Vägledning för många-till-många-relationer
Den här artikeln riktar sig till dig som datamodellerare som arbetar med Power BI Desktop. Den beskriver tre olika modelleringsscenarier för många-till-många. Det ger dig också vägledning om hur du utformar dem i dina modeller.
Kommentar
En introduktion till modellrelationer beskrivs inte i den här artikeln. Om du inte är helt bekant med relationer, deras egenskaper eller hur du konfigurerar dem rekommenderar vi att du först läser artikeln Modellrelationer i Power BI Desktop .
Det är också viktigt att du har en förståelse för star-schemadesign. Mer information finns i Förstå star-schema och vikten för Power BI.
Det finns faktiskt tre många-till-många-scenarier. De kan inträffa när du måste:
- Relatera två tabeller av dimensionstyp
- Relatera två tabeller av faktatyp
- Relatera tabeller av faktatyp med högre kornighet, när tabellen av faktatyp lagrar rader med ett högre korn än tabellrader av dimensionstyp
Kommentar
Power BI har nu inbyggt stöd för många-till-många-relationer. Mer information finns i Tillämpa många-många-relationer i Power BI Desktop.
Relatera många-till-många-dimensioner
Låt oss överväga den första typen av många-till-många-scenario med ett exempel. Det klassiska scenariot relaterar två entiteter: bankkunder och bankkonton. Tänk på att kunder kan ha flera konton och att konton kan ha flera kunder. När ett konto har flera kunder kallas de ofta för gemensamma kontoinnehavare.
Modellering av dessa entiteter är rättframt. En tabell av dimensionstyp lagrar konton och en annan tabell av dimensionstyp lagrar kunder. Som är kännetecknande för tabeller av dimensionstyp finns det en ID-kolumn i varje tabell. För att modellera relationen mellan de två tabellerna krävs en tredje tabell. Den här tabellen kallas ofta för en bryggningstabell. I det här exemplet är syftet att lagra en rad för varje kundkontoassociation. Intressant nog, när den här tabellen bara innehåller ID-kolumner, kallas den en faktalös faktatabell.
Här är ett förenklat modelldiagram över de tre tabellerna.
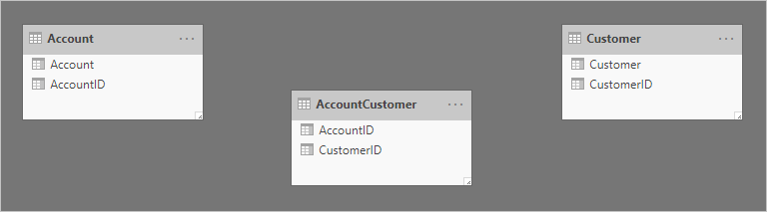
Den första tabellen heter Konto och innehåller två kolumner: AccountID och Konto. Den andra tabellen heter AccountCustomer och innehåller två kolumner: AccountID och CustomerID. Den tredje tabellen heter Kund och innehåller två kolumner: CustomerID och Customer. Relationer finns inte mellan någon av tabellerna.
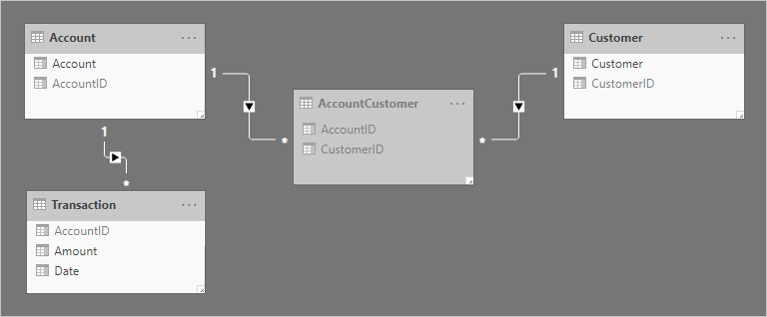
Två en-till-många-relationer läggs till för att relatera tabellerna. Här är ett uppdaterat modelldiagram över de relaterade tabellerna. En tabell av faktatyp med namnet Transaction har lagts till. Den registrerar kontotransaktioner. Bryggningstabellen och alla ID-kolumner har dolts.
