Modellrelationer i Power BI Desktop
Den här artikeln riktar sig till importdatamodellerare som arbetar med Power BI Desktop. Det är ett viktigt modelldesignämne som är viktigt för att leverera intuitiva, korrekta och optimala modeller.
En djupare diskussion om optimal modelldesign, inklusive tabellroller och relationer, finns i Förstå star-schema och vikten för Power BI.
Relationssyfte
En modellrelation sprider filter som tillämpas på kolumnen i en modelltabell till en annan modelltabell. Filter sprids så länge det finns en relationssökväg att följa, vilket kan innebära spridning till flera tabeller.
Relationssökvägar är deterministiska, vilket innebär att filter alltid sprids på samma sätt och utan slumpmässig variation. Relationer kan dock inaktiveras eller få filterkontexten ändrad av modellberäkningar som använder specifika DAX-funktioner. Mer information finns i avsnittet relevanta DAX-funktioner senare i den här artikeln.
Viktigt!
Modellrelationer framtvingar inte dataintegritet. Mer information finns i avsnittet Relationsutvärdering senare i den här artikeln, som förklarar hur modellrelationer beter sig när det finns dataintegritetsproblem med dina data.
Så här sprider relationer filter med ett animerat exempel.
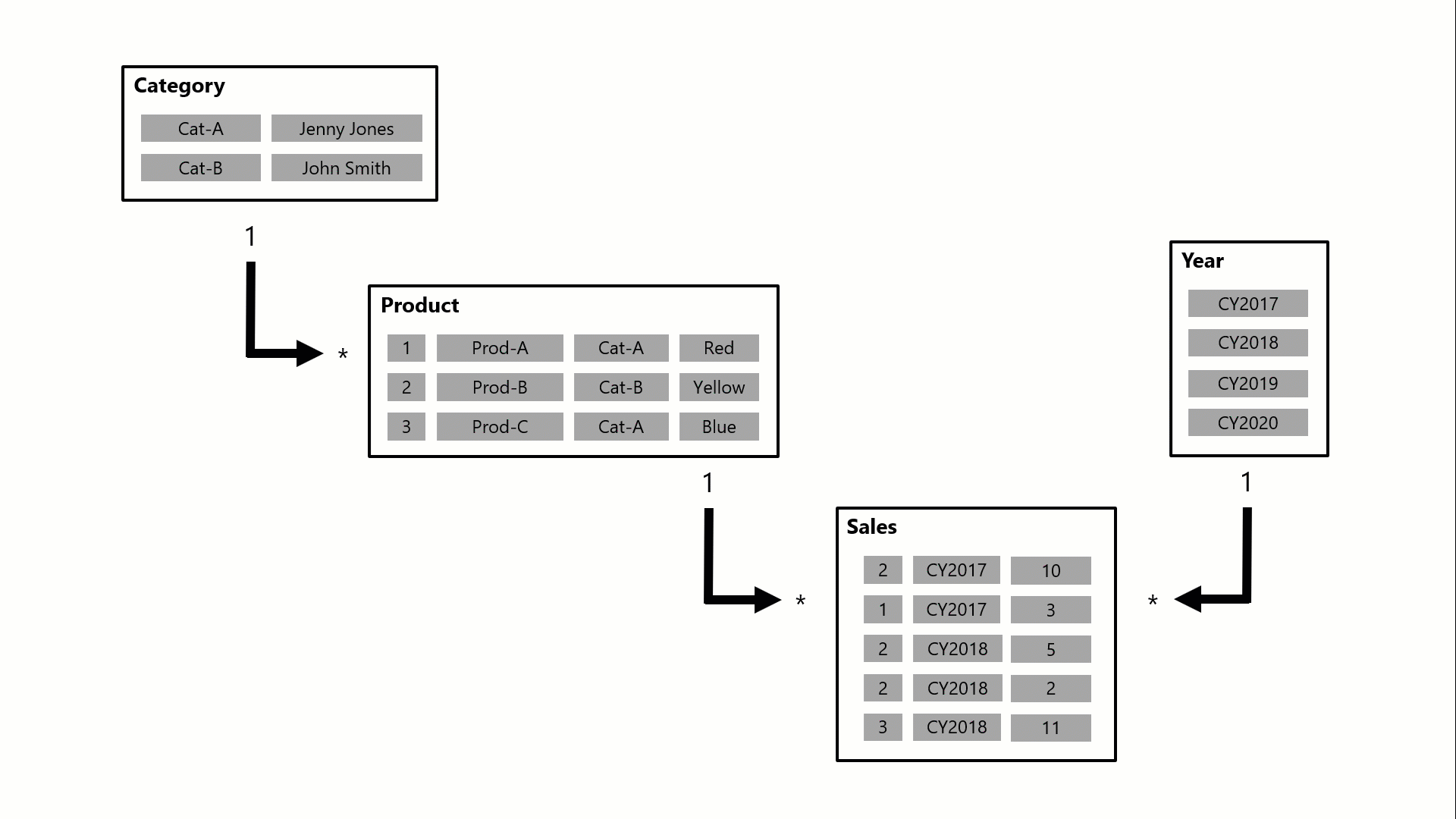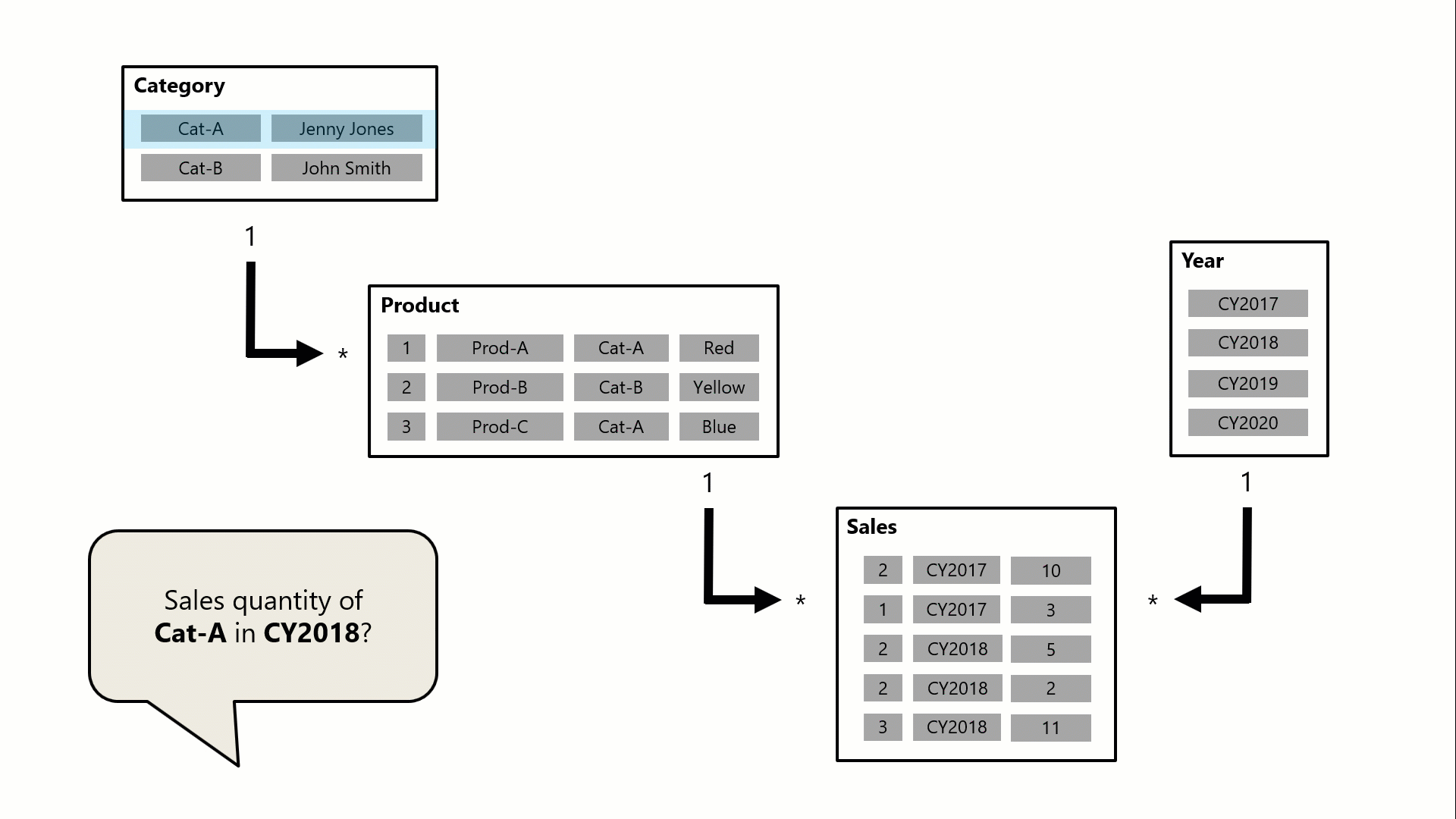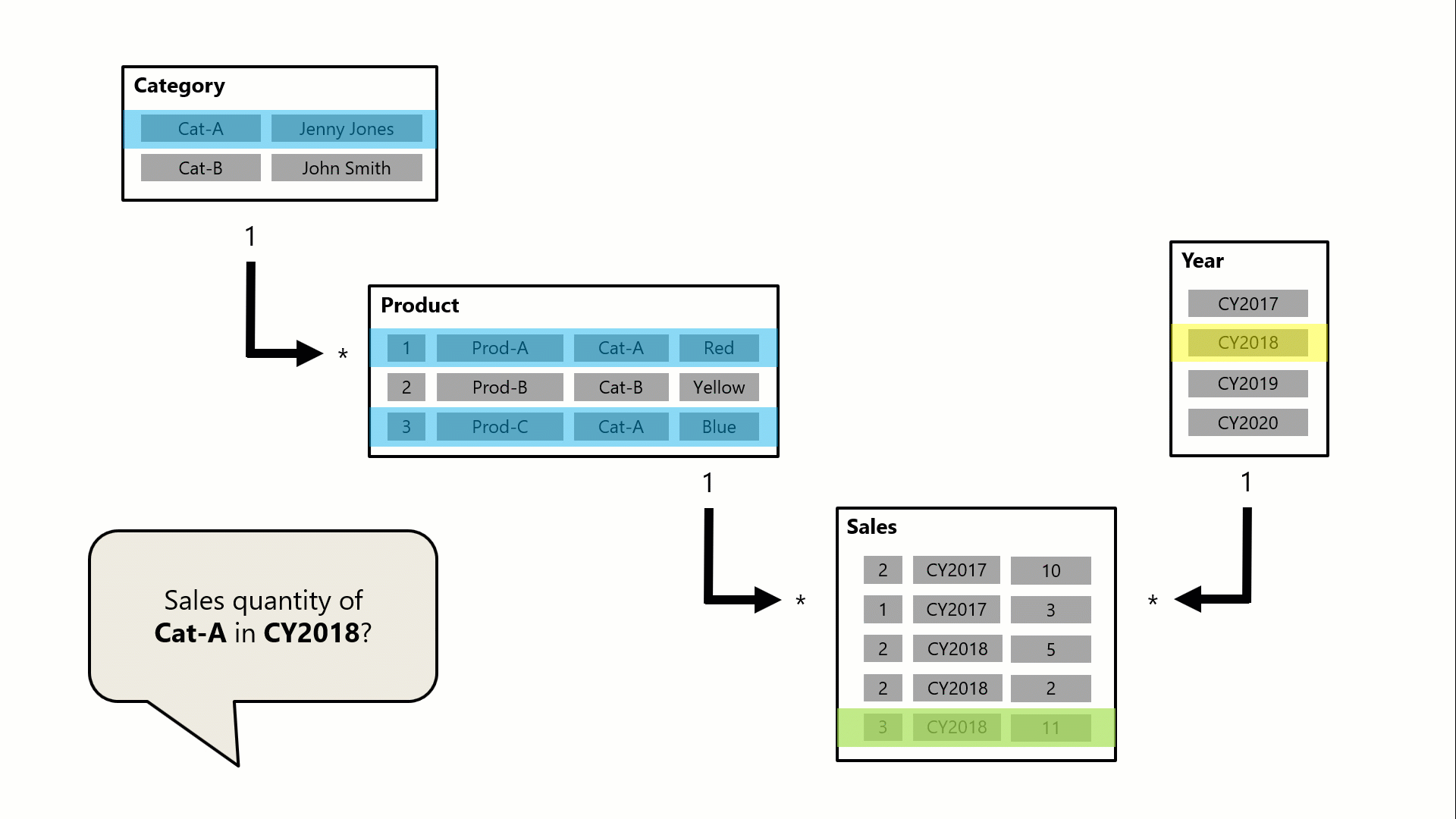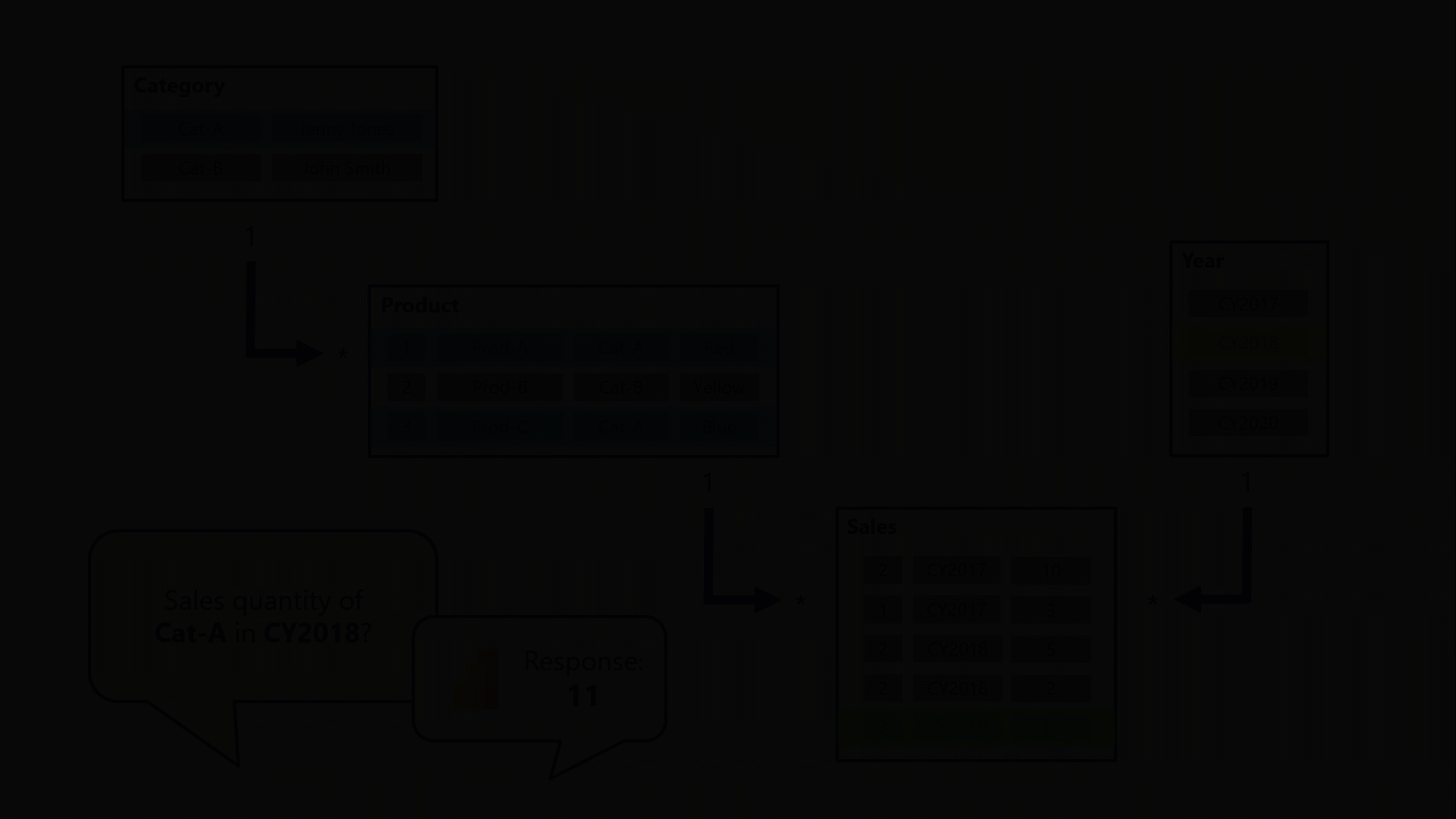
I det här exemplet består modellen av fyra tabeller: Kategori, Produkt, År och Försäljning. Tabellen Kategori relaterar till tabellen Produkt och tabellen Produkt relaterar till tabellen Försäljning . Tabellen Year relaterar också till tabellen Försäljning . Alla relationer är en-till-många (vars information beskrivs senare i den här artikeln).
En fråga, som eventuellt genereras av ett visuellt Power BI-kort, begär den totala försäljningskvantiteten för försäljningsorder som gjorts för en enda kategori, Cat-A, och för ett enda år, CY2018. Det är därför du kan se filter som tillämpas på tabellerna Kategori och År . Filtret i tabellen Kategori sprids till tabellen Produkt för att isolera två produkter som har tilldelats kategorin Cat-A. Sedan spridsprodukttabellfiltren till tabellen Försäljning för att isolera bara två försäljningsrader för dessa produkter. Dessa två försäljningsrader representerar försäljningen av produkter som tilldelats kategorin Cat-A. Deras sammanlagda kvantitet är 14 enheter. Samtidigt sprids tabellfiltret År för att ytterligare filtrera tabellen Försäljning, vilket bara resulterar i den enda försäljningsraden som är för produkter som tilldelats kategorin Cat-A och som beställdes år CY2018. Kvantitetsvärdet som returneras av frågan är 11 enheter. Observera att när flera filter tillämpas på en tabell (t.ex . tabellen Försäljning i det här exemplet) är det alltid en AND-åtgärd som kräver att alla villkor måste vara sanna.
