Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
gäller för:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
Den här artikeln beskriver hur du använder en formatfil för att hoppa över att importera en tabellkolumn när data för den överhoppade kolumnen inte finns i källdatafilen. En datafil kan innehålla färre fält än antalet kolumner i måltabellen, dvs. du kan hoppa över att importera en kolumn, bara om minst ett av följande två villkor är sant i måltabellen:
- Den överhoppade kolumnen är null.
- Den överhoppade kolumnen har ett standardvärde.
Obs
Den här syntaxen, inklusive massinfogning, stöds inte i Azure Synapse Analytics. I Azure Synapse Analytics och andra molndatabasplattformsintegreringar utför du dataflytt via COPY-instruktionen i Azure Data Factoryeller med hjälp av T-SQL-instruktioner som COPY INTO och PolyBase.
Exempeltabell och datafil
Exemplen i den här artikeln förväntar sig en tabell med namnet myTestSkipCol under dbo-schemat. Du kan skapa den här tabellen i en exempeldatabas, till exempel WideWorldImporters eller AdventureWorks eller i någon annan databas. Skapa den här tabellen på följande sätt:
USE WideWorldImporters;
GO
CREATE TABLE myTestSkipCol
(
Col1 SMALLINT,
Col2 NVARCHAR (50) NULL,
Col3 NVARCHAR (50) NOT NULL
);
GO
Exemplen i den här artikeln använder också en exempeldatafil myTestSkipCol2.dat. Den här datafilen innehåller bara två fält, även om måltabellen innehåller tre kolumner.
1,DataForColumn3
1,DataForColumn3
1,DataForColumn3
Grundläggande steg
Du kan använda en icke-XML-formatfil eller en XML-formatfil för att hoppa över en tabellkolumn. I båda fallen finns det två steg:
- Använd kommandoradsverktyget bcp för att skapa en standardformatfil.
- Ändra standardformatfilen i en textredigerare.
Den ändrade formatfilen måste mappa varje befintligt fält till motsvarande kolumn i måltabellen. Den måste också ange vilken tabellkolumn eller vilka kolumner som ska hoppa över.
Om du till exempel vill massimportera data från myTestSkipCol2.dat till tabellen myTestSkipCol måste formatfilen mappa det första datafältet till Col1, hoppa över Col2och mappa det andra fältet till Col3.
Alternativ 1 – Använd en fil som inte är XML-format
Steg 1 – Skapa en standardfil som inte är XML-format
Skapa en standardfil som inte är XML-format för myTestSkipCol-exempeltabellen genom att köra följande bcp-kommando i kommandotolken:
bcp WideWorldImporters..myTestSkipCol format nul -f myTestSkipCol_Default.fmt -c -T
Viktig
Du kan behöva ange namnet på den serverinstans som du ansluter till med -S argumentet. Du kan också behöva ange användarnamnet och lösenordet med argumenten -U och -P. Mer information finns i bcp Utility.
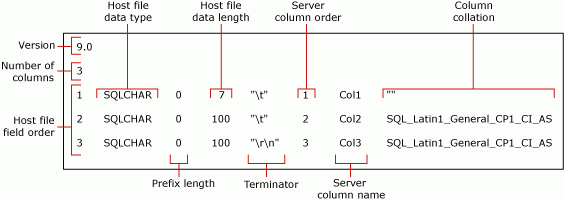
Föregående kommando skapar en fil som inte är XML-format, myTestSkipCol_Default.fmt. Den här formatfilen kallas för en standardformatfil eftersom det är formuläret som genereras av bcp. En standardformatfil beskriver en en-till-en-korrespondens mellan datafilfält och tabellkolumner.
Följande skärmbild visar värdena i den här standardformatfilen för exemplet.
Obs
Mer information om format-filfälten finns i filer som inte är XML-format (SQL Server).
Steg 2 – Ändra en fil som inte är XML-format
Om du vill ändra en standardfil som inte är XML-format finns det två alternativ. Båda alternativen anger att datafältet inte finns i datafilen och att inga data ska infogas i motsvarande tabellkolumn.
Om du vill hoppa över en tabellkolumn redigerar du standardfilen för icke-XML-format och ändrar filen med någon av följande alternativa metoder:
Alternativ 1 – Ta bort raden
Den rekommenderade metoden för att hoppa över en kolumn omfattar följande tre steg:
- Ta först bort valfri formatfilrad som beskriver ett fält som saknas i källdatafilen.
