หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
ในบทช่วยสอนนี้ คุณจะใช้โน้ตบุ๊กที่มี รันไทม์ Spark เพื่อแปลงและเตรียมข้อมูลดิบในเลคเฮ้าส์ของคุณ
ข้อกำหนดเบื้องต้น
ก่อนที่คุณจะเริ่มคุณต้องทําบทช่วยสอนก่อนหน้านี้ในชุดนี้ให้เสร็จสมบูรณ์:
- สร้างเลคเฮ้าส์
- นําเข้าข้อมูลลงในเลคเฮ้าส์
- ตรวจสอบให้แน่ใจว่าได้เปิดใช้งาน สคีมาเลคเฮาส์ ในเลคเฮาส์ของคุณ
เตรียมข้อมูล
จากขั้นตอนบทแนะนําการใช้งานก่อนหน้านี้ คุณจะมีข้อมูลดิบที่นําเข้าจากแหล่งที่มาไปยังส่วน ไฟล์ ของเลคเฮาส์ ในตอนนี้ คุณสามารถแปลงข้อมูลนั้นและเตรียมข้อมูลสําหรับการสร้างตาราง Delta ได้
ดาวน์โหลดสมุดบันทึกจากโฟลเดอร์โค้ดต้นฉบับของบทช่วยสอนของ Lakehouse
ในเบราว์เซอร์ของคุณ ให้ไปที่พื้นที่ทํางาน Fabric ของคุณในพอร์ทัล Fabric
เลือก>นําเข้าสมุดบันทึกจาก>คอมพิวเตอร์เครื่องนี้
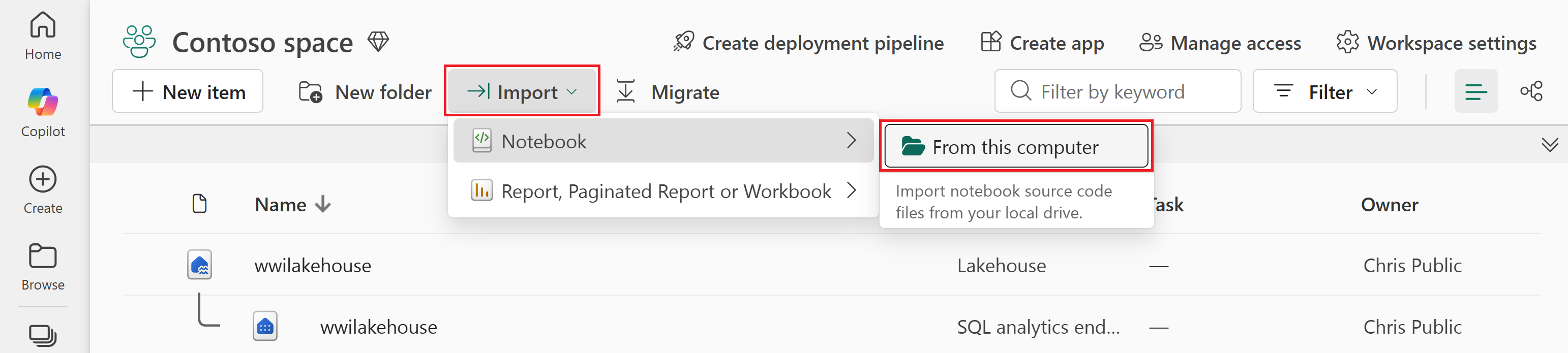
เลือก อัปโหลด จากบานหน้าต่าง สถานะ การนําเข้า ที่เปิดอยู่ทางด้านขวาของหน้าจอ
เลือกเฉพาะสมุดบันทึกที่ตรงกับภาษาการเขียนโค้ดที่คุณต้องการ
-
ไพสปาร์ค (
Prepare and transform data - PySpark.ipynb) -
สปาร์ค SQL (
Prepare and transform data - Spark SQL.ipynb)
-
ไพสปาร์ค (
เลือก เปิด การแจ้งเตือนที่ระบุสถานะของการนําเข้าจะปรากฏที่มุมบนขวาของหน้าต่างเบราว์เซอร์
หลังจากนําเข้าสําเร็จ ให้ไปที่มุมมองรายการของพื้นที่ทํางานเพื่อตรวจสอบสมุดบันทึกที่นําเข้า
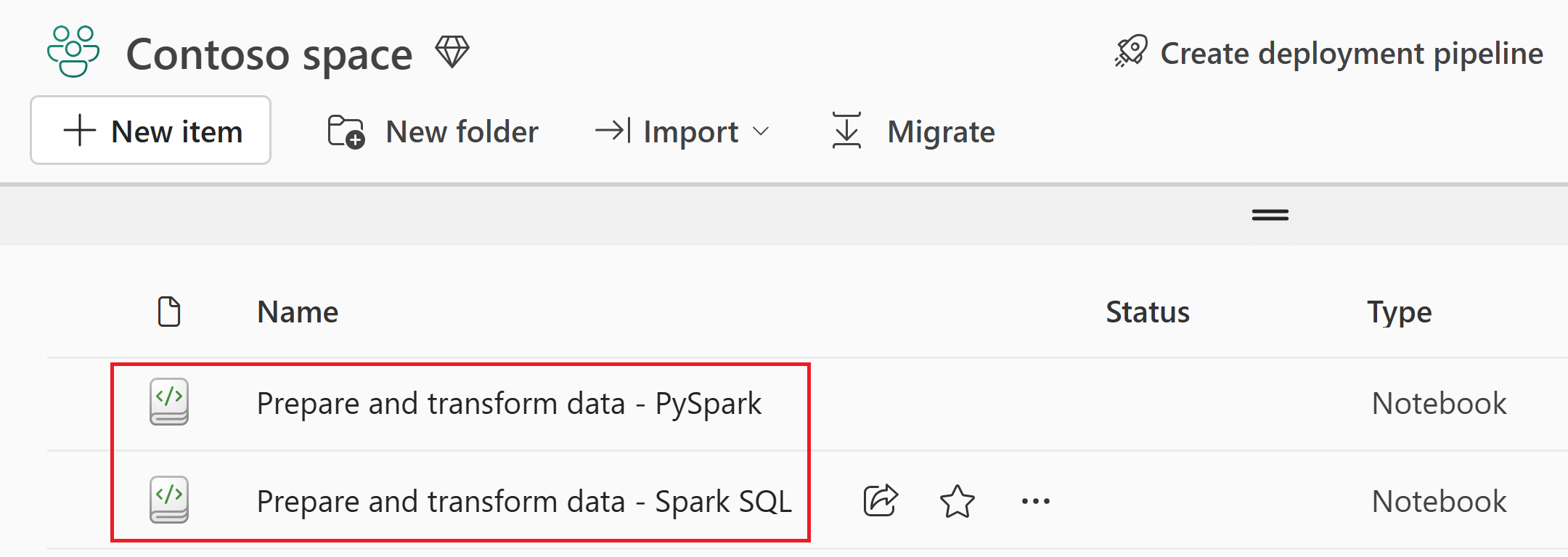
เลือกเลคเฮาส์ wwilakehouse เพื่อเปิด เพื่อให้สมุดบันทึกที่คุณเปิดถัดไปเชื่อมโยงกับสมุดบันทึกนั้น
