnerar en uppsättning data. Du kan redigera dessa frågor innan du läser in data, till exempel för att tillämpa filter, aggregera data eller ansluta olika tabeller.
Vid inläsning importeras alla data som definierats av frågorna till Power BI-cachen.
När du skapar ett visuellt objekt i Power BI Desktop efterfrågas cachelagrade data. Power BI Store säkerställer att frågan är snabb och att alla ändringar i det visuella objektet återspeglas omedelbart.
Visuella objekt återspeglar inte ändringar i underliggande data i datalagret. Du måste importera om för att uppdatera data.
När du publicerar rapporten till Power BI-tjänst som en .pbix-fil skapas och laddas en semantisk modell som innehåller importerade data. Sedan kan du schemalägga datauppdatering, till exempel importera data varje dag igen. Beroende på platsen för den ursprungliga datakällan kan det vara nödvändigt att konfigurera en lokal datagateway för uppdateringen.
Om du öppnar en befintlig rapport eller redigerar en ny rapport i Power BI-tjänst frågas importerade data igen, vilket säkerställer interaktivitet.
Du kan fästa visuella objekt eller hela rapportsidor som paneler på instrumentpanelen i Power BI-tjänst. Panelerna uppdateras automatiskt när den underliggande semantiska modellen uppdateras.
DirectQuery-anslutningar
När du använder DirectQuery för att ansluta till en datakälla i Power BI Desktop uppstår följande resultat:
Du använder Hämta data för att välja källan. För relationskällor kan du fortfarande välja en uppsättning tabeller som definierar en fråga som logiskt returnerar en uppsättning data. För flerdimensionella källor som SAP Business Warehouse (SAP BW) väljer du endast källan.
Vid inläsning importeras inga data till Power BI-arkivet. När du skapar ett visuellt objekt skickar Power BI Desktop i stället frågor till den underliggande datakällan för att hämta nödvändiga data. Hur lång tid det tar att uppdatera det visuella objektet beror på den underliggande datakällans prestanda.
Ändringar av underliggande data återspeglas inte omedelbart i befintliga visuella objekt. Det är fortfarande nödvändigt att uppdatera. Power BI Desktop skickar om de nödvändiga frågorna för varje visuellt objekt och uppdaterar det visuella objektet efter behov.
När du publicerar rapporten till Power BI-tjänst skapas och laddas en semantisk modell upp, samma som för import. Den semantiska modellen innehåller dock inga data.
Om du öppnar en befintlig rapport eller redigerar en ny rapport i Power BI-tjänst frågar den underliggande datakällan om du vill hämta nödvändiga data. Beroende på platsen för den ursprungliga datakällan kan det vara nödvändigt att konfigurera en lokal datagateway för att hämta data.
Du kan fästa visuella objekt eller hela rapportsidor som instrumentpaneler. För att säkerställa att det går snabbt att öppna en instrumentpanel uppdateras panelerna automatiskt enligt ett schema, till exempel varje timme. Du kan styra uppdateringsfrekvensen beroende på hur ofta data ändras och vikten av att se de senaste data.
När du öppnar en instrumentpanel återspeglar panelerna data vid tidpunkten för den senaste uppdateringen, inte nödvändigtvis de senaste ändringarna som gjorts i den underliggande källan. Du kan uppdatera en öppen instrumentpanel för att säkerställa att den är aktuell.
Live-anslutningar
När du ansluter till SQL Server Analysis Services kan du välja att importera data eller använda en live-anslutning till den valda datamodellen. Användning av en live-anslutning liknar DirectQuery. Inga data importeras och den underliggande datakällan efterfrågas för att uppdatera visuella objekt.
När du till exempel använder import för att ansluta till SQL Server Analysis Services definierar du en fråga mot den externa SQL Server Analysis Services-källan och importerar data. Om du ansluter live definierar du inte en fråga, och hela den externa modellen visas i fältlistan.
Den här situationen gäller även när du ansluter till följande källor, förutom att det inte finns något alternativ för att importera data:
Power BI-semantiska modeller, till exempel anslutning till en Power BI-semantisk modell som redan har publicerats till tjänsten, för att skapa en ny rapport över den.
Microsoft Dataverse.
När du publicerar SQL Server Analysis Services-rapporter som använder live-anslutningar liknar beteendet i Power BI-tjänst DirectQuery-rapporter på följande sätt:
Om du öppnar en befintlig rapport eller skapar en ny rapport i Power BI-tjänst frågar du den underliggande SQL Server Analysis Services-källan, vilket eventuellt kräver en lokal datagateway.
Paneler på instrumentpanelen uppdateras automatiskt enligt ett schema, till exempel varje timme.
En live-anslutning skiljer sig också från DirectQuery på flera sätt. Live-anslutningar skickar till exempel alltid identiteten för användaren som öppnar rapporten till den underliggande SQL Server Analysis Services-källan.
DirectQuery-användningsfall
Anslut med DirectQuery kan vara användbart i följande scenarier. I flera av dessa fall är det nödvändigt eller fördelaktigt att lämna data på den ursprungliga källplatsen.
DirectQuery i Power BI erbjuder de största fördelarna i följande scenarier:
- Data ändras ofta och du behöver nästan realtidsrapportering.
- Du måste hantera stora data utan att behöva föraggregera.
- Den underliggande källan definierar och tillämpar säkerhetsregler.
- Begränsningar för datasuveränitet gäller.
- Källan är en flerdimensionell källa som innehåller mått, till exempel SAP BW.
Data ändras ofta och du behöver nästan realtidsrapportering
Du kan uppdatera modeller med importerade data högst en gång per timme, oftare med Power BI Pro- eller Power BI Premium-prenumerationer. Om data ändras kontinuerligt, och det är nödvändigt för rapporter att visa de senaste data, kanske import med schemalagd uppdatering inte uppfyller dina behov. Du kan strömma data direkt till Power BI, även om det finns begränsningar för de datavolymer som stöds för det här fallet.
Att använda DirectQuery innebär att öppna eller uppdatera en rapport eller instrumentpanel alltid visar de senaste data i källan. Panelerna på instrumentpanelen kan också uppdateras oftare, så ofta som var 15:e minut.
Data är mycket stora
Om data är mycket stora är det inte möjligt att importera allt. DirectQuery kräver ingen stor dataöverföring eftersom den frågar efter data på plats. Men stora data kan också göra prestandan för frågor mot den underliggande källan för långsam.
Du behöver inte alltid importera fullständiga detaljerade data. Med Power Query-redigeraren är det enkelt att föraggregera data under importen. Tekniskt sett är det möjligt att importera exakt de aggregerade data som du behöver för varje visuellt objekt. Även om DirectQuery är den enklaste metoden för stora data kan import av aggregerade data erbjuda en lösning om den underliggande datakällan är för långsam för DirectQuery.
Den här informationen gäller enbart användning av Power BI. Mer information om hur du använder stora modeller i Power BI finns i stora semantiska modeller i Power BI Premium. Det finns ingen begränsning för hur ofta data kan uppdateras.
Den underliggande källan definierar säkerhetsregler
När du importerar data ansluter Power BI till datakällan med den aktuella användarens Power BI Desktop-autentiseringsuppgifter eller de autentiseringsuppgifter som konfigurerats för schemalagd uppdatering från Power BI-tjänst. När du publicerar och delar rapporter som har importerat data måste du vara noga med att bara dela med användare som får se data, eller så måste du definiera säkerhet på radnivå som en del av den semantiska modellen.