- Minska sedan värdet "Fältordning för värdfil" för varje format-filrad som följer en borttagen rad. Målet är sekventiella värden för "Fältordning för värdfil", 1 till och med n, som återspeglar den faktiska positionen för varje datafält i datafilen.
- Slutligen minskar du värdet i fältet Antal kolumner för att återspegla det faktiska antalet fält i datafilen.
Följande exempel baseras på standardformatfilen för tabellen myTestSkipCol. Den ändrade formatfilen mappar det första datafältet till Col1, hoppar över Col2och mappar det andra datafältet till Col3. Raden för Col2 har tagits bort. Avgränsare efter det första fältet har också ändrats från \t till ,.
14.0
2
1 SQLCHAR 0 7 "," 1 Col1 ""
2 SQLCHAR 0 100 "\r\n" 3 Col3 SQL_Latin1_General_CP1_CI_AS
Alternativ 2 – Ändra raddefinitionen
Om du vill hoppa över en tabellkolumn kan du också ändra definitionen av den formatfilrad som motsvarar tabellkolumnen. I den här formatfilraden måste värdena "prefixlängd", "datalängd för värdfil" och "serverkolumnordning" anges till 0. Fälten "terminator" och "kolumnsortering" måste också anges till "" (det vill säga till ett tomt eller NULL värde). Värdet "serverkolumnnamn" kräver en icke-tom sträng, men det faktiska kolumnnamnet är inte nödvändigt. De återstående formatfälten kräver sina standardvärden.
Följande exempel härleds också från standardformatfilen för myTestSkipCol-tabellen.
14.0
3
1 SQLCHAR 0 7 "," 1 Col1 ""
2 SQLCHAR 0 0 "" 0 Col2 ""
3 SQLCHAR 0 100 "\r\n" 3 Col3 SQL_Latin1_General_CP1_CI_AS
Exempel med en fil som inte är XML-format
Följande exempel baseras på exempeltabellen myTestSkipCol och myTestSkipCol2.dat exempeldatafil som beskrivs tidigare i den här artikeln.
Använd MASSINFOGNING
Det här exemplet fungerar med någon av de ändrade icke-XML-formatfiler som skapats enligt beskrivningen i föregående avsnitt. I det här exemplet heter den ändrade formatfilen myTestSkipCol2.fmt. Om du vill använda BULK INSERT för att massimportera myTestSkipCol2.dat datafilen kör du följande kod i SQL Server Management Studio (SSMS). Uppdatera filsystemens sökvägar för placeringen av exempelfilerna på din dator.
USE WideWorldImporters;
GO
BULK INSERT myTestSkipCol FROM 'C:\myTestSkipCol2.dat'
WITH (FORMATFILE = 'C:\myTestSkipCol2.fmt');
GO
SELECT *
FROM myTestSkipCol;
GO
Alternativ 2 – Använd en XML-formatfil
Steg 1 – Skapa en xml-standardformatfil
Skapa en XML-standardformatfil för myTestSkipCol-exempeltabellen genom att köra följande bcp- kommando i kommandotolken:
bcp WideWorldImporters..myTestSkipCol format nul -f myTestSkipCol_Default.xml -c -x -T
Viktig
Du kan behöva ange namnet på den serverinstans som du ansluter till med -S argumentet. Du kan också behöva ange användarnamnet och lösenordet med argumenten -U och -P. Mer information finns i bcp Utility.
Föregående kommando skapar en XML-formatfil myTestSkipCol_Default.xml. Den här formatfilen kallas för en standardformatfil eftersom det är formuläret som genereras av bcp. En standardformatfil beskriver en en-till-en-korrespondens mellan datafilfält och tabellkolumner.
