Övning – Arbeta med datafiler i Azure Blob Storage direkt från Azure Cosmos DB for PostgreSQL
I den här övningen pg_azure_storage använder du tillägget för att mata in data från filer som lagras på ett säkert sätt i en privat container i Azure Blob Storage.
Viktigt!
Den här övningen förlitar sig på Azure Cosmos DB for PostgreSQL-databasen och distribuerade tabeller som du skapade i enhet 3.
Skapa ett Azure Blob Storage-konto
För att slutföra den här övningen måste du skapa ett Azure Storage-konto, hämta dess åtkomstnyckel, skapa en container och kopiera Woodgrove Banks historiska datafiler till containern. I den här uppgiften skapar du lagringskontot.
Öppna en webbläsare och gå till Azure-portalen.
Välj Skapa en resurs, ett lagrings- och lagringskonto. Du kan också använda sökfunktionen för att hitta resursen.
På fliken Grundläggande anger du följande information:
Parameter Värde Projektinformation Prenumeration Välj din Azure-prenumeration. Resursgrupp Välj den learn-cosmosdb-postgresqlresursgrupp som du skapade i föregående övning.Instansinformation Lagringskontonamn Ange ett globalt unikt namn, till exempel stlearnpostgresql.Region Välj samma region som du valde för ditt Azure Cosmos DB för PostgreSQL-databaskluster. Prestanda Välj Standard. Redundans Välj Lokalt redundant lagring (LRS). 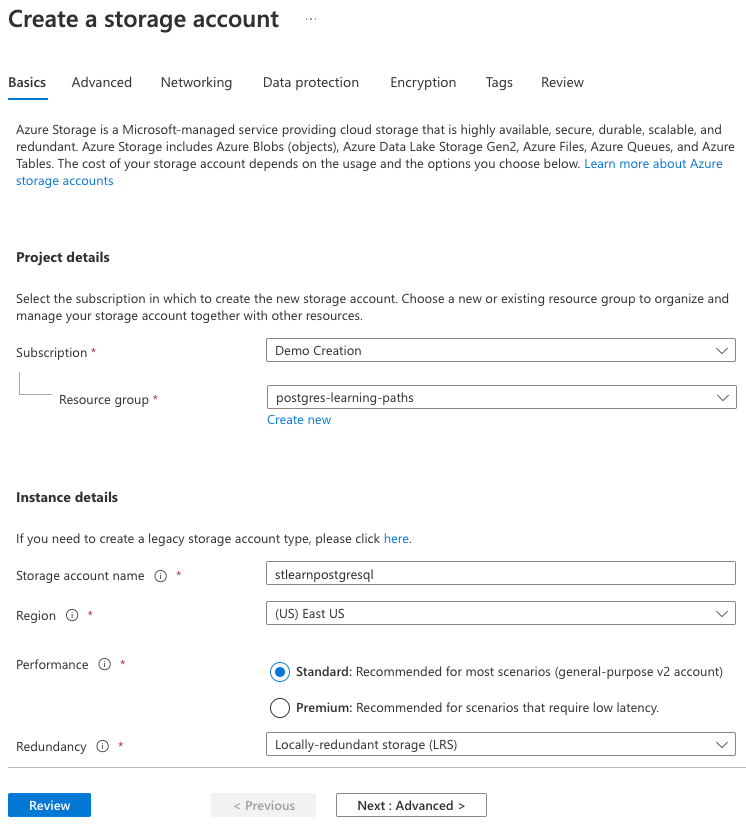
Du använder standardinställningarna för de återstående flikarna i lagringskontokonfigurationen, så välj knappen Granska .
Välj knappen Skapa på fliken Granska för att skapa lagringskontot.
Skapa en bloblagringscontainer och ladda upp datafiler
Woodgrove Bank har gett dig sina historiska datafiler i CSV-format. Skapa en container med namnet historical-data i det nya lagringskontot och ladda sedan upp filerna till den med hjälp av Azure CLI.
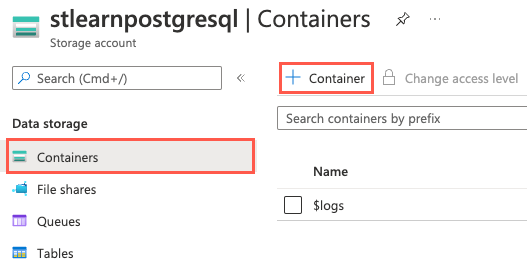
Gå till ditt nya lagringskonto i Azure-portalen.
