Grundläggande felsökning av nodfel som inte är redo
Den här artikeln innehåller felsökningssteg för att återställa Klusternoder i Microsoft Azure Kubernetes Service (AKS) efter ett fel. Den här artikeln tar specifikt upp de vanligaste felmeddelandena som genereras när ett nodfel inte är klart inträffar och förklarar hur nodreparationsfunktioner kan göras för både Windows- och Linux-noder.
Innan du börjar
Läs den officiella guiden för felsökning av Kubernetes-kluster. Läs även Microsoft-teknikerns guide till Kubernetes-felsökning. Den här guiden innehåller kommandon för felsökning av poddar, noder, kluster och andra funktioner.
Förutsättningar
- Azure CLI, version 2.31 eller senare. Om Azure CLI redan är installerat kan du hitta versionsnumret genom att köra
az --version.
Grundläggande felsökning
AKS övervakar kontinuerligt hälsotillståndet för arbetsnoder och reparerar automatiskt noderna om de inte är felfria. Azure Virtual Machine-plattformen (VM) underhåller virtuella datorer som upplever problem. VIRTUELLA AKS- och Azure-datorer arbetar tillsammans för att minska tjänststörningar för kluster.
För noder finns det två former av pulsslag:
Uppdateringar till statusfilen för ett
Nodeobjekt.Leasa objekt i namnområdet kube-node-lease . Var och
Nodeen har ett associeratLeaseobjekt.
Jämfört med uppdateringar av statusfilen för en Nodeär en Lease enkel resurs. Om du använder Lease objekt för pulsslag minskar prestandapåverkan för dessa uppdateringar för stora kluster.
Kubelet ansvarar för att skapa och uppdatera .status-filen för Node objekt. Den ansvarar också för att uppdatera de Lease objekt som är relaterade till objekten Node .
Kubelet uppdaterar Nodestatusfilen om något av följande villkor är sant:
En statusändring sker.
Ingen uppdatering sker efter ett konfigurerat tidsintervall.
Standardintervallet för statusuppdateringar till en Node är fem minuter. Det här intervallet är mycket längre än 40 sekunders standardtidsgränsen för noder som inte kan nås. Kubelet skapar och uppdaterar sedan objektet Lease en gång var tionde sekund (standarduppdateringsintervallet). Uppdateringar ske Lease oberoende av uppdateringar av statusenNode. Lease Om uppdateringen misslyckas försöker kubelet igen med hjälp av en exponentiell backoff som startar vid 200 millisekunder och begränsas till högst sju sekunder.
Du kan inte schemalägga en Pod för en Node som har statusen NotReady eller Unknown. Du kan bara schemalägga en Pod på noder som är i Ready tillståndet .
Om noden är i MemoryPressuretillståndet , DiskPressureeller PIDPressure måste du hantera dina resurser för att schemalägga extra poddar på noden. Om noden är i NetworkUnavailable läge måste du konfigurera nätverket på noden korrekt. Kontrollera att följande villkor är uppfyllda:
Klustret är i tillståndet Lyckades (körs). Om du vill kontrollera klusterstatusen på Azure Portal söker du efter och väljer Kubernetes-tjänster och väljer namnet på ditt AKS-kluster. På klustrets översiktssida tittar du sedan i Essentials för att hitta statusen. Du kan också ange kommandot az aks show i Azure CLI.
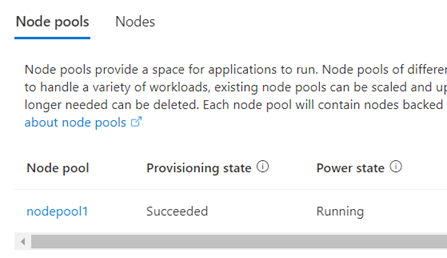
Nodpoolen har etableringstillståndetLyckades och energispartillståndetKörs. Om du vill kontrollera statusen för nodpoolen på Azure Portal går du tillbaka till AKS-klustrets sida och väljer sedan Nodpooler. Du kan också ange kommandot az aks nodepool show i Azure CLI.
De nödvändiga utgående portarna är öppna i nätverkssäkerhetsgrupperna (NSG:er) och brandväggen så att API-serverns IP-adress kan nås. Mer information finns i Obligatoriska regler för utgående nätverk och FQDN för AKS-kluster.
Noderna är i tillståndet i
Runningstället förStoppedellerDeallocated.Klustret kör en AKS-version av Kubernetes som stöds.
Ansvarsfriskrivning för tredje part
Microsoft tillhandahåller kontaktinformation från tredje part som hjälper dig att hitta ytterligare information om det här ämnet. Denna kontaktinformation kan ändras utan föregående meddelande. Microsoft garanterar inte att kontaktinformation från tredje part är korrekt.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för