Med DirectQuery kan ett rapportvisningsprograms autentiseringsuppgifter överföras till den underliggande källan, vilket tillämpar säkerhetsregler. DirectQuery stöder enkel inloggning (SSO) till Azure SQL-datakällor och via en datagateway till lokala SQL-servrar. Mer information finns i Översikt över enkel inloggning (SSO) för gatewayer i Power BI.
Begränsningar för datasuveränitet gäller
Vissa organisationer har principer kring datasuveränitet, vilket innebär att data inte kan lämna organisationens lokaler. Dessa data presenterar problem för lösningar baserade på dataimport. Med DirectQuery finns data kvar på den underliggande källplatsen. Men även med DirectQuery behåller Power BI-tjänst vissa cacheminnen med data på visuell nivå på grund av schemalagd uppdatering av paneler.
Den underliggande datakällan använder mått
En underliggande datakälla som SAP HANA eller SAP BW innehåller mått. Mått innebär att importerade data redan är på en viss aggregeringsnivå, enligt definitionen i frågan. Ett visuellt objekt som frågar efter data på en aggregering på högre nivå, till exempel TotalFörsäljning perår, aggregerar ytterligare det aggregerade värdet. Den här aggregeringen är bra för additiva mått, till exempel Sum och Min, men kan vara ett problem för icke-additiva mått, till exempel Average och DistinctCount.
För att enkelt få rätt mängddata som behövs för ett visuellt objekt direkt från källan krävs att frågor skickas per visuellt objekt, som i DirectQuery. När du ansluter till SAP BW tillåter valet av DirectQuery den här behandlingen av mått. Mer information finns i DirectQuery och SAP BW.
DirectQuery över SAP HANA behandlar för närvarande data på samma sätt som en relationskälla och genererar ett beteende som liknar import. Mer information finns i DirectQuery och SAP HANA.
DirectQuery-begränsningar
Att använda DirectQuery har vissa potentiellt negativa konsekvenser. Vissa av dessa begränsningar skiljer sig något beroende på vilken källa du använder. I följande avsnitt visas allmänna konsekvenser av att använda DirectQuery och begränsningar relaterade till prestanda, säkerhet, omvandlingar, modellering och rapportering.
Allmänna konsekvenser
Några allmänna konsekvenser och begränsningar för användning av DirectQuery följer:
Om data ändras måste du uppdatera för att visa de senaste data. Med tanke på användningen av cacheminnen finns det ingen garanti för att visuella objekt alltid visar de senaste data. Ett visuellt objekt kan till exempel visa transaktioner under den senaste dagen. En utsnittsändring kan uppdatera det visuella objektet för att visa transaktioner under de senaste två dagarna, inklusive nyligen ankomna transaktioner. Men om utsnittet returneras till det ursprungliga värdet kan det resultera i att det återigen visar det cachelagrade tidigare värdet. Välj Uppdatera för att rensa alla cacheminnen och uppdatera alla visuella objekt på sidan för att visa de senaste data.
Om data ändras finns det ingen garanti för konsekvens mellan visuella objekt. Olika visuella objekt, oavsett om de finns på samma sida eller på olika sidor, kan uppdateras vid olika tidpunkter. Om data i den underliggande källan ändras finns det ingen garanti för att varje visuellt objekt visar data vid samma tidpunkt.
Eftersom mer än en fråga kan krävas för ett enskilt visuellt objekt, till exempel för att få information och summor, garanteras inte ens konsekvens i ett enda visuellt objekt. För att garantera den här konsekvensen skulle det kräva att du uppdaterar alla visuella objekt när ett visuellt objekt uppdateras, tillsammans med att använda kostsamma funktioner som ögonblicksbildisolering i den underliggande datakällan.
Du kan åtgärda det här problemet i stor utsträckning genom att välja Uppdatera för att uppdatera alla visuella objekt på sidan. Även för importläge finns det ett liknande problem med att upprätthålla konsekvens när du importerar data från mer än en tabell.
Du måste uppdatera i Power BI Desktop för att återspegla schemaändringar. När en rapport har publicerats uppdaterar Uppdatera i Power BI-tjänst de visuella objekten i rapporten. Men om det underliggande källschemat ändras uppdaterar Power BI-tjänst inte automatiskt listan över tillgängliga fält. Om tabeller eller kolumner tas bort från den underliggande källan kan det leda till frågefel vid uppdatering. Om du vill uppdatera fälten i modellen för att återspegla ändringarna måste du öppna rapporten i Power BI Desktop och välja Uppdatera.
En gräns på 1 miljon rader kan returneras för alla frågor. Det finns en fast gräns på 1 miljon rader som kan returneras i en enskild fråga till den underliggande källan. Den här gränsen har i allmänhet inga praktiska konsekvenser, och visuella objekt visar inte så många punkter. Gränsen kan dock inträffa i fall där Power BI inte helt optimerar de frågor som skickas och begär ett mellanliggande resultat som överskrider gränsen.
Gränsen kan också inträffa när du skapar ett visuellt objekt, på vägen till ett mer rimligt slutligt tillstånd. Till exempel kan inklusive Customer och TotalSalesQuantity nå den här gränsen om det finns fler än 1 miljon kunder, tills du tillämpar ett filter. Felet som returneras är: Resultatuppsättningen för en fråga till en extern datakälla har överskridit den maximala tillåtna storleken på raderna "1000000".
Kommentar
Med Premium-kapaciteter kan du överskrida gränsen på en miljon rader. Mer information finns i maximalt antal mellanliggande raduppsättningar.
Du kan inte ändra en modell från import till DirectQuery-läge. Du kan växla en modell från DirectQuery-läge till importläge om du importerar alla nödvändiga data. Det går inte att växla tillbaka till DirectQuery-läge, främst på grund av funktionsuppsättningen som DirectQuery-läget inte stöder. För flerdimensionella källor som SAP BW kan du inte heller växla från DirectQuery till importläge på grund av den olika behandlingen av externa mått.
Prestanda- och belastningskonsekvenser
När du använder DirectQuery beror den övergripande upplevelsen på den underliggande datakällans prestanda. Om det tar mindre än fem sekunder att uppdatera varje visuellt objekt, till exempel efter att du har ändrat ett utsnittsvärde, är upplevelsen rimlig, även om den kan kännas trög jämfört med det omedelbara svaret med importerade data. Om källans långsamhet gör att enskilda visuella objekt tar längre tid än tiotals sekunder att uppdatera blir upplevelsen orimligt dålig. Frågor kan till och med överskrida tidsgränsen.
Tillsammans med den underliggande källans prestanda påverkar även belastningen på källan prestanda. Varje användare som öppnar en delad rapport och varje panel på instrumentpanelen som uppdateras skickar minst en fråga per visuellt objekt till den underliggande källan. Källan måste kunna hantera en sådan frågebelastning samtidigt som rimlig prestanda bibehålls.
Säkerhetskonsekvenser
Om inte den underliggande datakällan använder enkel inloggning använder en DirectQuery-rapport alltid samma fasta autentiseringsuppgifter för att ansluta till källan när den har publicerats till Power BI-tjänst. Omedelbart efter att du har publicerat en DirectQuery-rapport måste du konfigurera användarens autentiseringsuppgifter att använda. Tills du konfigurerar autentiseringsuppgifterna resulterar det i ett fel när du försöker öppna rapporten i Power BI-tjänst.
