Skapa ett HDInsight-kluster
Det finns olika metoder för att skapa ett HDInsight-kluster, det kan vara allt från att använda Azure Portal för ett enkelt användargränssnitt, till skriptkonfigurationer som kan hjälpa till med automatiserade distributioner. I följande tabell visas de olika metoder som du kan använda för att konfigurera ett HDInsight-kluster.
| Kluster som skapats med | Webbläsare | Kommandorad | REST API | SDK |
|---|---|---|---|---|
| Azure Portal | ✔ | |||
| Azure Data Factory | ✔ | ✔ | ✔ | ✔ |
| Azure CLI | ✔ | |||
| Azure PowerShell | ✔ | |||
| cURL | ✔ | ✔ | ||
| .NET SDK | ✔ | |||
| Azure Resource Manager-mall | ✔ |
Alla HDInsight-installationer kräver följande grundläggande information, inklusive:
Fliken Grundläggande
Projektinformation
Abonnemang
Definierar den Azure-prenumeration under vilken HDInsight ska faktureras och hanteras.
Namn på resursgrupp
En resursgrupp är en logisk gruppering av Azure-tekniker och -tjänster som vanligtvis är relaterade till samma program eller programlivscykel. Att gruppera tjänster i samma resursgrupp underlättar det administrativa underhållet.
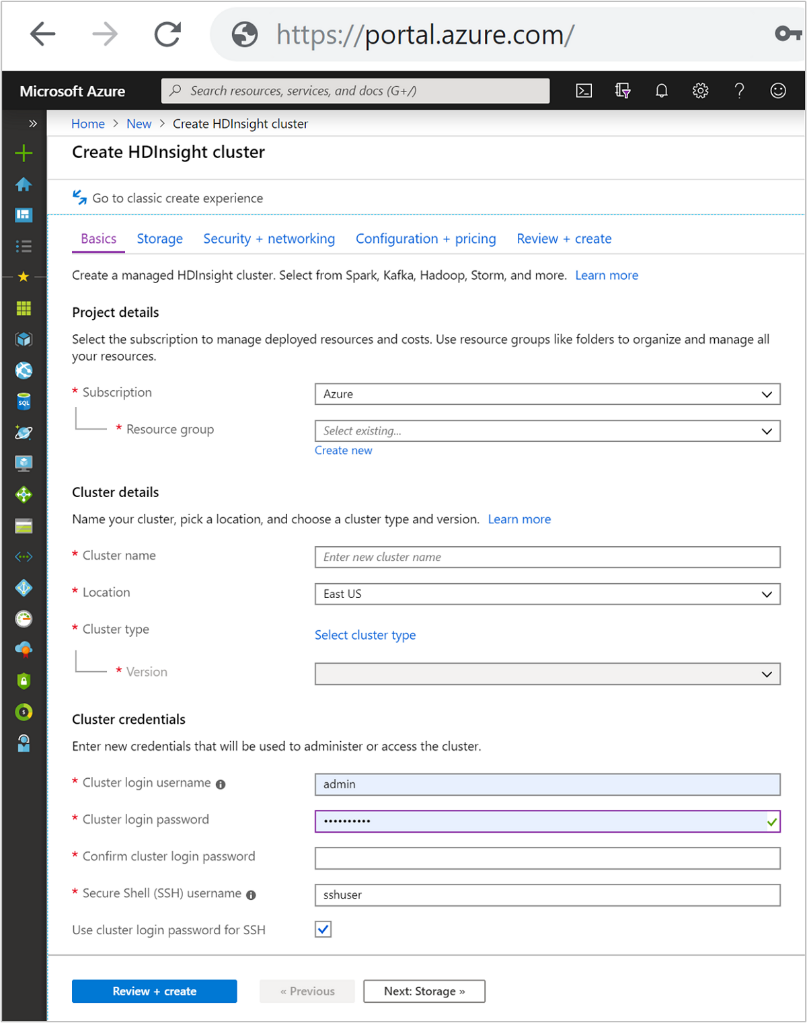
Klusterinformation
Klusternamn
HDInsight-klusternamn har följande begränsningar:
- Tillåtna tecken: a-z, 0-9, A-Z
- Max längd: 59
- Reserverade namn: appar
- Omfånget för klusternamngivning gäller för alla Azure-prenumerationer. Klusternamnet måste därför vara unikt över hela världen.