Tillämpa designprinciper för star-schema
Vi rekommenderar att du använder designprinciper för star-schema för att skapa en modell som består av dimensions- och faktatabeller. Det är vanligt att konfigurera Power BI för att framtvinga regler som filtrerar dimensionstabeller, så att modellrelationer effektivt kan sprida dessa filter till faktatabeller.
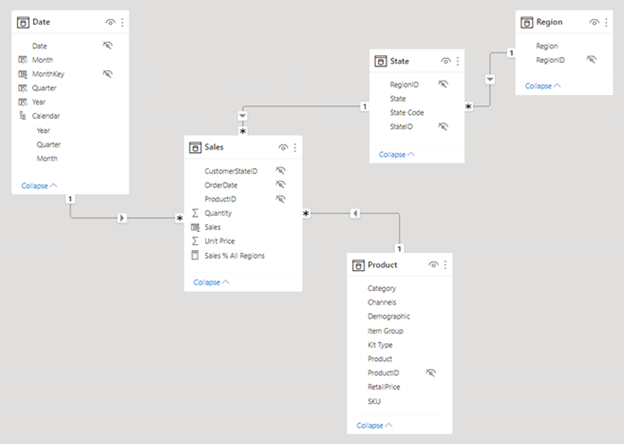
Följande bild är modelldiagrammet för datamodellen adventure works försäljningsanalys. Den visar en star-schemadesign som består av en enda faktatabell med namnet Försäljning. De övriga fyra tabellerna är dimensionstabeller som stöder analys av försäljningsmått efter datum, tillstånd, region och produkt. Observera modellrelationerna som ansluter alla tabeller. Dessa relationer sprider filter (direkt eller indirekt) till tabellen Försäljning .
Frånkopplade tabeller
Det är ovanligt att en modelltabell inte är relaterad till en annan modelltabell. En sådan tabell i en giltig modelldesign beskrivs som en frånkopplad tabell. En frånkopplad tabell är inte avsedd att sprida filter till andra modelltabeller. I stället accepteras "användarindata" (kanske med ett visuellt utsnitt) så att modellberäkningar kan använda indatavärdet på ett meningsfullt sätt. Tänk dig till exempel en frånkopplad tabell som läses in med ett intervall med valutakursvärden. Så länge ett filter används för att filtrera efter ett enskilt prisvärde kan ett måttuttryck använda det värdet för att konvertera försäljningsvärden.
Power BI Desktop-konsekvensparametern är en funktion som skapar en frånkopplad tabell. Mer information finns i Skapa och använda en Vad om-parameter för att visualisera variabler i Power BI Desktop.
Relationsegenskaper
En modellrelation relaterar en kolumn i en tabell till en kolumn i en annan tabell. (Det finns ett särskilt fall där det här kravet inte är sant, och det gäller endast för relationer med flera kolumner i DirectQuery-modeller. Mer information finns i dax-funktionsartikeln COMBINEVALUES .)
Kommentar
Det går inte att relatera en kolumn till en annan kolumn i samma tabell. Det här konceptet förväxlas ibland med möjligheten att definiera en begränsning av sekundärnyckeln för relationsdatabasen som är självrefererande tabell. Du kan använda det här relationsdatabaskonceptet för att lagra överordnade och underordnade relationer (till exempel är varje anställds post relaterad till en "rapport till" anställd). Du kan dock inte använda modellrelationer för att generera en modellhierarki baserat på den här typen av relation. Information om hur du skapar en överordnad-underordnad hierarki finns i Funktioner för överordnad och underordnad.
Datatyper av kolumner
Datatypen för både kolumnen "från" och "till" i relationen ska vara densamma. Att arbeta med relationer som definierats i DateTime-kolumner kanske inte fungerar som förväntat. Motorn som lagrar Power BI-data använder endast DateTime-datatyper . Datatyperna Date, Time och Date/Time/Time/Timezone är Power BI-formateringskonstruktioner som implementeras ovanpå. Alla modellberoende objekt visas fortfarande som DateTime i motorn (till exempel relationer, grupper och så vidare). Om en användare väljer Datum på fliken Modellering för sådana kolumner registreras de fortfarande inte som samma datum, eftersom tidsdelen av data fortfarande beaktas av motorn. Läs mer om hur datum/tid-typer hanteras. För att korrigera beteendet bör kolumndatatyperna uppdateras i Power Query-redigeraren för att ta bort tidsdelen från importerade data, så när motorn hanterar data visas värdena på samma sätt.
Kardinalitet
Varje modellrelation definieras av en kardinalitetstyp. Det finns fyra alternativ för kardinalitetstyp som representerar dataegenskaperna för de "från" och "till" relaterade kolumnerna. Sidan "en" innebär att kolumnen innehåller unika värden. "många"-sidan innebär att kolumnen kan innehålla duplicerade värden.
Kommentar
Om en datauppdateringsåtgärd försöker läsa in duplicerade värden i en "en" sidokolumn misslyckas hela datauppdateringen.
De fyra alternativen, tillsammans med deras kortfattade noteringar, beskrivs i följande punktlista:
- En-till-många (1:*)
- Många-till-en (*:1)
- En-till-en (1:1)
- Många-till-många (*:*)
När du skapar en relation i Power BI Desktop identifierar och anger designern automatiskt kardinalitetstypen. Power BI Desktop frågar modellen om vilka kolumner som innehåller unika värden. För importmodeller används intern lagringsstatistik. för DirectQuery-modeller skickar den profileringsfrågor till datakällan. Ibland kan dock Power BI Desktop göra fel. Det kan bli fel när tabeller ännu inte har lästs in med data, eller på grund av att kolumner som du förväntar dig ska innehålla duplicerade värden för närvarande innehåller unika värden. I båda fallen kan du uppdatera kardinalitetstypen så länge alla "en" sidokolumner innehåller unika värden (eller så har tabellen ännu inte lästs in med rader med data).
