Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Lagringsdirigering är en funktion i Azure Local och Windows Server som gör att du kan klustra servrar med intern lagring till en programvarudefinierad lagringslösning.
Den här artikeln innehåller en översikt över Lagringsutrymmen Direct, hur det fungerar, när du ska använda det och dess viktigaste fördelar. Du kan också utforska videor och verkliga kundberättelser i den här artikeln för att lära dig mer om Lagringsutrymmen Direct.
Kom igång genom att prova Lagringsdirigering i Microsoft Azure eller ladda ned en 180-dagars licensierad utvärderingskopia av Windows Server från Windows Server Evaluations. Information om de lägsta maskinvarukraven för Lagringsdirigering på Windows Server och Azure Local finns i Systemkrav för Windows Server respektive Systemkrav för Azure Local. Information om hur du distribuerar Lagringsdirigering som en del av Azure Local finns i Distribuera det lokala Azure-operativsystemet.
Vad är Lagringsutrymmen Direct?
Lagringsdirigering är en programvarudefinierad lagringslösning som gör att du kan dela lagringsresurser i din konvergerade och hyperkonvergerade IT-infrastruktur. Det gör att du kan kombinera interna lagringsenheter på ett kluster med fysiska servrar (2 och upp till 16) till en programvarudefinierad lagringspool. Den här lagringspoolen har cache-, nivå-, återhämtnings- och raderingskodning över kolumner – allt konfigurerat och hanterat automatiskt.
Du kan skala ut klustrets lagringskapacitet genom att lägga till fler enheter eller lägga till fler servrar i klustret. Lagringsdirigering registrerar automatiskt de nya enheterna och balanserar om lagringspoolen. Den använder också automatiskt de snabbaste lagringsmedierna som finns för att tillhandahålla inbyggd cache som alltid är på.
Lagringsdirigering är en kärnteknik för Azure Local, versionerna 21H2 och 20H2. Den ingår också i Datacenter-versionerna av Windows Server 2022, Windows Server 2019, Windows Server 2016, Windows Server Insider Preview Builds och Azure Edition av Windows Server 2022.
Du kan distribuera Lagringsutrymmen Direct på ett kluster med fysiska servrar eller på virtuella datorers gästkluster (VM).
Distribution av Lagringsdirigering på VM-gästkluster ger virtuell delad lagring över en uppsättning virtuella datorer ovanpå ett privat eller offentligt moln. I produktionsmiljöer stöds den här distributionen endast i Windows Server. Information om hur du distribuerar Lagringsdirigering på VM-gästkluster i Windows Server finns i Använda Lagringsdirigering i virtuella gästdatorkluster.
Så här fungerar det
Lagringsdirigering använder många av funktionerna i Windows Server, till exempel redundansklustring, filsystemet för klusterdelade volymer (CSV), SMB 3 (Server Message Block) och Lagringsutrymmen. Den introducerar också en ny teknik som kallas Software Storage Bus.
Lagringsdirigering skapar en programvarudefinierad lagringslösning genom att kombinera de interna lagringsenheterna på ett kluster av servrar av branschstandard. Du börjar med att ansluta dina servrar med interna lagringsenheter via Ethernet för att bilda ett kluster – ingen speciell kabel eller lagringsstruktur krävs. När du aktiverar Lagringsdirigering på det här klustret kombineras lagringsenheterna från var och en av dessa servrar till en programvarudefinierad pool med virtuellt delad lagring.
Sedan skapar du volymer från den lagringspoolen, där du kan lagra dina data. Dessa volymer kör CSV-filsystemet. Det innebär att dessa volymer för varje server ser ut och fungerar som om de vore monterade lokalt. Med inbyggd feltolerans i dessa volymer förblir dina data online och tillgängliga även om en enhet går sönder eller om hela noden går offline.
I dessa volymer kan du placera dina filer, till exempel .vhd och .vhdx för virtuella datorer. Du kan använda klustret som kör Lagringsdirigering som:
- Skala ut filservern (SoFS) genom att exponera volymerna över nätverket som SMB3-filresurser.
- Hyperkonvergerat system genom att aktivera Hyper-V i klustret och placera dina virtuella datorer direkt ovanpå volymerna.
I följande avsnitt beskrivs funktionerna och komponenterna i en Lagringsdirigering-stack.
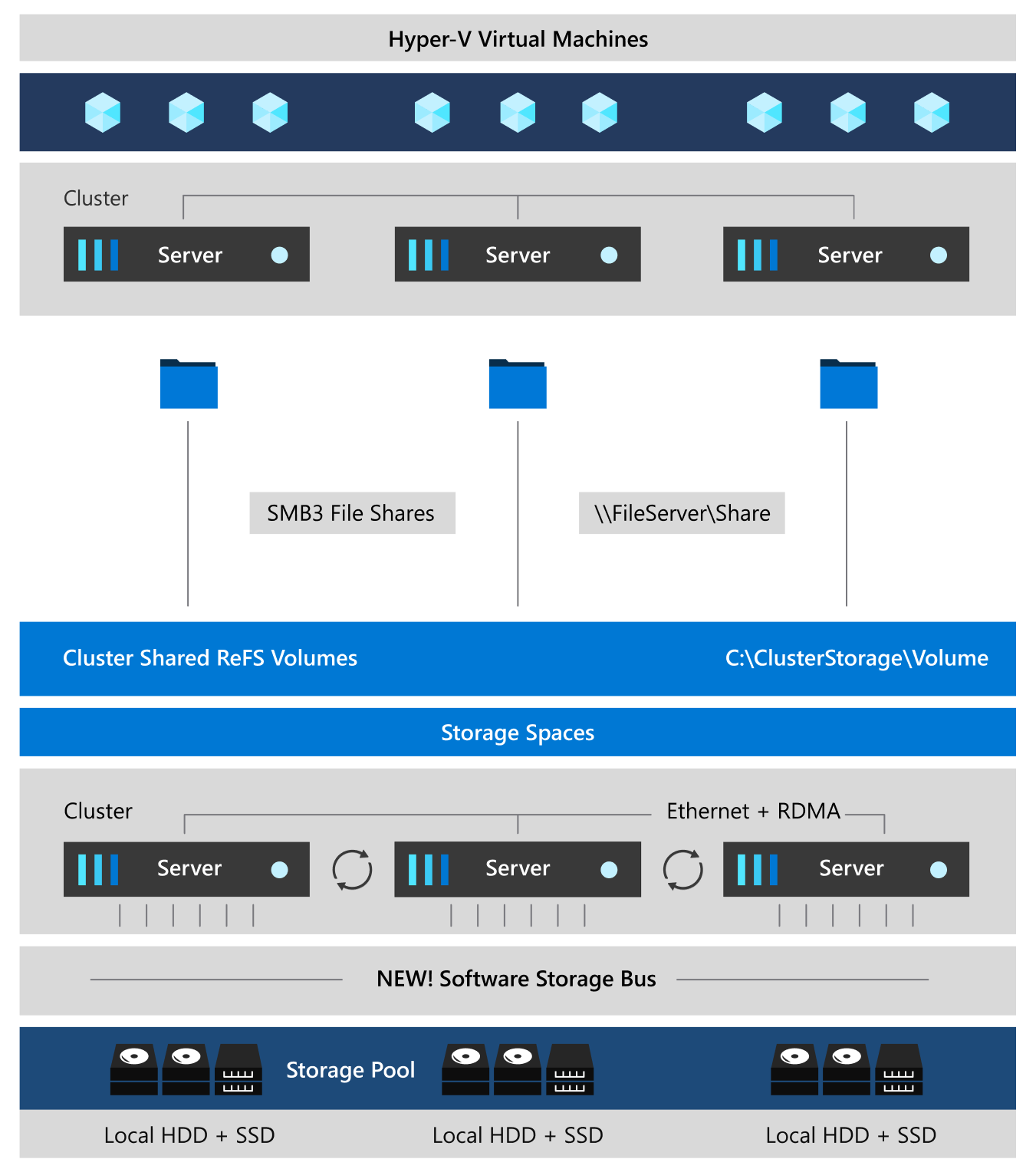
Nätverksmaskinvara. Lagringsdirigering använder SMB3, inklusive SMB Direct och SMB Multichannel, över Ethernet för att kommunicera mellan servrar. Vi rekommenderar starkt att du använder 10+ GbE med RDMA (Remote Direct Memory Access), antingen iWARP eller RoCE.
Lagringsmaskinvara. Lagringsdirigering kräver 2 och upp till 16 Microsoft-godkända servrar med direktanslutna SATA-, SAS-, NVMe- eller beständiga minnesenheter som är fysiskt anslutna till bara en server vardera. Varje server måste ha minst två SSD-enheter och minst fyra fler enheter. SATA- och SAS-enheterna ska finnas bakom en värdbussadapter (HBA) och en SAS-expanderare.
Redundansklustring. Lagringsdirigering använder den inbyggda klustringsfunktionen i Azure Local och Windows Server för att ansluta servrarna.
Programvarulagringsbuss. Software Storage Bus sträcker sig över klustret och upprättar en programvarudefinierad lagringsstruktur där alla servrar kan se alla varandras lokala enheter. Du kan se det som att ersätta dyra och restriktiva Fibre Channel- eller Shared SAS-kablar.
Cacheminne för lagringsbusslager. Software Storage Bus binder dynamiskt de snabbaste enheterna som finns (till exempel SSD) till långsammare enheter (till exempel hårddiskar) för att tillhandahålla cachelagring av läsning/skrivning på serversidan som påskyndar I/O och ökar dataflödet.
Lagringspool. Samlingen av enheter som utgör grunden för Lagringsutrymmen kallas lagringspoolen. Den skapas automatiskt och alla berättigade enheter identifieras och läggs till automatiskt i den. Vi rekommenderar starkt att du använder en pool per kluster med standardinställningarna. Mer information om lagringspoolen finns i bloggen Djupdykning i lagringspoolen .
Lagringsutrymmen. Lagringsutrymmen ger feltolerans för "virtuella diskar" med hjälp av spegling, raderingskodning eller både och. Du kan se det som distribuerad, programvarudefinierad RAID med hjälp av enheterna i poolen. I Lagringsutrymmen Direct har dessa virtuella diskar vanligtvis motståndskraft mot två samtidiga enhets- eller serverfel (till exempel 3-vägsspegling, där varje datakopia kopieras på en annan server) – även om feltolerans för chassi och rack också är tillgängligt.
ReFS (Resilient File System). ReFS är det främsta filsystemet som är specialbyggt för virtualisering. Den innehåller dramatiska accelerationer för .vhdx-filåtgärder, till exempel skapande, expansion och sammanslagning av kontrollpunkter, och inbyggda kontrollsummor för att upptäcka och korrigera bitfel. Den introducerar också realtidsnivåer som roterar data mellan "heta" och "kalla" lagringsnivåer i realtid, baserat på användning.
Kluster delade volymer. CSV-filsystemet förenar alla ReFS-volymer i ett enda namnområde som är tillgängligt via valfri server. För varje server ser varje volym ut och fungerar som om den är monterad lokalt.
Scale-Out filserver. Det här sista lagret är endast nödvändigt i konvergerade distributioner. Det ger fjärråtkomst till filer genom att använda SMB3-åtkomstprotokollet till klienter, till exempel ett annat kluster som kör Hyper-V, över nätverket, vilket effektivt omvandlar Lagringsdirigering till nätverksansluten lagring (NAS).
Viktiga fördelar
Lagringsdirigering erbjuder följande viktiga fördelar:
| Image | Description |
|---|---|
|
|
Simplicity. Gå från branschstandardservrar som kör Windows Server eller Azure Local till ditt första lagringsdirigeringskluster på mindre än 15 minuter. För System Center-användare är distributionen bara en kryssruta. |
|
|
Höga prestanda. Oavsett om det är helt flash eller hybrid kan Lagringsutrymmen direkt överstiga 13,7 miljoner IOPS per server. Den hypervisor-inbäddade arkitekturen i Lagringsutrymmen Direct ger konsekvent, låg latens, inbyggd läs-/skrivcache och stöd för banbrytande NVMe-enheter monterade direkt på PCIe-bussen. |
|
|
Feltolerans. Inbyggd återhämtning hanterar enhets-, server- eller komponentfel med kontinuerlig tillgänglighet. Större distributioner kan också konfigureras för feltolerans för chassi och rack. När hårdvaran misslyckas är det bara att byta ut den; Programvaran läker sig själv utan komplicerade hanteringssteg. |
|
|
Resurseffektivitet. Raderingskodning ger upp till 2,4 gånger högre lagringseffektivitet, med unika innovationer, som lokala rekonstruktionskoder och ReFS-realtidsnivåer för att utöka dessa vinster till hårddiskar och blandade varma eller kalla arbetsbelastningar, samtidigt som CPU-förbrukningen minimeras för att ge resurser tillbaka till där de behövs mest – till de virtuella datorerna. |
|
|
Manageability. Använd QoS-kontroller för lagring för att hålla upptagna virtuella datorer i schack med lägsta och högsta IOPS-gränser per virtuell dator. Hälsotjänsten tillhandahåller kontinuerlig inbyggd övervakning och aviseringar. Nya API:er gör det enkelt att samla in omfattande prestanda- och kapacitetsmått för hela klustret. |
|
|
Scalability. Skaffa upp till 16 servrar och över 400 enheter för upp till 4 petabyte (4 000 terabyte) lagringsutrymme per kluster. Om du vill skala ut lägger du till fler enheter eller lägger till fler servrar. Lagringsdirigering registrerar automatiskt nya enheter och börjar använda dem. Lagringseffektivitet och prestanda förbättras förutsägbart i stor skala. |
När du ska använda detta
Lagringsdirigering är en kärnteknik för Azure Local och Windows Server. Det ger en idealisk nätverkslagringslösning när du vill:
- Skala upp eller skala ut nätverkets lagringskapacitet. Du kan lägga till fler enheter eller lägga till fler servrar för att utöka nätverkets lagringskapacitet, samtidigt som du håller dina data säkra och tillgängliga. Om en enhet i lagringspoolen slutar fungera eller om hela noden kopplas från förblir alla data online och tillgängliga.
- Dela samma uppsättning data från olika platser samtidigt. Lagringspoolen som Lagringsdirigering skapar ser ut och fungerar som en nätverksresurs. Dina nätverksanvändare kan komma åt lagrad data när som helst från vilken plats som helst, utan att behöva oroa dig för den fysiska platsen för deras lagrade data.
- Använd en blandning av lagringsmedier. Med Lagringsdirigering kan du kombinera olika typer av lagringsmedia i serverklustret för att skapa den programvarudefinierade lagringspoolen. Programvaran bestämmer automatiskt vilka media som ska användas baserat på data – aktiva data på snabbare media och andra sällan använda data på långsammare medier.
Implementeringsalternativ
Lagringsdirigering har stöd för följande två distributionsalternativ:
- Hyperconverged
- Converged
Note
Azure Local stöder endast hyperkonvergerad distribution.
Hyperkonvergerad distribution
I en hyperkonvergerad distribution använder du ett enda kluster för både beräkning och lagring. Alternativet för hyperkonvergerad distribution körs Hyper-V virtuella datorer eller SQL Server-databaser direkt på servrarna som tillhandahåller lagringen och lagrar deras filer på de lokala volymerna. Detta eliminerar behovet av att konfigurera filserveråtkomst och behörigheter, vilket i sin tur minskar maskinvarukostnaderna för små till medelstora företag och fjärr- eller filialkontorsdistributioner. Information om hur du distribuerar Lagringsdirigering på Windows Server finns i Distribuera Lagringsdirigering på Windows Server. Information om hur du distribuerar Lagringsdirigering som en del av Azure Local finns i Om lokal Azure-distribution.

Konvergerad distribution
I en konvergerad distribution använder du separata kluster för lagring och beräkning. Det konvergerade distributionsalternativet, även kallat "disaggregerat", lägger en skalbar filserver (SoFS) ovanpå Lagringsdirigering för att tillhandahålla nätverksansluten lagring över SMB3-filresurser. Detta gör det möjligt att skala beräkning och arbetsbelastning oberoende av lagringsklustret, vilket är viktigt för distributioner i större skala, till exempel Hyper-V IaaS (Infrastructure as a Service) för tjänstleverantörer och företag.

Hantera och övervaka
Du kan använda följande verktyg för att hantera och övervaka Lagringsdirigering:
| Name | Grafiskt eller kommandorad? | Betald eller inkluderad? |
|---|---|---|
| Administrationscenter för Windows | Graphical | Included |
| Serverhanteraren och klusterhanteraren för växling vid fel | Graphical | Included |
| Windows PowerShell | Command-line | Included |
|
System Center Hanterare för virtuella datorer (SCVMM) & Operations Manager |
Graphical | Paid |
Videos
Lagringsutrymmen Direkt översikt (5 minuter)
Lagringsutrymmen Direct på Microsoft Ignite 2018 (1 timme)
Lagringsutrymmen direkt på Microsoft Ignite 2017 (1 timme)
Lanseringsevent för Lagringsutrymmen Direct på Microsoft Ignite 2016 (1 timme)
Kundcase
Det finns över 10 000 kluster över hela världen som kör Lagringsutrymmen Direct. Organisationer av alla storlekar, från små företag som bara distribuerar två noder, till stora företag och myndigheter som distribuerar hundratals noder, är beroende av Lagringsutrymmen Direct för sina kritiska program och infrastruktur.
Besök Microsoft.com/HCI för att läsa deras berättelser.
:::image type="content" source="media/storage-spaces-direct-overview/customer-stories.png" alt-text="Rutnät med kundlogotyper." link="https://azure.microsoft.com/products/local/:::-->