Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt
Stödet för Machine Learning Studio (klassisk) upphör den 31 augusti 2024. Vi rekommenderar att du byter till Azure Machine Learning innan dess.
Från och med den 1 december 2021 kan du inte längre skapa nya Machine Learning Studio-resurser (klassisk). Du kan fortsätta att använda befintliga Machine Learning Studio-resurser (klassisk) till och med den 31 augusti 2024.
- Se information om hur du flyttar maskininlärningsprojekt från ML Studio (klassisk) till Azure Machine Learning.
- Läs mer om Azure Machine Learning.
Dokumentationen om ML Studio (klassisk) håller på att dras tillbaka och kanske inte uppdateras i framtiden.
Konfigurerar och initierar en K-means-klustermodell
Kategori: Machine Learning/Initiera modell/Klustring
Anteckning
Gäller endast för: Machine Learning Studio ( klassisk)
Liknande dra och släpp-moduler finns i Azure Machine Learning-designern.
Modulöversikt
Den här artikeln beskriver hur du använder K-Means Clustering-modulen i Machine Learning Studio (klassisk) för att skapa en otränad K-means-klustermodell.
K-means är en av de enklaste och mest kända oövervakade inlärningsalgoritmerna och kan användas för en mängd olika maskininlärningsuppgifter, till exempel identifiering av onormala data, klustring av textdokument och analys av en datauppsättning innan du använder andra klassificerings- eller regressionsmetoder. Om du vill skapa en klustringsmodell lägger du till den här modulen i experimentet, ansluter en datauppsättning och anger parametrar som antalet kluster som du förväntar dig, avståndsmåttet som ska användas för att skapa klustren och så vidare.
När du har konfigurerat modulens hyperparametrar ansluter du den otränade modellen till modulen Train Clustering Model eller Sweep Clustering för att träna modellen på de indata som du anger. Eftersom K-means-algoritmen är en oövervakad inlärningsmetod är en etikettkolumn valfri.
- Om dina data innehåller en etikett kan du använda etikettvärdena för att vägleda valet av kluster och optimera modellen.
- Om dina data inte har någon etikett skapar algoritmen kluster som representerar möjliga kategorier, enbart baserat på data.
Tips
Om dina träningsdata har etiketter bör du överväga att använda någon av de övervakade klassificeringsmetoderna i Machine Learning. Du kan till exempel jämföra resultatet av klustring med resultaten när du använder någon av beslutsträdsalgoritmerna för flera klasser.
Förstå k-means-klustring
I allmänhet använder klustring iterativa tekniker för att gruppera fall i en datauppsättning i kluster som innehåller liknande egenskaper. Dessa grupperingar är användbara för att utforska data, identifiera avvikelser i data och så småningom för att göra förutsägelser. Klustringsmodeller kan också hjälpa dig att identifiera relationer i en datauppsättning som du kanske inte logiskt härleder genom surfning eller enkel observation. Av dessa skäl används klustring ofta i de tidiga faserna av maskininlärningsuppgifter, för att utforska data och upptäcka oväntade korrelationer.
När du konfigurerar en klustringsmodell med hjälp av metoden k-means måste du ange ett målnummer k som anger antalet centroider som du vill använda i modellen. Centroiden är en punkt som är representativ för varje kluster. K-means-algoritmen tilldelar varje inkommande datapunkt till ett av klustren genom att minimera kvadratsumman inom klustret.
När du bearbetar träningsdata börjar K-means-algoritmen med en första uppsättning slumpmässigt valda centroider, som fungerar som startpunkter för varje kluster, och tillämpar Lloyds algoritm för att iterativt förfina centroidernas platser. K-means-algoritmen slutar skapa och förfina kluster när den uppfyller ett eller flera av dessa villkor:
Centroiderna stabiliseras, vilket innebär att klustertilldelningar för enskilda punkter inte längre ändras och algoritmen har konvergerat på en lösning.
Algoritmen slutförde körningen av det angivna antalet iterationer.
När du har slutfört träningsfasen använder du modulen Tilldela data till kluster för att tilldela nya ärenden till ett av de kluster som hittades av k-means-algoritmen. Klustertilldelningen utförs genom beräkning av avståndet mellan det nya ärendet och centroiden för varje kluster. Varje nytt ärende tilldelas klustret med närmaste centroid.
Så här konfigurerar du K-Means-kluster
Lägg till modulen K-Means Clustering i experimentet.
Ange hur du vill att modellen ska tränas genom att ange alternativet Skapa träningsläge .
