Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln innehåller några exempelscenarier för vart och ett av de tre möjliga utfallen för frågeveckling. Den innehåller också några förslag på hur du får ut mesta möjliga av frågevikningsmekanismen och vilken effekt den kan ha på dina frågor.
Scenariot
Tänk dig ett scenario där du med hjälp av Wide World Importers-databasen för Azure Synapse Analytics SQL-databasen har till uppgift att skapa en fråga i Power Query som ansluter till fact_Sale tabellen och hämtar de senaste 10 försäljningarna med endast följande fält:
- Försäljningskod
- Kundnyckel
- Fakturadatumnyckel
- Description
- Kvantitet
Anmärkning
I demonstrationssyfte använder den här artikeln databasen som beskrivs i handledningen om hur du laddar upp Wide World Importers-databasen i Azure Synapse Analytics. Den största skillnaden i den här artikeln är att fact_Sale tabellen endast innehåller data för år 2000, med totalt 3 644 356 rader.
Även om resultatet kanske inte exakt matchar de resultat du får genom att följa handledningen i Azure Synapse Analytics-dokumentationen, är målet med den här artikeln att visa de grundläggande principerna och den inverkan som frågedelegering kan ha i dina frågor.

Den här artikeln visar tre sätt att uppnå samma utdata med olika nivåer av frågedelegering:
- Ingen frågedelegering
- Partiell frågedelegering
- Fullständig frågedelegering
Inget frågedelegeringsexempel
Viktigt!
Frågor som enbart förlitar sig på ostrukturerade datakällor eller som inte har någon beräkningsmotor, till exempel CSV- eller Excel-filer, har inte frågedelegeringsfunktioner. Det innebär att Power Query utvärderar alla nödvändiga datatransformeringar med hjälp av Power Query-motorn.
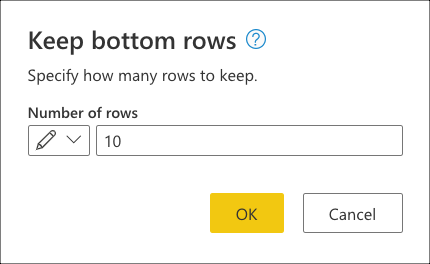
När du har anslutit till databasen och navigerat till fact_Sale tabellen väljer du transformeringen Behåll de nedersta raderna som finns i gruppen Minska rader på fliken Start .
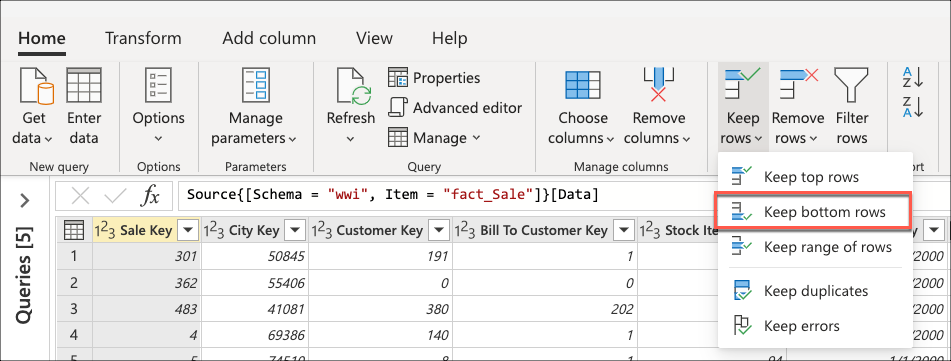
När du har valt den här transformen visas en ny dialogruta. I den här nya dialogrutan kan du ange det antal rader som du vill behålla. I det här fallet anger du värdet 10 och väljer sedan OK.
Tips/Råd
I det här fallet ger den här åtgärden resultatet av de senaste 10 försäljningarna. I de flesta scenarier rekommenderar vi att du anger en mer explicit logik som definierar vilka rader som anses vara sist genom att använda en sorteringsåtgärd i tabellen.
