Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
I den här proceduren skapar du en tabell i Dataverse och fyller tabellen med data från en OData-feed med hjälp av Power Query. Du kan använda samma tekniker för att integrera data från dessa online- och lokala källor, bland annat:
- SQL Server
- Salesforce
- IBM DB2
- Access
- Excel
- Webb-API:er
- OData-feeds
- Textfiler
Du kan också filtrera, transformera och kombinera data innan du läser in dem i en ny eller befintlig tabell.
Om du inte har en licens för Power Apps kan du registrera dig gratis.
Förutsättningar
Innan du börjar följa den här artikeln:
- Växla till en miljö där du kan skapa tabeller.
- Du måste ha en Power Apps-plan per användarplan eller Power Apps per appplan.
Ange källdata
Logga in på Power Apps.
I navigeringsfönstret, välj Surfplattor.
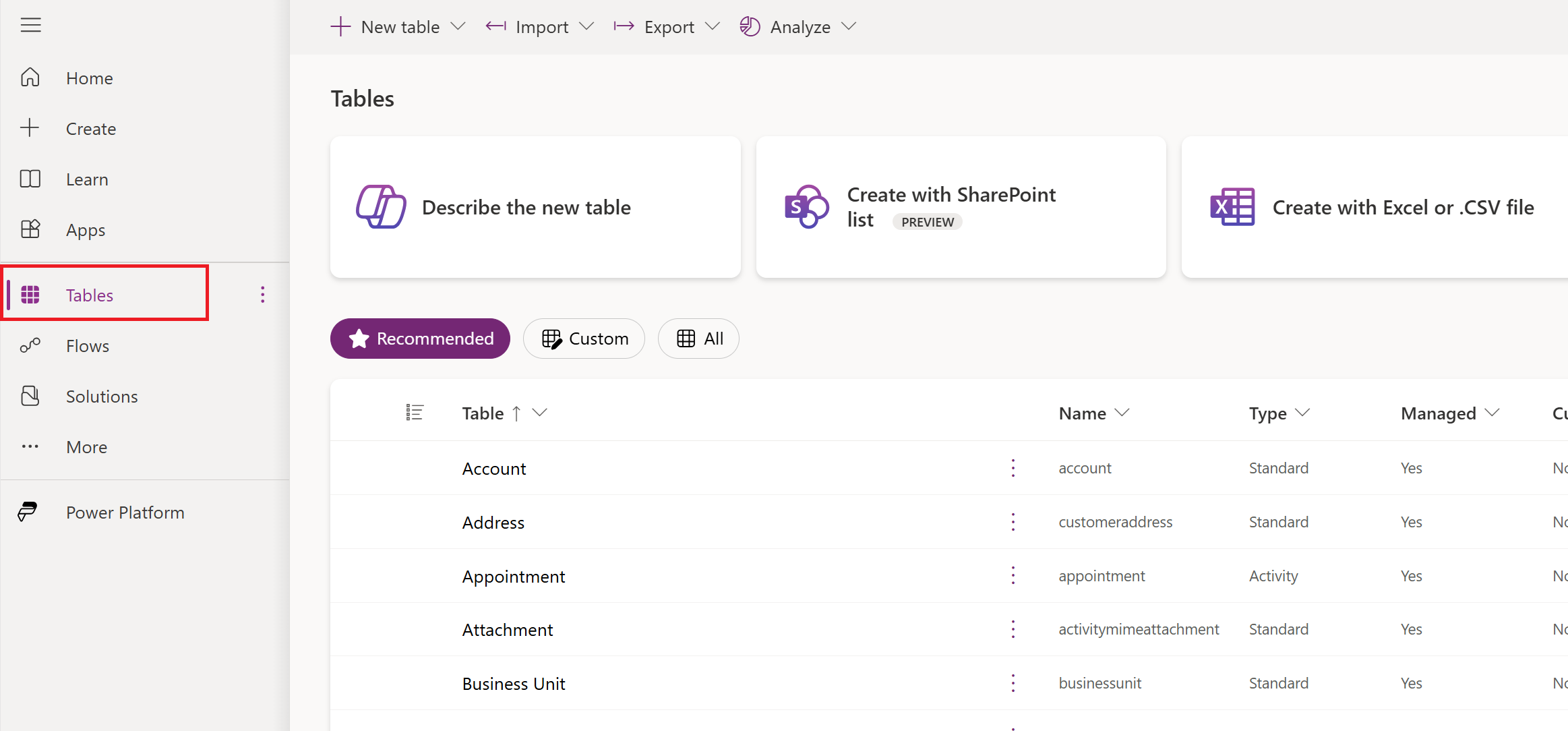
I kommandomenyn väljer du Importera>importera data.