Enskild parameter: Om du känner till de exakta parametrar som du vill använda i klustringsmodellen kan du ange en specifik uppsättning värden som argument.
Parameterintervall: Om du inte är säker på de bästa parametrarna kan du hitta de optimala parametrarna genom att ange flera värden och använda modulen Sweep Clustering för att hitta den optimala konfigurationen.
Tränaren itererar över flera kombinationer av de inställningar som du angav och avgör kombinationen av värden som ger optimala klustringsresultat.
För Antal centroider anger du det antal kluster som du vill att algoritmen ska börja med.
Modellen är inte garanterad att producera exakt det här antalet kluster. Algoriten börjar med det här antalet datapunkter och itererar för att hitta den optimala konfigurationen, enligt beskrivningen i avsnittet Tekniska anteckningar .
Om du utför en parametersvepning ändras namnet på egenskapen till Intervall för Antal centroider. Du kan använda Range Builder för att ange ett intervall, eller så kan du skriva en serie tal som representerar olika antal kluster som ska skapas när varje modell initieras.
Egenskaperna Initiering eller Initiering för svep används för att ange den algoritm som används för att definiera den inledande klusterkonfigurationen.
Första N: Ett visst initialt antal datapunkter väljs från datauppsättningen och används som det ursprungliga medelvärdet.
Kallas även Forgy-metoden.
Slumpmässigt: Algoritmen placerar slumpmässigt en datapunkt i ett kluster och beräknar sedan det ursprungliga medelvärdet som centroid för klustrets slumpmässigt tilldelade punkter.
Kallas även metoden för slumpmässig partition .
K-Means++: Det här är standardmetoden för att initiera kluster.
K-means ++-algoritmen föreslogs 2007 av David Arthur och Sergej Vassilvitskii för att undvika dålig klustring av standard-k-means-algoritmen. K-means ++ förbättrar standard-K-means genom att använda en annan metod för att välja de första klustercentren.
K-Means++Fast: En variant av K-means ++- algoritmen som optimerades för snabbare klustring.
Jämnt: Centroider är placerade som likvärdiga med varandra i d-dimensionalutrymmet för n-datapunkter.
Använd etikettkolumn: Värdena i etikettkolumnen används för att styra valet av centroider.
Ange ett värde som ska användas som startvärde för klusterinitieringen för slumptalsutsäde. Det här värdet kan ha en betydande effekt på valet av kluster.
Om du använder en parametersvepning kan du ange att flera inledande frön ska skapas för att leta efter det bästa startvärde. För Antal frön som ska sopas anger du det totala antalet slumpmässiga startvärden som ska användas som startpunkter.
För Mått väljer du den funktion som ska användas för att mäta avståndet mellan klustervektorer eller mellan nya datapunkter och den slumpmässigt valda centroiden. Machine Learning stöder följande mått för klusteravstånd:
Euklidiska: Det euklidiska avståndet används ofta som ett mått på klusterspridare för K-means-klustring. Det här måttet rekommenderas eftersom det minimerar medelvärdet mellan punkter och centroider.
Cosiné: Cosinine-funktionen används för att mäta klusterlikhet. Cosinélikhet är användbart i fall där du inte bryr dig om längden på en vektor, bara dess vinkel.
För Iterationer anger du hur många gånger algoritmen ska iterera över träningsdata innan du slutför valet av centroider.
Du kan justera den här parametern för att balansera noggrannhet jämfört med träningstid.
I Tilldela etikettläge väljer du ett alternativ som anger hur en etikettkolumn, om den finns i datauppsättningen, ska hanteras.
Eftersom K-means-klustring är en oövervakad maskininlärningsmetod är etiketter valfria. Men om datauppsättningen redan har en etikettkolumn kan du använda dessa värden för att styra valet av kluster, eller så kan du ange att värdena ska ignoreras.
Ignorera etikettkolumn: Värdena i etikettkolumnen ignoreras och används inte för att skapa modellen.
Fyll i saknade värden: Kolumnvärden för etiketter används som funktioner för att skapa kluster. Om några rader saknar en etikett imputeras värdet med hjälp av andra funktioner.
Skriv över från närmast mitten: Kolumnvärdena för etikett ersätts med förutsagda etikettvärden med hjälp av etiketten för den punkt som är närmast den aktuella centroiden.
Träna modellen.
Om du anger Skapa träningsläge till Enskild parameter lägger du till en taggad datauppsättning och tränar modellen med hjälp av modulen Träna klustringsmodell .