Välj sedan transformen Välj kolumner som finns i gruppen Hantera kolumner på fliken Start . Du kan sedan välja de kolumner som du vill behålla från tabellen och ta bort resten.
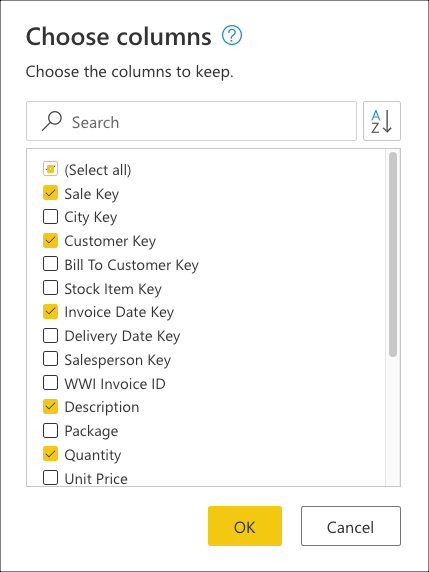
I dialogrutan Välj kolumner väljer du slutligen kolumnerna Sale Key, Customer Key, Invoice Date Key, Descriptionoch Quantity och väljer sedan OK.
Följande kodexempel är det fullständiga M-skriptet för frågan du skapade:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Kept bottom rows" = Table.LastN(Navigation, 10),
#"Choose columns" = Table.SelectColumns(
#"Kept bottom rows",
{"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}
)
in
#"Choose columns""
Ingen frågekomprimering: Förståelse för frågeutvärderingen
Under Tillämpade steg i Power Query-redigeraren ser du att frågedelegeringsindikatorerna för Behållna nedre rader och Välj kolumner markeras som steg som utvärderas utanför datakällan, dvs. av Power Query-motorn.
Fönstret Tillämpade steg för frågan med indikatorerna för frågekomprimering som visar stegen Behållna nedre rader och Borttagna övriga kolumner.
Du kan högerklicka på det sista steget i frågan, det som heter Välj kolumner, och välja det alternativ som läser Visa frågeplan. Målet med frågeplanen är att ge dig en detaljerad vy över hur frågan körs. Mer information om den här funktionen finns i Frågeplan.

Varje ruta i föregående bild kallas för en nod. En nod representerar åtgärdsfördelningen för att uppfylla den här frågan. Noder som representerar datakällor, till exempel SQL Server i föregående exempel och Value.NativeQuery noden, representerar vilken del av frågan som avlastas till datakällan. Resten av noderna, i det här fallet Table.LastN och Table.SelectColumns markerade i rektangeln i föregående bild, utvärderas av Power Query-motorn. Dessa två noder representerar de två transformeringar som du har lagt till, Bevarade nedre rader och Välj kolumner. Resten av noderna representerar åtgärder som sker på datakällans nivå.
Om du vill se den exakta begäran som skickas till datakällan väljer du Visa information i Value.NativeQuery noden.

Den här begäran om datakälla är på det ursprungliga språket för datakällan. I det här fallet är språket SQL och den här instruktionen representerar en begäran för alla rader och fält från fact_Sale tabellen.
Genom att konsultera den här datakällans begäran kan du bättre förstå den berättelse som frågeplanen försöker förmedla:
-
Sql.Database: Den här noden representerar datakällans åtkomst. Ansluter till databasen och skickar metadatabegäranden för att förstå dess funktioner. -
Value.NativeQuery: Representerar den begäran som genererades av Power Query för att uppfylla frågan. Power Query skickar databegäranden i en intern SQL-instruktion till datakällan. I det här fallet representerar det alla poster och fält (kolumner) frånfact_Saletabellen. I det här scenariot är det här fallet oönskat eftersom tabellen innehåller miljontals rader och intresset bara är i de sista 10. -
Table.LastN: När Power Query tar emot alla poster frånfact_Saletabellen använder den Power Query-motorn för att filtrera tabellen och behålla endast de sista 10 raderna. -
Table.SelectColumns: Power Query använder nodensTable.LastNutdata och tillämpar en ny transformering med namnetTable.SelectColumns, som väljer de specifika kolumner som du vill behålla från en tabell.