I den vänstra navigeringsmenyn väljer du Containrar under Datalagring och sedan + Container i verktygsfältet.
I dialogrutan Ny container anger du
historical-datai fältet Namn, lämnar Privat (ingen anonym åtkomst) vald för inställningen Offentlig åtkomstnivå och väljer Skapa.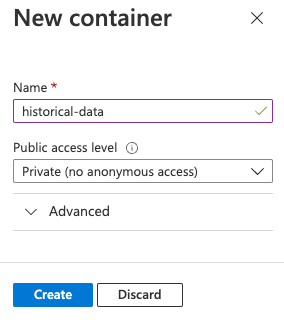
Genom att ställa in containerns åtkomstnivå på Privat (ingen anonym åtkomst) förhindrar du offentlig åtkomst till containern och dess innehåll. Nedan anger
pg_azure_storagedu tillägget med kontonamnet och åtkomstnyckeln så att det kan komma åt filerna på ett säkert sätt.Du behöver det namn och den nyckel som är associerad med ditt lagringskonto för att ladda upp datafilerna med hjälp av Azure CLI. I den vänstra navigeringsmenyn väljer du Åtkomstnycklar under Säkerhet + nätverk.
När sidan Åtkomstnycklar är öppen väljer du Cloud Shell-ikonen i azure-portalens verktygsfält för att öppna ett nytt Cloud Shell-fönster längst ned i webbläsarfönstret.
I Azure Cloud Shell-prompten kör du följande
curlkommandon för att ladda ned filerna som tillhandahålls av Woodgrove Bank.curl -O https://raw.githubusercontent.com/MicrosoftDocs/mslearn-create-connect-postgresHyperscale/main/users.csv curl -O https://raw.githubusercontent.com/MicrosoftDocs/mslearn-create-connect-postgresHyperscale/main/events.csvFilerna läggs till i Cloud Shell-lagringskontot.
Sedan använder du Azure CLI för att ladda upp filerna till containern
historical-datasom du skapade i ditt lagringskonto. Börja med att skapa variabler för lagringskontots namn och nyckelvärden för att göra det enklare.Kopiera lagringskontots namn genom att välja knappen Kopiera till Urklipp bredvid lagringskontots namn på sidan Åtkomstnycklar ovanför Cloud Shell:
Kör nu följande kommando för att skapa en variabel för lagringskontots namn och ersätt
{your_storage_account_name}token med namnet på ditt lagringskonto:ACCOUNT_NAME={your_storage_account_name}Välj sedan knappen Visa bredvid nyckeln för key1 och välj sedan knappen Kopiera till Urklipp bredvid nyckelns värde.
Kör sedan följande kommando och
{your_storage_account_key}ersätt token med nyckelvärdet som du kopierade:ACCOUNT_KEY={your_storage_account_key}Om du vill ladda upp filerna använder
az storage blob uploaddu kommandot från Azure CLI. Kör följande kommandon för att ladda upp filerna till lagringskontotshistorical-datacontainer:az storage blob upload --account-name $ACCOUNT_NAME --account-key $ACCOUNT_KEY --container-name historical-data --file users.csv --name users.csv --overwrite az storage blob upload --account-name $ACCOUNT_NAME --account-key $ACCOUNT_KEY --container-name historical-data --file events.csv --name events.csv --overwriteI den här övningen arbetar du med några filer. Du kommer förmodligen att arbeta med många fler filer i verkliga scenarier. Under dessa omständigheter kan du granska olika metoder för att migrera filer till ett Azure Storage-konto och välja den teknik som fungerar bäst för din situation.