จากเมนูการนําทางด้านบน ให้เลือก เปิดสมุด>บันทึกสมุดบันทึกที่มีอยู่
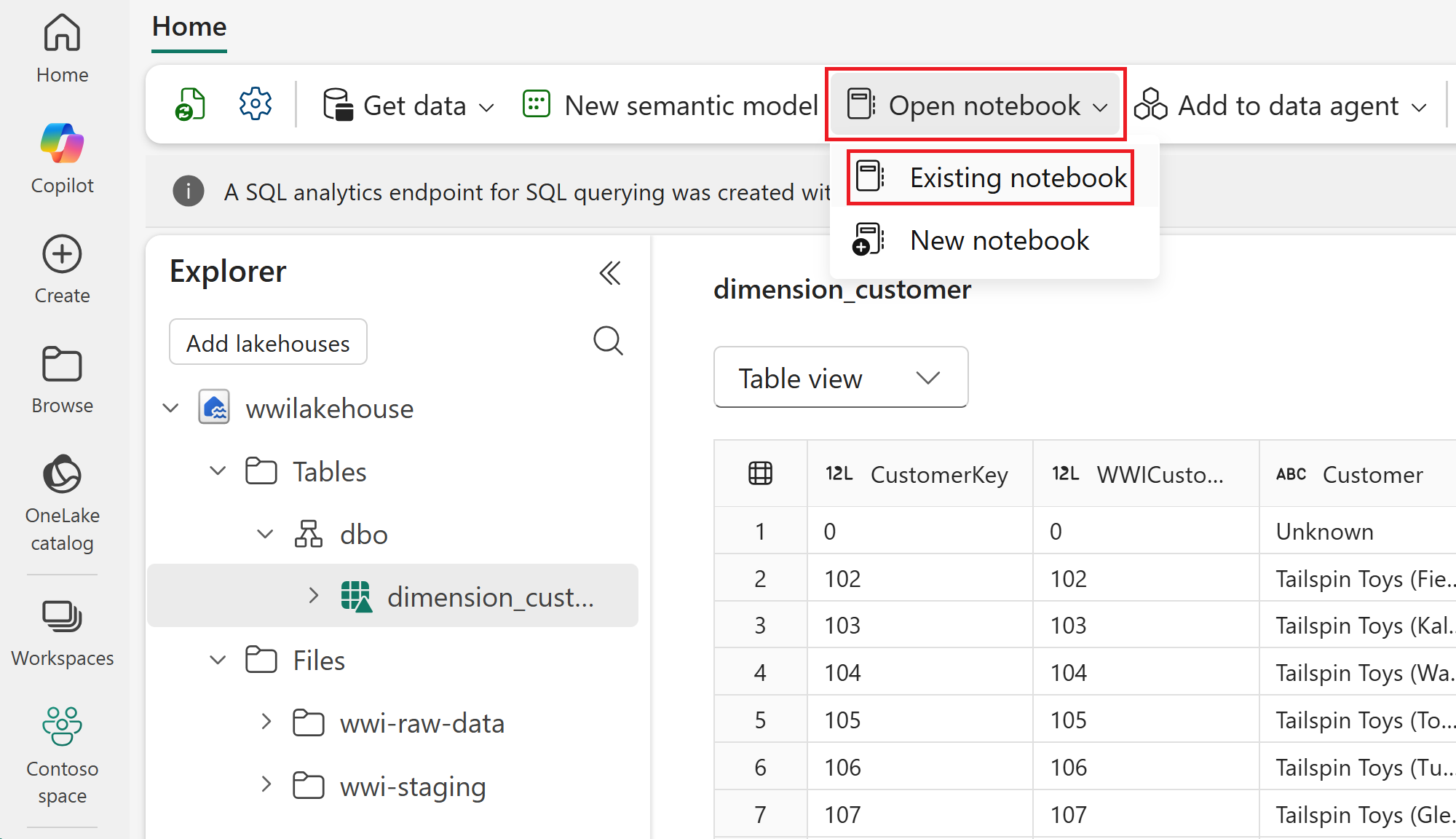
เลือกสมุดบันทึกที่นําเข้าของคุณสําหรับ PySpark หรือ Spark SQL แล้วเลือก เปิด สมุดบันทึกเชื่อมโยงกับเลคเฮาส์ที่เปิดอยู่แล้ว ดังที่แสดงใน เลคเฮาส์ Explorer



ตอนนี้คุณพร้อมที่จะเรียกใช้เซลล์สมุดบันทึกที่สร้างและแปลงตารางเดลต้าของคุณแล้ว
ในส่วนต่อไปนี้ ให้เรียกใช้เซลล์สมุดบันทึกตามลําดับ หากต้องการเรียกใช้เซลล์ ให้เลือกไอคอน เรียกใช้ ที่ปรากฏทางด้านซ้ายของเซลล์เมื่อวางเมาส์เหนือ คุณยังสามารถเลือก เรียกใช้ทั้งหมด บน Ribbon ด้านบน (หน้าแรก) เพื่อเรียกใช้เซลล์ทั้งหมดตามลําดับ
สำคัญ
บทช่วยสอนนี้จําเป็นต้องเปิดใช้งาน Schema เลคเฮาส์ ถ้าไม่ได้เปิดใช้งาน Schema โค้ดในบทช่วยสอนนี้จะไม่ทํางานตามที่ตั้งใจไว้
ในสมุดบันทึกที่นําเข้า คุณจะเห็นทั้งส่วนเส้นทาง 1 และเส้นทาง 2 สําหรับบทช่วยสอนนี้ ให้ใช้ เส้นทาง 1 (เปิดใช้งาน Schema Lakehouse) และละเว้น Path 2 (ไม่ได้เปิดใช้งาน Schema Lakehouse)
สร้างตารางเดลต้า
ในส่วนนี้ คุณเรียกใช้เซลล์สมุดบันทึกเพื่อสร้างตารางเดลต้าจากข้อมูลดิบ
ตารางเป็นไปตามสคีมารูปดาว ซึ่งเป็นรูปแบบทั่วไปสําหรับการจัดระเบียบข้อมูลการวิเคราะห์:
-
ตารางข้อเท็จจริง (
fact_sale) ประกอบด้วยเหตุการณ์ที่วัดได้ของธุรกิจ — ในกรณีนี้ ธุรกรรมการขายแต่ละรายการที่มีปริมาณ ราคา และกําไร -
ตารางมิติ (
dimension_city,dimension_customer,dimension_date, ,dimension_employee)dimension_stock_itemประกอบด้วยแอตทริบิวต์เชิงพรรณนาที่ให้บริบทของข้อเท็จจริง เช่น สถานที่ที่การขายเกิดขึ้น ใครเป็นผู้ทํา และเมื่อใด