- De första sex tecknen måste vara unika i ett virtuellt nätverk
Plats
Anger platsen där klustertypen lagras. Om ingen plats har definierats är klustret indelade på samma plats som standardlagringen. Platsen ska vara så nära dina användare som möjligt för att minska svarstiden.
Klustertyper
Definierar den teknikstack som etablerats i klustret med resurser. Välj en klustertyp baserat på vilken typ av data du har och vilken typ av bearbetning ditt scenario kräver. Tillgängliga klustertyper som visas i följande tabell.
| Klustertyp | Beskrivning |
|---|---|
| Apache Hadoop | Ett ramverk som använder HDFS och en enkel MapReduce-programmeringsmodell för att bearbeta och analysera batchdata. |
| Apache Spark | Ett ramverk för parallellbearbetning med öppen källkod som stöder intern bearbetning för att höja prestandan hos program för stordataanalys. |
| HBase | En NoSQL-databas som bygger på Hadoop och ger slumpmässig åtkomst och stark konsekvens för stora mängder ostrukturerade och delstrukturerade data – potentiellt miljarder rader gånger miljoner kolumner. |
| Apache Interaktiv fråga | Minnesintern cachelagring för interaktiva och snabba Hive-frågor. |
| Apache Kafka | En öppen källkodsplattform som används för att skapa strömmande datapipelines och program. Kafka tillhandahåller även en meddelandeköfunktion med vilken du kan publicera och prenumerera på dataströmmar. |