Om du vill verifiera att filerna har laddats upp kan du navigera till sidan Containrar i ditt lagringskonto genom att välja Containrar på den vänstra navigeringsmenyn. Välj containern
historical-datai listan med containrar och observera att containern nu innehåller filer med namnetevents.csvochusers.csv.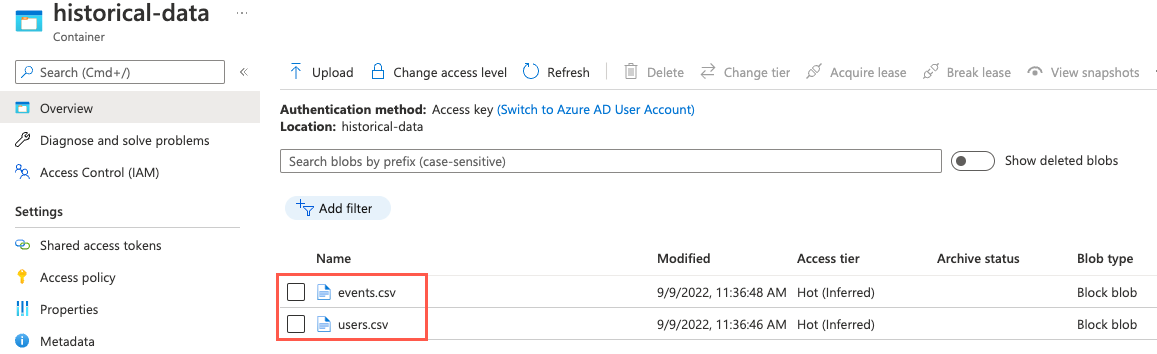
Anslut till databasen med psql i Azure Cloud Shell
När filerna nu är säkert lagrade i Blob Storage är det dags att konfigurera pg_azure_storage tillägget i databasen. Du använder psql kommandoradsverktyget från Azure Cloud Shell för att utföra den här uppgiften.
Med samma webbläsarflik där Cloud Shell är öppet går du till din Azure Cosmos DB for PostgreSQL-resurs i Azure-portalen.
I databasens vänstra navigeringsmeny väljer du Anslut ionssträngar under Inställningar och kopierar anslutningssträng märkt psql.
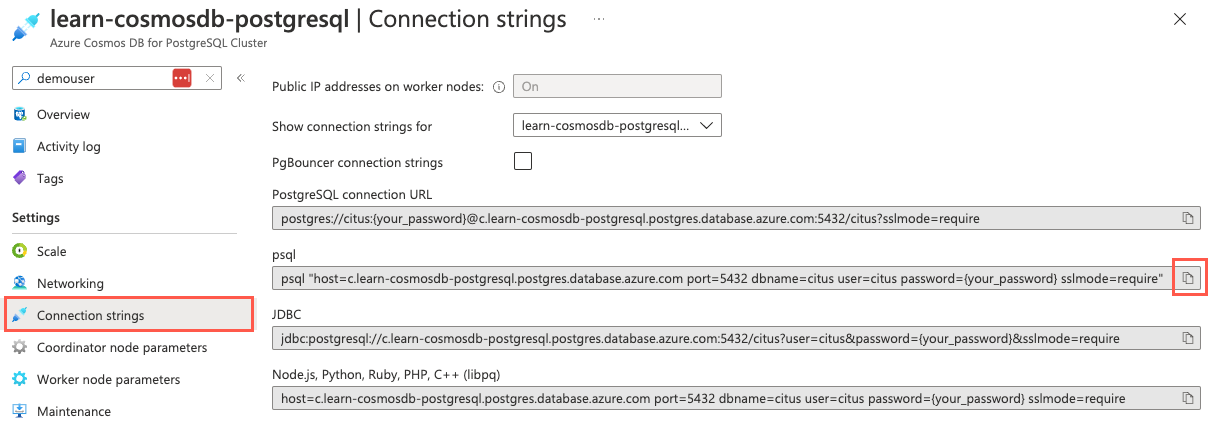
Klistra in anslutningssträng i en textredigerare som Anteckningar och ersätt
{your_password}token med det lösenord som du tilldeladecitusanvändaren när du skapade klustret. Kopiera den uppdaterade anslutningssträng för användning nedan.I det öppna Cloud Shell-fönstret kontrollerar du att Bash är valt för miljön och sedan använder kommandoradsverktyget psql för att ansluta till databasen. Klistra in den uppdaterade anslutningssträng (den som innehåller rätt lösenord) i kommandotolken i Cloud Shell och kör sedan kommandot, som bör se ut ungefär som följande kommando:
psql "host=c.learn-cosmosdb-postgresql.postgres.database.azure.com port=5432 dbname=citus user=citus password=P@ssword.123! sslmode=require"
Installera pg_azure_storage-tillägget
Nu när du är ansluten till databasen kan du installera pg_azure_storage tillägget.