För att beskriva hur relationsfilterspridningen fungerar har modelldiagrammet ändrats för att visa tabellraderna.
Kommentar
Det går inte att visa tabellrader i Power BI Desktop-modelldiagrammet. Det görs i den här artikeln för att stödja diskussionen med tydliga exempel.

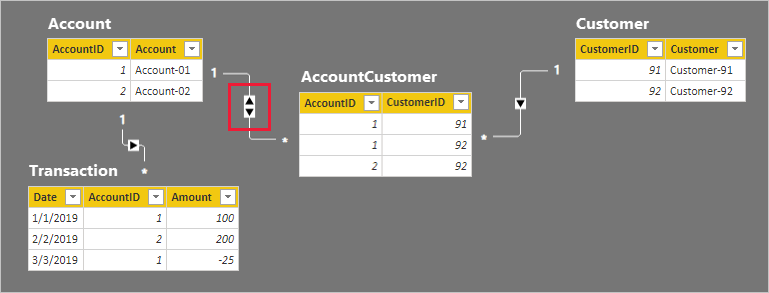
Radinformationen för de fyra tabellerna beskrivs i följande punktlista:
- Tabellen Konto har två rader:
- AccountID 1 är för Account-01
- AccountID 2 är för Account-02
- Tabellen Kund har två rader:
- CustomerID 91 är för Customer-91
- CustomerID 92 är för Customer-92
- Tabellen AccountCustomer har tre rader:
- AccountID 1 är associerat med CustomerID 91
- AccountID 1 är associerat med CustomerID 92
- AccountID 2 är associerat med CustomerID 92
- Tabellen Transaktion har tre rader:
- Datum 1 januari 2019, AccountID 1, Belopp 100
- Datum 2 februari 2019, AccountID 2, Belopp 200
- Datum 3 mars 2019, AccountID 1, Belopp -25
Nu ska vi se vad som händer när modellen efterfrågas.
Nedan visas två visuella objekt som sammanfattar kolumnen Amount från transaktionstabellen. De första visuella objekten grupperas efter konto, så summan av kolumnerna Amount representerar kontosaldot. Det andra visuella objektet grupperar efter kund, så summan av kolumnerna Amount representerar kundsaldot.
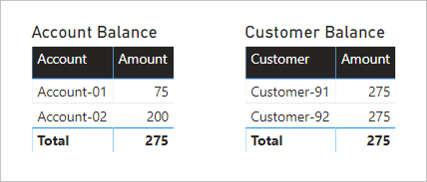
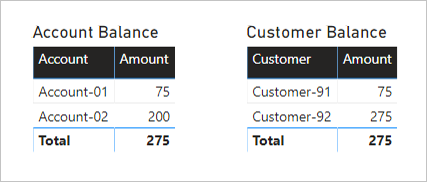
Det första visuella objektet heter Kontosaldo och har två kolumner: Konto och Belopp. Det visar följande resultat:
- Konto-01 saldobelopp är 75
- Konto-02 saldobelopp är 200
- Summan är 275
Det andra visuella objektet heter Customer Balance och har två kolumner: Kund och Belopp. Det visar följande resultat:
- Kund-91 saldobelopp är 275
- Kund-92 saldobelopp är 275
- Summan är 275
En snabb överblick över tabellraderna och det visuella objektet Kontosaldo visar att resultatet är korrekt för varje konto och det totala beloppet. Det beror på att varje kontogruppering resulterar i en filterspridning till transaktionstabellen för det kontot.
Något verkar dock inte korrekt med det visuella objektet Customer Balance . Varje kund i det visuella objektet Customer Balance har samma saldo som det totala saldot. Det här resultatet kan bara vara korrekt om varje kund var en gemensam kontoinnehavare för varje konto. Så är inte fallet i det här exemplet. Problemet gäller filterspridning. Den flödar inte hela vägen till transaktionstabellen.