Om du ställer in Skapa träningsläge på Parameterintervall lägger du till en taggad datauppsättning och tränar modellen med hjälp av Svepa kluster. Du kan använda modellen som tränats med hjälp av dessa parametrar, eller så kan du anteckna de parameterinställningar som ska användas när du konfigurerar en elev.
Resultat
När du har konfigurerat och tränat modellen har du en modell som du kan använda för att generera poäng. Det finns dock flera sätt att träna modellen och flera sätt att visa och använda resultaten:
Avbilda en ögonblicksbild av modellen på din arbetsyta
Om du använde modulen Train Clustering Model (Träna klustermodell)
- Högerklicka på modulen Träna klustringsmodell .
- Välj Tränad modell och klicka sedan på Spara som tränad modell.
Om du använde modulen Sweep Clustering för att träna modellen
- Högerklicka på modulen Svep klustring .
- Välj Bästa tränade modell och klicka sedan på Spara som tränad modell.
Den sparade modellen representerar träningsdata när du sparade modellen. Om du senare uppdaterar träningsdata som används i experimentet uppdateras inte den sparade modellen.
Se en visuell representation av klustren i modellen
Om du använde modulen Train Clustering Model (Träna klustringsmodell)
- Högerklicka på modulen och välj Resultatdatauppsättning.
- Välj Visualisera.
Om du använde modulen Sweep Clustering
Lägg till en instans av modulen Assign Data to Clusters (Tilldela data till kluster) och generera poäng med hjälp av modellen Best Trained (Bäst tränad).
Högerklicka på modulen Tilldela data till kluster , välj Resultatdatauppsättning och välj Visualisera.
Diagrammet genereras med hjälp av Principal Component Analysis, som är en teknik inom datavetenskap för att komprimera funktionsutrymmet för en modell. Diagrammet visar en uppsättning funktioner, komprimerade i två dimensioner, som bäst karaktäriserar skillnaden mellan klustren. Genom att visuellt granska den allmänna storleken på funktionsutrymmet för varje kluster och hur mycket klustren överlappar kan du få en uppfattning om hur bra din modell kan prestera.
Följande PCA-diagram representerar till exempel resultaten från två modeller som tränats med samma data: den första konfigurerades för att mata ut två kluster och den andra konfigurerades för att mata ut tre kluster. I de här diagrammen kan du se att en ökning av antalet kluster inte nödvändigtvis förbättrade uppdelningen av klasserna.
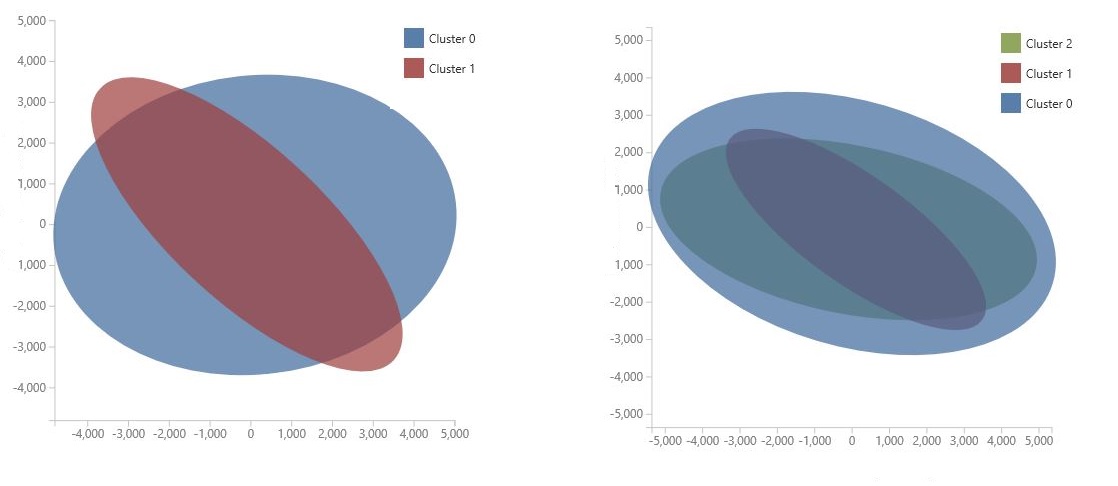
Tips
Använd modulen Sweep Clustering för att välja den optimala uppsättningen hyperparametrar, inklusive slumpmässigt startvärde och antal startcentroider.
Se listan över datapunkter och de kluster som de tillhör
Det finns två alternativ för att visa datauppsättningen med resultat, beroende på hur du har tränat modellen:
Om du använde modulen Sweep Clustering för att träna modellen
- Använd kryssrutan i modulen Sweep Clustering för att ange om du vill se indata tillsammans med resultaten eller bara se resultatet.