Version:
Definierar versionen av HDInsight för det här klustret. HDInsight 4.0 är den senaste versionen och har de senaste ramverken etablerade till kluster.
Klusterautentiseringsuppgifter
Med HDInsight-kluster kan du konfigurera två användarkonton när klustret skapas.
Klusterinloggning och lösenord
Standardanvändarnamnet är admin. Den använder den grundläggande konfigurationen på Azure Portal. Ibland kallas det "Klusteranvändare".
SSH-användarnamn och lösenord
Används för att ansluta till klustret via SSH.
Anteckning
Med Enterprise-säkerhetspaketet kan du integrera HDInsight med Active Directory och Apache Ranger. Flera användare kan skapas med hjälp av Enterprise-säkerhetspaketet.
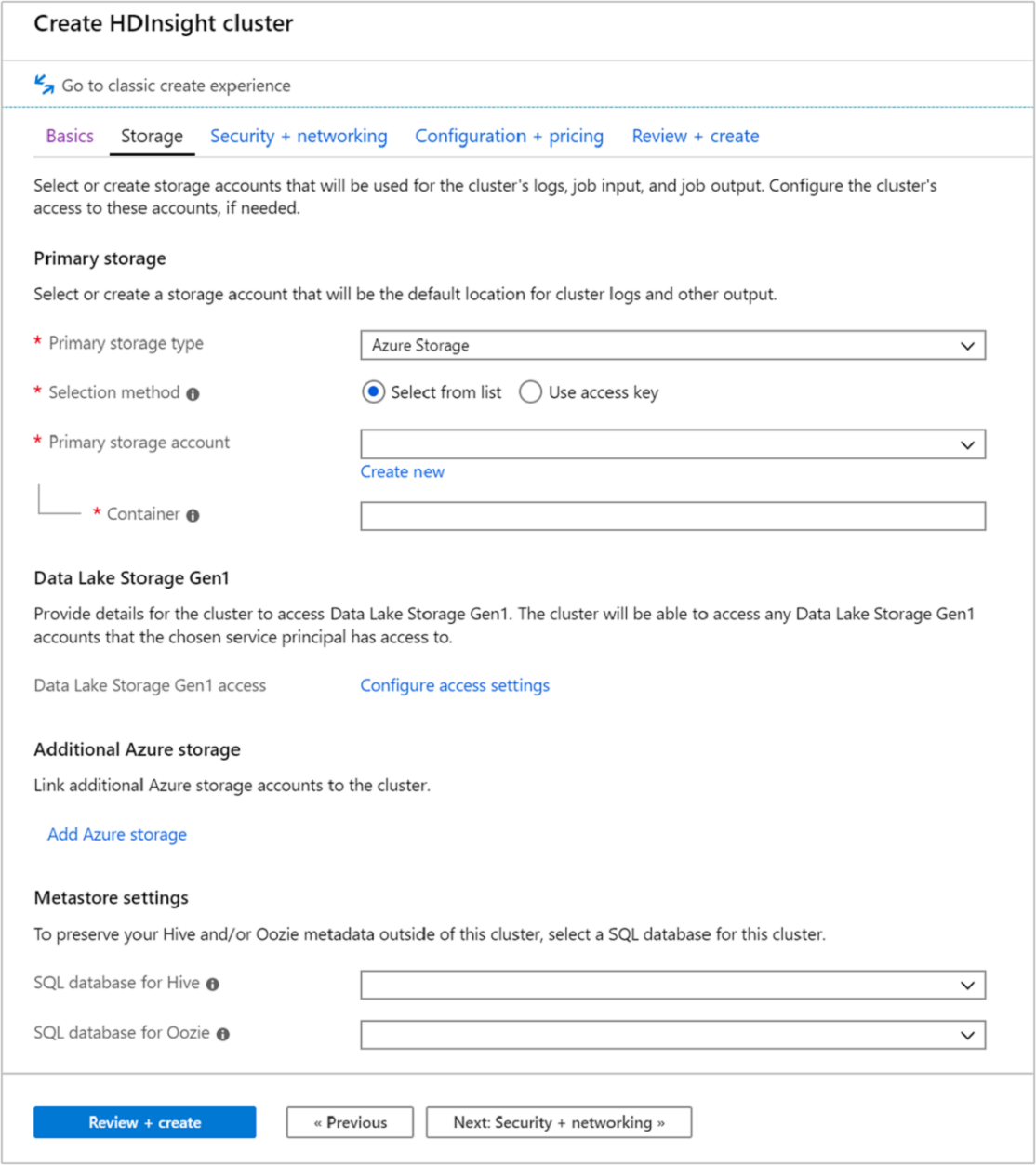
Fliken Lagring
HDInsight-kluster kan använda följande lagringsalternativ som visas på lagringsskärmen:
- Azure Data Lake Storage Gen2
- Azure Data Lake Storage Gen1
- Azure Storage Generell användning v2
- Azure Storage Generell användning v1
- Blockblob för Azure Storage (stöds endast som sekundär lagring)
