หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
บทช่วยสอนนี้แสดงตัวอย่างแบบ end-to-end ของเวิร์กโฟลว์ Synapse Data Science ใน Microsoft Fabric ในสถานการณ์นี้ เราสร้างแบบจําลองการตรวจจับการฉ้อโกงใน R ด้วยอัลกอริทึมการเรียนรู้ของเครื่องที่ได้รับการฝึกฝนในข้อมูลในอดีต จากนั้นเราใช้แบบจําลองเพื่อตรวจสอบธุรกรรมการฉ้อโกงในอนาคต
บทช่วยสอนนี้ครอบคลุมขั้นตอนเหล่านี้:
- ติดตั้งไลบรารีแบบกําหนดเอง
- โหลดข้อมูล
- ทําความเข้าใจและประมวลผลข้อมูลด้วยการวิเคราะห์ข้อมูลเชิงสํารวจ และแสดงการใช้คุณลักษณะ Fabric Data Wrangler
- ฝึกแบบจําลองการเรียนรู้ของเครื่องด้วย LightGBM
- ใช้แบบจําลองการเรียนรู้ของเครื่องสําหรับการให้คะแนนและการคาดการณ์
ข้อกําหนดเบื้องต้น
รับ การสมัครใช้งาน Microsoft Fabric หรือลงทะเบียนสําหรับ Microsoft Fabric รุ่นทดลองใช้ฟรี
ลงชื่อเข้าใช้ Microsoft Fabric
ใช้ตัวสลับประสบการณ์การใช้งานที่ด้านล่างซ้ายของหน้าหลักของคุณเพื่อเปลี่ยนเป็น Fabric
- หากจําเป็น ให้สร้าง Microsoft Fabric lakehouse ตามที่อธิบายไว้ใน สร้างเลคเฮ้าส์ใน Microsoft Fabric
ติดตามในสมุดบันทึก
คุณสามารถเลือกหนึ่งในตัวเลือกเหล่านี้เพื่อติดตามในสมุดบันทึกได้:
- เปิดและเรียกใช้สมุดบันทึกที่มีอยู่ภายในในประสบการณ์วิทยาศาสตร์ข้อมูล Synapse
- อัปโหลดสมุดบันทึกของคุณจาก GitHub ไปยังประสบการณ์วิทยาศาสตร์ข้อมูล Synapse
เปิดสมุดบันทึกที่มีอยู่แล้วภายใน
ตัวอย่างการตรวจหา ฉ้อฉล สมุดบันทึกมาพร้อมกับบทช่วยสอนนี้
เมื่อต้องการเปิดสมุดบันทึกตัวอย่างสําหรับบทช่วยสอนนี้ ให้ทําตามคําแนะนําใน เตรียมระบบของคุณสําหรับบทช่วยสอนวิทยาศาสตร์ข้อมูล
ตรวจสอบให้แน่ใจว่า แนบ lakehouse เข้ากับ สมุดบันทึกก่อนที่คุณจะเริ่มเรียกใช้โค้ด
นําเข้าสมุดบันทึกจาก GitHub
AIsample - R Detection.ipynb notebook มาพร้อมกับบทช่วยสอนนี้
เมื่อต้องการเปิดสมุดบันทึกที่มาพร้อมกับบทช่วยสอนนี้ ให้ทําตามคําแนะนําใน เตรียมระบบของคุณสําหรับบทช่วยสอนวิทยาศาสตร์ข้อมูล การนําเข้าสมุดบันทึกไปยังพื้นที่ทํางานของคุณ
ถ้าคุณต้องการคัดลอกและวางโค้ดจากหน้านี้ สร้างสมุดบันทึกใหม่
ตรวจสอบให้แน่ใจว่า แนบ lakehouse เข้ากับ สมุดบันทึกก่อนที่คุณจะเริ่มเรียกใช้โค้ด
ขั้นตอนที่ 1: ติดตั้งไลบรารีแบบกําหนดเอง
สําหรับการพัฒนาแบบจําลองการเรียนรู้ของเครื่องหรือการวิเคราะห์ข้อมูลเฉพาะกิจ คุณอาจจําเป็นต้องติดตั้งไลบรารีแบบกําหนดเองสําหรับเซสชัน Apache Spark ของคุณได้อย่างรวดเร็ว คุณมีสองตัวเลือกในการติดตั้งไลบรารี
- ใช้ทรัพยากรการติดตั้งแบบอินไลน์ เช่น