Följ relationsfilteranvisningarna från tabellen Kund till tabellen Transaktion . Det bör vara uppenbart att relationen mellan tabellen Account och AccountCustomer sprids i fel riktning. Filterriktningen för den här relationen måste vara inställd på Båda.
Som förväntat har det inte skett någon ändring i det visuella objektet Kontosaldo .
De visuella objekten customer balance visar dock nu följande resultat:
- Kund-91 saldobelopp är 75
- Kund-92 saldobelopp är 275
- Summan är 275
Det visuella objektet Customer Balance visar nu ett korrekt resultat. Följ filterriktningarna själv och se hur kundsaldonen beräknades. Förstå också att den visuella summan innebär alla kunder.
Någon som inte känner till modellrelationerna kan dra slutsatsen att resultatet är felaktigt. De kanske frågar: Varför är inte det totala saldot för Customer-91 och Customer-92 lika med 350 (75 + 275)?
Svaret på deras fråga ligger i att förstå många-till-många-relationen. Varje kundsaldo kan representera tillägg av flera kontosaldon och därför är kundsaldonen icke-additiva.
Relatera vägledning för många-till-många-dimensioner
När du har en många-till-många-relation mellan tabeller av dimensionstyp ger vi följande vägledning:
- Lägg till varje många-till-många-relaterad entitet som en modelltabell, så att den har en unik ID-kolumn (ID)
- Lägga till en bryggningstabell för att lagra associerade entiteter
- Skapa en-till-många-relationer mellan de tre tabellerna
- Konfigurera en dubbelriktad relation så att filterspridning kan fortsätta till tabeller av faktatyp
- När det inte är lämpligt att ha saknade ID-värden anger du egenskapen Is Nullable för ID-kolumner till FALSE – datauppdateringen misslyckas sedan om saknade värden hämtas
- Dölj bryggningstabellen (om den inte innehåller ytterligare kolumner eller mått som krävs för rapportering)
- Dölj eventuella ID-kolumner som inte är lämpliga för rapportering (till exempel när ID:t är surrogatnycklar)
- Om det är klokt att lämna en ID-kolumn synlig kontrollerar du att den är på "en"-bilden i relationen – dölj alltid kolumnen "många" på sidan. Det ger bästa filterprestanda.
- För att undvika förvirring eller feltolkning kan du förmedla förklaringar till rapportanvändarna – du kan lägga till beskrivningar med textrutor eller knappbeskrivningar för visuella sidhuvuden
Vi rekommenderar inte att du relaterar många-till-många-tabeller av dimensionstyp direkt. Den här designmetoden kräver att du konfigurerar en relation med kardinaliteten många-till-många. Konceptuellt kan det uppnås, men det innebär att de relaterade kolumnerna kommer att innehålla duplicerade värden. Det är dock en väl accepterad designpraxis att tabeller av dimensionstyp har en ID-kolumn. Tabeller av dimensionstyp bör alltid använda ID-kolumnen som "en" sida av en relation.
Relatera många-till-många-fakta
Den andra typen av många-till-många-scenario omfattar två tabeller av faktatyp. Två tabeller av faktatyp kan relateras direkt. Den här designtekniken kan vara användbar för snabb och enkel datautforskning. Men för att vara tydlig rekommenderar vi vanligtvis inte den här designmetoden. Vi förklarar varför senare i det här avsnittet.
Låt oss ta ett exempel som omfattar två tabeller av faktatyp: Order och Fulfillment. Tabellen Order innehåller en rad per orderrad och tabellen Fulfillment kan innehålla noll eller fler rader per orderrad. Rader i tabellen Order representerar försäljningsorder. Rader i tabellen Fulfillment representerar orderobjekt som har levererats. En många-till-många-relation relaterar de två OrderID-kolumnerna, med filterspridning endast från tabellen Order (OrderfilterFulfillment).