Kardinalitet 1-till-många (och många-till-en)
Kardinalitetsalternativen 1-till-många och många-till-en är i stort sett desamma, och de är också de vanligaste kardinalitetstyperna.
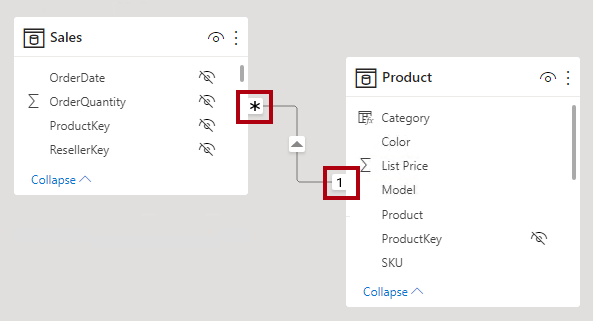
När du konfigurerar en en-till-många- eller många-till-en-relation väljer du den som matchar den ordning som du relaterade kolumnerna i. Överväg hur du konfigurerar relationen från tabellen Produkt till tabellen Försäljning med hjälp av kolumnen ProductID som finns i varje tabell. Kardinalitetstypen skulle vara en-till-många eftersom kolumnen ProductID i tabellen Produkt innehåller unika värden. Om du relaterade tabellerna i omvänd riktning, Försäljning till produkt, skulle kardinaliteten vara många-till-en.
En-till-en-kardinalitet
En en-till-en-relation innebär att båda kolumnerna innehåller unika värden. Den här kardinalitetstypen är inte vanlig, och den representerar troligen en underoptimal modelldesign på grund av lagring av redundanta data.
Mer information om hur du använder den här kardinalitetstypen finns i Vägledning för en-till-en-relation.
Kardinalitet för många-till-många
En många-till-många-relation innebär att båda kolumnerna kan innehålla dubblettvärden. Den här kardinalitetstypen används sällan. Det är vanligtvis användbart när du utformar komplexa modellkrav. Du kan använda den för att relatera många-till-många-fakta eller för att relatera fakta med högre kornighet. Till exempel när försäljningsmålfakta lagras på produktkategorinivå och produktdimensionstabellen lagras på produktnivå.
Vägledning om hur du använder den här kardinalitetstypen finns i Vägledning för många-till-många-relationer.
Kommentar
Kardinalitetstypen Många-till-många stöds för modeller som utvecklats för Power BI-rapportserver januari 2024 och senare.
Dricks
I Power BI Desktop-modellvyn kan du tolka en relations kardinalitetstyp genom att titta på indikatorerna (1 eller *) på vardera sidan av relationslinjen. För att avgöra vilka kolumner som är relaterade måste du välja, eller hovra markören över, relationslinjen för att markera kolumnerna.
Korsfilterriktning
Varje modellrelation definieras med korsfilterriktning. Inställningen bestämmer i vilken riktning/vilka filter som ska spridas. De möjliga alternativen för korsfilter är beroende av kardinalitetstypen.
| Kardinalitetstyp | Alternativ för korsfilter |
|---|---|
| En-till-många (eller många-till-en) | Enstaka Båda |
| En-till-en | Båda |
| Många till många | Enkel (Table1 till Table2) Enkel (Table2 till Table1) Båda |
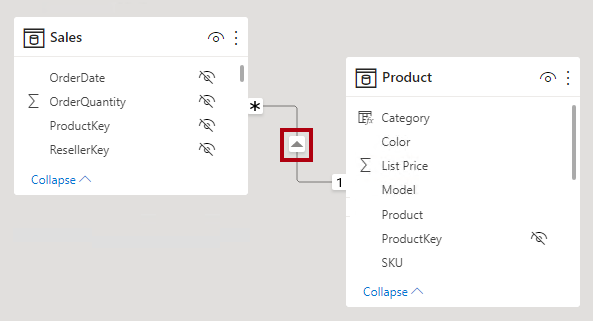
Enkel korsfilterriktning betyder "enkel riktning" och Båda betyder "båda riktningarna". En relation som filtrerar i båda riktningarna beskrivs ofta som dubbelriktad.
För en-till-många-relationer är korsfilterriktningen alltid från "en"-sidan och eventuellt från "många"-sidan (dubbelriktad). För en-till-en-relationer kommer korsfilterriktningen alltid från båda tabellerna. För många-till-många-relationer kan korsfilterriktningen slutligen vara från antingen en av tabellerna eller från båda tabellerna. Observera att när kardinalitetstypen innehåller en "en"-sida kommer filtren alltid att spridas från den sidan.
När korsfilterriktningen är inställd på Båda blir en annan egenskap tillgänglig. Den kan tillämpa dubbelriktad filtrering när Power BI tillämpar regler för säkerhet på radnivå (RLS). Mer information om RLS finns i Säkerhet på radnivå (RLS) med Power BI Desktop.
Du kan ändra relationens korsfilterriktning, inklusive inaktivering av filterspridning, med hjälp av en modellberäkning. Det uppnås med hjälp av DAX-funktionen CROSSFILTER .
Tänk på att dubbelriktade relationer kan påverka prestanda negativt. Om du försöker konfigurera en dubbelriktad relation kan det dessutom resultera i tvetydiga filterspridningssökvägar. I det här fallet kan Power BI Desktop misslyckas med att genomföra relationsändringen och varnar dig med ett felmeddelande. Ibland kan du dock använda Power BI Desktop för att definiera tvetydiga relationssökvägar mellan tabeller. Lösning av tvetydighet för relationssökväg beskrivs senare i den här artikeln.
Vi rekommenderar att du endast använder dubbelriktad filtrering efter behov. Mer information finns i Vägledning för dubbelriktade relationer.
Dricks
I Power BI Desktop-modellvyn kan du tolka en relations korsfilterriktning genom att märka pilspetsarna längs relationslinjen. En enda pilspets representerar ett filter med en riktning i pilspetsens riktning. en dubbel pilspets representerar en dubbelriktad relation.