När du har angett användarautentiseringsuppgifterna använder Power BI dessa autentiseringsuppgifter för den som öppnar rapporten, samma som för importerade data. Varje användare ser samma data, såvida inte säkerhet på radnivå definieras som en del av rapporten. Du måste vara uppmärksam på att dela rapporten som för importerade data, även om det finns säkerhetsregler som definierats i den underliggande källan.
Anslut ing till Power BI-semantiska modeller och Analysis Services i DirectQuery-läge använder alltid enkel inloggning, så säkerheten liknar liveanslutningar till Analysis Services.
Alternativa autentiseringsuppgifter stöds inte när du skapar DirectQuery-anslutningar till SQL Server från Power BI Desktop. Du kan använda dina aktuella Windows-autentiseringsuppgifter eller databasautentiseringsuppgifter.
Du kan använda flera datakällor i en DirectQuery-modell med hjälp av sammansatta modeller. När du använder flera datakällor är det viktigt att förstå säkerhetskonsekvenserna av hur data flyttas fram och tillbaka mellan de underliggande datakällorna.
Begränsningar för datatransformering
DirectQuery begränsar de datatransformeringar som du kan använda inom Power Query-redigeraren. Med importerade data kan du enkelt använda en avancerad uppsättning transformeringar för att rensa och omforma data innan du använder dem för att skapa visuella objekt. Du kan till exempel parsa JSON-dokument eller pivotera data från en kolumn till ett radformulär. Dessa transformeringar är mer begränsade i DirectQuery.
När du ansluter till en OLAP-källa (Online Analytical Processing) som SAP BW kan du inte definiera några transformeringar och hela den externa modellen hämtas från källan. För relationskällor som SQL Server kan du fortfarande definiera en uppsättning transformeringar per fråga, men dessa transformeringar är begränsade av prestandaskäl.
Alla transformeringar måste tillämpas på varje fråga på den underliggande källan i stället för en gång vid datauppdatering. Transformeringar måste rimligen kunna översättas till en enda intern fråga. Om du använder en transformering som är för komplex får du ett felmeddelande om att den antingen måste tas bort eller att anslutningsmodellen växlas till import.
Dialogrutan Hämta data eller Power Query-redigeraren använda undermarkeringar i de frågor som de genererar och skickar för att hämta data för ett visuellt objekt. Frågor som definierats i Power Query-redigeraren måste vara giltiga i den här kontexten. I synnerhet går det inte att använda en fråga med vanliga tabelluttryck eller en fråga som anropar lagrade procedurer.
Modelleringsbegränsningar
Termen modellering i det här sammanhanget innebär att förfina och berika rådata som en del av redigeringen av en rapport med hjälp av data. Exempel på modellering är:
- Definiera relationer mellan tabeller.
- Lägga till nya beräkningar, till exempel beräknade kolumner och mått.
- Byta namn på och dölja kolumner och mått.
- Definiera hierarkier.
- Definiera kolumnformatering, standardsammanfattning och sorteringsordning.
- Grupperings- eller klustringsvärden.
Du kan fortfarande göra många av dessa modellberikningar när du använder DirectQuery och använda principen om att berika rådata för att förbättra senare förbrukning. Vissa modelleringsfunktioner är dock inte tillgängliga eller är begränsade med DirectQuery. Begränsningarna tillämpas för att undvika prestandaproblem.
Följande begränsningar är gemensamma för alla DirectQuery-källor. Fler begränsningar kan gälla för enskilda källor.
Ingen inbyggd datumhierarki: Med importerade data har varje datum/datetime-kolumn också en inbyggd datumhierarki tillgänglig som standard. Om du till exempel importerar en tabell med försäljningsorder som innehåller en kolumn OrderDate och du använder OrderDate i ett visuellt objekt, kan du välja lämplig datumnivå att använda, till exempel år, månad eller dag. Den här inbyggda datumhierarkin är inte tillgänglig med DirectQuery. Om det finns en tillgänglig datumtabell i den underliggande källan, vilket är vanligt i många informationslager, kan du använda dax-tidsinformationsfunktionerna (Data Analysis Expressions) som vanligt.
Stöd för datum/tid endast till sekundnivå: För semantiska modeller som använder tidskolumner utfärdar Power BI frågor till den underliggande DirectQuery-källan endast upp till detaljnivån sekunder, inte millisekunder. Ta bort millisekundersdata från källkolumnerna.
Begränsningar i beräknade kolumner: Beräknade kolumner kan bara vara intrarad, dvs. de kan bara referera till värden för andra kolumner i samma tabell, utan att använda några aggregerade funktioner. Dessutom är de tillåtna DAX-skalärfunktionerna, till exempel
LEFT(), begränsade till de funktioner som kan push-överföras till den underliggande källan. Funktionerna varierar beroende på källans exakta funktioner. Funktioner som inte stöds visas inte i komplettera automatiskt när du redigerar DAX-frågan för en beräknad kolumn och resulterar i ett fel om det används.Inget stöd för överordnade och underordnade DAX-funktioner: När du är i DirectQuery-läge går det inte att använda de funktioner
DAX PATH()som vanligtvis hanterar överordnade och underordnade strukturer, till exempel diagram över konton eller medarbetarhierarkier.Ingen klustring: När du använder DirectQuery kan du inte använda klustringsfunktionen för att automatiskt hitta grupper.
Rapporteringsbegränsningar
Nästan alla rapporteringsfunktioner stöds för DirectQuery-modeller. Så länge den underliggande källan har en lämplig prestandanivå kan du använda samma uppsättning visualiseringar som för importerade data.
En allmän begränsning är att den maximala längden på data i en textkolumn för DirectQuery-semantiska modeller är 32 764 tecken. Rapportering av längre texter resulterar i ett fel.
Följande Power BI-rapporteringsfunktioner kan orsaka prestandaproblem i DirectQuery-baserade rapporter:
Måttfilter: Visuella objekt som använder mått eller aggregeringar av kolumner kan innehålla filter i dessa mått. Följande bild visar till exempel SalesAmount efter kategori, men endast för kategorier med mer än 20 miljoner försäljningar.
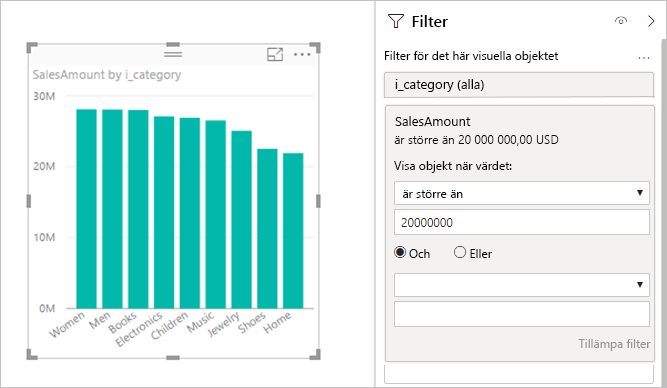
Den här metoden gör att två frågor skickas till den underliggande källan:
- Den första frågan hämtar de kategorier som uppfyller villkoret SalesAmount som är större än 20 miljoner.
