Konfigurera Power BI Premium-dataflödesarbetsbelastningar
Du kan skapa dataflödesarbetsbelastningar i din Power BI Premium-prenumeration. Power BI använder begreppet arbetsbelastningar för att beskriva Premium-innehåll. Arbetsbelastningar omfattar datauppsättningar, sidnumrerade rapporter, dataflöden och AI. Med dataflödenas arbetsbelastning kan du använda dataflöden med självbetjäningsdataförberedelser för att mata in, transformera, integrera och berika data. Power BI Premium-dataflöden hanteras i administratörsportalen.
I följande avsnitt beskrivs hur du aktiverar dataflöden i din organisation, hur du förfinar deras inställningar i din Premium-kapacitet och vägledning för vanlig användning.
Aktivera dataflöden i Power BI Premium
Det första kravet för att använda dataflöden i din Power BI Premium-prenumeration är att göra det möjligt att skapa och använda dataflöden för din organisation. I administratörsportalen väljer du Klientorganisation Inställningar och växlar skjutreglaget under Dataflödesinställningar till Aktiverad, enligt följande bild.
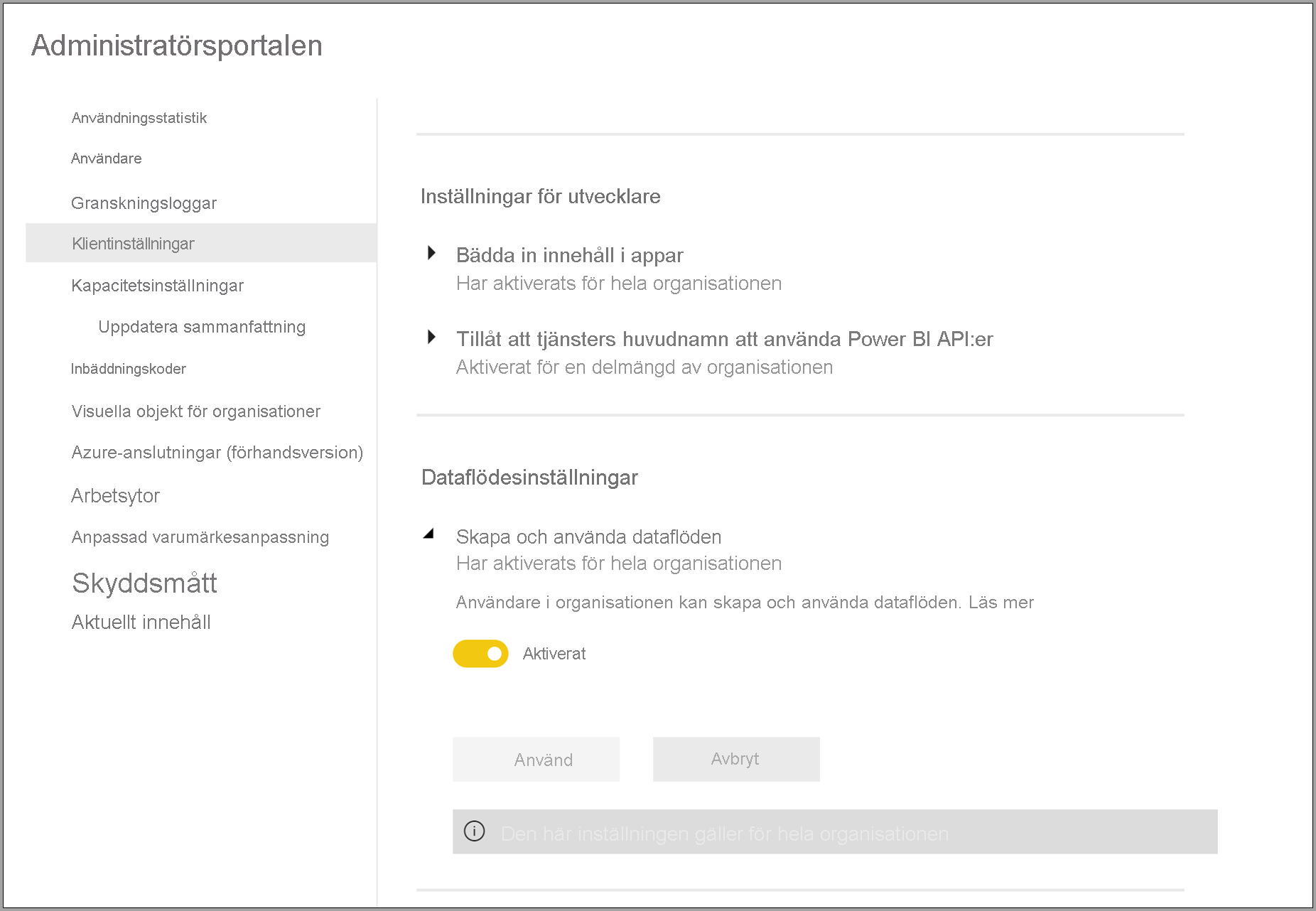
När du har aktiverat arbetsbelastningen för dataflöden konfigureras den med standardinställningar. Du kanske vill justera de här inställningarna som du vill. Därefter beskriver vi var de här inställningarna finns, beskriver var och en och hjälper dig att förstå när du kanske vill ändra värdena för att optimera dataflödesprestandan.