Aktivera den här relationen
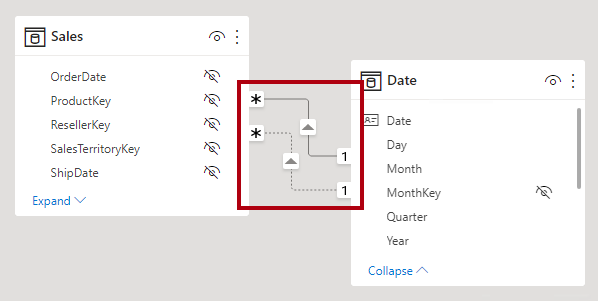
Det kan bara finnas en aktiv filterspridningssökväg mellan två modelltabeller. Det är dock möjligt att införa ytterligare relationssökvägar, även om du måste ange dessa relationer som inaktiva. Inaktiva relationer kan bara aktiveras under utvärderingen av en modellberäkning. Det uppnås med hjälp av DAX-funktionen USERELATIONSHIP .
I allmänhet rekommenderar vi att du definierar aktiva relationer när det är möjligt. De breddar omfattningen och potentialen för hur rapportförfattare kan använda din modell. Att endast använda aktiva relationer innebär att dimensionstabeller för rollspel ska dupliceras i din modell.
Under vissa omständigheter kan du dock definiera en eller flera inaktiva relationer för en rollspelsdimensionstabell. Du kan tänka på den här designen när:
- Det finns inget krav på att rapportvisualiseringar ska filtreras efter olika roller samtidigt.
- Du använder
USERELATIONSHIPDAX-funktionen för att aktivera en specifik relation för relevanta modellberäkningar.
Mer information finns i Vägledning för aktiva kontra inaktiva relationer.
Dricks
I Power BI Desktop-modellvyn kan du tolka en relations aktiva kontra inaktiva status. En aktiv relation representeras av en heldragen linje. en inaktiv relation representeras som en streckad linje.
Anta referensintegritet
Egenskapen Anta referensintegritet är endast tillgänglig för en-till-många- och en-till-en-relationer mellan två DirectQuery-lagringslägestabeller som tillhör samma källgrupp. Du kan bara aktivera den här egenskapen när "många"-sidokolumnen inte innehåller NULLL:er.
När de är aktiverade ansluter interna frågor som skickas till datakällan de två tabellerna med hjälp av en INNER JOIN i stället för en OUTER JOIN. Att aktivera den här egenskapen förbättrar i allmänhet frågeprestanda, även om det beror på datakällans specifika egenskaper.
Aktivera alltid den här egenskapen när det finns en begränsning för sekundärnyckel för databasen mellan de två tabellerna. Även om det inte finns någon begränsning för sekundärnyckel kan du överväga att aktivera egenskapen så länge du är säker på att dataintegriteten finns.
Viktigt!
Om dataintegriteten skulle komprometteras eliminerar den inre kopplingen omatchade rader mellan tabellerna. Tänk dig till exempel en modellförsäljningstabell med ett ProductID-kolumnvärde som inte fanns i den relaterade produkttabellen. Filterspridning från tabellen Produkt till tabellen Försäljning eliminerar försäljningsrader för okända produkter. Detta skulle resultera i en underdrift av försäljningsresultatet.
Mer information finns i Anta inställningar för referensintegritet i Power BI Desktop.
Relevanta DAX-funktioner
Det finns flera DAX-funktioner som är relevanta för modellrelationer. Varje funktion beskrivs kortfattat i följande punktlista:
- RELATERAT: Hämtar värdet från "en" sida av en relation. Det är användbart när du använder beräkningar från olika tabeller som utvärderas i radkontext.
- RELATEDTABLE: Hämta en tabell med rader från "många" sidan av en relation.
- USERELATIONSHIP: Tillåter att en beräkning använder en inaktiv relation. (Tekniskt sett ändrar den här funktionen vikten för en specifik inaktiv modellrelation som bidrar till att påverka dess användning.) Det är användbart när din modell innehåller en rollspelsdimensionstabell och du väljer att skapa inaktiva relationer från den här tabellen. Du kan också använda den här funktionen för att lösa tvetydighet i filtersökvägar.
- CROSSFILTER: Ändrar relationens korsfilterriktning (till en eller båda), eller så inaktiveras filterspridning (ingen). Det är användbart när du behöver ändra eller ignorera modellrelationer under utvärderingen av en specifik beräkning.
- COMBINEVALUES: Kopplar två eller flera textsträngar till en textsträng. Syftet med den här funktionen är att stödja relationer med flera kolumner i DirectQuery-modeller när tabeller tillhör samma källgrupp.
- TREATAS: Tillämpar resultatet av ett tabelluttryck som filter på kolumner från en orelaterad tabell. Det är användbart i avancerade scenarier när du vill skapa en virtuell relation under utvärderingen av en specifik beräkning.
- Överordnade och underordnade funktioner: En familj med relaterade funktioner som du kan använda för att generera beräknade kolumner för att naturalisera en överordnad-underordnad hierarki. Du kan sedan använda dessa kolumner för att skapa en hierarki på fast nivå.
Relationsutvärdering
Modellrelationer klassificeras ur ett utvärderingsperspektiv som antingen regelbundna eller begränsade. Det är inte en konfigurerbar relationsegenskap. Det härleds faktiskt från kardinalitetstypen och datakällan för de två relaterade tabellerna. Det är viktigt att förstå utvärderingstypen eftersom det kan uppstå prestandakonsekvenser eller konsekvenser om dataintegriteten komprometteras. Dessa konsekvenser och integritetskonsekvenser beskrivs i det här avsnittet.
För det första krävs en del modelleringsteori för att förstå relationsutvärderingar fullt ut.
En import- eller DirectQuery-modell hämtar alla sina data från antingen Vertipaq-cachen eller källdatabasen. I båda instanserna kan Power BI fastställa att en "en" sida av en relation finns.
En sammansatt modell kan dock bestå av tabeller med olika lagringslägen (import, DirectQuery eller dubbla) eller flera DirectQuery-källor. Varje källa, inklusive Vertipaq-cachen för importerade data, anses vara en källgrupp. Modellrelationer kan sedan klassificeras som intrakällgrupp eller inter-/korskällgrupp. En relation mellan källgrupper relaterar två tabeller i en källgrupp, medan en relation mellan källgrupper relaterar tabeller mellan två källgrupper. Observera att relationer i import- eller DirectQuery-modeller alltid är inom källgruppen.
Här är ett exempel på en sammansatt modell.
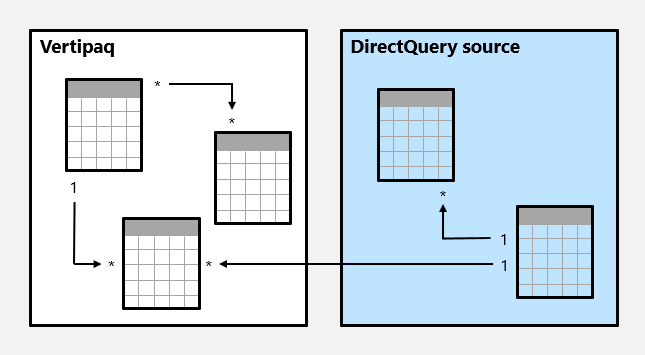
I det här exemplet består den sammansatta modellen av två källgrupper: en Vertipaq-källgrupp och en DirectQuery-källgrupp. Vertipaq-källgruppen innehåller tre tabeller och DirectQuery-källgruppen innehåller två tabeller. Det finns en relation mellan källgrupper för att relatera en tabell i Vertipaq-källgruppen till en tabell i DirectQuery-källgruppen.
Vanliga relationer
En modellrelation är vanlig när frågemotorn kan fastställa "en"-sidan av relationen. Den har en bekräftelse på att kolumnen på sidan "en" innehåller unika värden. Alla en-till-många-relationer inom källgruppen är vanliga relationer.
I följande exempel finns det två vanliga relationer, båda markerade som R. Relationer inkluderar en-till-många-relationen som finns i Vertipaq-källgruppen och en-till-många-relationen som finns i DirectQuery-källan.
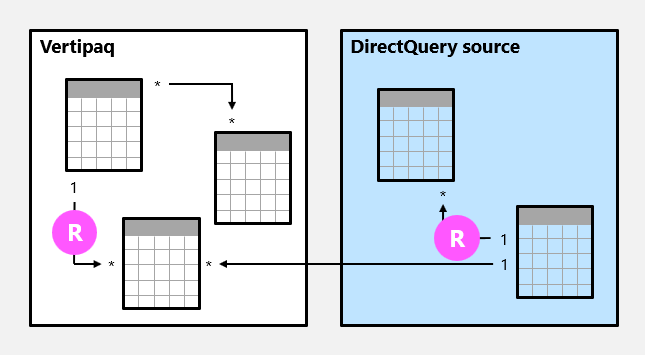
För importmodeller, där alla data lagras i Vertipaq-cachen, skapar Power BI en datastruktur för varje vanlig relation vid datauppdateringen. Datastrukturerna består av indexerade mappningar av alla kolumn-till-kolumn-värden och syftet med dem är att påskynda sammanfogning av tabeller vid frågetillfället.
Vid frågetillfället tillåter reguljära relationer att tabellexpansion sker. Tabellexpansion leder till att en virtuell tabell skapas genom att de ursprungliga kolumnerna i bastabellen inkluderas och sedan expanderas till relaterade tabeller. För importtabeller utförs tabellexpansion i frågemotorn. För DirectQuery-tabeller görs det i den interna frågan som skickas till källdatabasen (så länge egenskapen Anta referensintegritet inte är aktiverad). Frågemotorn fungerar sedan på den expanderade tabellen och tillämpar filter och grupperar efter värdena i de expanderade tabellkolumnerna.
Kommentar
Inaktiva relationer utökas också, även om relationen inte används av en beräkning. Dubbelriktade relationer påverkar inte tabellexpansionen.
För en-till-många-relationer sker tabellexpansion från "många" till "en"-sidorna med hjälp LEFT OUTER JOIN av semantik. När ett matchande värde från "många" till "en"-sidan inte finns läggs en tom virtuell rad till i tabellen på sidan "en". Det här beteendet gäller endast för vanliga relationer, inte för begränsade relationer.
Tabellexpansion sker också för en-till-en-relationer mellan källgrupper, men med hjälp FULL OUTER JOIN av semantik. Den här kopplingstypen säkerställer att tomma virtuella rader läggs till på båda sidor när det behövs.
Tomma virtuella rader är i praktiken okända medlemmar. Okända medlemmar representerar referensintegritetsöverträdelser där "många"-sidovärdet inte har något motsvarande "en" sidovärde. Helst bör dessa tomma inte finnas. De kan elimineras genom rensning eller reparation av källdata.
Så här fungerar tabellexpansion med ett animerat exempel.

I det här exemplet består modellen av tre tabeller: Kategori, Produkt och Försäljning. Tabellen Kategori relaterar till tabellen Produkt med en en-till-många-relation och tabellen Produkt relaterar till tabellen Försäljning med en en-till-många-relation. Tabellen Kategori innehåller två rader, tabellen Produkt innehåller tre rader och tabellerna Försäljning innehåller fem rader. Det finns matchande värden på båda sidor av alla relationer, vilket innebär att det inte finns några överträdelser av referensintegriteten. En utökad tabell för frågetid visas. Tabellen består av kolumnerna från alla tre tabellerna. Det är i själva verket ett avnormaliserat perspektiv på data som finns i de tre tabellerna. En ny rad läggs till i tabellen Försäljning och har ett produktionsidentifierarvärde (9) som inte har något matchande värde i tabellen Produkt . Det är en referensintegritetsöverträdelse. I den expanderade tabellen har den nya raden (tomma) värden för tabellkolumnerna Kategori och Produkt .
Begränsade relationer
En modellrelation är begränsad när det inte finns någon garanterad "en" sida. En begränsad relation kan inträffa av två orsaker:
- Relationen använder kardinalitetstypen många-till-många (även om en eller båda kolumnerna innehåller unika värden).
- Relationen är en korskällgrupp (vilket bara kan vara fallet för sammansatta modeller).
I följande exempel finns det två begränsade relationer, båda markerade som L. De två relationerna omfattar många-till-många-relationen i Vertipaq-källgruppen och en-till-många-relationen mellan källgrupper.
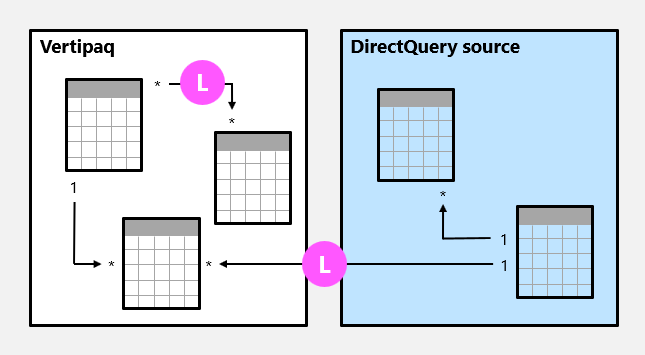
För importmodeller skapas aldrig datastrukturer för begränsade relationer. I så fall löser Power BI tabellkopplingar vid frågetillfället.
Tabellexpansion sker aldrig för begränsade relationer. Tabellkopplingar uppnås med hjälp INNER JOIN av semantik, och därför läggs inte tomma virtuella rader till för att kompensera för överträdelser av referensintegritet.
Det finns andra begränsningar som rör begränsade relationer:
- DAX-funktionen
RELATEDkan inte användas för att hämta kolumnvärdena på sidan "en". - Framtvingandet av RLS har topologibegränsningar.
Dricks
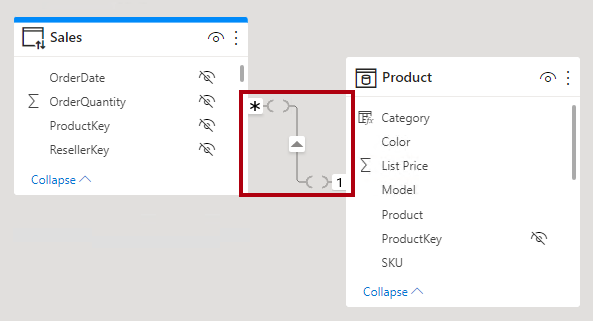
I Power BI Desktop-modellvyn kan du tolka en relation som begränsad. En begränsad relation representeras med parentesliknande märken ( ) efter kardinalitetsindikatorerna.
Lösa tvetydighet för relationssökväg
Dubbelriktade relationer kan introducera flera, och därför tvetydiga, filterspridningssökvägar mellan modelltabeller. När du utvärderar tvetydighet väljer Power BI sökvägen för filterspridning efter prioritet och vikt.
Prioritet
Prioritetsnivåer definierar en sekvens med regler som Power BI använder för att lösa tvetydighet i relationssökvägen. Den första regelmatchningen avgör vilken sökväg Power BI ska följa. Varje regel nedan beskriver hur filter flödar från en källtabell till en måltabell.
- En sökväg som består av en-till-många-relationer.
- En sökväg som består av en-till-många- eller många-till-många-relationer.
- En sökväg som består av många-till-en-relationer.
- En sökväg som består av en-till-många-relationer från källtabellen till en mellanliggande tabell följt av många-till-en-relationer från den mellanliggande tabellen till måltabellen.
- En sökväg som består av en-till-många- eller många-till-många-relationer från källtabellen till en mellanliggande tabell följt av många-till-en- eller många-till-många-relationer från mellanliggande tabell till måltabellen.
- Alla andra sökvägar.
När en relation ingår i alla tillgängliga sökvägar tas den bort från övervägandet från alla sökvägar.
Grovlek
Varje relation i en sökväg har en vikt. Som standard är varje relationsvikt lika med om inte funktionen USERELATIONSHIP används. Sökvägsvikten är det högsta av alla relationsvikter längs sökvägen. Power BI använder sökvägsvikterna för att lösa tvetydighet mellan flera sökvägar på samma prioritetsnivå. Den väljer inte en sökväg med lägre prioritet, men den väljer sökvägen med högre vikt. Antalet relationer i sökvägen påverkar inte vikten.
Du kan påverka vikten på en relation med hjälp av funktionen USERELATIONSHIP . Vikten bestäms av anropets kapslingsnivå till den här funktionen, där det innersta anropet får den högsta vikten.
Betänk följande exempel. Måttet Produktförsäljning tilldelar en högre vikt till relationen mellan Sales[ProductID] och Product[ProductID], följt av relationen mellan Inventory[ProductID] och Product[ProductID].
Product Sales =
CALCULATE(
CALCULATE(
SUM(Sales[SalesAmount]),
USERELATIONSHIP(Sales[ProductID], Product[ProductID])
),
USERELATIONSHIP(Inventory[ProductID], Product[ProductID])
)
Kommentar
Om Power BI identifierar flera sökvägar som har samma prioritet och samma vikt returneras ett tvetydigt sökvägsfel. I det här fallet måste du lösa tvetydigheten genom att påverka relationsvikterna med hjälp av funktionen USERELATIONSHIP eller genom att ta bort eller ändra modellrelationer.
Prestandainställningar
Följande listordningar filtrerar spridningsprestanda, från snabbaste till långsammaste prestanda:
- En-till-många-relationer inom källgruppen
- Många-till-många-modellrelationer som uppnås med en mellanliggande tabell och som omfattar minst en dubbelriktad relation
- Kardinalitetsrelationer för många-till-många
- Relationer mellan källgrupper
Relaterat innehåll
Mer information om den här artikeln finns i följande resurser:
- Förstå star-schema och vikten för Power BI
- Vägledning för en-till-en-relation
- Vägledning för många-till-många-relationer
- Vägledning för aktiva kontra inaktiva relationer
- Vägledning för dubbelriktad relation
- Vägledning för relationsfelsökning
- Video: Dos och Don'ts för Power BI-relationer
- Frågor? Prova att fråga Power BI Community
- Förslag? Bidra med idéer för att förbättra Power BI
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för