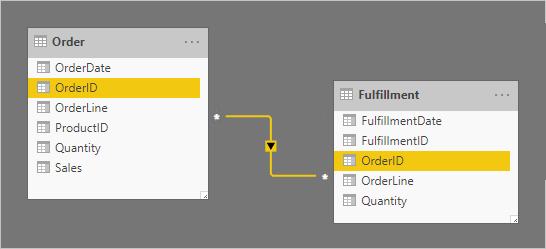
Relations kardinaliteten är inställd på många-till-många för att kunna lagra duplicerade OrderID-värden i båda tabellerna. I tabellen Order kan dubbletter av OrderID-värden finnas eftersom en order kan ha flera rader. I tabellen Fulfillment kan dubbletter av OrderID-värden finnas eftersom beställningar kan ha flera rader och orderrader kan uppfyllas av många försändelser.
Nu ska vi ta en titt på tabellraderna. I tabellen Fulfillment (Uppfyllelse ) ser du att orderrader kan uppfyllas av flera försändelser. (Avsaknaden av en orderrad innebär att ordern ännu inte har uppfyllts.)
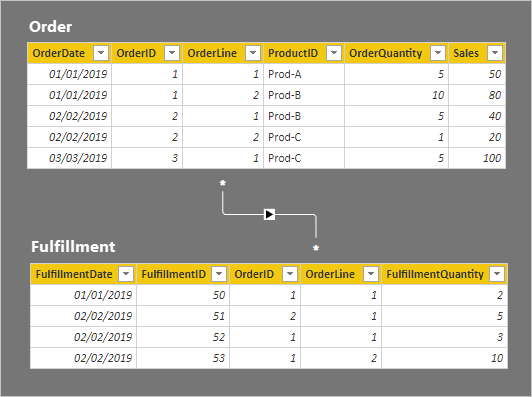
Radinformationen för de två tabellerna beskrivs i följande punktlista:
- Tabellen Order har fem rader:
- OrderDate 1 januari 2019, OrderID 1, OrderLine 1, ProductID Prod-A, OrderQuantity 5, Sales 50
- OrderDate 1 januari 2019, OrderID 1, OrderLine 2, ProductID Prod-B, OrderQuantity 10, Sales 80
- OrderDate 2 februari 2019, OrderID 2, OrderLine 1, ProductID Prod-B, OrderQuantity 5, Sales 40
- OrderDate 2 februari 2019, OrderID 2, OrderLine 2, ProductID Prod-C, OrderQuantity 1, Sales 20
- OrderDate 3 mars 2019, OrderID 3, OrderLine 1, ProductID Prod-C, OrderQuantity 5, Sales 100
- Tabellen Fulfillment har fyra rader:
- FulfillmentDate 1 januari 2019, FulfillmentID 50, OrderID 1, OrderLine 1, FulfillmentQuantity 2
- FulfillmentDate 2 februari 2019, FulfillmentID 51, OrderID 2, OrderLine 1, FulfillmentQuantity 5
- FulfillmentDate 2 februari 2019, FulfillmentID 52, OrderID 1, OrderLine 1, FulfillmentQuantity 3
- FulfillmentDate 1 januari 2019, FulfillmentID 53, OrderID 1, OrderLine 2, FulfillmentQuantity 10
Nu ska vi se vad som händer när modellen efterfrågas. Här är ett visuellt tabellobjekt som jämför order- och uppfyllandekvantiteter med ordertabellens OrderID-kolumn.
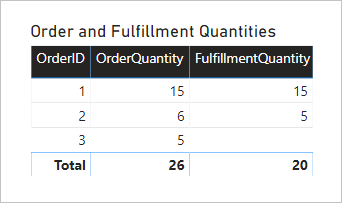
Det visuella objektet visar ett korrekt resultat. Men modellens användbarhet är begränsad – du kan bara filtrera eller gruppera efter ordertabellensOrderID-kolumn.