ในหน้าบทช่วยสอนนี้ ให้เลือกแท็บที่ตรงกับสมุดบันทึกที่คุณนําเข้า และใช้แท็บเดียวกันนั้นต่อไปสําหรับทุกขั้นตอน แท็บจะอยู่ในบทความนี้ ไม่ใช่ในสมุดบันทึก
เซลล์ 1 - การกําหนดค่าเซสชัน Spark เซลล์นี้เปิดใช้งานคุณสมบัติ Fabric สองอย่างที่ปรับวิธีการเขียนและอ่านข้อมูลในเซลล์ที่ตามมาให้เหมาะสม V-order ปรับเค้าโครงไฟล์ปาร์เก้ให้เหมาะสมเพื่อการอ่านที่เร็วขึ้นและการบีบอัดที่ดีขึ้น เพิ่มประสิทธิภาพการเขียน จะช่วยลดจํานวนไฟล์ที่เขียนและเพิ่มขนาดไฟล์แต่ละไฟล์
เรียกใช้เซลล์นี้ และรอให้เซลล์เสร็จสิ้นก่อนที่จะไปยังขั้นตอนถัดไป
spark.conf.set("spark.sql.parquet.vorder.enabled", "true") spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", "true") spark.conf.set("spark.microsoft.delta.optimizeWrite.binSize", "1073741824")เซลล์ 2 - ข้อเท็จจริง - การขาย เซลล์นี้อ่านข้อมูลปาร์เก้ดิบจาก
Files/wwi-raw-data/full/fact_sale_1y_fullเพิ่มคอลัมน์ส่วนวันที่ (ปีไตรมาส และเดือน) และเขียนfact_saleเป็นตารางเดลต้าที่แบ่งตามปีและไตรมาสเรียกใช้เซลล์นี้ และรอให้เซลล์เสร็จสิ้นก่อนที่จะไปยังขั้นตอนถัดไป
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/dbo/" + table_name)เซลล์ 3 - ขนาด เซลล์นี้อ่านชุดข้อมูลปาร์เก้ห้ามิติและเขียนเป็นตารางเดลต้า (
dimension_city,dimension_customer,dimension_date,dimension_employeeและdimension_stock_item) ภายใต้Tables/dbo/....เรียกใช้เซลล์นี้ และรอให้เซลล์เสร็จสิ้นก่อนที่จะไปยังขั้นตอนถัดไป
def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/dbo/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)หากต้องการตรวจสอบตารางที่สร้างขึ้น ให้คลิกขวาที่เลคเฮาส์ wwilakehouse ในตัวสํารวจ แล้วเลือก รีเฟรช ตารางจะปรากฏขึ้น

แปลงข้อมูลสําหรับการรวมธุรกิจ
ในส่วนนี้ คุณจะดําเนินการต่อในสมุดบันทึกเดียวกันและเรียกใช้เซลล์ถัดไปเพื่อสร้างตารางรวมจากตารางเดลต้าที่คุณสร้างขึ้นในส่วนก่อนหน้า
ตรวจสอบให้แน่ใจว่าโน้ตบุ๊กยังคงเชื่อมโยงกับ wwilakehouse
เซลล์ 4 - โหลดตารางต้นทางสําหรับการแปลง (PySpark เท่านั้น) ถ้าคุณกําลังใช้สมุดบันทึก PySpark ให้เรียกใช้เซลล์นี้เพื่อโหลดตารางเดลต้าลงใน DataFrames สําหรับขั้นตอนการรวมที่ตามมา
เรียกใช้เซลล์นี้ และรอให้เซลล์เสร็จสิ้นก่อนที่จะไปยังขั้นตอนถัดไป
df_fact_sale = spark.read.format("delta").load("Tables/dbo/fact_sale") df_dimension_date = spark.read.format("delta").load("Tables/dbo/dimension_date") df_dimension_city = spark.read.format("delta").load("Tables/dbo/dimension_city")เซลล์ 5 - สร้าง
aggregate_sale_by_date_cityเซลล์นี้จะรวมข้อมูลยอดขาย วันที่ และเมือง จากนั้นสร้างตารางรวมระดับเมืองเรียกใช้เซลล์นี้ และรอให้เซลล์เสร็จสิ้นก่อนที่จะไปยังขั้นตอนถัดไป