- Den andra frågan hämtar nödvändiga data för det visuella objektet, som innehåller de kategorier som uppfyllde villkoret
WHERE.
Den här metoden fungerar vanligtvis bra om det finns hundratals eller tusentals kategorier, som i det här exemplet. Prestanda kan försämras om antalet kategorier är mycket större. Frågan misslyckas om det finns fler än en miljon kategorier.
TopN-filter: Du kan definiera avancerade filter för att endast filtrera på de översta eller nedre
Nvärdena rangordnade efter något mått. Filter kan till exempel innehålla de 10 främsta kategorierna. Den här metoden skickar återigen två frågor till den underliggande källan. Den första frågan returnerar dock alla kategorier från den underliggande källan och sedan bestäms deTopNbaserat på de returnerade resultaten. Beroende på kardinaliteten i den aktuella kolumnen kan den här metoden leda till prestandaproblem eller frågefel på grund av gränsen på en miljon rader för frågeresultat.Median: Alla aggregeringar, till exempel
SumellerCount Distinct, skickas till den underliggande källan. Men vanligtvismedianstöds inte aggregeringen av den underliggande källan. Förmedianhämtas informationsdata från den underliggande källan och medianen beräknas utifrån de returnerade resultaten. Den här metoden är rimlig för att beräkna medianvärdet över ett relativt litet antal resultat.Prestandaproblem eller frågefel kan uppstå om kardinaliteten är stor på grund av radgränsen på en miljon. Det kan till exempel vara rimligt att fråga efter medianland/regionpopulation , men medianförsäljningspriset kanske inte är rimligt.
Avancerade textfilter som "contains": Avancerad filtrering i en textkolumn tillåter filter som
containsochbegins with. Dessa filter kan resultera i försämrade prestanda för vissa datakällor. Använd i synnerhet inte standardfiltretcontainsom du behöver en exakt matchning. Även om resultatet kan vara detsamma beroende på faktiska data, kan prestandan vara drastiskt annorlunda på grund av index.Utsnitt med flera val: Som standard tillåter utsnitt endast att göra en enda markering. Om du tillåter flera val i filter kan det orsaka prestandaproblem. Om användaren till exempel väljer 10 produkter av intresse resulterar varje nytt val i att frågor skickas till källan. Även om användaren kan välja nästa objekt innan frågan slutförs, resulterar den här metoden i extra belastning på den underliggande källan.
Summor i visuella tabellobjekt: Som standard visar tabeller och matriser summor och delsummor. I många fall måste separata frågor skickas till den underliggande källan för att hämta värdena för sådana summor. Det här kravet gäller när du använder
DistinctCountaggregering eller i alla fall som använder DirectQuery via SAP BW eller SAP HANA. Du kan stänga av sådana summor med hjälp av fönstret Format .
DirectQuery-rekommendationer
Det här avsnittet innehåller vägledning på hög nivå om hur du använder DirectQuery, med tanke på dess konsekvenser.
Prestanda för underliggande datakälla
Verifiera att enkla visuella objekt uppdateras inom fem sekunder för att ge en rimlig interaktiv upplevelse. Om det tar längre tid än 30 sekunder att uppdatera visuella objekt är det troligt att ytterligare problem efter rapportpublicering gör lösningen ogenomförbar.
Om frågorna är långsamma undersöker du de frågor som skickas till den underliggande källan och orsaken till den långsamma prestandan. Mer information finns i Prestandadiagnostik.
Den här artikeln beskriver inte det breda utbudet av rekommendationer för databasoptimering i hela uppsättningen potentiella underliggande källor. Följande standarddatabasmetoder gäller för de flesta situationer:
För bättre prestanda kan du basera relationer på heltalskolumner i stället för att koppla kolumner av andra datatyper.
Skapa lämpliga index. Indexskapande innebär vanligtvis att använda kolumnlagringsindex i källor som stöder dem, till exempel SQL Server.
Uppdatera all nödvändig statistik i källan.
Modelldesign
När du definierar modellen följer du den här vägledningen:
Undvik komplexa frågor i Power Query-redigeraren. Power Query-redigeraren översätter en komplex fråga till en enda SQL-fråga. Den enskilda frågan visas i undermarkeringen för varje fråga som skickas till tabellen. Om frågan är komplex kan det leda till prestandaproblem för varje fråga som skickas. Du kan hämta den faktiska SQL-frågan för en uppsättning steg genom att högerklicka på det sista steget under Tillämpade steg i Power Query-redigeraren och välja Visa intern fråga.
Håll måtten enkla. Begränsa måtten till enkla aggregeringar, åtminstone till en början. Om åtgärderna fungerar på ett tillfredsställande sätt kan du definiera mer komplexa mått, men vara uppmärksam på prestanda.
Undvik relationer på beräknade kolumner. I databaser där du behöver göra flerkolumnskopplingar tillåter Power BI inte att relationer baseras på flera kolumner som primärnyckel eller sekundärnyckel. Den vanliga lösningen är att sammanfoga kolumnerna med hjälp av en beräknad kolumn och basera kopplingen på den kolumnen.
Den här lösningen är rimlig för importerade data, men för DirectQuery resulterar det i en koppling i ett uttryck. Det här resultatet förhindrar vanligtvis användning av index och leder till dåliga prestanda. Den enda lösningen är att materialisera flera kolumner i en enda kolumn i den underliggande datakällan.
Undvik relationer i kolumner med "uniqueidentifier". Power BI har inte inbyggt stöd för en
uniqueidentifierdatatyp. Om du definierar en relation mellanuniqueidentifierkolumner resulterar det i en fråga med en koppling som involverar en rollbesättning. Återigen leder den här metoden ofta till dåliga prestanda. Den enda lösningen är att materialisera kolumner av en alternativ typ i den underliggande datakällan.Dölj kolumnen "till" för relationer. Kolumnen
toför relationer är vanligtvis den primära nyckeln itotabellen. Kolumnen ska vara dold, men om den är dold visas den inte i fältlistan och kan inte användas i visuella objekt. Ofta är de kolumner som relationer baseras på i själva verket systemkolumner, till exempel surrogatnycklar i ett informationslager. Det är fortfarande bäst att dölja sådana kolumner.Om kolumnen har betydelse introducerar du en beräknad kolumn som är synlig och som har ett enkelt uttryck för att vara lika med primärnyckeln, till exempel:
ProductKey_PK (Destination of a relationship, hidden) ProductKey (= [ProductKey_PK], visible) ProductName ...Granska alla beräknade kolumner och ändringar av datatypen. Du kan använda beräknade tabeller när du använder DirectQuery med sammansatta modeller. De här funktionerna är inte nödvändigtvis skadliga, men de resulterar i frågor som innehåller uttryck snarare än enkla referenser till kolumner. Dessa frågor kan leda till att index inte används.
Undvik dubbelriktad korsfiltrering på relationer. Dubbelriktad korsfiltrering kan leda till frågeinstruktioner som inte fungerar bra. Mer information om dubbelriktad korsfiltrering finns i Aktivera dubbelriktad korsfiltrering för DirectQuery i Power BI Desktop eller ladda ned vitboken dubbelriktad korsfiltrering . Exemplen i dokumentet är för SQL Server Analysis Services, men de grundläggande punkterna gäller även för Power BI.