I listan över datakällor väljer du OData.
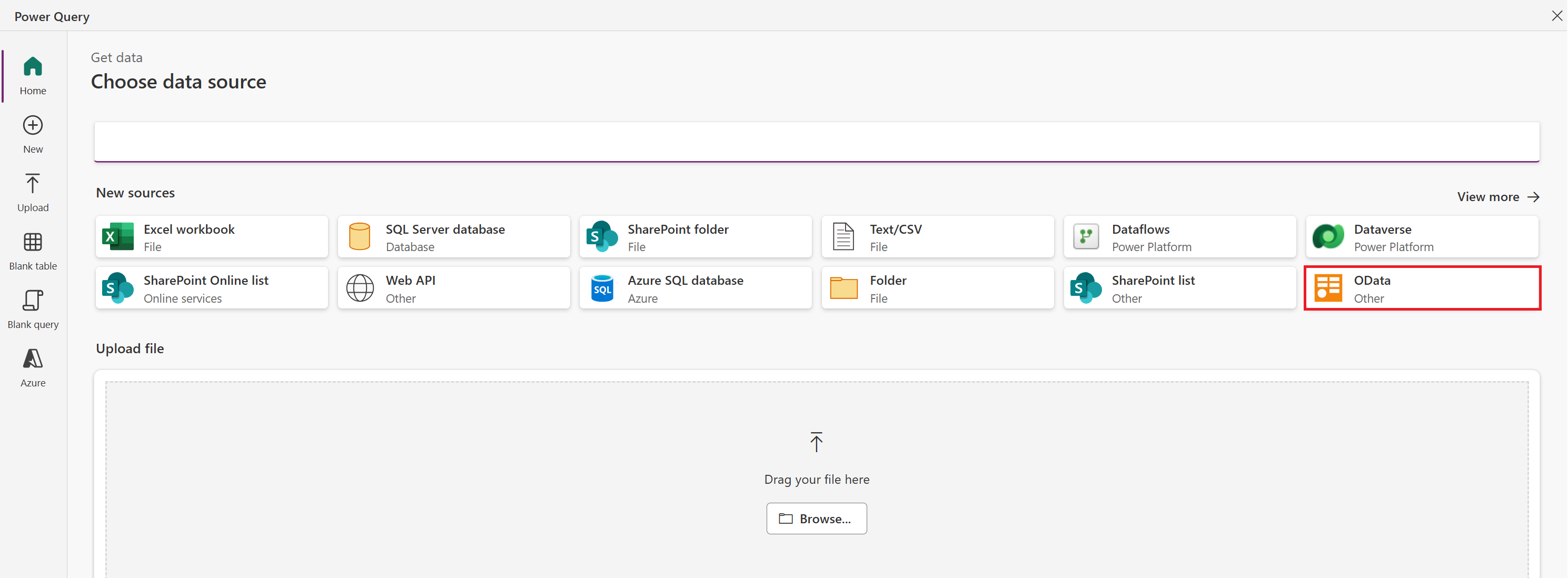
Under Anslutningsinställningar skriver eller klistrar du in följande URL och väljer sedan Nästa:
https://services.odata.org/V4/Northwind/Northwind.svc/Markera kryssrutan Kunder i listan över tabeller och välj sedan Nästa.
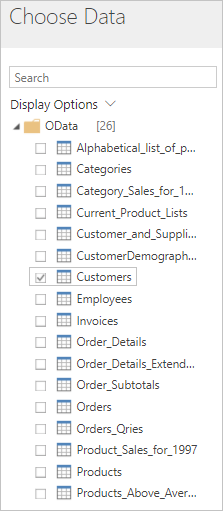
(valfritt) Ändra schemat så att det passar dina behov genom att välja vilka kolumner som ska inkluderas, transformera tabellen på ett eller flera sätt, lägga till ett index eller en villkorsstyrd kolumn eller göra andra ändringar.