Förfina dataflödesinställningar i Premium
När dataflöden har aktiverats kan du använda administratörsportalen för att ändra eller förfina hur dataflöden skapas och hur de använder resurser i din Power BI Premium-prenumeration. Power BI Premium kräver inte att minnesinställningarna ändras. Minnet i Power BI Premium hanteras automatiskt av det underliggande systemet. Följande steg visar hur du justerar dina dataflödesinställningar.
I administratörsportalen väljer du Klientinställningar för att visa en lista över alla kapaciteter som har skapats. Välj en kapacitet för att hantera dess inställningar.
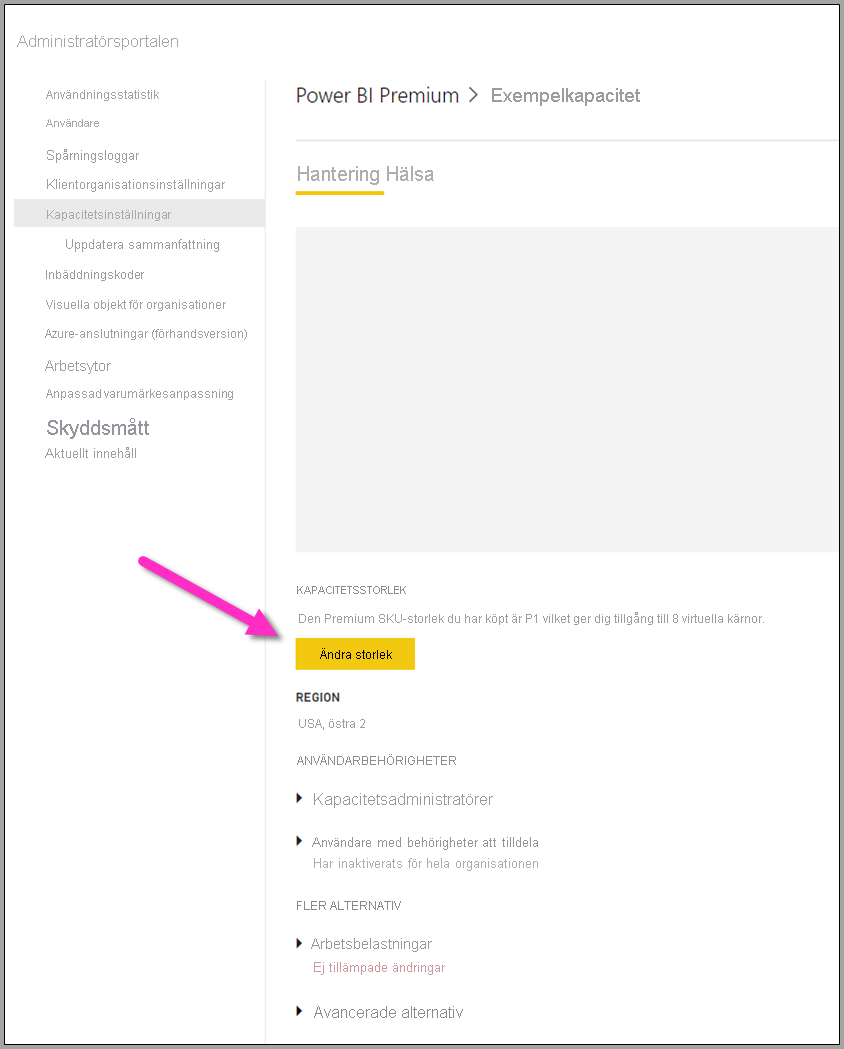
Din Power BI Premium-kapacitet återspeglar de resurser som är tillgängliga för dina dataflöden. Du kan ändra kapacitetens storlek genom att välja knappen Ändra storlek , enligt följande bild.