För utvärderingen var den här frågan tvungen att ladda ned alla rader och fält från fact_Sale tabellen. Den här frågan tog i genomsnitt 6 minuter och 1 sekund att bearbetas i en standardinstans av Power BI-dataflöden (som står för utvärdering och inläsning av data till dataflöden).
Exempel på partiell frågedelegering
När du har anslutit till databasen och navigerat till fact_Sale tabellen börjar du med att välja de kolumner som du vill behålla från tabellen. Välj transformen Välj kolumner som finns i gruppen Hantera kolumner på fliken Start . Den här transformeringen hjälper dig att uttryckligen välja de kolumner som du vill behålla från tabellen och ta bort resten.
I dialogrutan Välj kolumner väljer du kolumnerna Sale Key, Customer Key, Invoice Date Key, Descriptionoch Quantity och sedan OK.
Nu skapar du logik som sorterar tabellen så att den sista försäljningen finns längst ned i tabellen.
Sale Key Välj kolumnen, som är primärnyckeln och inkrementell sekvens eller index för tabellen. Sortera tabellen med endast det här fältet i stigande ordning från snabbmenyn för kolumnen.
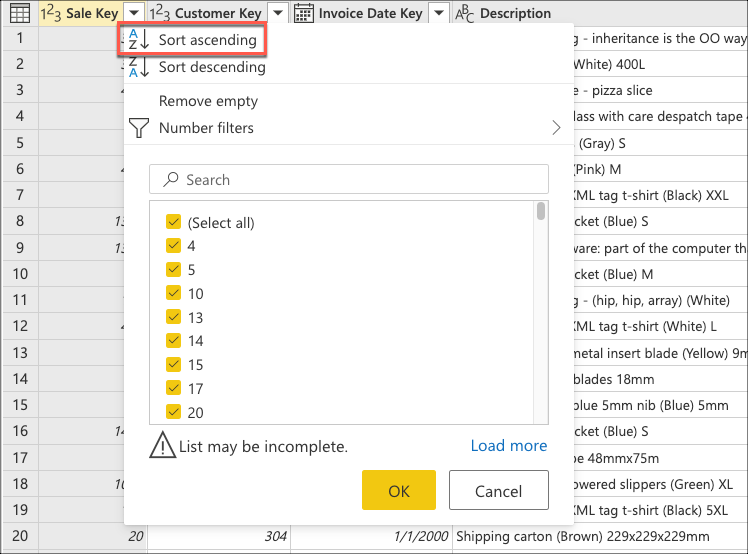
Välj sedan snabbmenyn för tabellen och välj transformeringen Behåll de nedre raderna .
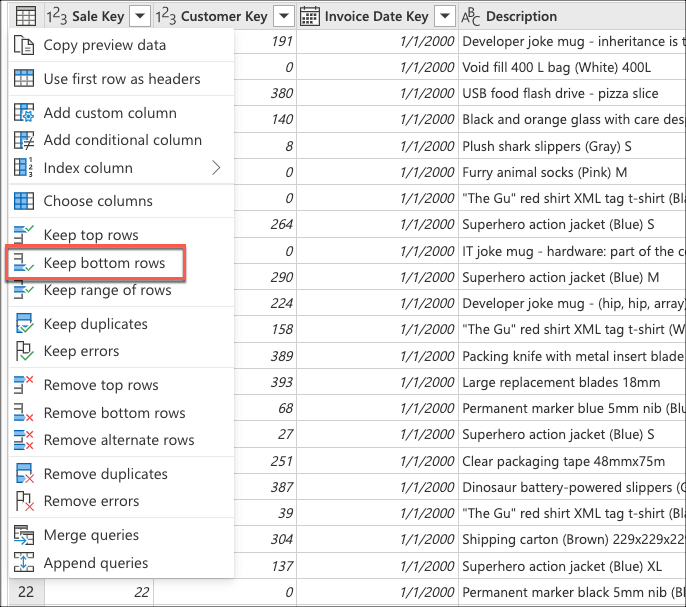
I Behåll de nedre raderna anger du värdet 10 och väljer sedan OK.