Relatera vägledning om många-till-många-fakta
I allmänhet rekommenderar vi inte att du relaterar två tabeller av faktatyp direkt med kardinaliteten många-till-många. Den främsta orsaken är att modellen inte ger flexibilitet i hur du rapporterar visuella objekt filtrerar eller grupperar. I exemplet är det bara möjligt för visuella objekt att filtrera eller gruppera efter ordertabellensOrderID-kolumn. Ytterligare en orsak gäller kvaliteten på dina data. Om dina data har integritetsproblem är det möjligt att vissa rader utelämnas under frågor på grund av arten av den begränsade relationen. Mer information finns i Modellrelationer i Power BI Desktop (Relationsutvärdering).
I stället för att relatera tabeller av faktatyp direkt rekommenderar vi att du antar designprinciper för Star Schema . Du gör det genom att lägga till tabeller av dimensionstyp. Tabellerna av dimensionstyp relaterar sedan till tabellerna av faktatyp med hjälp av en-till-många-relationer. Den här designmetoden är robust eftersom den ger flexibla rapporteringsalternativ. Du kan filtrera eller gruppera med någon av kolumnerna av dimensionstyp och sammanfatta alla relaterade tabeller av faktatyp.
Nu ska vi överväga en bättre lösning.
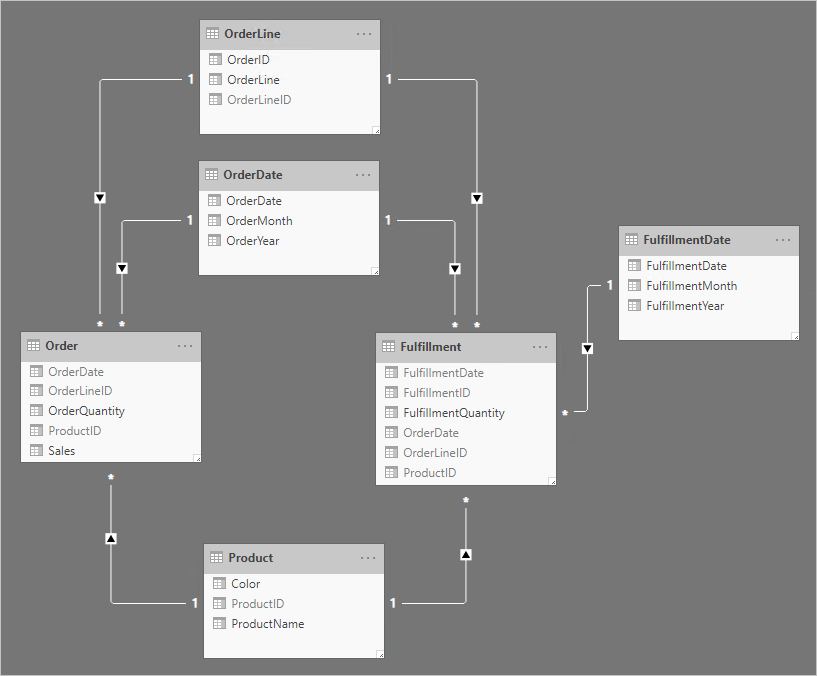
Observera följande designändringar:
- Modellen har nu ytterligare fyra tabeller: OrderLine, OrderDate, Product och FulfillmentDate
- De fyra ytterligare tabellerna är alla tabeller av dimensionstyp och en-till-många-relationer relaterar dessa tabeller till tabeller av faktatyp
- Tabellen OrderLine innehåller en OrderLineID-kolumn som representerar OrderID-värdet multiplicerat med 100 plus OrderLine-värdet – en unik identifierare för varje orderrad
- Tabellerna Order och Fulfillment innehåller nu en OrderLineID-kolumn och de innehåller inte längre kolumnerna OrderID och OrderLine
- Tabellen Fulfillment innehåller nu kolumnerna OrderDate och ProductID
- Tabellen FulfillmentDate relaterar endast till tabellen Fulfillment
- Alla unika identifierarkolumner är dolda
Att ta sig tid att tillämpa designprinciper för star-schema ger följande fördelar:
- Dina visuella rapportobjekt kan filtrera eller gruppera efter valfri synlig kolumn från tabeller av dimensionstyp
- Dina visuella rapportobjekt kan sammanfatta alla synliga kolumner från tabeller av faktatyp
- Filter som tillämpas på tabellerna OrderLine, OrderDate eller Product sprids till båda tabellerna av faktatyp
- Alla relationer är en-till-många och varje relation är en vanlig relation. Dataintegritetsproblem maskeras inte. Mer information finns i Modellrelationer i Power BI Desktop (Relationsutvärdering).