SKU:er för Premium-kapacitet – skala upp maskinvaran
Power BI Premium-arbetsbelastningar använder v-kärnor för att hantera snabba frågor i de olika arbetsbelastningstyperna. Kapaciteter och SKU:er innehåller ett diagram som illustrerar de aktuella specifikationerna för var och en av de tillgängliga arbetsbelastningserbjudandena. Kapaciteter av A3 och större kan dra nytta av beräkningsmotorn, så när du vill använda den förbättrade beräkningsmotorn börjar du där.
Förbättrad beräkningsmotor – en möjlighet att förbättra prestanda
Den förbättrade beräkningsmotorn är en motor som kan påskynda dina frågor. Power BI använder en beräkningsmotor för att bearbeta dina frågor och uppdateringsåtgärder. Den förbättrade beräkningsmotorn är en förbättring jämfört med standardmotorn och fungerar genom att läsa in data till en SQL Cache och använder SQL för att påskynda tabelltransformering, uppdatera åtgärder och aktivera DirectQuery-anslutning. Om din affärslogik tillåter det när den är konfigurerad till På eller Optimerad för beräknade entiteter, använder Power BI SQL snabbare prestanda. Att ha motorn På tillhandahåller även DirectQuery-anslutning. Kontrollera att dataflödesanvändningen utnyttjar den förbättrade beräkningsmotorn korrekt. Användare kan konfigurera den förbättrade beräkningsmotorn så att den är på, optimerad eller inaktiverad per dataflöde.
Kommentar
Den förbättrade beräkningsmotorn är ännu inte tillgänglig i alla regioner.
Vägledning för vanliga scenarier
Det här avsnittet innehåller vägledning för vanliga scenarier när du använder dataflödesarbetsbelastningar med Power BI Premium.
Långsamma uppdateringstider
Långsamma uppdateringstider är vanligtvis ett parallellitetsproblem. Du bör granska följande alternativ i ordning:
Ett viktigt begrepp för långsamma uppdateringstider är typen av dataförberedelse. När du kan optimera dina långsamma uppdateringstider genom att dra nytta av att datakällan faktiskt förbereder och utför frågelogik i förväg bör du göra det. När du använder en relationsdatabas, till exempel SQL som källa, kan du se om den första frågan kan köras på källan och använda källfrågan för ditt första extraheringsdataflöde för datakällan. Om du inte kan använda en intern fråga i källsystemet utför du åtgärder som dataflödesmotorn kan vika till datakällan.
Utvärdera utspridda uppdateringstider på samma kapacitet. Uppdateringsåtgärder är en process som kräver betydande beräkning. Att använda vår restauranganalogi är att sprida ut uppdateringstider som att begränsa antalet gäster i din restaurang. Precis som restauranger schemalägger gäster och planerar för kapacitet, vill du också överväga uppdateringsåtgärder under tider då användningen inte är som störst. Detta kan gå långt för att lindra belastningen på kapaciteten.
Om stegen i det här avsnittet inte ger önskad grad av parallellitet kan du överväga att uppgradera din kapacitet till en högre SKU. Följ sedan föregående steg i den här sekvensen igen.
Använda beräkningsmotorn för att förbättra prestanda
Utför följande steg för att aktivera arbetsbelastningar för att utlösa beräkningsmotorn och alltid förbättra prestandan:
För beräknade och länkade entiteter på samma arbetsyta:
För inmatning fokuserar du på att få data till lagringen så snabbt som möjligt, med filter endast om de minskar den totala datamängdens storlek. Det är bästa praxis att hålla omvandlingslogik åtskild från det här steget och låta motorn fokusera på den första insamlingen av ingredienser. Därefter separerar du omvandlingen och affärslogik i ett separat dataflöde på samma arbetsyta med hjälp av länkade eller beräknade entiteter. Detta gör att motorn kan aktivera och påskynda dina beräkningar. Logiken måste förberedas separat innan den kan dra nytta av beräkningsmotorn.
Se till att du utför de åtgärder som viker, till exempel sammanslagningar, kopplingar, konvertering och andra.
Skapa dataflöden inom publicerade riktlinjer och begränsningar.
Du kan också använda DirectQuery.
Beräkningsmotorn är aktiverad men prestandan är långsam
Utför följande steg när du undersöker scenarier där Beräkningsmotorn är på, men du ser långsammare prestanda:
Begränsa beräknade och länkade entiteter som finns på arbetsytan.
När du utför den första uppdateringen med beräkningsmotorn aktiverad skrivs data i sjön och i cacheminnet. Den här dubbelskrivningen innebär att dessa uppdateringar blir långsammare.
Om du har ett dataflöde som länkar till flera dataflöden ska du schemalägga uppdateringar av källdataflödena så att de inte uppdateras samtidigt.
Relaterat innehåll
Följande artiklar innehåller mer information om dataflöden och Power BI:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för