install.packagesและdevtools::install_versionเพื่อติดตั้งในสมุดบันทึกปัจจุบันของคุณเท่านั้น - อีกวิธีหนึ่งคือ คุณสามารถสร้างสภาพแวดล้อม Fabric ติดตั้งไลบรารีจากแหล่งข้อมูลสาธารณะ หรืออัปโหลดไลบรารีแบบกําหนดเอง จากนั้นผู้ดูแลระบบพื้นที่ทํางานของคุณสามารถแนบสภาพแวดล้อมเป็นค่าเริ่มต้นสําหรับพื้นที่ทํางานได้ ไลบรารีทั้งหมดในสภาพแวดล้อมจะพร้อมใช้งานสําหรับใช้ในข้อกําหนดงานของสมุดบันทึกและ Spark ในพื้นที่ทํางาน สําหรับข้อมูลเพิ่มเติมเกี่ยวกับสภาพแวดล้อม ให้ดู สร้าง กําหนดค่า และใช้สภาพแวดล้อมใน Microsoft Fabric
ในบทช่วยสอนนี้ ให้ใช้ install.version() เพื่อติดตั้งไลบรารี imbalanced-learn:
# Install dependencies
devtools::install_version("bnlearn", version = "4.8")
# Install imbalance for SMOTE
devtools::install_version("imbalance", version = "1.0.2.1")
ขั้นตอนที่ 2: โหลดข้อมูล
ชุดข้อมูลการตรวจจับการฉ้อโกงประกอบด้วยธุรกรรมบัตรเครดิตตั้งแต่เดือนกันยายน 2013 ซึ่งผู้ถือบัตรชาวยุโรปในช่วงเวลาสองวัน ชุดข้อมูลประกอบด้วยคุณลักษณะตัวเลขเท่านั้นเนื่องจากการแปลงคอมโพเนนต์หลัก (PCA) ที่นําไปใช้กับคุณลักษณะดั้งเดิม PCA แปลงคุณลักษณะทั้งหมดยกเว้น Time และ Amount เพื่อปกป้องความลับ เราไม่สามารถให้คุณลักษณะดั้งเดิมหรือข้อมูลเบื้องหลังเพิ่มเติมเกี่ยวกับชุดข้อมูลได้
รายละเอียดเหล่านี้อธิบายชุดข้อมูล:
- คุณลักษณะ
V1,V2,V3, ...V28เป็นส่วนประกอบหลักที่ได้จาก PCA - คุณลักษณะ
Timeประกอบด้วยวินาทีที่ผ่านไประหว่างธุรกรรมและธุรกรรมแรกในชุดข้อมูล - ลักษณะการทํางาน
Amountคือยอดเงินธุรกรรม คุณสามารถใช้คุณลักษณะนี้สําหรับการเรียนรู้ที่ขึ้นอยู่กับตัวอย่าง และมีความไวต่อค่าใช้จ่าย - คอลัมน์
Classคือตัวแปรการตอบสนอง (เป้าหมาย) มี1ค่าสําหรับการฉ้อโกงและ0ถ้าเป็นอย่างอื่น
เพียง 492 รายการ จากธุรกรรมทั้งหมด 284,807 รายการ ชุดข้อมูลมีความไม่สมดุลอย่างมาก เนื่องจากบัญชีของชั้นน้อย (ฉ้อฉล) มีเพียงประมาณ 0.172% ของข้อมูลเท่านั้น
ตารางนี้แสดงตัวอย่างของข้อมูล creditcard.csv:
| เวลา | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | V11 | V12 | V13 | V14 | V15 | V16 | V17 | V18 | V19 | V20 | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | ปริมาณ | ประเภท |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1.3598071336738 | -0.0727811733098497 | 2.53634673796914 | 1.37815522427443 | -0.338320769942518 | 0.462387777762292 | 0.239598554061257 | 0.0986979012610507 | 0.363786969611213 | 0.0907941719789316 | -0.551599533260813 | -0.617800855762348 | -0.991389847235408 | -0.311169353699879 | 1.46817697209427 | -0.470400525259478 | 0.207971241929242 | 0.0257905801985591 | 0.403992960255733 | 0.251412098239705 | -0.018306777944153 | 0.277837575558899 | -0.110473910188767 | 0.0669280749146731 | 0.128539358273528 | -0.189114843888824 | 0.133558376740387 | -0.0210530534538215 | 149.62 | "0" |
| 0 | 1.19185711131486 | 0.26615071205963 | 0.16648011335321 | 0.448154078460911 | 0.0600176492822243 | -0.0823608088155687 | -0.0788029833323113 | 0.0851016549148104 | -0.255425128109186 | -0.166974414004614 | 1.61272666105479 | 1.06523531137287 | 0.48909501589608 | -0.143772296441519 | 0.635558093258208 | 0.463917041022171 | -0.114804663102346 | -0.183361270123994 | -0.145783041325259 | -0.0690831352230203 | -0.225775248033138 | -0.638671952771851 | 0.101288021253234 | -0.339846475529127 | 0.167170404418143 | 0.125894532368176 | -0.00898309914322813 | 0.0147241691924927 | 2.69 | "0" |
ดาวน์โหลดชุดข้อมูลและอัปโหลดไปยัง lakehouse
กําหนดพารามิเตอร์เหล่านี้เพื่อให้คุณสามารถใช้สมุดบันทึกนี้กับชุดข้อมูลที่แตกต่างกันได้:
IS_CUSTOM_DATA <- FALSE # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE <- FALSE # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS <- 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT <- "/lakehouse/default"
DATA_FOLDER <- "Files/fraud-detection" # Folder with data files
DATA_FILE <- "creditcard.csv" # Data file name
รหัสนี้จะดาวน์โหลดเวอร์ชันสาธารณะของชุดข้อมูล และจากนั้นเก็บไว้ใน Fabric lakehouse
สําคัญ
อย่าลืม เพิ่มเลคเฮาส์ ลงในสมุดบันทึกก่อนที่คุณจะเรียกใช้ มิฉะนั้น คุณจะได้รับข้อผิดพลาด
if (!IS_CUSTOM_DATA) {
# Download data files into a lakehouse if they don't exist
library(httr)
remote_url <- "https://synapseaisolutionsa.blob.core.windows.net/public/Credit_Card_Fraud_Detection"
fname <- "creditcard.csv"
download_path <- file.path(DATA_ROOT, DATA_FOLDER, "raw")
dir.create(download_path, showWarnings = FALSE, recursive = TRUE)
if (!file.exists(file.path(download_path, fname))) {
r <- GET(file.path(remote_url, fname), timeout(30))
writeBin(content(r, "raw"), file.path(download_path, fname))
}
message("Downloaded demo data files into lakehouse.")