Experimentera med inställningen Anta referensintegritet. Inställningen Anta referensintegritet för relationer gör att frågor kan använda
INNER JOINsnarare änOUTER JOINinstruktioner. Den här vägledningen förbättrar vanligtvis frågeprestanda, även om den beror på datakällans specifika egenskaper.Använd inte relativ datafiltrering i Power Query-redigeraren. Det går att definiera relativ datumfiltrering i Power Query-redigeraren. Du kan till exempel filtrera till de rader där datumet är under de senaste 14 dagarna.
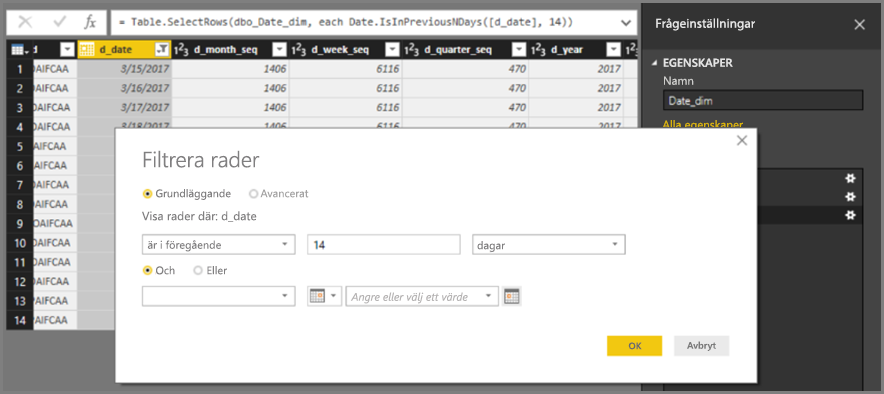
Det här filtret översätts dock till ett filter baserat på ett fast datum, till exempel den tid då frågan skapades, som du kan se i den interna frågan.

Dessa data är förmodligen inte vad du vill ha. Använd datumfiltret i rapporten för att säkerställa att filtret tillämpas baserat på datumet då rapporten körs. Du kan skapa en beräknad kolumn som beräknar antalet dagar sedan med hjälp av funktionen och använda den
DAX DATE()beräknade kolumnen i filtret.
Rapportdesign
När du skapar en rapport som använder en DirectQuery-anslutning följer du den här vägledningen:
Överväg att använda alternativ för frågeminskning: Power BI tillhandahåller rapportalternativ för att skicka färre frågor och för att inaktivera vissa interaktioner som orsakar en dålig upplevelse om de resulterande frågorna tar lång tid att köra. De här alternativen gäller när du interagerar med rapporten i Power BI Desktop och även när användarna använder rapporten i Power BI-tjänst.
Om du vill komma åt de här alternativen i Power BI Desktop går du till Filalternativ>och inställningar>Alternativ och väljer Frågereduktion.
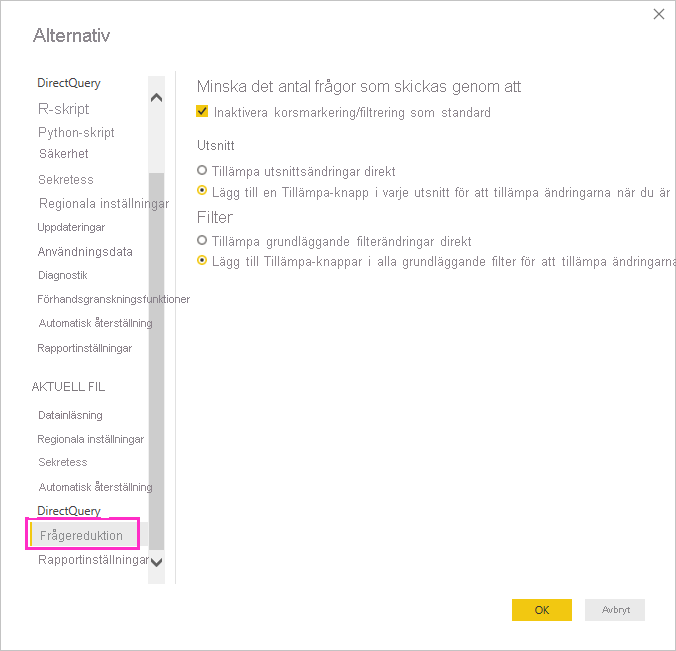
Med val på skärmen Frågereduktion kan du visa knappen Tillämpa för utsnitt eller filterval. Inga frågor skickas förrän du väljer knappen Tillämpa i filtret eller utsnittet. Frågorna använder sedan dina val för att filtrera data. Med den här knappen kan du göra flera utsnitts- och filterval innan du tillämpar dem.
Använd filter först: Använd alltid alla tillämpliga filter i början av skapandet av ett visuellt objekt. I stället för att till exempel dra i TotalSalesAmount och ProductName och sedan filtrera till ett visst år använder du filtret på År i början.
Varje steg för att skapa ett visuellt objekt skickar en fråga. Även om det är möjligt att göra en ny ändring innan den första frågan har slutförts, lämnar den här metoden fortfarande onödig belastning på den underliggande källan. Att använda filter tidigt gör vanligtvis dessa mellanliggande frågor mindre kostsamma. Om du inte tillämpar filter tidigt kan det leda till att gränsen på en miljon rader nås.
Begränsa antalet visuella objekt på en sida: När du öppnar en sida eller ändrar ett utsnitt eller filter på sidnivå uppdateras alla visuella objekt på sidan. Det finns en gräns för antalet parallella frågor. När antalet visuella objekt ökar uppdateras vissa visuella objekt seriellt, vilket ökar den tid det tar att uppdatera sidan. Därför är det bäst att begränsa antalet visuella objekt på en enda sida och i stället ha fler, enklare sidor.
Överväg att stänga av interaktion mellan visuella objekt: Som standard kan visualiseringar på en rapportsida användas för att korsfiltrera och korsmarkera de andra visualiseringarna på sidan. Om du till exempel väljer 1999 i cirkeldiagrammet korsmarkeras kolumndiagrammet för att visa försäljningen efter kategori för 1999.
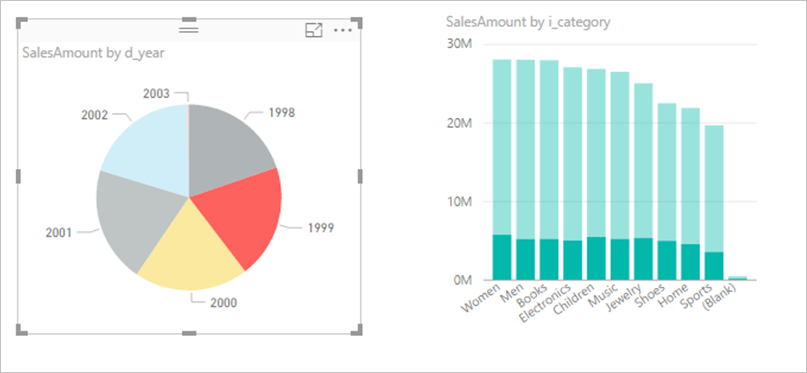
Korsfiltrering och korsmarkering i DirectQuery kräver att frågor skickas till den underliggande källan. Du bör stänga av den här interaktionen om den tid det tar att svara på användarnas val är orimligt lång.
Du kan använda inställningarna för frågereduktion för att inaktivera korsmarkering i hela rapporten eller från fall till fall. Mer information finns i Hur visuella objekt korsfiltrerar varandra i en Power BI-rapport.
