Grundläggande felsökning av problem med start av AKS-kluster
Den här artikeln beskriver de grundläggande felsökningsmetoder som ska användas om du inte kan starta ett AkS-kluster (Microsoft Azure Kubernetes Service).
Azure CLI (version 2.0.59 eller senare).
Kubernetes kubectl-verktyget . Om du vill installera kubectl med hjälp av Azure CLI kör du kommandot az aks install-cli .
När du startar kluster med hjälp av Azure CLI registreras fel som utdata om åtgärden misslyckas. Så här kan ett kommando, användarindata och åtgärdsutdata visas i en Bash konsol:
$ az aks start --resource-group myResourceGroup --name MyManagedCluster
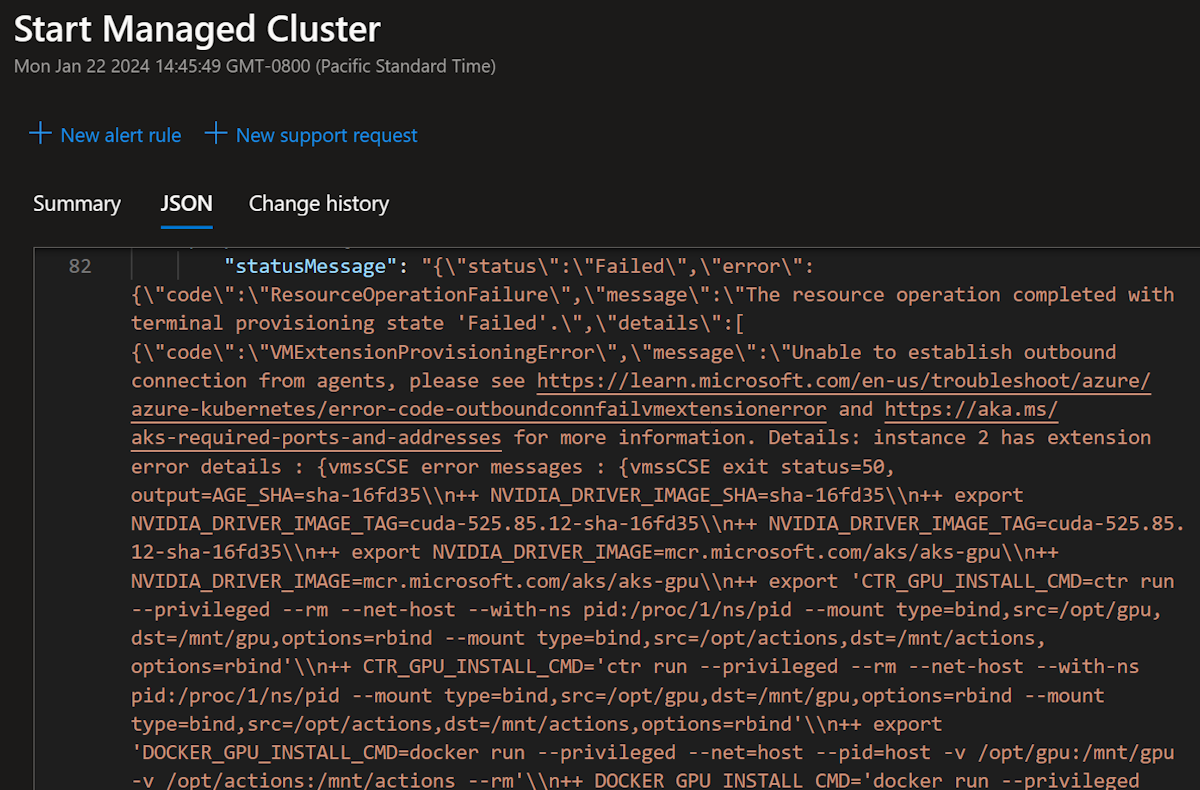
(VMExtensionProvisioningError) Unable to establish outbound connection from agents, please see https://learn.microsoft.com/en-us/troubleshoot/azure/azure-kubernetes/error-code-outboundconnfailvmextensionerror and https://aka.ms/aks-required-ports-and-addresses for more information.
Details: instance 3 has extension error details : {vmssCSE error messages : {vmssCSE exit status=50, output=AGE_SHA=sha-16fd35
Dessa fel innehåller ofta detaljerade beskrivningar av vad som gick fel i klusterstartåtgärden, och de innehåller länkar till artiklar som innehåller mer information. Dessutom kan du använda våra felsökningsartiklar som referens baserat på felet som en Azure CLI-åtgärd genererar.
Om du vill visa information om fel i Azure Portal granskar du Azure-aktivitetsloggen. Sök i aktivitetsloggen för att hitta listan över aktivitetsloggar i Azure Portal. Eller välj Meddelanden (klockikonen) och välj sedan Fler händelser i aktivitetsloggen.