Relatera fakta med högre kornighet
Det här många-till-många-scenariot skiljer sig mycket från de andra två som redan beskrivs i den här artikeln.
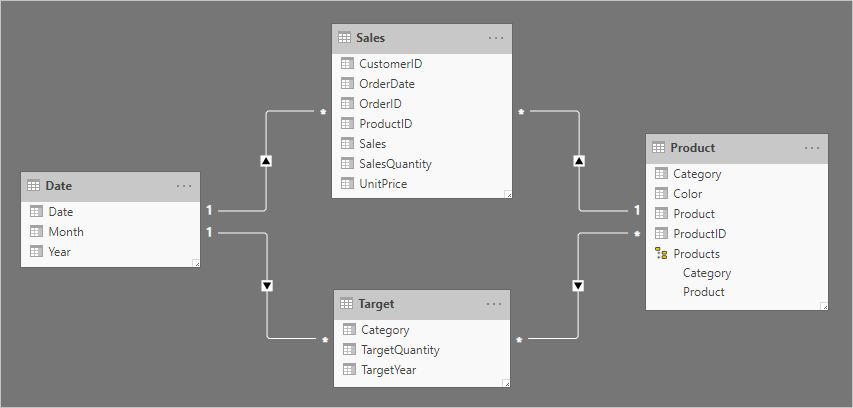
Låt oss ta ett exempel som omfattar fyra tabeller: Datum, Försäljning, Produkt och Mål. Datum och produkt är tabeller av dimensionstyp och en-till-många-relationer relaterar var och en till tabellen sales fact-type. Hittills representerar den en bra design av star-schema. Måltabellen är dock ännu inte relaterad till de andra tabellerna.
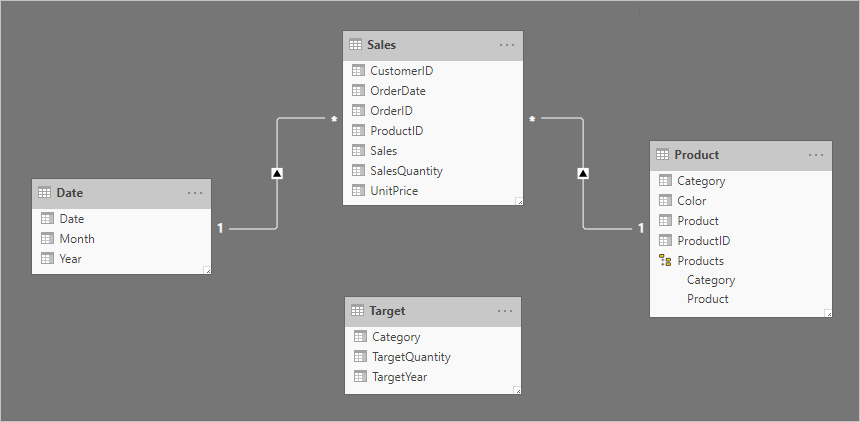
Tabellen Target innehåller tre kolumner: Category, TargetQuantity och TargetYear. Tabellraderna visar en kornighet för år och produktkategori. Med andra ord anges mål – som används för att mäta försäljningsprestanda – varje år för varje produktkategori.