Maximalt antal anslutningar
Du kan ange det maximala antalet anslutningar som DirectQuery öppnar för varje underliggande datakälla, vilket styr antalet frågor som skickas samtidigt till varje datakälla.
DirectQuery öppnar ett maximalt standardantal på 10 samtidiga anslutningar. Om du vill ändra det maximala antalet för den aktuella filen i Power BI Desktop går du till Filalternativ>och Inställningar> Alternativ och väljer DirectQuery i avsnittet Aktuell fil i det vänstra fönstret.
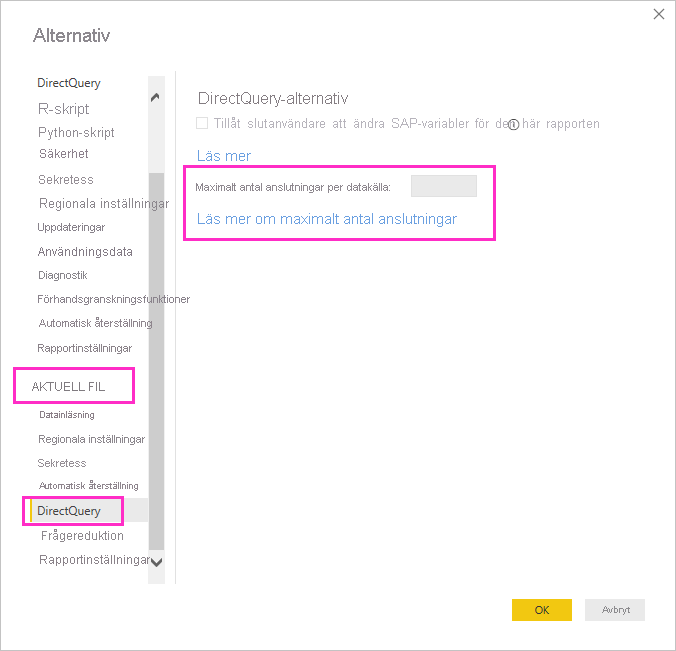
Inställningen aktiveras endast när det finns minst en DirectQuery-källa i den aktuella rapporten. Värdet gäller för alla DirectQuery-källor och för alla nya DirectQuery-källor som läggs till i rapporten.
Om du ökar Maximalt antal anslutningar per datakälla kan du skicka fler frågor, upp till det maximala antal som angetts, till den underliggande datakällan. Den här metoden är användbar när många visuella objekt finns på en enda sida eller många användare får åtkomst till en rapport samtidigt. När det maximala antalet anslutningar har nåtts placeras ytterligare frågor i kö tills en anslutning blir tillgänglig. En högre gräns resulterar i mer belastning på den underliggande källan, så inställningen är inte garanterad för att förbättra den övergripande prestandan.
När du publicerar en rapport till Power BI-tjänst beror det maximala antalet samtidiga frågor också på fasta gränser som angetts för målmiljön där rapporten publiceras. Power BI, Power BI Premium och Power BI-rapportserver införa olika gränser. Tabellen nedan visar de övre gränserna för de aktiva anslutningarna per datakälla för varje Power BI-miljö. Dessa gränser gäller för molndatakällor och lokala datakällor som SQL Server, Oracle och Teradata.
| Environment | Övre gräns per datakälla |
|---|---|
| Power BI Pro | 10 aktiva anslutningar |
| Power BI Premium | Beror på SKU-begränsning för semantisk modell |
| Power BI-rapportserver | 10 aktiva anslutningar |
Kommentar
Det maximala antalet DirectQuery-anslutningar gäller för alla DirectQuery-källor när du aktiverar förbättrade metadata, vilket är standardinställningen för alla modeller som skapats i Power BI Desktop.
DirectQuery i Power BI-tjänst
Alla DirectQuery-datakällor stöds från Power BI Desktop och vissa källor är också tillgängliga direkt från Power BI-tjänst. En företagsanvändare kan till exempel använda Power BI för att ansluta till sina data i Salesforce och omedelbart hämta en instrumentpanel utan att använda Power BI Desktop.
Endast följande två DirectQuery-aktiverade källor är tillgängliga direkt i Power BI-tjänst:
- Spark
- Azure Synapse Analytics (tidigare SQL Data Warehouse)
Även för dessa två källor är det fortfarande bäst att starta DirectQuery-användning i Power BI Desktop. Det är enkelt att först upprätta anslutningen i Power BI-tjänst, men det finns begränsningar för att ytterligare förbättra den resulterande rapporten. I tjänsten går det till exempel inte att skapa några beräkningar, använda många analytiska funktioner eller uppdatera metadata för att återspegla ändringar i det underliggande schemat.
Prestandan för en DirectQuery-rapport i Power BI-tjänst beror på vilken belastning som läggs på den underliggande datakällan. Belastningen beror på:
- Antalet användare som delar rapporten och instrumentpanelen.
- Rapportens komplexitet.
- Om rapporten definierar säkerhet på radnivå.
Rapportbeteende i Power BI-tjänst
När du öppnar en rapport i Power BI-tjänst uppdateras alla visuella objekt på den aktuella sidan. Varje visuellt objekt kräver minst en fråga till den underliggande datakällan. Vissa visuella objekt kan kräva mer än en fråga. Ett visuellt objekt kan till exempel visa aggregerade värden från två olika faktatabeller, eller innehålla ett mer komplext mått eller innehålla summor av ett icke-additivt mått som Count Distinct. Om du flyttar till en ny sida uppdateras de visuella objekten. Uppdatering skickar en ny uppsättning frågor till den underliggande källan.
Varje användarinteraktion i rapporten kan leda till att visuella objekt uppdateras. Om du till exempel väljer ett annat värde i ett utsnitt måste du skicka en ny uppsättning frågor för att uppdatera alla berörda visuella objekt. Detsamma gäller för att välja ett visuellt objekt för att korsmarkera andra visuella objekt eller ändra ett filter. På samma sätt kräver skapandet eller redigeringen av en rapport att frågor skickas för varje steg på sökvägen för att skapa det slutliga visuella objektet.
Det finns viss cachelagring av resultat. Uppdateringen av ett visuellt objekt sker omedelbart om exakt samma resultat nyligen erhölls. Om säkerhet på radnivå definieras delas inte dessa cacheminnen mellan användare.
Att använda DirectQuery medför några viktiga begränsningar i vissa av funktionerna som Power BI-tjänst erbjuder för publicerade rapporter:
Snabbinsikter stöds inte: Snabbinsikter i Power BI söker i olika delmängder av din semantiska modell samtidigt som en uppsättning avancerade algoritmer används för att identifiera potentiellt intressanta insikter. Eftersom snabbinsikter kräver frågor med höga prestanda är den här funktionen inte tillgänglig på semantiska modeller som använder DirectQuery.
Om du använder Utforska i Excel får du dåliga prestanda: Du kan utforska en semantisk modell med hjälp av funktionen Utforska i Excel , där du kan skapa pivottabeller och pivotdiagram i Excel. Den här funktionen stöds för semantiska modeller som använder DirectQuery, men prestanda är långsammare än att skapa visuella objekt i Power BI. Om det är viktigt att använda Excel för dina scenarier kan du ta hänsyn till det här problemet när du bestämmer om du vill använda DirectQuery.
