Create a vector query in Azure AI Search
In Azure AI Search, if you have a vector index, this article explains how to:
This article uses REST for illustration. For code samples in other languages, see the azure-search-vector-samples GitHub repository for end-to-end solutions that include vector queries.
You can also use Search Explorer in the Azure portal.
Prerequisites
Azure AI Search, in any region and on any tier.
A vector index on Azure AI Search. Check for a
vectorSearchsection in your index to confirm a vector index.Optionally, add a vectorizer to your index for built-in text-to-vector or image-to-vector conversion during queries.
Visual Studio Code with a REST client and sample data if you want to run these examples on your own. To get started with the REST client, see Quickstart: Azure AI Search using REST.
Convert a query string input into a vector
To query a vector field, the query itself must be a vector.
One approach for converting a user's text query string into its vector representation is to call an embedding library or API in your application code. As a best practice, always use the same embedding models used to generate embeddings in the source documents. You can find code samples showing how to generate embeddings in the azure-search-vector-samples repository.
A second approach is using integrated vectorization, now generally available, to have Azure AI Search handle your query vectorization inputs and outputs.
Here's a REST API example of a query string submitted to a deployment of an Azure OpenAI embedding model:
POST https://{{openai-service-name}}.openai.azure.com/openai/deployments/{{openai-deployment-name}}/embeddings?api-version={{openai-api-version}}
Content-Type: application/json
api-key: {{admin-api-key}}
{
"input": "what azure services support generative AI'"
}
The expected response is 202 for a successful call to the deployed model.
The "embedding" field in the body of the response is the vector representation of the query string "input". For testing purposes, you would copy the value of the "embedding" array into "vectorQueries.vector" in a query request, using syntax shown in the next several sections.
The actual response for this POST call to the deployed model includes 1536 embeddings, trimmed here to just the first few vectors for readability.
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.009171937,
0.018715322,
...
-0.0016804502
]
}
],
"model": "ada",
"usage": {
"prompt_tokens": 7,
"total_tokens": 7
}
}
In this approach, your application code is responsible for connecting to a model, generating embeddings, and handling the response.
Vector query request
This section shows you the basic structure of a vector query. You can use the Azure portal, REST APIs, or the Azure SDKs to formulate a vector query. If you're migrating from 2023-07-01-Preview, there are breaking changes. See Upgrade to the latest REST API for details.
2024-07-01 is the stable REST API version for Search POST. This version supports:
vectorQueriesis the construct for vector search.vectorQueries.kindset tovectorfor a vector array, or set totextif the input is a string and you have a vectorizer.vectorQueries.vectoris query (a vector representation of text or an image).vectorQueries.weight(optional) specifies the relative weight of each vector query included in search operations (see Vector weighting).exhaustive(optional) invokes exhaustive KNN at query time, even if the field is indexed for HNSW.
In the following example, the vector is a representation of this string: "what Azure services support full text search". The query targets the contentVector field. The query returns k results. The actual vector has 1536 embeddings, so it's trimmed in this example for readability.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"weight": 0.5,
"k": 5
}
]
}
Vector query response
In Azure AI Search, query responses consist of all retrievable fields by default. However, it's common to limit search results to a subset of retrievable fields by listing them in a select statement.
In a vector query, carefully consider whether you need to vector fields in a response. Vector fields aren't human readable, so if you're pushing a response to a web page, you should choose nonvector fields that are representative of the result. For example, if the query executes against contentVector, you could return content instead.
If you do want vector fields in the result, here's an example of the response structure. contentVector is a string array of embeddings, trimmed here for brevity. The search score indicates relevance. Other nonvector fields are included for context.
{
"@odata.count": 3,
"value": [
{
"@search.score": 0.80025613,
"title": "Azure Search",
"category": "AI + Machine Learning",
"contentVector": [
-0.0018343845,
0.017952163,
0.0025753193,
...
]
},
{
"@search.score": 0.78856903,
"title": "Azure Application Insights",
"category": "Management + Governance",
"contentVector": [
-0.016821077,
0.0037742127,
0.016136652,
...
]
},
{
"@search.score": 0.78650564,
"title": "Azure Media Services",
"category": "Media",
"contentVector": [
-0.025449317,
0.0038463024,
-0.02488436,
...
]
}
]
}
Key points:
kdetermines how many nearest neighbor results are returned, in this case, three. Vector queries always returnkresults, assuming at leastkdocuments exist, even if there are documents with poor similarity, because the algorithm finds anyknearest neighbors to the query vector.The
@search.scoreis determined by the vector search algorithm.Fields in search results are either all
retrievablefields, or fields in aselectclause. During vector query execution, the match is made on vector data alone. However, a response can include anyretrievablefield in an index. Because there's no facility for decoding a vector field result, the inclusion of nonvector text fields is helpful for their human readable values.
Multiple vector fields
You can set the "vectorQueries.fields" property to multiple vector fields. The vector query executes against each vector field that you provide in the fields list. When querying multiple vector fields, make sure each one contains embeddings from the same embedding model, and that the query is also generated from the same embedding model.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector, titleVector",
"k": 5
}
]
}
Multiple vector queries
Multi-query vector search sends multiple queries across multiple vector fields in your search index. A common example of this query request is when using models such as CLIP for a multimodal vector search where the same model can vectorize image and text content.