Följande kodexempel är det fullständiga M-skriptet för frågan du skapade:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(
Navigation,
{"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}
),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Ascending}}),
#"Kept bottom rows" = Table.LastN(#"Sorted rows", 10)
in
#"Kept bottom rows"
Exempel på partiell frågedelning: Förståelse av frågeutvärderingen
När du kontrollerar panelen för tillämpade steg ser du att indikatorerna för frågedelegering visar att den senaste transformationen som du lade till, Kept bottom rows, är markerad som ett steg som utvärderas utanför datakällan eller, det vill säga, av Power Query-motorn.
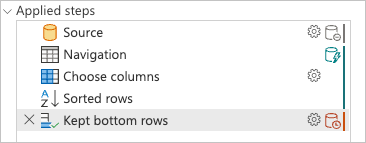
Du kan högerklicka på det sista steget i frågan, det som heter Kept bottom rows, och välja alternativet Frågeplan för att bättre förstå hur frågan kan utvärderas.

Varje ruta i föregående bild kallas för en nod. En nod representerar varje process som måste ske (från vänster till höger) för att din fråga ska kunna utvärderas. Vissa av dessa noder kan utvärderas i datakällan medan andra, till exempel noden för Table.LastN, som representeras av steget Behållna nedre rader , utvärderas med hjälp av Power Query-motorn.
Om du vill se den exakta begäran som skickas till datakällan väljer du Visa information i Value.NativeQuery noden.

Den här begäran är på datakällans modersmål. I det här fallet är språket SQL och den här instruktionen representerar en begäran för alla rader, med endast de begärda fälten från tabellen fact_Sale som sorteras efter Sale Key fältet.
Genom att konsultera den här datakällans begäran kan du bättre förstå den berättelse som den fullständiga frågeplanen försöker förmedla. Ordningen på noderna är en sekventiell process som börjar med att begära data från datakällan:
-
Sql.Database: Ansluter till databasen och skickar metadatabegäranden för att förstå dess funktioner. -
Value.NativeQuery: Representerar den begäran som genererats av Power Query för att uppfylla frågan. Power Query skickar databegäranden i en intern SQL-instruktion till datakällan. I det här fallet innefattar det alla poster, med endast de begärda fälten frånfact_Sale-tabellen i databasen som är sorterade i stigande ordning efterSales Key-fältet. -
Table.LastN: När Power Query tar emot alla poster frånfact_Saletabellen använder den Power Query-motorn för att filtrera tabellen och behålla endast de sista 10 raderna.
För utvärderingen var den här frågan tvungen att ladda ned alla rader och endast de obligatoriska fälten fact_Sale från tabellen. Det tog i genomsnitt 3 minuter och 4 sekunder att bearbetas i en standardinstans av Power BI-dataflöden (som står för utvärdering och inläsning av data till dataflöden).
Exempel på fullständig frågedelning
När du har anslutit till databasen och navigerat till fact_Sale tabellen börjar du med att välja de kolumner som du vill behålla från tabellen. Välj transformen Välj kolumner som finns i gruppen Hantera kolumner på fliken Start . Den här transformeringen hjälper dig att uttryckligen välja de kolumner som du vill behålla från tabellen och ta bort resten.
I Välj kolumner väljer du kolumnerna Sale Key, Customer Key, Invoice Date Key, Descriptionoch Quantity och sedan OK.
Nu skapar du logik som sorterar tabellen så att den sista försäljningen finns överst i tabellen.
Sale Key Välj kolumnen, som är primärnyckeln och inkrementell sekvens eller index för tabellen. Sortera tabellen endast med hjälp av det här fältet i fallande ordning från snabbmenyn för kolumnen.
Välj sedan snabbmenyn för tabellen och välj transformeringen Behåll de översta raderna.
