หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
สําคัญ
คุณลักษณะนี้อยู่ใน แสดงตัวอย่าง
Fabric Runtime มอบการผสานรวมที่ราบรื่นภายในระบบนิเวศ Microsoft Fabric นําเสนอสภาพแวดล้อมที่มีประสิทธิภาพสําหรับโครงการวิศวกรรมข้อมูลและวิทยาศาสตร์ข้อมูลที่ขับเคลื่อนโดย Apache Spark
บทความนี้แนะนํา Fabric Runtime 2.0 Public Preview ซึ่งเป็นรันไทม์ล่าสุดที่ออกแบบมาสําหรับการคํานวณข้อมูลขนาดใหญ่ใน Microsoft Fabric โดยเน้นย้ําถึงคุณสมบัติและส่วนประกอบหลักที่ทําให้รุ่นนี้เป็นก้าวสําคัญสําหรับการวิเคราะห์ที่ปรับขนาดได้และปริมาณงานขั้นสูง
Fabric Runtime 2.0 รวมส่วนประกอบและการอัปเกรดต่อไปนี้ที่ออกแบบมาเพื่อปรับปรุงความสามารถในการประมวลผลข้อมูลของคุณ:
- อาปาเช่ สปาร์ค 4.0
- ระบบปฏิบัติการ: Azure Linux 3.0 (Mariner 3.0)
- ชวา: 21
- สกาล่า: 2.13
- หลาม: 3.12
- ทะเลสาบเดลต้า: 4.0
- อาร์: 4.5.2
เคล็ดลับ
Fabric Runtime 2.0 รองรับ Native Execution Engine ซึ่งสามารถเพิ่มประสิทธิภาพได้อย่างมีนัยสําคัญโดยไม่มีค่าใช้จ่ายเพิ่มเติม คุณสามารถเปิดใช้งานกลไกการดําเนินการดั้งเดิมในระดับสภาพแวดล้อม เพื่อให้งานและสมุดบันทึกทั้งหมดสืบทอดความสามารถด้านประสิทธิภาพที่ได้รับการปรับปรุงโดยอัตโนมัติ
เปิดใช้งานรันไทม์ 2.0
คุณสามารถเปิดใช้งานรันไทม์ 2.0 ได้ที่ระดับพื้นที่ทํางานหรือระดับรายการสภาพแวดล้อม ใช้การตั้งค่าพื้นที่ทํางานเพื่อใช้ Runtime 2.0 เป็นค่าเริ่มต้นสําหรับปริมาณงาน Spark ทั้งหมดในพื้นที่ทํางานของคุณ อีกวิธีหนึ่งคือ สร้างรายการสภาพแวดล้อมที่มี Runtime 2.0 เพื่อใช้กับสมุดบันทึกเฉพาะหรือข้อกําหนดงาน Spark ซึ่งจะแทนที่ค่าเริ่มต้นของพื้นที่ทํางาน
เปิดใช้งานรันไทม์ 2.0 ในการตั้งค่าพื้นที่ทํางาน
เมื่อต้องการตั้งค่ารันไทม์ 2.0 เป็นค่าเริ่มต้นสําหรับพื้นที่ทํางานทั้งหมดของคุณ:
นําทางไปยังหน้า การตั้งค่าพื้นที่ทํางาน ภายในพื้นที่ทํางาน Fabric ของคุณ
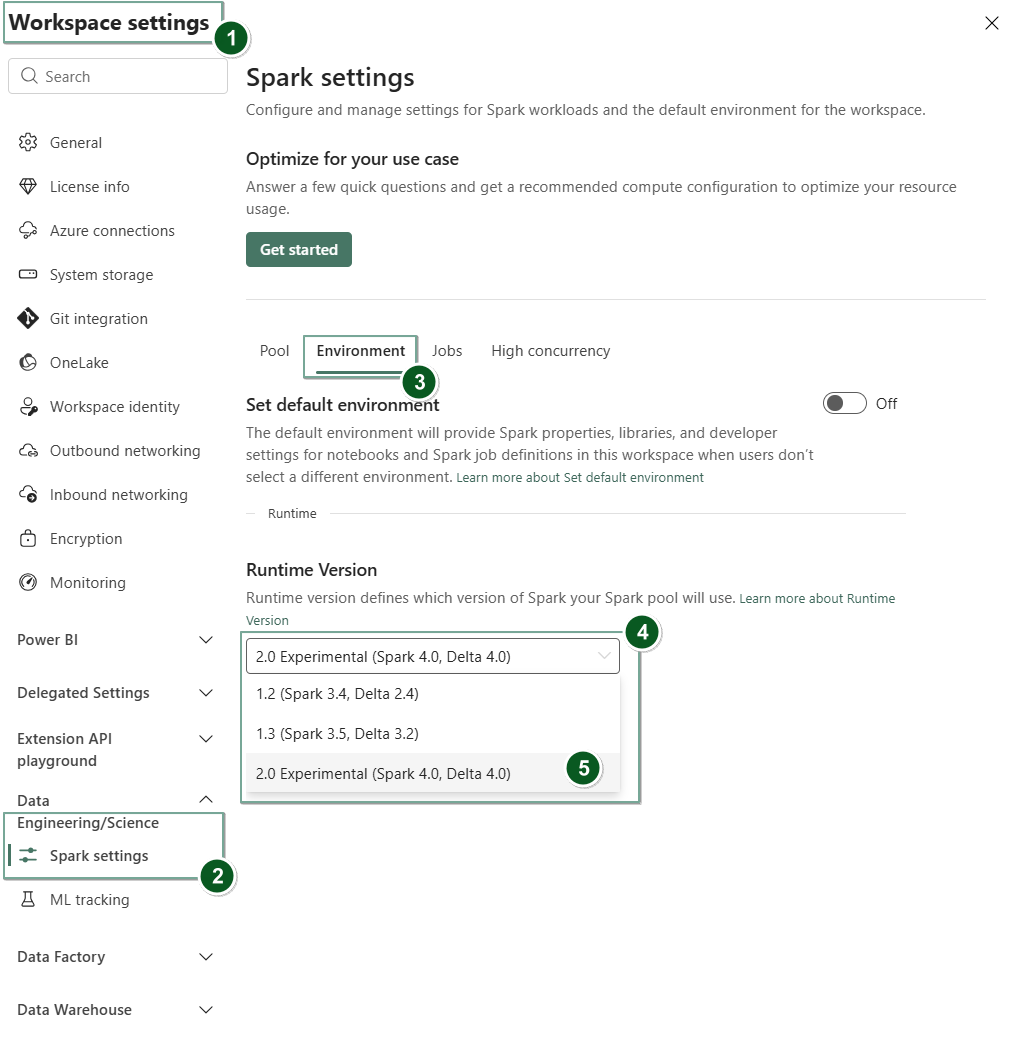
เลือกแท็บ วิศวกรรมข้อมูล/วิทยาศาสตร์ แล้วเลือก การตั้งค่า Spark
เลือกแท็บ สภาพแวดล้อม
ภายใต้ดรอปดาวน์ เวอร์ชันรันไทม์ ให้เลือก 2.0 การแสดงตัวอย่างสาธารณะ (Spark 4.0, Delta 4.0) และบันทึกการเปลี่ยนแปลงของคุณ
รันไทม์ 2.0 ถูกตั้งค่าเป็นรันไทม์เริ่มต้นสําหรับพื้นที่ทํางานของคุณ

เปิดใช้งานรันไทม์ 2.0 ในรายการสภาพแวดล้อม
หากต้องการใช้ Runtime 2.0 กับสมุดบันทึกเฉพาะหรือข้อกําหนดงาน Spark:
สร้างรายการสภาพแวดล้อมใหม่หรือเปิดรายการที่มีอยู่
ภายใต้ดรอปดาวน์ รันไทม์ ให้เลือก 2.0 การแสดงตัวอย่างสาธารณะ (Spark 4.0, Delta 4.0)
SaveและPublishการเปลี่ยนแปลงของคุณ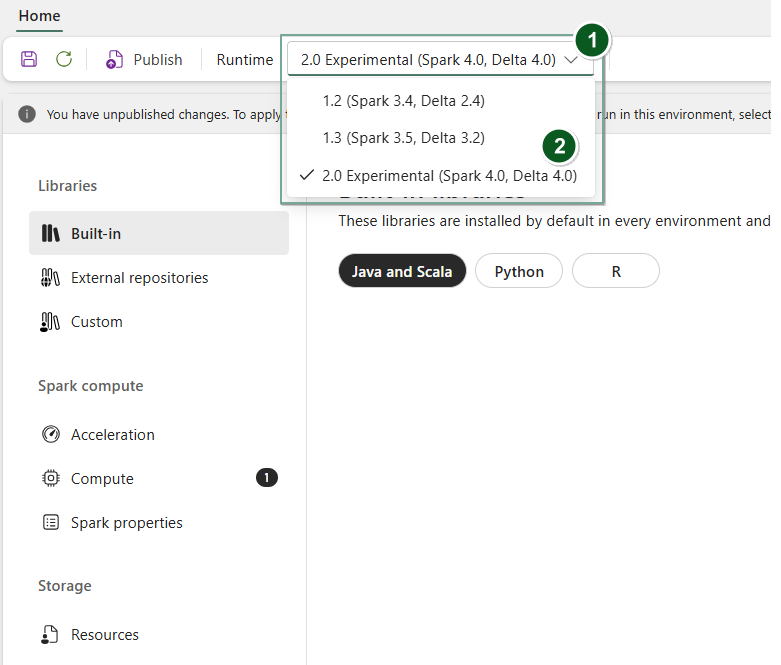
ถัดไป คุณสามารถใช้รายการสภาพแวดล้อมนี้กับ หรือ ของคุณ
NotebookSpark Job Definition

ตอนนี้คุณสามารถเริ่มทดลองกับการปรับปรุงและฟังก์ชันใหม่ล่าสุดที่นํามาใช้ใน Fabric Runtime 2.0 (Spark 4.0 และ Delta Lake 4.0)
เคล็ดลับ
การเริ่มต้นเซสชัน Spark เริ่มต้นสําหรับ Runtime 2.0 อาจใช้เวลาสักครู่ในระหว่างการแสดงตัวอย่างสาธารณะ หากต้องการลดความล่าช้าในการสตาร์ทเย็น ให้ใช้ Live Pools แบบกําหนดเอง (พรีวิว) เพื่ออุ่นเครื่องพูล Spark ล่วงหน้า หรือกําหนดค่าโปรไฟล์ทรัพยากรเพื่อจัดสรรทรัพยากรล่วงหน้า
Note
โพรโทคอล WASB สําหรับบัญชี Azure Storage สําหรับวัตถุประสงค์ทั่วไป v2 (GPv2) เลิกใช้แล้ว คุณควรใช้โปรโตคอล ABFS ล่าสุดแทนสําหรับการอ่านและเขียนไปยังบัญชีที่เก็บข้อมูล GPv2
การแสดงตัวอย่างสาธารณะ
ขั้นตอนการแสดงตัวอย่างสาธารณะของ Fabric Runtime 2.0 ช่วยให้คุณเข้าถึงคุณลักษณะและ API ใหม่ๆ จากทั้ง Spark 4.0 และ Delta Lake 4.0 การแสดงตัวอย่างช่วยให้คุณใช้การปรับปรุงล่าสุดที่ใช้ Spark และ Delta ได้ทันที รวมทั้งรับประกันความพร้อมและการเปลี่ยนแปลงที่ราบรื่นสําหรับการเปลี่ยนแปลงที่ได้รับการปรับปรุงและปรับปรุง เช่น Java, Scala และ Python เวอร์ชันที่ใหม่กว่า
เคล็ดลับ
สําหรับข้อมูลล่าสุด รายการการเปลี่ยนแปลงโดยละเอียด และบันทึกย่อประจํารุ่นเฉพาะสําหรับ Fabric runtimes ตรวจสอบและสมัครใช้งาน การเผยแพร่และการอัปเดต Spark Runtimes
จุดเด่นหลัก
การปรับปรุงกลไกประสิทธิภาพและการดําเนินการ
Fabric Runtime 2.0 มี Native Execution Engine ซึ่งให้การปรับปรุงประสิทธิภาพที่สําคัญเหนือ Spark แบบโอเพนซอร์ส กลไกจัดการใช้การประมวลผลแบบเวกเตอร์เพื่อเร่งการสืบค้น Spark บนโครงสร้างพื้นฐานเลคเฮาส์โดยไม่ต้องเปลี่ยนโค้ด
คุณสมบัติด้านประสิทธิภาพที่สําคัญใน Runtime 2.0:
- เร็วขึ้นสูงสุดหกเท่า: เกณฑ์มาตรฐานแสดงประสิทธิภาพที่เร็วขึ้นถึงหกเท่าเมื่อเทียบกับ Spark แบบโอเพนซอร์สในปริมาณงาน TPC-DS
- การแยกวิเคราะห์ CSV แบบเวกเตอร์: เอ็นจิ้นการดําเนินการแบบเนทีฟประกอบด้วยตัวแยกวิเคราะห์ CSV แบบเวกเตอร์ที่เร่งการนําเข้า CSV และปริมาณงานการสืบค้น มีการวางแผนการแยกวิเคราะห์ JSON แบบเวกเตอร์และการรองรับการสตรีมที่มีโครงสร้างของ Spark สําหรับการอัปเดตในอนาคต
หากต้องการเปิดใช้งานกลไกการดําเนินการแบบเนทีฟ โปรดดู กลไกการดําเนินการแบบเนทีฟสําหรับวิศวกรรมข้อมูล Fabric
อาปาเช่ สปาร์ค 4.0
Apache Spark 4.0 ถือเป็นก้าวสําคัญในการเปิดตัวครั้งแรกในซีรีส์ 4.x ซึ่งรวบรวมความพยายามร่วมกันของชุมชนโอเพ่นซอร์สที่มีชีวิตชีวา
ในเวอร์ชันนี้ Spark SQL ได้รับการเสริมสร้างอย่างมีนัยสําคัญด้วยคุณสมบัติใหม่ที่ทรงพลังซึ่งออกแบบมาเพื่อเพิ่มการแสดงออกและความเก่งกาจสําหรับปริมาณงาน SQL เช่น การสนับสนุนประเภทข้อมูล VARIANT, ฟังก์ชันที่ผู้ใช้กําหนดโดย SQL, ตัวแปรเซสชัน, ไวยากรณ์ไปป์ และการเปรียบเทียบสตริง PySpark เห็นความทุ่มเทอย่างต่อเนื่องทั้งในด้านการทํางานและประสบการณ์โดยรวมของนักพัฒนา โดยนํา API การพล็อตดั้งเดิม API แหล่งข้อมูล Python ใหม่ รองรับ Python UDTF และการสร้างโปรไฟล์แบบรวมสําหรับ PySpark UDF ควบคู่ไปกับการปรับปรุงอื่นๆ อีกมากมาย การสตรีมแบบมีโครงสร้างพัฒนาขึ้นด้วยการเพิ่มคีย์ที่ให้การควบคุมที่ดีขึ้นและง่ายต่อการดีบัก โดยเฉพาะอย่างยิ่งการแนะนํา Arbitrary State API v2 เพื่อการจัดการสถานะที่ยืดหยุ่นยิ่งขึ้น และแหล่งข้อมูลของรัฐเพื่อการดีบักที่ง่ายขึ้น
คุณสามารถตรวจสอบรายการทั้งหมดและการเปลี่ยนแปลงโดยละเอียดได้ที่นี่: https://spark.apache.org/releases/spark-release-4-0-0.html
Note
ใน Spark 4.0 SparkR ถูกเลิกใช้และอาจถูกลบออกในเวอร์ชันในอนาคต
เดลต้าเลค 4.0
Delta Lake 4.0 แสดงถึงความมุ่งมั่นร่วมกันในการทําให้ Delta Lake ทํางานร่วมกันได้ในทุกรูปแบบ ทํางานได้ง่ายขึ้น และมีประสิทธิภาพมากขึ้น Delta 4.0 เป็นการเปิดตัวครั้งสําคัญที่อัดแน่นไปด้วยคุณสมบัติใหม่ที่ทรงพลัง การเพิ่มประสิทธิภาพ และการปรับปรุงพื้นฐานสําหรับอนาคตของเลคเฮาส์ข้อมูลแบบเปิด
คุณสามารถตรวจสอบรายการทั้งหมดและการเปลี่ยนแปลงโดยละเอียดที่แนะนําใน Delta Lake 3.3 และ 4.0 ได้ที่นี่: https://github.com/delta-io/delta/releases/tag/v3.3.0. https://github.com/delta-io/delta/releases/tag/v4.0.0
เค้าโครงข้อมูลและการเพิ่มประสิทธิภาพ
รันไทม์ 2.0 รองรับเค้าโครงข้อมูลและคุณสมบัติการเพิ่มประสิทธิภาพสําหรับตารางเดลต้า:
- การเรียงลําดับ Z: จัดระเบียบข้อมูลภายในไฟล์ตารางเดลต้าตามคอลัมน์ที่ระบุเพื่อปรับปรุงประสิทธิภาพการสืบค้นสําหรับการค้นหาที่กรอง
- Liquid Clustering: วิธีการจัดกลุ่มที่ยืดหยุ่นซึ่งปรับเค้าโครงข้อมูลให้เหมาะสมโดยอัตโนมัติโดยไม่ต้องบํารุงรักษาด้วยตนเอง
- การโหลดสแนปช็อตเดลต้าแบบขนาน: เอ็นจิ้นการดําเนินการดั้งเดิมจะโหลดสแนปช็อตตารางเดลต้าแบบขนาน ซึ่งช่วยลดเวลาเริ่มต้นคิวรีสําหรับตารางขนาดใหญ่
สําคัญ
คุณลักษณะเฉพาะของ Delta Lake 4.0 เป็นการทดลองและใช้งานได้กับประสบการณ์ Spark เท่านั้น เช่น สมุดบันทึกและคําจํากัดความของงาน Spark หากคุณต้องการใช้ตาราง Delta Lake เดียวกันในปริมาณงาน Microsoft Fabric หลายรายการ อย่าเปิดใช้งานคุณลักษณะเหล่านั้น หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับเวอร์ชันและคุณลักษณะของโปรโตคอลที่เข้ากันได้กับประสบการณ์การใช้งาน Microsoft Fabric ทั้งหมด โปรดอ่าน การทํางานร่วมกันของรูปแบบตาราง Delta Lake
การจัดการการประมวลผลใน Runtime 2.0
รันไทม์ 2.0 รองรับคุณสมบัติการจัดการการประมวลผลต่อไปนี้:
- โปรไฟล์ทรัพยากร: กําหนดค่าการจัดสรรทรัพยากรที่กําหนดไว้ล่วงหน้าสําหรับเซสชัน Spark เพื่อให้ตรงกับความต้องการของปริมาณงานและควบคุมต้นทุน
- พูลสดแบบกําหนดเอง (พรีวิว): สร้างพูล Spark เฉพาะที่อุ่นเครื่องไว้ล่วงหน้า ซึ่งช่วยลดเวลาเริ่มต้นเซสชัน พูลสดแบบกําหนดเองพร้อมใช้งานในการแสดงตัวอย่างสําหรับปริมาณงานรันไทม์ 2.0
ข้อจํากัดและหมายเหตุ
- คุณลักษณะเฉพาะของ Delta Lake 4.0 เป็นการทดลองและใช้ได้กับประสบการณ์ Spark เท่านั้น เช่น สมุดบันทึกและข้อกําหนดงาน Spark หากคุณต้องการใช้ตาราง Delta Lake เดียวกันในปริมาณงาน Fabric หลายรายการ อย่าเปิดใช้งานคุณลักษณะเหล่านั้น สําหรับข้อมูลเพิ่มเติม โปรดดู ความสามารถในการทํางานร่วมกันของรูปแบบตาราง Delta Lake
- รันไทม์ 2.0 อยู่ในการแสดงตัวอย่างสาธารณะ ฟีเจอร์และ API บางอย่างอาจเปลี่ยนแปลงได้ก่อนการวางจําหน่ายทั่วไป
- ส่วนขยาย VS Code สําหรับ Fabric Spark รองรับรันไทม์ 2.0 สําหรับการพัฒนาข้อกําหนดงานของโน้ตบุ๊กและ Spark
เนื้อหาที่เกี่ยวข้อง
- รันไทม์ Apache Spark ใน Fabric - ภาพรวม การกําหนดเวอร์ชัน และการสนับสนุนรันไทม์หลายรายการ
- คู่มือการโยกย้าย Spark Core
- คู่มือการโยกย้าย SQL, ชุดข้อมูล และ DataFrame
- คู่มือการโยกย้ายแบบสตรีมมิ่งที่มีโครงสร้าง
- คู่มือการโยกย้าย MLlib (Machine Learning)
- คู่มือการโยกย้าย PySpark (Python บน Spark)
- คู่มือการโยกย้าย SparkR (R บน Spark)