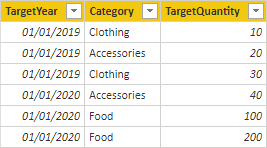
Eftersom tabellen Target lagrar data på en högre nivå än tabellerna av dimensionstyp kan inte en en-till-många-relation skapas. Tja, det är sant för bara en av relationerna. Nu ska vi utforska hur tabellen Target kan relateras till tabeller av dimensionstyp.
Relatera tidsperioder med högre kornighet
En relation mellan tabellerna Datum och Mål ska vara en en-till-många-relation. Det beror på att kolumnvärdena TargetYear är datum. I det här exemplet är varje TargetYear-kolumnvärde målårets första datum.
Dricks
När du lagrar fakta vid en högre tidskornighet än dagen anger du kolumndatatypen till Datum (eller Vem nummer om du använder datumnycklar). I kolumnen lagrar du ett värde som representerar den första dagen i tidsperioden. Till exempel registreras en årsperiod som 1 januari på året och en månadsperiod registreras som den första dagen i den månaden.
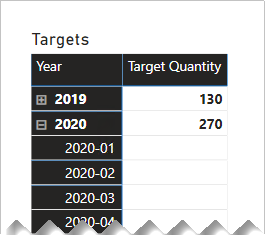
Var dock noga med att se till att filter på månad eller datumnivå ger ett meningsfullt resultat. Utan någon särskild beräkningslogik kan rapportvisualiseringar rapportera att måldatum bokstavligen är den första dagen i varje år. Alla andra dagar – och alla månader utom januari – sammanfattar målkvantiteten som TOM.
Följande matrisvisualisering visar vad som händer när rapportanvändaren ökar detaljnivån från ett år till dess månader. Det visuella objektet sammanfattar kolumnen TargetQuantity . (Den Visa objekt utan dataalternativ har aktiverats för matrisraderna.)
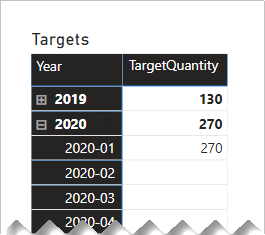
För att undvika det här beteendet rekommenderar vi att du kontrollerar sammanfattningen av dina faktadata med hjälp av mått. Ett sätt att styra sammanfattningen är att returnera BLANK när tidsperioder på lägre nivå efterfrågas. Ett annat sätt – som definierats med vissa avancerade DAX – är att fördela värden över tidsperioder på lägre nivå.
Överväg följande måttdefinition som använder DAX-funktionen ISFILTERED . Det returnerar bara ett värde när kolumnerna Datum eller Månad inte filtreras.
Target Quantity =
IF(
NOT ISFILTERED('Date'[Date])
&& NOT ISFILTERED('Date'[Month]),
SUM(Target[TargetQuantity])
)
Följande visuella matrisobjekt använder nu måttet Målkvantitet . Den visar att alla månatliga målkvantiteter är BLANK.
Relatera högre kornighet (ej datum)
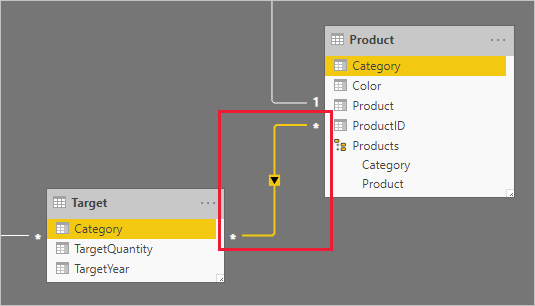
En annan designmetod krävs när du relaterar en icke-datumkolumn från en tabell av dimensionstyp till en tabell av faktatyp (och den har ett högre korn än tabellen av dimensionstyp).