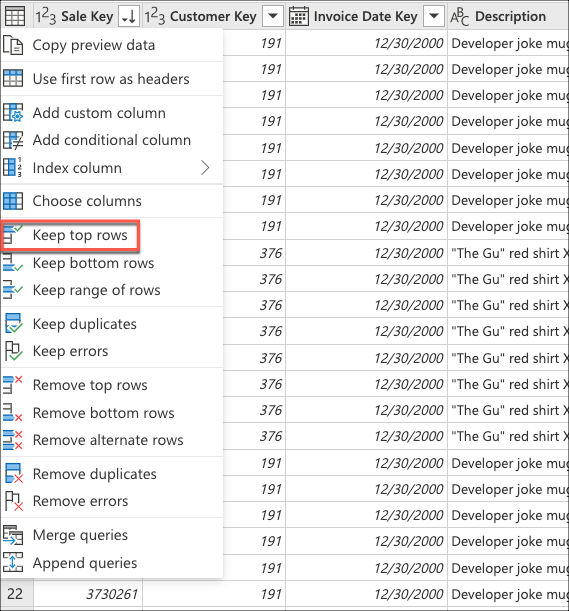
I Behåll de översta raderna anger du värdet 10 och väljer sedan OK.
Följande kodexempel är det fullständiga M-skriptet för frågan du skapade:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(
Navigation,
{"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}
),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Descending}}),
#"Kept top rows" = Table.FirstN(#"Sorted rows", 10)
in
#"Kept top rows"
Exempel på fullständig frågedelegering: Förstå frågeutvärderingen
När du kontrollerar det tillämpade stegfönstret bör du observera att frågefällningsindikatorerna visar att de transformeringar som du har lagt till, Välj kolumner, Sorterade rader, och Bevarade översta rader, är markerade som steg som utvärderas vid datakällan.

Du kan högerklicka på det sista steget i frågan, det som heter Bevarade översta rader, och välja det alternativ som läser Frågeplan.

Den här begäran är på datakällans modersmål. I det här fallet är språket SQL och den här instruktionen representerar en begäran för alla rader och fält från fact_Sale tabellen.
Genom att konsultera den här datakällans fråga kan du bättre förstå den berättelse som den fullständiga frågeplanen försöker förmedla:
-
Sql.Database: Ansluter till databasen och skickar metadatabegäranden för att förstå dess funktioner. -
Value.NativeQuery: Representerar den begäran som genererats av Power Query för att uppfylla frågan. Power Query skickar databegäranden i en intern SQL-instruktion till datakällan. I det här fallet representerar det en begäran om endast de 10 översta posterna ifact_Saletabellen, med endast de obligatoriska fälten efter att ha sorterats i fallande ordning med hjälp av fältetSale Key.
Anmärkning
Det finns ingen sats som kan användas för att VÄLJA de nedre raderna i en tabell på T-SQL-språket, men det finns en TOP-sats som hämtar de översta raderna i en tabell.
För utvärderingen laddar den här frågan bara ned 10 rader, med endast de fält som du begärde från fact_Sale tabellen. Den här frågan tog i genomsnitt 31 sekunder att bearbeta i en standardinstans av Power BI-dataflöden (som står för utvärdering och inläsning av data till dataflöden).
Prestandajämförelse
För att bättre förstå vilken effekt frågedelegering har i dessa frågor kan du uppdatera dina frågor, registrera den tid det tar att uppdatera varje fråga fullständigt och jämföra dem. För enkelhetens skull innehåller den här artikeln de genomsnittliga uppdateringstiderna som samlas in med power BI-dataflödens uppdateringsmekanik vid anslutning till en dedikerad Azure Synapse Analytics-miljö med DW2000c som tjänstnivå.