Excel visar inte hierarkier: När du till exempel använder Analysera i Excel visas inga hierarkier som definierats i Azure Analysis Services-modeller eller Power BI-semantiska modeller som använder DirectQuery.
Uppdatering av instrumentpanel
I Power BI-tjänst kan du fästa enskilda visuella objekt eller hela sidor på instrumentpaneler som paneler. Paneler som baseras på DirectQuery-semantiska modeller uppdateras automatiskt genom att skicka frågor till de underliggande datakällorna enligt ett schema. Som standard uppdateras semantiska modeller varje timme, men du kan konfigurera uppdatering mellan varje vecka och var 15:e minut som en del av semantiska modellinställningar.
Om ingen säkerhet på radnivå definieras i modellen uppdateras varje panel en gång och resultaten delas mellan alla användare. Om du använder säkerhet på radnivå kräver varje panel att separata frågor per användare skickas till den underliggande källan.
Det kan finnas en stor multiplikatoreffekt. En instrumentpanel med 10 paneler, som delas med 100 användare, som skapats på en semantisk modell med DirectQuery med säkerhet på radnivå, resulterar i att minst 1 000 frågor skickas till den underliggande datakällan för varje uppdatering. Tänk noga på användningen av säkerhet på radnivå och konfigurationen av uppdateringsschemat.
Timeout för frågor
En tidsgräns på fyra minuter gäller för enskilda frågor i Power BI-tjänst. Frågor som tar längre tid än fyra minuter misslyckas. Den här gränsen är avsedd att förhindra problem som orsakas av alltför långa körningstider. Du bör endast använda DirectQuery för källor som kan ge interaktiva frågeprestanda.
Prestandadiagnostik
I det här avsnittet beskrivs hur du diagnostiserar prestandaproblem eller hur du får mer detaljerad information för att optimera dina rapporter.
Börja diagnostisera prestandaproblem i Power BI Desktop i stället för i Power BI-tjänst. Prestandaproblem baseras ofta på den underliggande källans prestanda. Du kan enklare identifiera och diagnostisera problem i den mer isolerade Power BI Desktop-miljön.
Den här metoden eliminerar inledningsvis vissa komponenter, till exempel Power BI-gatewayen. Om prestandaproblemen inte uppstår i Power BI Desktop kan du undersöka detaljerna i rapporten i Power BI-tjänst.
Prestandaanalysverktyget för Power BI Desktop är ett användbart verktyg för att identifiera problem. Försök att isolera eventuella problem till ett visuellt objekt i stället för många visuella objekt på en sida. Om ett enskilt visuellt objekt på en Power BI Desktop-sida är trögt använder du prestandaanalysen för att analysera de frågor som Power BI Desktop skickar till den underliggande källan.
Du kan också visa spårningar och diagnostikinformation som vissa underliggande datakällor genererar. Även om det inte finns några spårningar från källan kan spårningsfilen innehålla användbar information om hur en fråga körs och hur du kan förbättra den. Du kan använda följande process för att visa de frågor som Power BI skickar och deras körningstider.
Använda SQL Server Profiler för att se frågor
Som standard loggar Power BI Desktop händelser under en viss session till en spårningsfil med namnet FlightRecorderCurrent.trc. Spårningsfilen finns i Power BI Desktop-mappen för den aktuella användaren, i en mapp med namnet AnalysisServicesWorkspaces.
För vissa DirectQuery-källor innehåller den här spårningsfilen alla frågor som skickas till den underliggande datakällan. Följande datakällor skickar frågor till loggen:
- SQL Server
- Azure SQL Database
- Azure Synapse Analytics (tidigare SQL Data Warehouse)
- Oracle
- Teradata
- SAP HANA
Du kan läsa spårningsfilerna med hjälp av SQL Server Profiler, som är en del av den kostnadsfria nedladdningen av SQL Server Management Studio.
Så här öppnar du spårningsfilen för den aktuella sessionen:
Under en Power BI Desktop-session väljer du Alternativ för filalternativ>och inställningar> och sedan Diagnostik.
Under Kraschdumpsamling väljer du Öppna kraschdump/spårningsmapp.
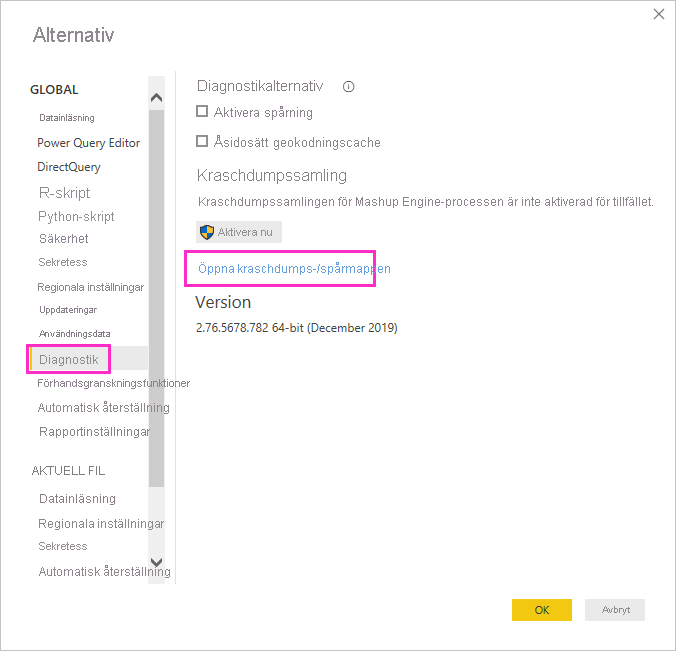
Mappen Power BI Desktop\Traces öppnas.
Gå till den överordnade mappen och sedan till mappen AnalysisServicesWorkspaces , som innehåller en arbetsytemapp för varje öppen instans av Power BI Desktop. Dessa mappar namnges med ett heltalssuffix, till exempel AnalysisServicesWorkspace2058279583. Arbetsytans mapp tas bort när den associerade Power BI Desktop-sessionen avslutas.
I arbetsytans mapp för den aktuella Power BI-sessionen innehåller mappen \Data spårningsfilen FlightRecorderCurrent.trc . Gör en notering av plats.
Öppna SQL Server Profiler och välj Arkiv Öppna>spårningsfil.>
Navigera till eller ange sökvägen till spårningsfilen för den aktuella Power BI-sessionen och öppna FlightRecorderCurrent.trc.
SQL Server Profiler visar alla händelser från den aktuella sessionen. Följande skärmbild visar en grupp händelser för en fråga. Varje frågegrupp har följande händelser:
En
Query Beginhändelse somQuery Endrepresenterar början och slutet av en DAX-fråga som genereras genom att ändra ett visuellt objekt eller filter i Power BI-användargränssnittet, eller från filtrering eller transformering av data i Power Query-redigeraren.Ett eller flera par
DirectQuery Beginmed ochDirectQuery Endhändelser, som representerar frågor som skickas till den underliggande datakällan som en del av utvärderingen av DAX-frågan.

Flera DAX-frågor kan köras parallellt, så händelser från olika grupper kan interfolieras. Du kan använda värdet ActivityID för att avgöra vilka händelser som tillhör samma grupp.