Listan över loggar på sidan Aktivitetslogg innehåller en radpost där kolumnvärdet Åtgärdsnamn heter Starta hanterat kluster. Motsvarande händelse som initieras av kolumnvärdet anges till namnet på ditt arbets- eller skolkonto. Om åtgärden lyckas visar kolumnvärdet Status Godkända.
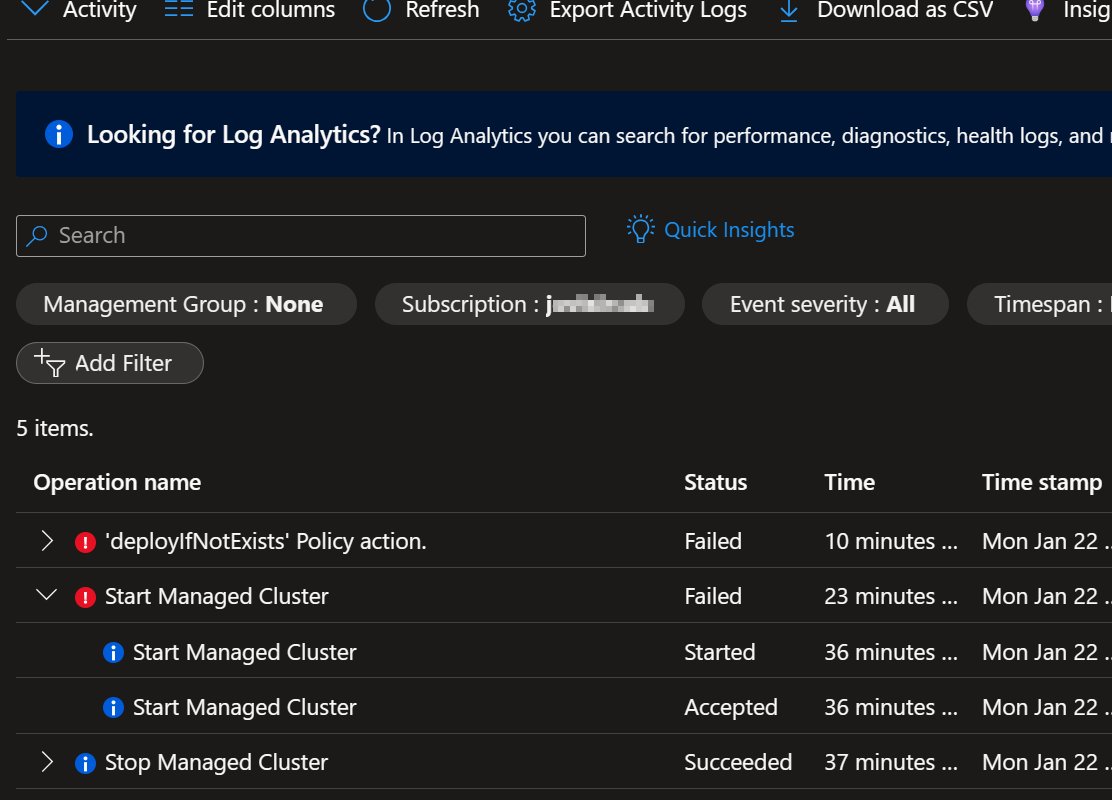
Vad händer om ett fel inträffar i stället? I så fall visas fältet Status för åtgärden Starta hanterat kluster. Till skillnad från i åtgärderna för att skapa klusterkomponenter måste du expandera posten för den misslyckade åtgärden för att granska underoperationsposterna. Typiska underoperationsnamn är principåtgärder, till exempel "granska" principåtgärd och principåtgärden "auditIfNotExists". Vissa underåtgärder fortsätter att visa att de lyckades.
Om du vill undersöka ytterligare kan du välja en av de misslyckade underåtgärderna. En sidoruta öppnas så att du kan granska mer information om underåtgärden. Du kan felsöka värden för fält som Sammanfattning, JSON och Ändringshistorik. JSON-fältet innehåller utdatatexten för felet i JSON-format och innehåller vanligtvis den mest användbara informationen.
Du kan också generera klusterinsikter som hjälper dig att felsöka via bladet Diagnostisera och lösa problem i Azure Portal. Följ dessa steg för att komma åt den här funktionen:
I Azure Portal söker du efter och väljer Kubernetes-tjänster.
Välj namnet på ditt AKS-kluster.
I navigeringsfönstret på AKS-klustersidan väljer du Diagnostisera och lösa problem.
På sidan Diagnostisera och lösa problem väljer du länken Klusterinsikter . Verktyget klusterinsikter analyserar klustret och ger sedan en lista över resultaten i avsnittet Observationer och lösningar på sidan Klusterinsikter .