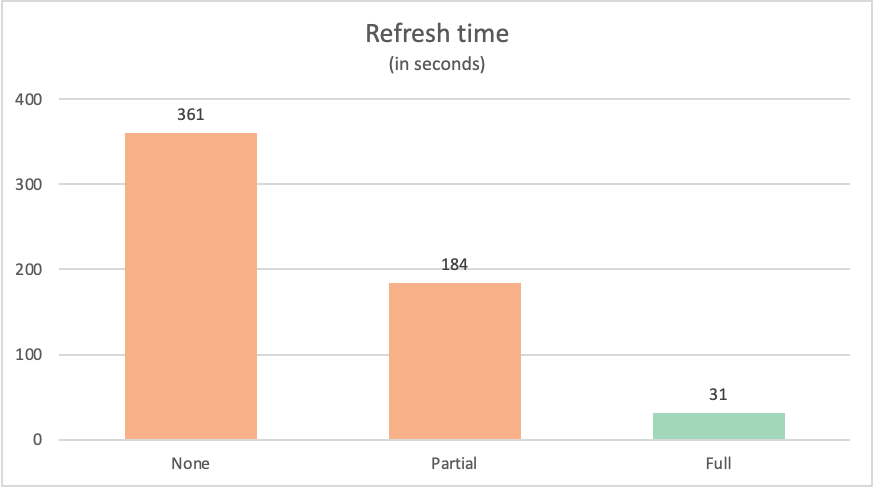
Uppdateringstiden för varje fråga var följande:
| Example | Etikett | Tid i sekunder |
|---|---|---|
| Ingen frågedelegering | None | 361 |
| Partiell frågedelegering | Partial | 184 |
| Fullständig frågedelegering | Fullständig | 31 |
Det är ofta så att en fråga som helt viks tillbaka till datakällan överträffar liknande frågor som inte helt viks tillbaka till datakällan. Det kan finnas många orsaker till att så är fallet. Dessa orsaker sträcker sig från komplexiteten i de transformeringar som din fråga utför, till frågeoptimeringar som implementeras i din datakälla, till exempel index och dedikerad databehandling och nätverksresurser. Det finns dock två specifika nyckelprocesser som query folding försöker använda för att minimera den påverkan som dessa processer har på Power Query.
- Data på väg
- Transformeringar som körs av Power Query-motorn
I följande avsnitt förklaras den effekt som dessa två processer har i de tidigare nämnda frågorna.
Data på väg
När en fråga körs försöker den hämta data från datakällan som ett av de första stegen. Vilka data som hämtas från datakällan definieras av frågevikningsmekanismen. Den här mekanismen identifierar stegen från frågan som kan avlastas till datakällan.
I följande tabell visas antalet rader som begärs från fact_Sale databasens tabell. Tabellen innehåller också en kort beskrivning av SQL-instruktionen som skickas för att begära sådana data från datakällan.
| Example | Etikett | Begärda rader | Description |
|---|---|---|---|
| Ingen frågedelegering | None | 3644356 | Begäran om alla fält och alla poster från fact_Sale tabellen |
| Partiell frågedelegering | Partial | 3644356 | Begär alla poster men endast de obligatoriska fälten från fact_Sale-tabellen efter att den har sorterats efter Sale Key-fältet. |
| Fullständig frågedelegering | Fullständig | 10 | Begär endast de obligatoriska fälten och de 10 främsta posterna i fact_Sale-tabellen efter att de har sorterats i fallande ordning efter fältet Sale Key. |
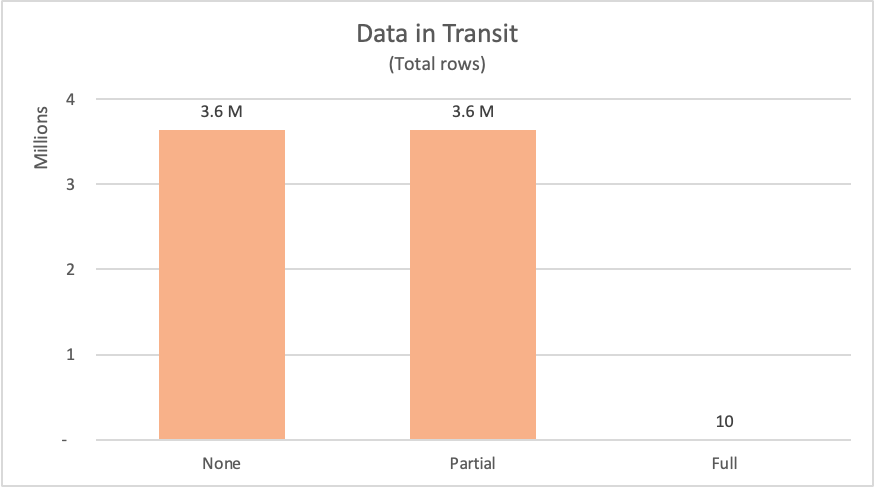
När du begär data från en datakälla måste datakällan beräkna resultatet för begäran och sedan skicka data till beställaren. Även om databehandlingsresurserna redan har nämnts kan nätverksresurserna för att flytta data från datakällan till Power Query och sedan låta Power Query effektivt ta emot data och förbereda dem för de transformeringar som sker lokalt ta lite tid beroende på datastorleken.