The following query example looks for similarity in both myImageVector and myTextVector, but sends in two different query embeddings respectively, each executing in parallel. This query produces a result that's scored using Reciprocal Rank Fusion (RRF).
vectorQueriesprovides an array of vector queries.vectorcontains the image vectors and text vectors in the search index. Each instance is a separate query.fieldsspecifies which vector field to target.kis the number of nearest neighbor matches to include in results.
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"fields": "myimagevector",
"k": 5
},
{
"kind": "vector"
"vector": [
-0.002222222,
0.018708462,
-0.013770515,
. . .
],
"fields": "mytextvector",
"k": 5
}
]
}
Search results would include a combination of text and images, assuming your search index includes a field for the image file (a search index doesn't store images).
Query with integrated vectorization
This section shows a vector query that invokes the integrated vectorization that converts a text or image query into a vector. We recommend the stable 2024-07-01 REST API, Search Explorer, or newer Azure SDK packages for this feature.
A prerequisite is a search index having a vectorizer configured and assigned to a vector field. The vectorizer provides connection information to an embedding model used at query time.
Search Explorer supports integrated vectorization at query time. If your index contains vector fields and has a vectorizer, you can use the built-in text-to-vector conversion.
Sign in to the Azure portal with your Azure account, and go to your Azure AI Search service.
From the left menu, expand Search management > Indexes, and select your index. Search Explorer is the first tab on the index page.
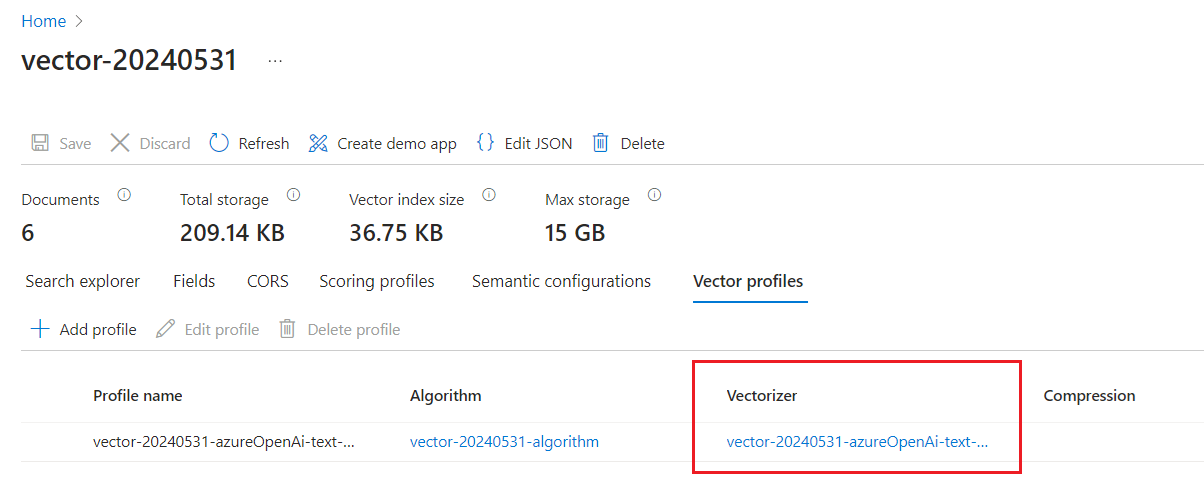
Check Vector profiles to confirm you have a vectorizer.
In Search Explorer, you can enter a text string into the default search bar in query view. The built-in vectorizer converts your string into a vector, performs the search, and returns results.
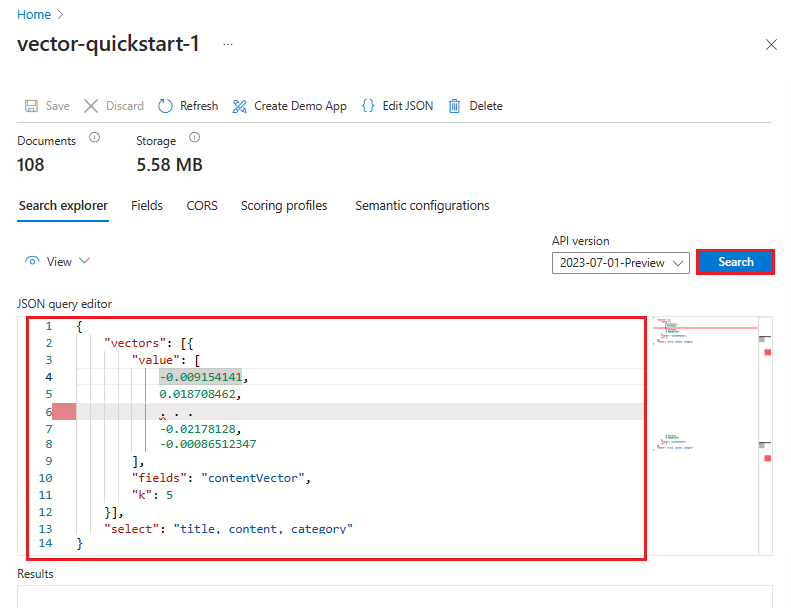
Alternatively, you can select View > JSON view to view or modify the query. If vectors are present, Search Explorer sets up a vector query automatically. You can use JSON view to select fields used in search and in the response, add filters, or construct more advanced queries like hybrid. A JSON example is provided in the REST API tab of this section.