Välj ett av resultaten för att visa mer information om ett problem och dess möjliga lösningar.
I Azure Portal kanske du vill visa de resurser som skapades när klustret skapades. Dessa resurser finns vanligtvis i en resursgrupp som börjar med MC_. Resursgruppen för det hanterade klustret kan ha ett namn som MC_MyResourceGroup_MyManagedCluster_location-code>.< Namnet kan dock vara annorlunda om du har skapat klustret med hjälp av en anpassad hanterad klusterresursgrupp.
Om du vill hitta resursgruppen söker du efter och väljer Resursgrupper i Azure Portal och väljer sedan den resursgrupp där klustret skapades. Resurslistan visas på sidan Översikt i resursgruppen.
Varning
Vi rekommenderar att du inte ändrar resurser i resursgruppen MC_ . Den här åtgärden kan orsaka oönskade effekter på DITT AKS-kluster.
Om du vill granska statusen för en VM-skalningsuppsättning kan du välja skalningsuppsättningens namn i resurslistan för resursgruppen. Det kan ha ett namn som liknar aks-nodepool1-12345678-vmss och ett typvärde för VM-skalningsuppsättning. Status för skalningsuppsättningen visas överst på nodpoolens översiktssida, och mer information visas i rubriken Essentials. Om distributionen misslyckades är den visade statusen Misslyckad.
För alla resurser kan du granska information för att bättre förstå varför distributionen misslyckades. För en skalningsuppsättning kan du välja statustexten Misslyckades för att visa information om felet. Informationen finns på en rad som innehåller kolumnerna Status, Nivå och Kod . I följande exempel visas en rad med kolumnvärden.
| Column | Exempelvärde |
|---|---|
| Status | Etableringen misslyckades |
| Nivå | Fel |
| Kod | ProvisioningState/failed/VMExtensionProvisioningError |
Välj raden för att se fältet Meddelande . Detta innehåller ännu mer information om felet. Till exempel börjar fältet Meddelande för exempelraden med följande text:
Den virtuella datorn har rapporterat ett fel vid bearbetning av tillägget "vmssCSE". Felmeddelande: "Aktivera misslyckades: det gick inte att köra kommandot: kommandot avslutades med slutstatus=50 [stdout] [stderr] 0 0 0 --: Beväpnad med den här informationen kan du dra slutsatsen att de virtuella datorerna i skalningsuppsättningen misslyckades och genererade utgångsstatus 50.
Om du vill ha ett annat alternativ för att felsöka fel i klustret anger du kubectl-kommandon för att få information om de resurser som distribuerades i klustret. Om du vill använda kubectl loggar du först in på ditt AKS-kluster:
az aks get-credentials --resource-group MyResourceGroup --name MyManagedCluster
Beroende på typen av fel och när det inträffade kanske du inte kan logga in på klustret för att få mer information. Men i allmänhet bör du kunna logga in och köra kubectl-kommandon om klustret har skapats och visas i Azure Portal.
Om du vill ha mer information för att fastställa nodernas tillstånd kan du visa klusternoderna genom att ange kommandot kubectl get nodes . I det här exemplet rapporteras inga noder i klustret:
$ kubectl get nodes
No resources found
Att visa poddarna i kube-system-namnområdet är också ett bra sätt att felsöka problemet. Med den här metoden kan du visa status för Kubernetes-systempoddar. I det här exemplet anger kubectl get pods vi kommandot:
$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-845757d86-7xjqb 0/1 Pending 0 78m
coredns-autoscaler-5f85dc856b-mxkrj 0/1 Pending 0 77m
konnectivity-agent-67f7f5554f-nsw2g 0/1 Pending 0 77m
konnectivity-agent-8686cb54fd-xlsgk 0/1 Pending 0 65m
metrics-server-6bc97b47f7-dfhbr 0/1 Pending 0 77m
Genom att beskriva statusen för poddarna kan du visa konfigurationsinformationen och alla händelser som har inträffat på poddarna. Kör kommandot kubectl describe pod:
$ kubectl describe pod coredns-845757d86-7xjqb -n kube-system
Name: coredns-845757d86-7xjqb
Namespace: kube-system
Priority: 2000001000
Priority Class Name: system-node-critical
Node: <none>
Labels: k8s-app=kube-dns
kubernetes.io/cluster-service=true
pod-template-hash=845757d86
version=v20
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 24m (x1 over 25m) default-scheduler no nodes available to schedule pods
Warning FailedScheduling 29m (x57 over 84m) default-scheduler no nodes available to schedule pods
I kommandoutdata kan du se att podden inte kan distribueras till en nod eftersom inga noder är tillgängliga.
Om du har frågor eller behöver hjälp skapar du en supportförfrågan eller frågar Azure community support. Du kan också skicka produktfeedback till Azure-feedbackcommunityn.