För de exempel som visades var Power Query tvungen att begära över 3,6 miljoner rader från datakällan för exemplen utan frågedelegering och partiell frågedelegering. För det fullständiga frågebearbetningsexemplet begärde det bara 10 rader. För de begärda fälten begärde exemplet utan frågevikning alla tillgängliga fält från tabellen. Både den partiella frågekomprimeringen och exemplen på fullständig frågekomprimering skickade bara en begäran på precis de fält de behövde.
Försiktighet
Vi rekommenderar att du implementerar inkrementella uppdateringslösningar som använder query folding för frågor eller tabeller med stora mängder data. Olika produktintegreringar av Power Query implementerar tidsgränser för att avsluta tidskrävande frågor. Vissa datakällor implementerar också tidsgränser för långvariga sessioner och försöker köra dyra frågor mot sina servrar. Mer information: Använda inkrementell uppdatering med dataflöden och inkrementell uppdatering för semantiska modeller
Transformeringar som körs av Power Query-motorn
Den här artikeln visar hur du kan använda frågeplanen för att bättre förstå hur frågan kan utvärderas. I frågeplanen kan du se de exakta noderna för de transformeringsåtgärder som utförs av Power Query-motorn.
I följande tabell visas noderna från frågeplanerna för de tidigare frågorna som skulle ha utvärderats av Power Query-motorn.
| Example | Etikett | Transformeringsnoder för Power Query-motorn |
|---|---|---|
| Ingen frågedelegering | None |
Table.LastN, Table.SelectColumns |
| Partiell frågedelegering | Partial | Table.LastN |
| Fullständig frågedelegering | Fullständig | — |
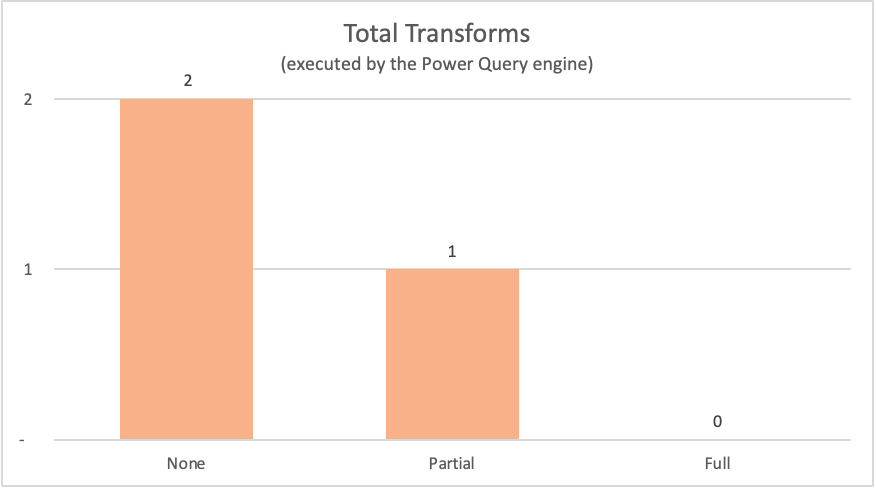
För exemplen som visas i den här artikeln kräver det fullständiga frågedelegeringsexemplet inga transformeringar i Power Query-motorn eftersom den obligatoriska utdatatabellen kommer direkt från datakällan. De andra två frågorna krävde däremot viss beräkning vid Power Query-motorn. På grund av mängden data som behöver bearbetas av dessa två frågor tar processen för dessa exempel längre tid än det fullständiga frågedelegeringsexemplet.