Number of ranked results in a vector query response
A vector query specifies the k parameter, which determines how many matches are returned in the results. The search engine always returns k number of matches. If k is larger than the number of documents in the index, then the number of documents determines the upper limit of what can be returned.
If you're familiar with full text search, you know to expect zero results if the index doesn't contain a term or phrase. However, in vector search, the search operation is identifying nearest neighbors, and it will always return k results even if the nearest neighbors aren't that similar. So, it's possible to get results for nonsensical or off-topic queries, especially if you aren't using prompts to set boundaries. Less relevant results have a worse similarity score, but they're still the "nearest" vectors if there isn't anything closer. As such, a response with no meaningful results can still return k results, but each result's similarity score would be low.
A hybrid approach that includes full text search can mitigate this problem. Another mitigation is to set a minimum threshold on the search score, but only if the query is a pure single vector query. Hybrid queries aren't conducive to minimum thresholds because the RRF ranges are so much smaller and volatile.
Query parameters affecting result count include:
"k": nresults for vector-only queries"top": nresults for hybrid queries that include a "search" parameter
Both "k" and "top" are optional. Unspecified, the default number of results in a response is 50. You can set "top" and "skip" to page through more results or change the default.
Ranking algorithms used in a vector query
Ranking of results is computed by either:
- Similarity metric
- Reciprocal Rank Fusion (RRF) if there are multiple sets of search results.
Similarity metric
The similarity metric specified in the index vectorSearch section for a vector-only query. Valid values are cosine, euclidean, and dotProduct.
Azure OpenAI embedding models use cosine similarity, so if you're using Azure OpenAI embedding models, cosine is the recommended metric. Other supported ranking metrics include euclidean and dotProduct.
Using RRF
Multiple sets are created if the query targets multiple vector fields, runs multiple vector queries in parallel, or if the query is a hybrid of vector and full text search, with or without semantic ranking.
During query execution, a vector query can only target one internal vector index. So for multiple vector fields and multiple vector queries, the search engine generates multiple queries that target the respective vector indexes of each field. Output is a set of ranked results for each query, which are fused using RRF. For more information, see Relevance scoring using Reciprocal Rank Fusion (RRF).
Vector weighting
Add a weight query parameter to specify the relative weight of each vector query included in search operations. This value is used when combining the results of multiple ranking lists produced by two or more vector queries in the same request, or from the vector portion of a hybrid query.
The default is 1.0 and the value must be a positive number larger than zero.
Weights are used when calculating the reciprocal rank fusion scores of each document. The calculation is multiplier of the weight value against the rank score of the document within its respective result set.
The following example is a hybrid query with two vector query strings and one text string. Weights are assigned to the vector queries. The first query is 0.5 or half the weight, reducing its importance in the request. The second vector query is twice as important.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-07-01
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my_first_vector_field",
"k": 10,
"weight": 0.5
},
{
"kind": "vector",
"vector": [4.0, 5.0, 6.0],
"fields": "my_second_vector_field",
"k": 10,
"weight": 2.0
}
],
"search": "hello world"
}
Vector weighting applies to vectors only. The text query in this example ("hello world") has an implicit weight of 1.0 or neutral weight. However, in a hybrid query, you can increase or decrease the importance of text fields by setting maxTextRecallSize.
Set thresholds to exclude low-scoring results (preview)
Because nearest neighbor search always returns the requested k neighbors, it's possible to get multiple low scoring matches as part of meeting the k number requirement on search results. To exclude low-scoring search result, you can add a threshold query parameter that filters out results based on a minimum score. Filtering occurs before fusing results from different recall sets.
This parameter is still in preview. We recommend preview REST API version 2024-05-01-preview.
In this example, all matches that score below 0.8 are excluded from vector search results, even if the number of results fall below k.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my-cosine-field",
"threshold": {
"kind": "vectorSimilarity",
"value": 0.8
}
}
]
}
MaxTextSizeRecall for hybrid search (preview)
Vector queries are often used in hybrid constructs that include nonvector fields. If you discover that BM25-ranked results are over or under represented in a hybrid query results, you can set maxTextRecallSize to increase or decrease the BM25-ranked results provided for hybrid ranking.
You can only set this property in hybrid requests that include both "search" and "vectorQueries" components.
This parameter is still in preview. We recommend preview REST API version 2024-05-01-preview.
For more information, see Set maxTextRecallSize - Create a hybrid query.
Next steps
As a next step, review vector query code examples in Python, C# or JavaScript.