Följande kolumner är också av intresse:
- TextData: Textinformationen om händelsen. För
Query BeginochQuery Endhändelser är informationen DAX-frågan. FörDirectQuery BeginochDirectQuery Endhändelser är informationen den SQL-fråga som skickas till den underliggande källan. TextData för den markerade händelsen visas också i fönstret längst ned på skärmen. - EndTime: Tiden då händelsen slutfördes.
- Varaktighet: Varaktigheten i millisekunder tog det att köra DAX- eller SQL-frågan.
- Fel: Om ett fel inträffade, i vilket fall händelsen också visas i rött.
Så här samlar du in en spårning för att diagnostisera ett potentiellt prestandaproblem:
Öppna en enda Power BI Desktop-session för att undvika förvirring i flera arbetsytemappar.
Utför de åtgärder som är intressanta i Power BI Desktop. Inkludera några fler åtgärder för att säkerställa att händelser av intresse töms i spårningsfilen.
Öppna SQL Server Profiler och granska spårningen. Kom ihåg att om du stänger Power BI Desktop tas spårningsfilen bort. Dessutom visas inte ytterligare åtgärder i Power BI Desktop omedelbart. Du måste stänga och öppna spårningsfilen igen för att se nya händelser.
Håll enskilda sessioner någorlunda små, kanske 10 sekunders åtgärder, inte hundratals. Den här metoden gör det enklare att tolka spårningsfilen. Det finns också en gräns för spårningsfilens storlek. För långa sessioner finns det en risk att tidiga händelser tas bort.
Förstå formatet på frågor
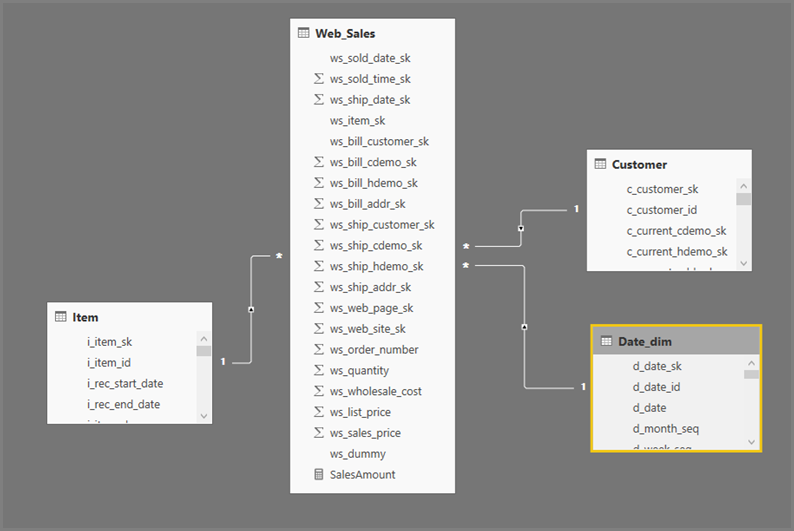
Det allmänna formatet för Power BI Desktop-frågor använder undermarkeringar för varje tabell som de refererar till. Den Power Query-redigeraren frågan definierar undervalsfrågorna. Anta till exempel att du har följande TPC-DS-tabeller i SQL Server:
Kör följande fråga:
SalesAmount (SUMX(Web_Sales, [ws_sales_price]*[ws_quantity]))
by Item[i_category]
for Date_dim[d_year] = 2000
Resulterar i följande visuella objekt i Power BI:
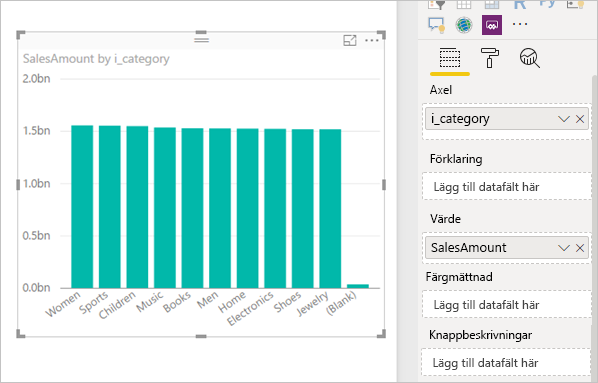
När du uppdaterar det visuella objektet skapas SQL-frågan i följande bild. Det finns tre undervalsfrågor för Web_Sales, Itemoch , som var och Date_dimen returnerar alla kolumner i respektive tabell, även om det visuella objektet endast refererar till fyra kolumner.
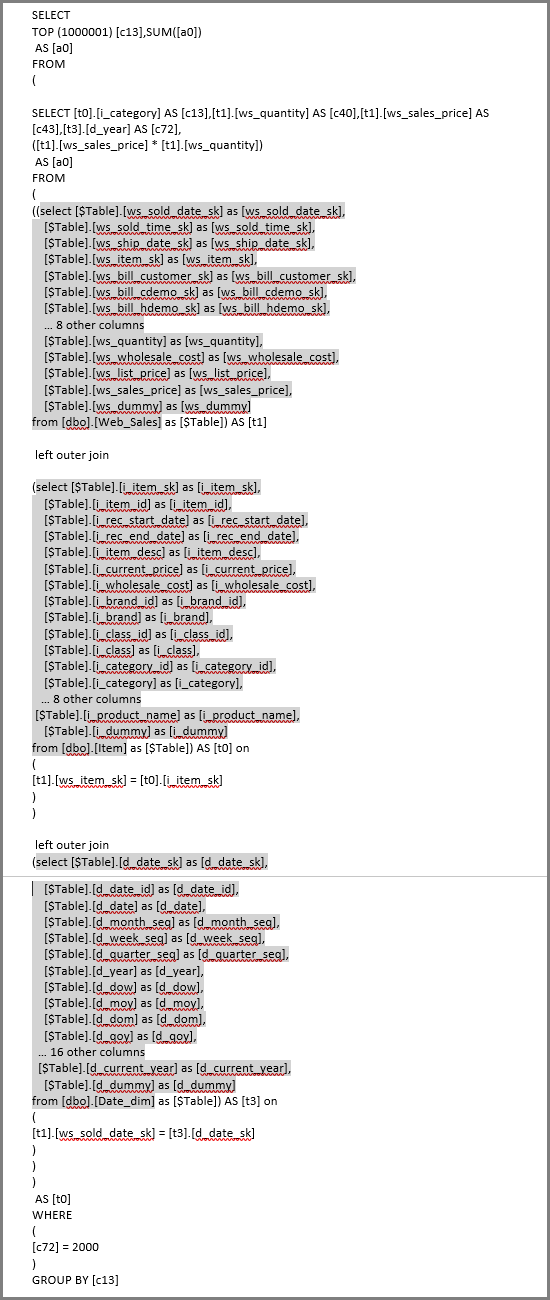
Power Query-redigeraren definierar de exakta undervalsfrågorna. Den här användningen av undervalsfrågor har inte visats påverka prestanda för de datakällor som DirectQuery stöder. Datakällor som SQL Server optimerar bort referenserna till de andra kolumnerna.
Power BI använder det här mönstret eftersom analytikern tillhandahåller SQL-frågan direkt. Power BI använder frågan som den tillhandahålls, utan att försöka skriva om den.
Relaterat innehåll
Mer information om DirectQuery i Power BI finns i:
I den här artikeln beskrivs aspekter av DirectQuery som är vanliga i alla datakällor. Mer information om specifika källor finns i följande artiklar: