Kombinera och optimera data
Organisationer sorterar ofta olika typer av information från många källor. Informationen lagras i ett stort antal tabeller. Ibland kan du behöva koppla tabeller baserat på logiska relationer mellan dem, för djupare analys eller rapportering. I detaljhandelsscenariot använder du tabeller för kunder, produkter och försäljningsinformation.
I den här modulen får du lära dig om olika sätt att kombinera data i Kusto-frågor för att ge dina teammedlemmar den information de behöver för att öka produktmedvetenheten och öka försäljningen.
Förstå dina data
Innan du börjar skriva frågor som kombinerar information från dina tabeller måste du förstå dina data. När du arbetar med Kusto-frågor vill du se tabeller som i stort sett hör till någon av två kategorier:
- Faktatabeller: Tabeller vars poster är oföränderliga fakta, till exempel tabellen SalesFact i detaljhandelsscenariot. I dessa tabeller läggs poster progressivt till i ett fortlöpande flöde eller i stora block. Posterna finns kvar i tabellen tills de tas bort och de uppdateras aldrig.
- Dimensionstabeller: Tabeller som har föränderliga dimensioner i sina poster, till exempel i detaljhandelsscenariot, så som tabellerna Kunder och Produkter. Dessa tabeller innehåller referensdata, till exempel uppslagstabeller från en entitetsidentifierare till dess egenskaper. Dimensionstabeller uppdateras inte regelbundet med nya data.
I vårt detaljhandelsföretagsscenario använder du dimensionstabeller för att utöka tabellen SalesFact med ytterligare information eller för att tillhandahålla fler alternativ för att filtrera data för frågor.
Du vill också förstå de datavolymer som du arbetar med och dess struktur eller schema (kolumnnamn och typer). Du kan köra följande frågor för att hämta den informationen genom att ersätta TABLE_NAME med namnet på tabellen som du undersöker:
Om du vill hämta antalet poster i en tabell använder du operatorn
count:KustoTABLE_NAME | countOm du vill hämta schemat för en tabell använder du operatorn
getschema:KustoTABLE_NAME | getschema
När du kör dessa frågor på fakta- och dimensionstabellerna i detaljhandelsföretagets scenario får du information som i följande exempel:
| Bord | Arkiv | Schemat |
|---|---|---|
| SalesFact | 2,832,193 | - SalesAmount (verklig) - TotalCost (verklig) – DateKey (datumtid) - ProductKey (lång) - CustomerKey (lång) |
| Kunder | 18,484 | – CityName (sträng) – CompanyName (sträng) – ContinentName (sträng) - CustomerKey (lång) - Utbildning (textsträng) – Förnamn (sträng) - Kön (sträng) – Efternamn (sträng) – Civilstånd (sträng) - Yrke (text) – RegionCountryName (sträng) – StateProvinceName (sträng) |
| Produkter | 2,517 | – ProductName (sträng) – Tillverkare (sträng) - ColorName (sträng) – ClassName (sträng) – ProductCategoryName (sträng) – ProductSubcategoryName (sträng) - ProductKey (lång) |
I tabellen markerade vi de unika identifierare CustomerKey och ProductKey- som används för att kombinera poster mellan tabeller.
Förstå frågor med flera tabeller
När du har analyserat dina data måste du förstå hur du kombinerar tabeller för att tillhandahålla den information du behöver. Kusto-frågor innehåller flera operatorer som du kan använda för att kombinera data från flera tabeller, inklusive operatorerna lookup, joinoch union.
Operatorn join sammanfogar raderna i två tabeller genom att matcha värdena för de angivna kolumnerna från varje tabell. Den resulterande tabellen beror på vilken typ av koppling du använder. Om du till exempel använder en inre kopplinghar tabellen samma kolumner som den vänstra tabellen (kallas ibland yttre tabellen), plus kolumnerna från den högra tabellen (kallas ibland inre tabell). Du lär dig mer om kopplingstyper i nästa avsnitt. För bästa prestanda, om en tabell alltid är mindre än den andra, använder du den som vänster sida av join-operatorn.
Operatorn lookup är en särskild implementering av en join-operator som optimerar prestandan för frågor där en faktatabell berikas med data från en dimensionstabell. Den utökar faktatabellen med värden som letas upp i en dimensionstabell. För bästa prestanda förutsätter systemet som standard att den vänstra tabellen är den större tabellen (fakta) och att den högra tabellen är den mindre tabellen (dimensionen). Detta antagande är precis motsatsen till det antagande som används av join-operatorn.
Operatorn union returnerar alla rader från två eller flera tabeller. Det är användbart när du vill kombinera data från flera tabeller.
Funktionen materialize() cachelagrar resultat i ett frågeutförande för senare återanvändning i frågan. Det är som att ta en ögonblicksbild av resultatet av en underfråga och använda den flera gånger i frågan. Den här funktionen är användbar för att optimera frågor för scenarier där resultatet:
- Är dyra att beräkna
- Är nondeterministiska
Snart lär du dig mer om de olika tabellsammanslagningens operatorer och funktionen materialize() och hur du använder dem.
Typer av koppling
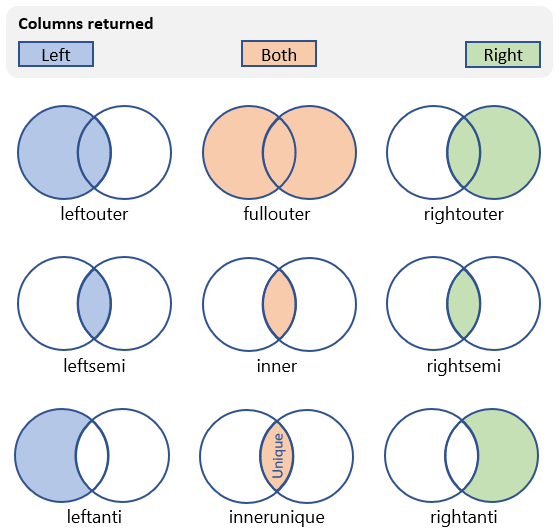
Det finns många olika typer av kopplingar som kan utföras som påverkar schemat och raderna i den resulterande tabellen. I följande tabell visas de typer av kopplingar som stöds av Kusto Query Language och schema och rader som de returnerar:
| Gå med snäll | Beskrivning | Illustration |
|---|---|---|
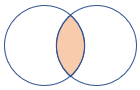
innerunique (förvalt) |
Inre koppling med deduplicering på vänster sida Schema: Alla kolumner från båda tabellerna, inklusive matchande nycklar Rader: Alla deduplicerade rader från den vänstra tabellen som matchar rader från den högra tabellen |
|
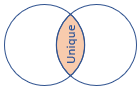
inner |
Inre standardkoppling Schema: Alla kolumner från båda tabellerna, inklusive matchande nycklar rader: Endast matchande rader från båda tabellerna |
|
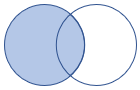
leftouter |
Vänster yttre koppling Schema: Alla kolumner från båda tabellerna, inklusive matchande nycklar Rader: Alla poster från den vänstra tabellen och endast matchande rader från den högra tabellen |
|
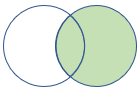
rightouter |
Höger yttre koppling Schema: Alla kolumner från båda tabellerna, inklusive matchande nycklar Rader: Alla värden från den högra tabellen och endast matchande rader från den vänstra tabellen |
|
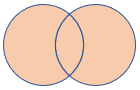
fullouter |
Fullständig yttre koppling Schema: Alla kolumner från båda tabellerna, inklusive matchande nycklar Rader: Alla poster från båda tabellerna med omatchade celler ifyllda med null |
|
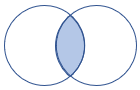
leftsemi |
Vänster halvkoppling Schema: Alla kolumner från den vänstra tabellen Rader: Alla poster från vänstra tabellen som matchar poster i högra tabellen |
|
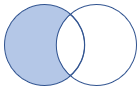
leftanti, anti, leftantisemi |
Vänster antikoppling och semivariant Schema: Alla kolumner från den vänstra tabellen Rader: Alla poster från den vänstra tabellen som inte matchar poster från den högra tabellen |
|
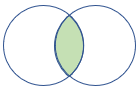
rightsemi |
Höger halvkoppling Schema: Alla kolumner från den högra tabellen Rader: Alla poster från den högra tabellen som stämmer överens med poster från den vänstra tabellen |
|
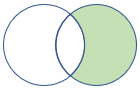
rightanti, rightantisemi |
Höger antikoppling och semivariant Schema: Alla kolumner från den högra tabellen Rader: Alla poster från den högra tabellen som inte har någon motsvarighet i den vänstra tabellen |
|
Observera att standardanslutningstypen är inneruniqueoch att den inte behöver anges. Det är dock bästa praxis att alltid uttryckligen ange kopplingstyp för tydlighetens skull.
När du går vidare med den här modulen lär du dig även om aggregeringsfunktionerna arg_min() och arg_max(), as-operatorn som ett alternativ till let-instruktionen och funktionen startofmonth() för att hjälpa till med att gruppera data efter månad.