På lagringsskärmen kan du definiera det primära lagringskontot och standardcontainern. Du kan också länka ytterligare Azure Storage till klustret. Med metaarkivinställningarna kan du definiera en extern SQL-databas för att lagra Hive-tabeller när ett kluster har tagits bort och för att förbättra Oozies prestanda genom att lagra metadata i ett externt arkiv.
Säkerhet och nätverk
För klustertyperna Hadoop, Spark, HBase, Kafka och Interaktiv fråga kan du välja att aktivera Enterprise Security Package. Det här paketet ger möjlighet att ha en säkrare klusterkonfiguration med hjälp av Apache Ranger och integrering med Microsoft Entra-ID.
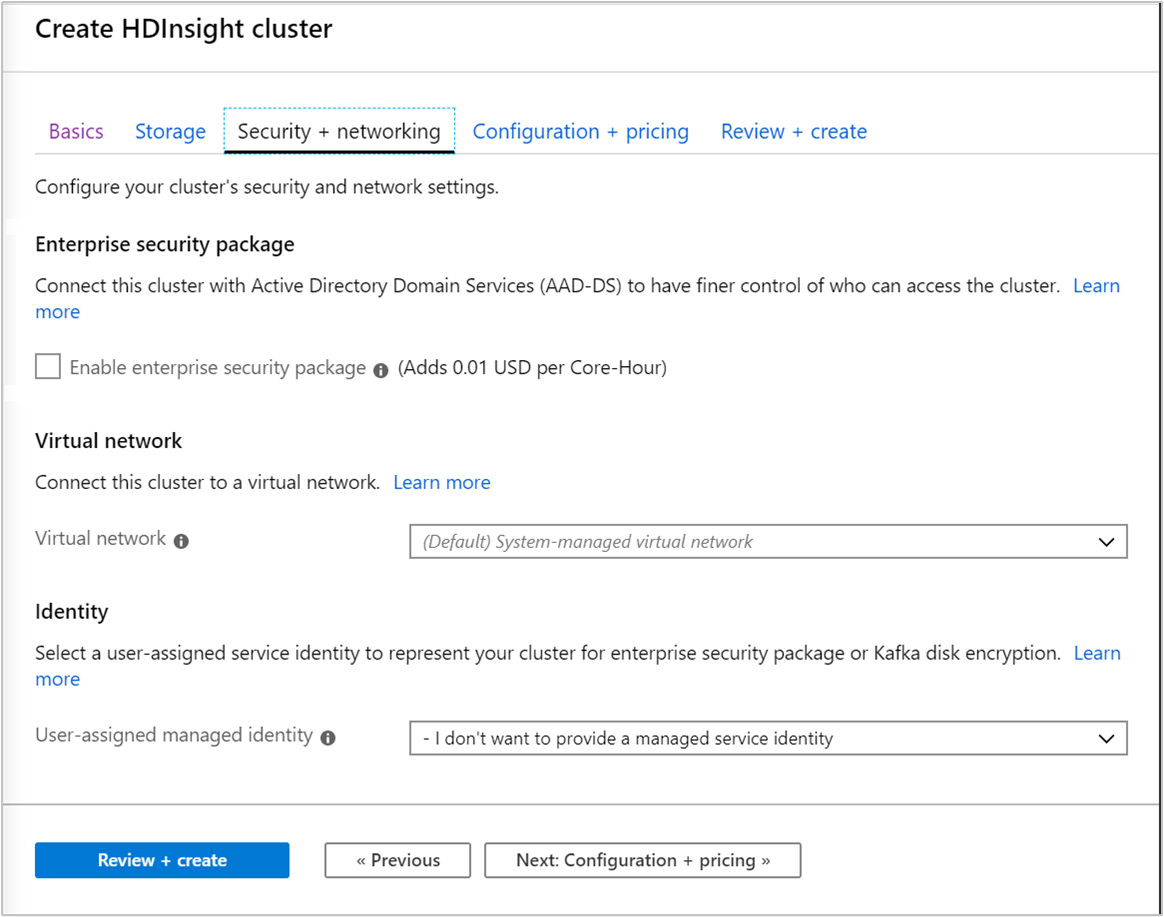
Dessutom rekommenderar vi alltid att du distribuerar HDInsight-kluster i ett virtuellt nätverk och du kan definiera och ange det virtuella nätverket på den här skärmen. Om din lösning kräver tekniker som är spridda över flera HDInsight-klustertyper kan ett virtuellt Azure-nätverk ansluta de klustertyper som krävs. Med den här konfigurationen kan klustren och all kod som du distribuerar till dem kommunicera direkt med varandra.
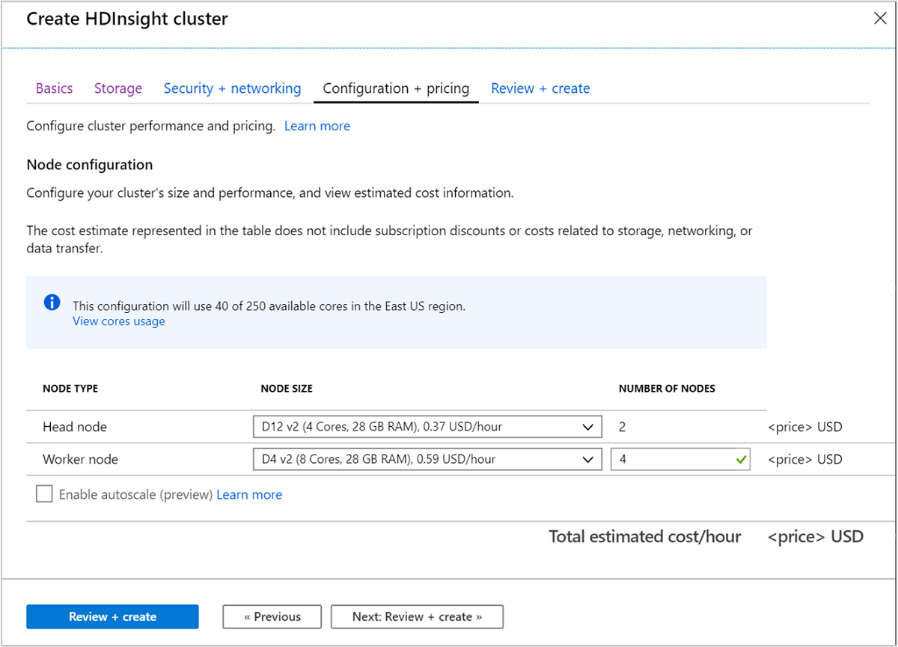
Konfiguration och prissättning
På den här sidan kan du konfigurera klustrets storlek och prestanda och visa uppskattad kostnadsinformation. På den här skärmen kan du definiera de virtuella datorer som ska användas för huvudnoderna (huvudnoderna) och även för arbetsnoderna.