<?xml version="1.0"?>
<BCPFORMAT xmlns="http://schemas.microsoft.com/sqlserver/2004/bulkload/format" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<RECORD>
<FIELD ID="1" xsi:type="CharTerm" TERMINATOR="\t" MAX_LENGTH="7" />
<FIELD ID="2" xsi:type="CharTerm" TERMINATOR="\t" MAX_LENGTH="100" COLLATION="SQL_Latin1_General_CP1_CI_AS" />
<FIELD ID="3" xsi:type="CharTerm" TERMINATOR="\r\n" MAX_LENGTH="100" COLLATION="SQL_Latin1_General_CP1_CI_AS" />
</RECORD>
<ROW>
<COLUMN SOURCE="1" NAME="Col1" xsi:type="SQLSMALLINT" />
<COLUMN SOURCE="2" NAME="Col2" xsi:type="SQLNVARCHAR" />
<COLUMN SOURCE="3" NAME="Col3" xsi:type="SQLNVARCHAR" />
</ROW>
</BCPFORMAT>
Obs
Information om strukturen för XML-formatfiler finns i XML-formatfiler (SQL Server).
Steg 2 – Ändra en XML-formatfil
Här är den ändrade XML-formatfilen, myTestSkipCol2.xml, som hoppar över Col2. Posterna FIELD och ROW för Col2 har tagits bort och posterna har numrerats om. Avgränsare efter det första fältet har också ändrats från \t till ,.
<?xml version="1.0"?>
<BCPFORMAT xmlns="http://schemas.microsoft.com/sqlserver/2004/bulkload/format" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<RECORD>
<FIELD ID="1" xsi:type="CharTerm" TERMINATOR="," MAX_LENGTH="7" />
<FIELD ID="2" xsi:type="CharTerm" TERMINATOR="\r\n" MAX_LENGTH="100" COLLATION="SQL_Latin1_General_CP1_CI_AS" />
</RECORD>
<ROW>
<COLUMN SOURCE="1" NAME="Col1" xsi:type="SQLSMALLINT" />
<COLUMN SOURCE="2" NAME="Col3" xsi:type="SQLNVARCHAR" />
</ROW>
</BCPFORMAT>
Exempel med en XML-formatfil
Följande exempel baseras på exempeltabellen myTestSkipCol och myTestSkipCol2.dat exempeldatafil som beskrivs tidigare i den här artikeln.
Om du vill importera data från myTestSkipCol2.dat till tabellen myTestSkipCol använder exemplen den ändrade XML-formatfilen myTestSkipCol2.xml.
Använd BULK INSERT med en vy
Med en XML-formatfil kan du inte hoppa över en kolumn när du importerar direkt till en tabell med hjälp av ett bcp-kommando eller en BULK INSERT instruktion. Du kan dock importera till alla utom den sista kolumnen i en tabell. Om du måste hoppa över någon annan kolumn än den sista kolumnen måste du skapa en vy över måltabellen som endast innehåller kolumnerna i datafilen. Sedan kan du massimportera data från filen till vyn.
I följande exempel skapas vyn v_myTestSkipCol i tabellen myTestSkipCol. Den här vyn hoppar över den andra tabellkolumnen, Col2. Exemplet använder sedan BULK INSERT för att importera myTestSkipCol2.dat-datafilen till den här vyn.
Kör följande kod i SSMS. Uppdatera filsystemens sökvägar för placeringen av exempelfilerna på din dator.
USE WideWorldImporters;
GO
CREATE VIEW v_myTestSkipCol AS
SELECT Col1,
Col3
FROM myTestSkipCol;
GO
BULK INSERT v_myTestSkipCol FROM 'C:\myTestSkipCol2.dat'
WITH (FORMATFILE = 'C:\myTestSkipCol2.xml');
GO
Använd OPENROWSET(BULK...)
Om du vill använda en XML-formatfil för att hoppa över en tabellkolumn med hjälp av OPENROWSET(BULK...)måste du ange en explicit lista med kolumner i urvalslistan och även i måltabellen enligt följande:
INSERT ...<column_list> SELECT <column_list> FROM OPENROWSET(BULK...)
I följande exempel används OPENROWSET massraderuppsättningsleverantör och formatfilen myTestSkipCol2.xml. I exemplet importeras myTestSkipCol2.dat-datafilen till tabellen myTestSkipCol. Påståendet innehåller en explicit lista över kolumner i urvalslistan och även i måltabellen, enligt krav.
Kör följande kod i SSMS. Uppdatera filsystemens sökvägar för placeringen av exempelfilerna på din dator.
USE WideWorldImporters;
GO
INSERT INTO myTestSkipCol (Col1, Col3)
SELECT Col1,
Col3
FROM OPENROWSET (
BULK 'C:\myTestSkipCol2.Dat',
FORMATFILE = 'C:\myTestSkipCol2.Xml'
) AS t1;
GO