Förstå pipelines
Pipelines i Microsoft Fabric kapslar in en sekvens med aktiviteter som utför dataflytt och bearbetningsuppgifter. Du kan använda en pipeline för att definiera dataöverförings- och transformeringsaktiviteter och samordna dessa aktiviteter via kontrollflödesaktiviteter som hanterar förgrening, loopning och annan typisk bearbetningslogik. Med den grafiska pipelinearbetsytan i användargränssnittet för Infrastruktur kan du skapa komplexa pipelines med minimal eller ingen kodning krävs.
Grundläggande pipelinebegrepp
Innan du skapar pipelines i Microsoft Fabric bör du förstå några grundläggande begrepp.
Aktiviteter
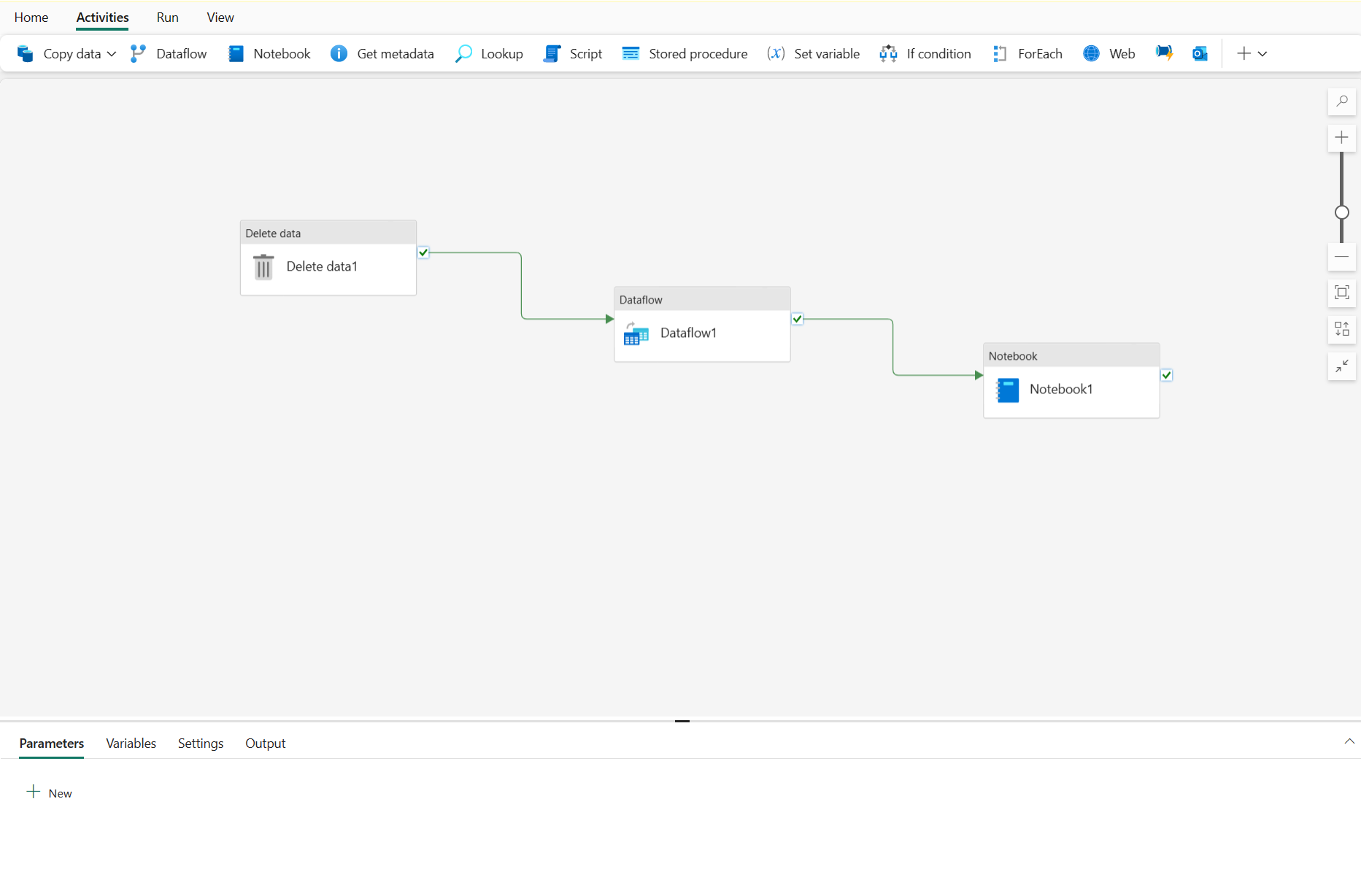
Aktiviteter är körbara uppgifter i en pipeline. Du kan definiera ett flöde av aktiviteter genom att ansluta dem i en sekvens. Resultatet av en viss aktivitet (framgång, fel eller slutförande) kan användas för att dirigera flödet till nästa aktivitet i sekvensen.
Det finns två breda aktivitetskategorier i en pipeline.
Datatransformeringsaktiviteter – aktiviteter som kapslar in dataöverföringsåtgärder, inklusive enkla kopieringsdataaktiviteter som extraherar data från en källa och läser in dem till ett mål, och mer komplexa Dataflöde aktiviteter som kapslar in dataflöden (Gen2) som tillämpar transformeringar på data när de överförs. Andra datatransformeringsaktiviteter är Notebook-aktiviteter för att köra en Spark-notebook-fil, Lagrade procedurer för att köra SQL-kod, Ta bort dataaktiviteter för att ta bort befintliga data och andra.
Kontrollera flödesaktiviteter – aktiviteter som du kan använda för att implementera loopar, villkorsstyrd förgrening eller hantera värden för variabler och parametrar. Med det breda utbudet av kontrollflödesaktiviteter kan du implementera komplex pipelinelogik för att samordna datainmatning och transformeringsflöde.
Dricks
Mer information om den fullständiga uppsättningen pipelineaktiviteter som är tillgängliga i Microsoft Fabric finns i Aktivitetsöversikt i Microsoft Fabric-dokumentationen.
Parametrar
Pipelines kan parametriseras så att du kan ange specifika värden som ska användas varje gång en pipeline körs. Du kanske till exempel vill använda en pipeline för att spara inmatade data i en mapp, men har flexibiliteten att ange ett mappnamn varje gång pipelinen körs.
Med hjälp av parametrar ökar återanvändningen av dina pipelines så att du kan skapa flexibla datainmatnings- och transformeringsprocesser.
Pipelinekörningar
Varje gång en pipeline körs initieras en datapipelinekörning . Körningar kan initieras på begäran i fabric-användargränssnittet eller schemaläggas att starta med en viss frekvens. Använd det unika körnings-ID:t för att granska körningsinformationen för att bekräfta att de har slutförts och undersöka de specifika inställningar som används för varje körning.