Från Cloud Shell Citus-prompten kör du följande SQL-kommando för att läsa in tillägget i databasen:
SELECT create_extension('azure_storage');Tilläggets namn förkortas till
azure_storagenär du skapar och arbetar med tillägget i databasen.
Bevilja åtkomst till ett bloblagringskonto
Nästa steg är att bevilja åtkomst till ditt lagringskonto när tillägget har installerats pg_azure_storage . Kom ihåg att containern historical-data skapades med åtkomstnivån Privat (ingen anonym åtkomst) så du måste ange namnet och nyckeln som är associerad med ditt lagringskonto för att ge tillägget åtkomst till filer i containern.
Med samma webbläsarflik där Cloud Shell är öppet går du till lagringskontoresursen i Azure-portalen.
I den vänstra navigeringsmenyn väljer du Åtkomstnycklar under Säkerhet + nätverk.
Kör frågan nedan för att ge
pg_azure_storagetillägget åtkomst till ditt lagringskonto och ersätt{storage_account_name}token och{storage_account_key}med dina värden, som du kan kopiera från sidan Åtkomstnycklar för ditt lagringskonto.SELECT azure_storage.account_add('{storage_account_name}', '{storage_account_key}');Om du vill visa listan över konton som har lagts till i databasen kan du använda funktionen på
account_list()följande sätt:SELECT azure_storage.account_list();Den här frågan ger följande utdata:
account_list ------------------------ (stlearnpostgresql,{})Observera att du kan ta bort konton från databasen med hjälp av
account_remove('ACCOUNT_NAME')funktionen, men gör det inte här eftersom du behöver kontot anslutet under resten av övningen.
Visa en lista över filer i en bloblagringscontainer
Nu när du är säkert ansluten till lagringskontot kan du använda blob_list() funktionen för att skapa en lista över blobarna i en namngiven container.
Om du vill visa filerna i containern
historical-datakör du följande fråga:SELECT path, content_type, pg_size_pretty(bytes) FROM azure_storage.blob_list('stlearnpostgresql', 'historical-data');Funktionen
blob_list()matar ut alla blobar i den container som du angav:path | content_type | pg_size_pretty ------------+--------------+---------------- events.csv | text/csv | 17 MB users.csv | text/csv | 29 MB
Granska filen users.csv
Innan du försöker mata in data från en fil måste du förstå strukturen för data i filen. Det enklaste sättet att förstå strukturen är att förhandsgranska filen i Azure-portalen, men den här funktionen är begränsad till filer som är mindre än 2,1 MB. Utdata från blob_list() funktionen visar att båda filerna som Woodgrove Bank gav dig är större än gränsen. Om du vill granska filerna måste du ladda ned och öppna dem lokalt.
Gå till lagringskontoresursen i Azure-portalen, välj Lagringswebbläsare på den vänstra navigeringsmenyn och välj sedan Blobcontainrar på sidan Lagringswebbläsare.
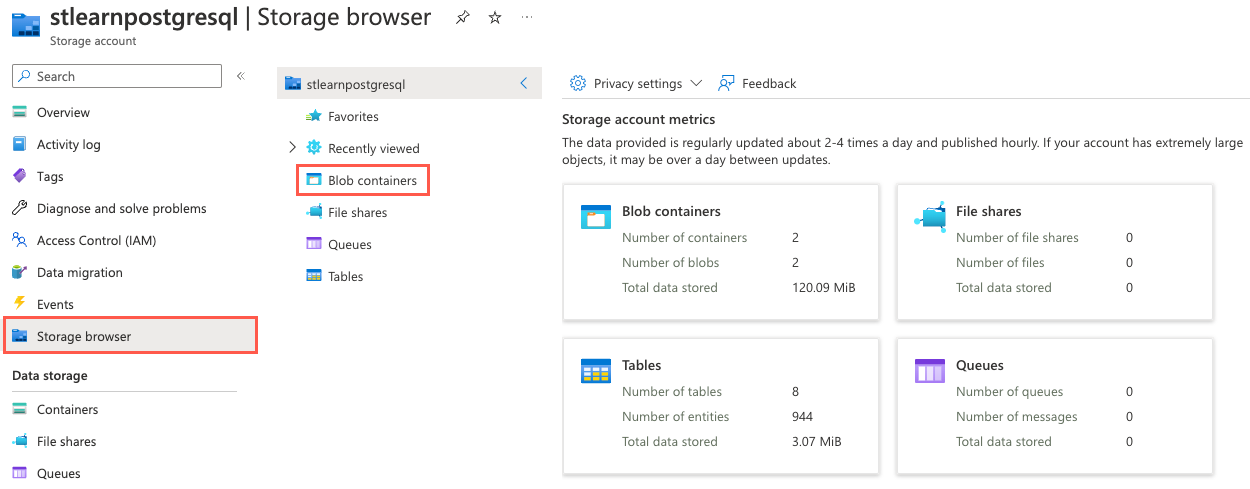
I listan med containrar väljer du historical-data.