- När träningen är klar högerklickar du på modulen och väljer Resultatdatauppsättning (utdatanummer 2)
- Klicka på Visualisera.
Om du använde modulen Train Clustering Model (Träna klustringsmodell)
- Lägg till modulen Tilldela data till kluster och anslut den tränade modellen till indata till vänster. Anslut en datauppsättning till högerindata.
- Lägg till modulen Konvertera till datauppsättning i experimentet och anslut den till utdata från Tilldela data till kluster.
- Använd kryssrutan i modulen Assign Data to Clusters (Tilldela data till kluster ) för att ange om du vill se indata tillsammans med resultaten eller bara se resultatet.
- Kör experimentet eller kör bara modulen Konvertera till datamängd .
- Högerklicka på Konvertera till datauppsättning, välj Resultatdatauppsättning och klicka på Visualisera.
Utdata innehåller kolumnerna för indata först, om du inkluderade dem, och följande kolumner för varje rad med indata:
Tilldelning: Tilldelningen är ett värde mellan 1 och n, där n är det totala antalet kluster i modellen. Varje rad med data kan bara tilldelas till ett kluster.
DistancesToClusterCenter no.n: Det här värdet mäter avståndet från den aktuella datapunkten till centroiden för klustret. En separat kolumn i utdata för varje kluster i den tränade modellen.
Värdena för klusteravstånd baseras på det avståndsmått som du valde i alternativet Mått för att mäta klusterresultat. Även om du utför en parameterrensning på klustringsmodellen kan endast ett mått tillämpas under svepet. Om du ändrar måttet kan du få olika avståndsvärden.
Visualisera avstånd mellan kluster
I datauppsättningen med resultat från föregående avsnitt klickar du på kolumnen med avstånd för varje kluster. Studio (klassisk) visar ett histogram som visualiserar fördelningen av avstånd för punkter i klustret.
Följande histogram visar till exempel fördelningen av klusteravstånd från samma experiment med hjälp av fyra olika mått. Alla andra inställningar för parameterrensningen var desamma. Att ändra måttet resulterade i ett annat antal kluster i en modell.
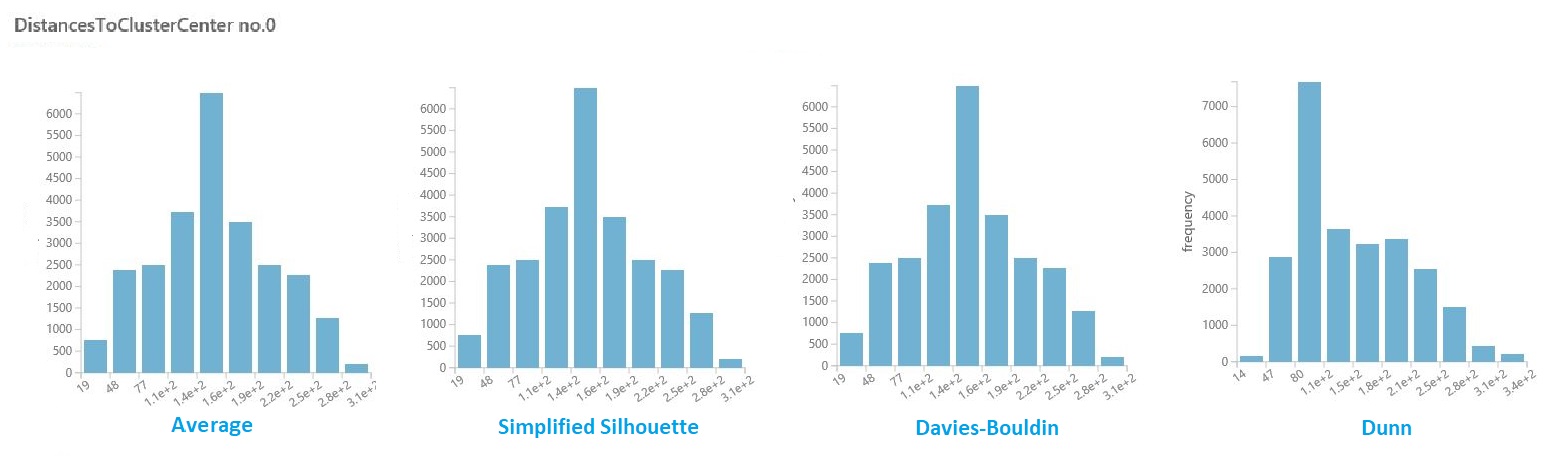
I allmänhet bör du välja ett mått som maximerar avståndet mellan datapunkter i olika klasser och minimerar avstånden inom en klass. Du kan använda förberäknade medelvärden och andra värden i fönstret Statistik för att vägleda dig i det här beslutet.