I det nedre högra hörnet väljer du Nästa.


Ange måltabellen (förhandsversion)
Under Läs in inställningar väljer du Läs in till ny tabell.

Du kan ge den nya tabellen ett annat namn eller visningsnamn, men låt standardvärdena följa den här självstudien exakt.
I kolumnen Unikt primärt namn väljer du ContactName och sedan Nästa.
Du kan ange en annan primärnamnskolumn, mappa en annan kolumn i källtabellen till varje kolumn i tabellen som du skapar, eller båda. Du kan också ange om textkolumner i frågeutdata ska skapas som antingen flerradstext eller enkelradstext i Dataversum. Om du vill följa den här självstudien exakt lämnar du standardkolumnmappningen.
Välj Uppdatera manuellt för Power Query – Uppdatera inställningar och välj sedan Publicera.
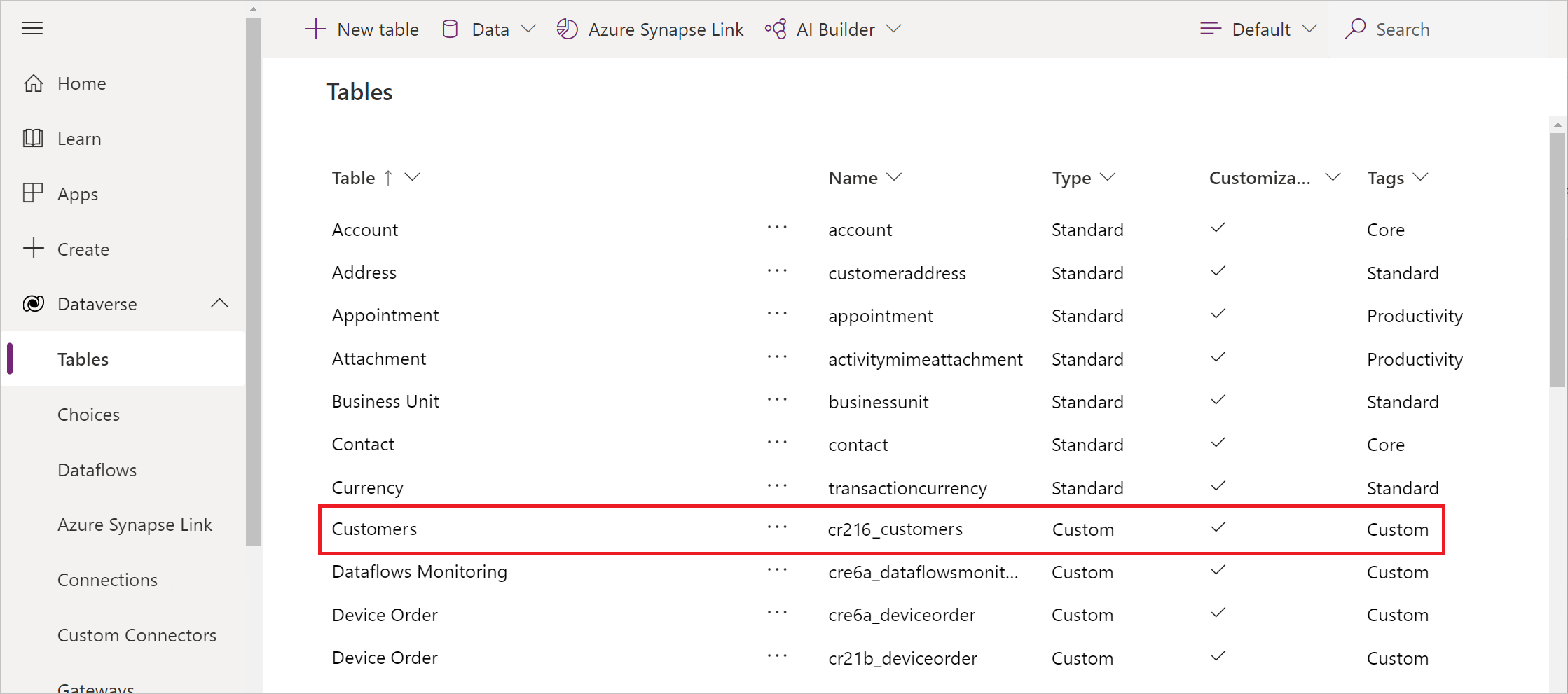
Under Dataverse (nära den vänstra kanten) väljer du Tabeller för att visa listan över tabeller i databasen.
Tabellen Kunder som du skapade från en OData-feed visas som en anpassad tabell.


Varning
Befintliga data kan ändras eller tas bort vid inläsning av data till en Dataverse-tabell samtidigt som rader som inte längre finns i frågeutdata är aktiverade eller en primärnyckelkolumn har definierats.
Läs in till befintlig tabell (förhandsversion)
Om du väljer Läs in till befintlig tabell kan du ange en befintlig Dataverse-tabell att läsa in data till.
När du väljer listrutan tabell kan det finnas upp till tre rekommenderade Dataverse-tabeller att välja från överst i listrutan, följt av alla andra Dataverse-tabeller. Dessa tabellrekommendationer baseras på att jämföra kolumnmetadata (kolumnnamn och kolumntyper) med kolumnmetadata för befintliga Dataverse-tabeller. Upp till tre Dataverse-tabeller rekommenderas med den starkaste rekommendationen som anges först. Om inga rekommendationer hittas visas endast alla tabeller i listrutan.

När du har valt vilken Dataverse-tabell som data ska läsas in i väljer du sedan importmetoden. Lägg till är markerat som standard och lägger till data som fler rader i den tidigare valda Dataverse-tabellen. Sammanslagning uppdaterar befintliga rader i dataversumtabellen. Om Sammanfogning är markerat finns det ett alternativ för att välja den primära nyckelkolumn som du vill använda.

Kolumnmappning (förhandsversion)
När du har valt en dataverse-måltabell och angett importmetoden grupperas kolumnerna i mappad, möjlig matchning och avmappad. Du kan växla mellan dessa grupper genom att välja flikarna Mappad, Möjlig matchning eller Avmappad längst upp eller stanna kvar på standardfliken Visa alla som visar alla mappningar.

Käll- och målkolumnmappningarna grupperas på följande sätt:
Mappad: Semantisk matchning med hög konfidens mellan betydelserna för kolumnnamnen och båda kolumndatatyperna är desamma.
Avmappad: Det finns inga semantiska kolumnmatchningar med hög konfidens för den här kolumnen. Om den här kolumnen är en obligatorisk kolumn måste du manuellt välja en källkolumn som du vill mappa dessa data till innan du fortsätter.
Möjlig matchning: Semantisk matchning mellan betydelserna för kolumnnamnen, men käll- och målkolumndatatyperna skiljer sig.
När manuella ändringar görs i mappningen av källkolumnen ändras statusen till Mappad om inte kolumndatatyperna skiljer sig åt. I så fall uppdateras statusen till Möjlig matchning. Precis som med alla möjliga matchningar rekommenderar ett rekommenderat åtgärdsmeddelande att du går tillbaka ett steg i dataflödet och ändrar källkolumntypen så att den matchar målkolumntypen i tabellen Dataverse.
Kända begränsningar
För närvarande kan AI-assisterad mappning bara identifiera typmatchningar mellan kolumner. Andra utmaningar med kolumnmappning i följande lista identifieras inte eftersom de kräver förhandsversion av posterna för inkommande data:
Trunkering: Hög konfidens i semantisk matchning mellan källa och mål, men minst en post i källan har fler tecken än målkolumnens teckengräns.
Värdegränser: Hög konfidens i semantisk matchning mellan källa och mål, men minst en post i källan innehåller ett värde utanför intervallet för de värdegränser som anges av målkolumnen.
Uppslagsvärden: Hög konfidens i semantisk matchning mellan källa och mål, men minst en post i källan innehåller ett värde som inte finns i uppslagsvärdet som anges av målkolumnen.
Kontakta administratören om ett felmeddelande om behörigheter visas.
Förslag på tabellval och kolumnmappning tillhandahålls av en lösning som kanske inte är tillgänglig i en specifik Power Platform-miljö. Om den här lösningen inte kan identifieras tillhandahålls inte förslag på tabellval och kolumnmappning av systemet. Du kan dock fortsätta att fortsätta manuellt.