sale_by_date_city = ( df_fact_sale.alias("sale") .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory") .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax") .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount") .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax") .withColumnRenamed("sum(Profit)", "SumOfProfit") .orderBy("date.Date", "city.StateProvince", "city.City") ) sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_city")เซลล์ 6 - สร้าง
aggregate_sale_by_date_employeeเซลล์นี้จะรวมข้อมูลการขาย วันที่ และพนักงาน จากนั้นสร้างตารางรวมระดับพนักงานเรียกใช้เซลล์นี้ และรอให้เซลล์เสร็จสิ้นก่อนที่จะไปยังขั้นตอนถัดไป
spark.sql(""" CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year , DE.PreferredName, DE.Employee , SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax , SUM(FS.TaxAmount) SumOfTaxAmount , SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax , SUM(FS.Profit) SumOfProfit FROM delta.`Tables/dbo/fact_sale` FS INNER JOIN delta.`Tables/dbo/dimension_date` DD ON FS.InvoiceDateKey = DD.Date INNER JOIN delta.`Tables/dbo/dimension_employee` DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASC """) sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_employee")หากต้องการตรวจสอบตารางที่สร้างขึ้น ให้คลิกขวาที่เลคเฮาส์ wwilakehouse ในตัวสํารวจ แล้วเลือก รีเฟรช ตารางรวมปรากฏขึ้น

บทช่วยสอนนี้เขียนข้อมูลเป็นไฟล์เดลต้าเลค Fabric จะค้นหาและลงทะเบียนตารางเหล่านี้ใน metastore โดยอัตโนมัติ ดังนั้นคุณจึงไม่จําเป็นต้องเรียกใช้คําสั่งแยกต่างหากCREATE TABLE