Tips
Du kan extrahera medelvärden och andra värden som används i visualiseringar med hjälp av PowerShell-modulen för Machine Learning.
Eller använd modulen Execute R Script (Kör R-skript) för att beräkna en anpassad avståndsmatris.
Tips för att generera den bästa klustringsmodellen
Det är känt att seeding-processen som används under klustring kan påverka modellen avsevärt. Seeding innebär den första placeringen av punkter i potenta centroider.
Om datamängden till exempel innehåller många extremvärden och en extremavvikelse väljs för att seeda klustren, skulle inga andra datapunkter passa bra med klustret och klustret kan vara en singleton: det vill säga ett kluster med bara en punkt.
Det finns olika sätt att undvika det här problemet:
Använd en parameterrensning för att ändra antalet centroider och prova flera startvärden.
Skapa flera modeller, varierande mått eller iterera mer.
Använd en metod som PCA för att hitta variabler som har en skadlig effekt på klustring. Se exemplet Hitta liknande företag för en demonstration av den här tekniken.
I allmänhet, med klustringsmodeller, är det möjligt att en viss konfiguration resulterar i en lokalt optimerad uppsättning kluster. Med andra ord passar den uppsättning kluster som returneras av modellen endast de aktuella datapunkterna och är inte generaliserbar för andra data. Om du använde en annan inledande konfiguration kan K-means-metoden hitta en annan, kanske överlägsen, konfiguration.
Viktigt
Vi rekommenderar att du alltid experimenterar med parametrarna, skapar flera modeller och jämför de resulterande modellerna.
Exempel
Exempel på hur K-means-klustring används i Machine Learning finns i de här experimenten i Azure AI-galleriet:
Gruppera irisdata: Jämför resultatet av K-Means-klustring och Logistisk regression i multiklass för en klassificeringsuppgift.
Exempel på färgkvantisering: Skapar flera K-means-modeller med olika parametrar för att hitta den optimala bildkomprimering.
Klustring: Liknande företag: Varierar antalet centroider för att hitta grupper av liknande företag i S-&P500.
Tekniska anteckningar
Med tanke på ett specifikt antal kluster (K) att hitta för en uppsättning D-dimensionella datapunkter med N-datapunkter , skapar K-means-algoritmen klustren på följande sätt:
Modulen initierar en K-by-D-matris med de slutliga centroider som definierar K-klustren som hittas.
Som standard tilldelar modulen de första K-datapunkterna till K-klustren.
Från och med en första uppsättning K-centroider använder metoden Lloyds algoritm för att iterativt förfina centroidernas platser.
Algoritmen avslutas när centroiderna stabiliseras eller när ett angivet antal iterationer har slutförts.
Ett likhetsmått (som standard euklidiska avstånd) används för att tilldela varje datapunkt till det kluster som har närmaste centroid.
Varning
- Om du skickar ett parameterintervall till Train Clustering Model används endast det första värdet i listan över parameterintervall.
- Om du skickar en enda uppsättning parametervärden till modulen Sweep Clustering ignorerar den värdena och använder standardvärdena för eleven när den förväntar sig ett intervall med inställningar för varje parameter.
- Om du väljer alternativet Parameterintervall och anger ett enda värde för valfri parameter används det enskilda värdet som du angav under svepet, även om andra parametrar ändras över ett värdeintervall.
Modulparametrar
| Name | Intervall | Typ | Standardvärde | Description |
|---|---|---|---|---|
| Antal centroider | >=2 | Integer | 2 | Antal centroider |
| Metric | Lista (delmängd) | Metric | Euklidisk | Valt mått |
| Initiering | Lista | Centroid-initieringsmetod | K-Means++ | Initieringsalgoritm |
| Iterationer | >=1 | Integer | 100 | Antal iterationer |
Utdata
| Namn | Typ | Description |
|---|---|---|
| Otränad modell | ICluster-gränssnitt | Otränad K-Means-klustringsmodell |
Undantag
En lista över alla undantag finns i Felkoder för Machine Learning-modul.
| Undantag | Description |
|---|---|
| Fel 0003 | Ett undantag inträffar om en eller flera indata är null eller tomma. |
Se även
Klustring
Tilldela data till kluster
Träna klustringsmodellen
Rensa klustring