Välj ellipsknappen (...) till höger om
users.csvfilen och välj Ladda ned på snabbmenyn.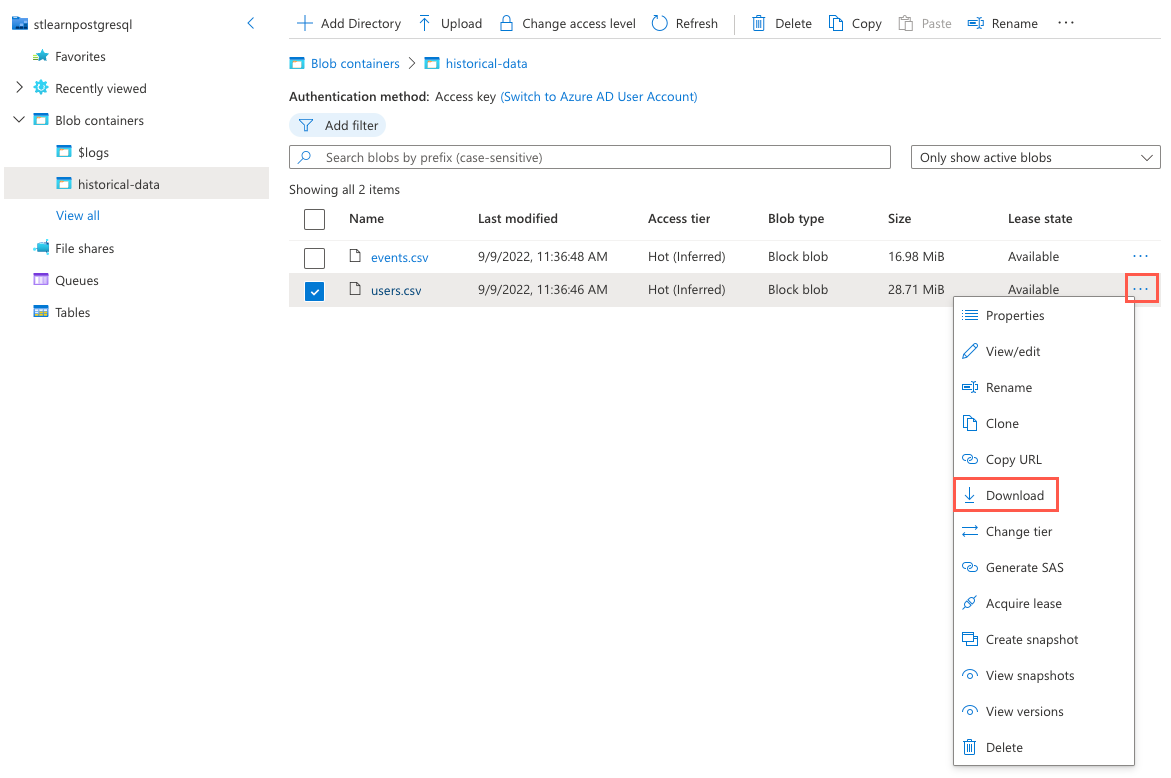
När nedladdningen är klar öppnar du filen med Hjälp av Microsoft Excel (eller en annan textredigerare som kan öppna CSV-filer) och observerar strukturen för data som finns i filen, vilket liknar följande exempel på de första 10 raderna i
users.csvfilen.user_idurlloginavatar_url21https://api.woodgrove.com/users/technoweenietechnoweeniehttps://avatars.woodgroveusercontent.com/u/21?22https://api.woodgrove.com/users/macournoyermacournoyerhttps://avatars.woodgroveusercontent.com/u/22?38https://api.woodgrove.com/users/atmosatmoshttps://avatars.woodgroveusercontent.com/u/38?45https://api.woodgrove.com/users/mojodnamojodnahttps://avatars.woodgroveusercontent.com/u/45?69https://api.woodgrove.com/users/rsanheimrsanheimhttps://avatars.woodgroveusercontent.com/u/69?78https://api.woodgrove.com/users/indirectindirecthttps://avatars.woodgroveusercontent.com/u/78?81https://api.woodgrove.com/users/engineyardengineyardhttps://avatars.woodgroveusercontent.com/u/81?82https://api.woodgrove.com/users/jsierlesjsierleshttps://avatars.woodgroveusercontent.com/u/82?85https://api.woodgrove.com/users/brixenbrixenhttps://avatars.woodgroveusercontent.com/u/85?87https://api.woodgrove.com/users/tmorninitmorninihttps://avatars.woodgroveusercontent.com/u/87?Observera att filen innehåller fyra kolumner. Den första kolumnen innehåller heltalsvärden och de återstående kolumnerna innehåller text. Det är också viktigt att observera att filen inte innehåller någon rubrikrad. Den här informationen ändrar hur du konfigurerar
COPYkommandot för att mata in filens data i databasen.Du skapade tabellen
payment_usersi enhet 3. Som en påminnelse är tabellens struktur följande:/* -- Table structure and distribution details provided for reference CREATE TABLE payment_users ( user_id bigint PRIMARY KEY, url text, login text, avatar_url text ); SELECT created_distributed_table('payment_users', 'user_id'); */Baserat på den observerade strukturen i
users.csvfilen verkar data stämma överens med vad som förväntas och du bör kunna läsa inpayment_userstabellen utan problem.
Extrahera data från filer i bloblagring