Kolumnerna Kategori (från både tabellerna Produkt och Mål ) innehåller duplicerade värden. Så det finns ingen "en" för en en-till-många-relation. I det här fallet måste du skapa en många-till-många-relation. Relationen bör sprida filter i en enda riktning, från tabellen av dimensionstyp till tabellen av faktatyp.
Nu ska vi ta en titt på tabellraderna.
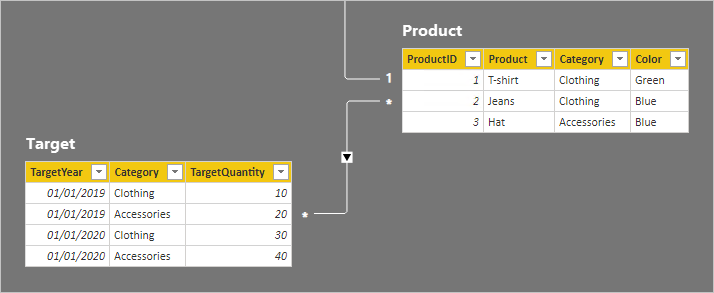
I tabellen Mål finns det fyra rader: två rader för varje målår (2019 och 2020) och två kategorier (Kläder och tillbehör). I tabellen Produkt finns det tre produkter. Två tillhör klädkategorin och en tillhör kategorin tillbehör. En av klädfärgerna är grön och de återstående två är blå.
En tabellvisualisering efter kolumnen Kategori från tabellen Produkt ger följande resultat.
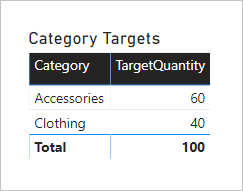
Det här visuella objektet ger rätt resultat. Nu ska vi fundera på vad som händer när kolumnen Färg från tabellen Produkt används för att gruppera målkvantitet.

Det visuella objektet genererar en felaktig framställning av data. Vad händer här?
Ett filter på kolumnen Färg från tabellen Produkt resulterar i två rader. En av raderna är för kategorin Kläder och den andra för kategorin Tillbehör. Dessa två kategorivärden sprids som filter till tabellen Target . Med andra ord, eftersom den blå färgen används av produkter från två kategorier, används dessa kategorier för att filtrera målen.
För att undvika det här beteendet rekommenderar vi att du kontrollerar sammanfattningen av dina faktadata med hjälp av mått.
Överväg följande måttdefinition. Observera att alla produkttabellkolumner som ligger under kategorinivån testas för filter.
Target Quantity =
IF(
NOT ISFILTERED('Product'[ProductID])
&& NOT ISFILTERED('Product'[Product])
&& NOT ISFILTERED('Product'[Color]),
SUM(Target[TargetQuantity])
)
Följande visuella tabellobjekt använder nu måttet Målkvantitet . Den visar att alla färgmålkvantiteter är TOMMA.
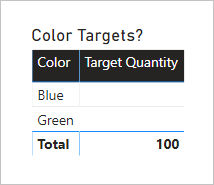
Den slutliga modelldesignen ser ut så här.
Relatera vägledning om fakta med högre kornighet
När du behöver relatera en tabell av dimensionstyp till en tabell av faktatyp, och tabellen av faktatyp lagrar rader med ett högre korn än tabellrader av dimensionstyp, ger vi följande vägledning:
- För faktadatum med högre kornighet:
- I tabellen av faktatyp lagrar du det första datumet i tidsperioden
- Skapa en en-till-många-relation mellan datumtabellen och tabellen av faktatyp
- För andra fakta med högre kornighet:
- Skapa en många-till-många-relation mellan tabellen av dimensionstyp och tabellen av faktatyp
- För båda typerna:
- Kontrollsammanfattning med måttlogik – returnera BLANK när kolumner av dimensionstyp på lägre nivå används för att filtrera eller gruppera
- Dölj sammanfattningsbara tabellkolumner av faktatyp – på det här sättet kan endast mått användas för att sammanfatta tabellen av faktatyp
Relaterat innehåll
Mer information om den här artikeln finns i följande resurser:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för