Transformeringar kan grupperas i följande kategorier:
| Typ av operator | Description |
|---|---|
| Fjärr | Operatörer som är datakällans noder. Utvärderingen av dessa operatorer sker utanför Power Query. |
| Streaming | Operatorer är genomströmningsoperatorer. Med ett enkelt filter kan du till exempel Table.SelectRows vanligtvis filtrera resultatet när de passerar genom operatorn och behöver inte samla in alla rader innan du flyttar data.
Table.SelectColumns och Table.ReorderColumns är andra exempel på den här typen av operatorer. |
| Fullständig genomsökning | Operatorer som behöver samla in alla rader innan data kan gå vidare till nästa operator i kedjan. Om du till exempel vill sortera data måste Power Query samla in alla data. Andra exempel på fullständiga genomsökningsoperatorer är Table.Group, Table.NestedJoinoch Table.Pivot. |
Tips/Råd
Även om inte varje transformering är densamma ur prestandasynpunkt är det i de flesta fall bättre att ha färre transformeringar.
Överväganden och förslag
- Följ metodtipsen när du skapar en ny fråga, enligt metodtipsen i Power Query.
- Använd frågeviksindikatorerna för att kontrollera vilka steg som hindrar frågan från att vikas ihop. Ändra ordning på dem om det behövs för att öka vikningen.
- Använd frågeplanen för att avgöra vilka transformeringar som sker i Power Query-motorn för ett visst steg. Överväg att ändra din befintliga fråga genom att ordna om stegen. Kontrollera sedan frågeplanen för det sista steget i frågan igen och se om frågeplanen ser bättre ut än den föregående. Den nya frågeplanen har till exempel färre noder än den föregående, och de flesta noderna är "Streaming"-noder och inte "fullständig genomsökning". För datakällor som stöder vikning representerar alla noder i frågeplanen förutom
Value.NativeQueryoch datakällans åtkomstnoder transformeringar som inte viks. - När det är tillgängligt kan du använda alternativet Visa intern fråga (eller Visa datakällfråga) för att se till att frågan kan vikas tillbaka till datakällan. Om det här alternativet är inaktiverat för ditt steg och du använder en källa som normalt aktiverar det, skapade du ett steg som stoppar frågedelegering. Om du använder en källa som inte stöder det här alternativet kan du förlita dig på frågedelegeringsindikatorerna och frågeplanen.
- Använd frågediagnostikverktygen för att bättre förstå de förfrågningar som skickas till din datakälla när frågeihopslagningsmöjligheter är tillgängliga för anslutningen.
- När du kombinerar data som kommer från användning av flera anslutningar försöker Power Query skicka så mycket arbete som möjligt till båda datakällorna samtidigt som de sekretessnivåer som definierats för varje datakälla uppfylls.
- Läs artikeln om sekretessnivåer för att skydda dina frågor från att utlösa ett fel i datasekretessbrandväggen.
- Använd andra verktyg för att kontrollera frågekomprimering från perspektivet för den begäran som tas emot av datakällan. Baserat på exemplet i den här artikeln kan du använda Microsoft SQL Server Profiler för att kontrollera de begäranden som skickas av Power Query och tas emot av Microsoft SQL Server.
- Om du lägger till ett nytt steg i en helt hopvikt fråga och det nya steget också viks, kan Power Query skicka en ny begäran till datakällan istället för att använda en cachead version av det föregående resultatet. I praktiken kan den här processen resultera i till synes enkla åtgärder på en liten mängd data som tar längre tid att uppdatera i förhandsversionen än förväntat. Den här längre uppdateringen beror på att Power Query frågar om datakällan i stället för att arbeta bort en lokal kopia av data.