Nu när du förstår data i filen kan du uppfylla Woodgrove Banks begäran om att massinläsa historiska data från filer i ett Azure Blob Storage-konto. Tillägget pg_azure_storage tillhandahåller massinläsningsfunktioner genom att utöka det interna PostgreSQL-kommandot COPY så att det kan hantera Azure Blob Storage-resurs-URL:er. Den här funktionen är aktiverad som standard och du kan hantera den med hjälp av inställningen azure_storage.enable_copy_command .
Använd det utökade
COPYkommandot och kör följande kommando för att mata in data frånusers.csvtabellenpayment_usersoch se till att ersätta{STORAGE_ACCOUNT_NAME}token med det unika namnet på lagringskontot som du skapade ovan.-- Bulk load data from the user.csv file in Blob Storage into the payment_users table copy payment_users FROM 'https://{STORAGE_ACCOUNT_NAME}.blob.core.windows.net/historical-data/users.csv';Utdata från
COPYkommandot anger antalet rader som kopieras till tabellen. Du bör se resultatet förusers.csvfilen:COPY 264197.users.csvAnta att filen innehöll en rubrikrad. Om du vill hantera det med hjälp avCOPYkommandot ochpg_azure_storagetillägget måste du ange alternativetWITH (header)som följer resurs-URL:en. Exempel:copy payment_users FROM 'https://{STORAGE_ACCOUNT_NAME}.blob.core.windows.net/historical-data/users.csv' WITH (header);Kör sedan en
COUNTfråga ipayment_userstabellen för att verifiera antalet poster som kopierats till tabellen:SELECT COUNT(*) FROM payment_users;Du bör se följande resultat som matchar resultatet från
COPYkommandot:count -------- 264197Gratulerar! Du har utökat din Azure Cosmos DB for PostgreSQL-databas och använt
pg_azure_storagetillägget för att mata in fildata från en säker container i Azure Blob Storage till en distribuerad tabell.I Cloud Shell kör du följande kommando för att koppla från databasen:
\q
Rensa
Det är viktigt att du rensar alla oanvända resurser. Du debiteras för den konfigurerade kapaciteten, inte hur mycket databasen används. Använd följande procedur för att ta bort resursgruppen tillsammans med de resurser som du skapade för den här modulen.
Öppna en webbläsare och gå till Azure-portalen.
I den vänstra navigeringsmenyn väljer du Resursgrupper och sedan den resursgrupp som du skapade som en del av övningen i enhet 4.
I fönstret Översikt väljer du Ta bort resursgrupp.
Ange namnet på resursgruppen som du skapade för att bekräfta och välj sedan Ta bort.
Välj Ta bort igen för att bekräfta borttagningen.