}
อ่านข้อมูลวันที่ดิบจากเลคเฮ้าส์
รหัสนี้อ่านข้อมูลดิบจากส่วน ไฟล์
data_df <- read.csv(file.path(DATA_ROOT, DATA_FOLDER, "raw", DATA_FILE))
ขั้นตอนที่ 3: ดําเนินการวิเคราะห์ข้อมูลเชิงสํารวจ
ใช้คําสั่ง display เพื่อดูสถิติระดับสูงของชุดข้อมูล:
display(as.DataFrame(data_df, numPartitions = 3L))
# Print dataset basic information
message(sprintf("records read: %d", nrow(data_df)))
message("Schema:")
str(data_df)
# If IS_SAMPLE is True, use only SAMPLE_ROWS of rows for training
if (IS_SAMPLE) {
data_df = sample_n(data_df, SAMPLE_ROWS)
}
พิมพ์การกระจายของคลาสในชุดข้อมูล:
# The distribution of classes in the dataset
message(sprintf("No Frauds %.2f%% of the dataset\n", round(sum(data_df$Class == 0)/nrow(data_df) * 100, 2)))
message(sprintf("Frauds %.2f%% of the dataset\n", round(sum(data_df$Class == 1)/nrow(data_df) * 100, 2)))
การแจกแจงคลาสนี้แสดงว่าธุรกรรมส่วนใหญ่ไม่มีการป้องกัน ดังนั้น จําเป็นต้องมีการประมวลผลข้อมูลล่วงหน้าก่อนการฝึกแบบจําลองเพื่อหลีกเลี่ยงการมากเกินไป
ดูการกระจายของการฉ้อโกงเทียบกับธุรกรรมที่ไม่ฉ้อฉล
ดูการกระจายการฉ้อโกงเทียบกับธุรกรรมที่ไม่ฉ้อฉลด้วยพล็อต เพื่อแสดงความไม่สมดุลของคลาสในชุดข้อมูล:
library(ggplot2)
ggplot(data_df, aes(x = factor(Class), fill = factor(Class))) +
geom_bar(stat = "count") +
scale_x_discrete(labels = c("no fraud", "fraud")) +
ggtitle("Class Distributions \n (0: No Fraud || 1: Fraud)") +
theme(plot.title = element_text(size = 10))
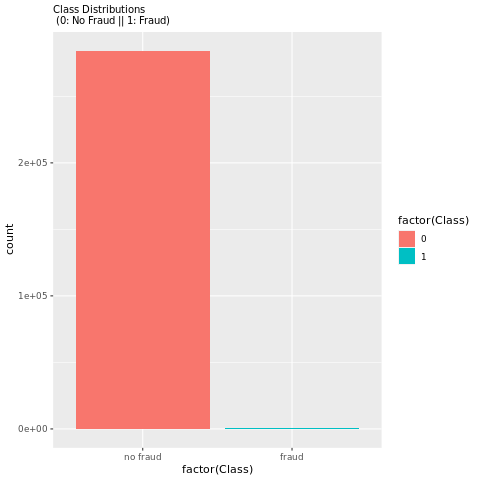
การลงจุดจะแสดงความไม่สมดุลของชุดข้อมูลอย่างชัดเจน:
แสดงสรุปตัวเลขห้าตัว
แสดงข้อมูลสรุปแบบห้าตัวเลข (คะแนนต่ําสุด ควอร์ไทล์ แรก ค่ามัธยฐาน ควอร์ไทล์ที่สาม และคะแนนสูงสุด) สําหรับจํานวนธุรกรรม พร้อมกับการลงจุดกล่อง:
library(ggplot2)
library(dplyr)
ggplot(data_df, aes(x = as.factor(Class), y = Amount, fill = as.factor(Class))) +
geom_boxplot(outlier.shape = NA) +
scale_x_discrete(labels = c("no fraud", "fraud")) +
ggtitle("Boxplot without Outliers") +
coord_cartesian(ylim = quantile(data_df$Amount, c(0.05, 0.95)))
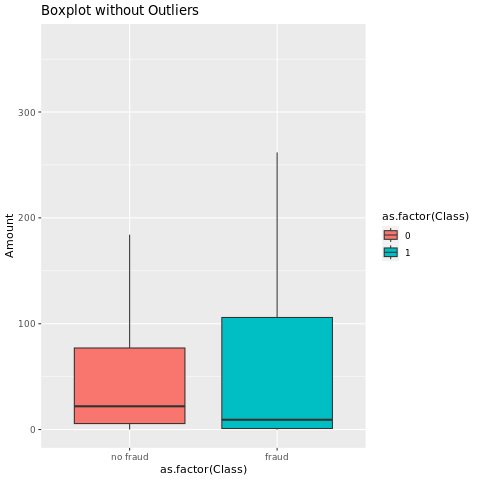
สําหรับข้อมูลที่ไม่สมดุลสูง แผนภูมิบ็อกซ์อาจไม่แสดงข้อมูลเชิงลึกที่ถูกต้อง อย่างไรก็ตาม คุณสามารถจัดการปัญหาความไม่สมดุลของ Class ก่อน จากนั้นสร้างพล็อตเดียวกันสําหรับข้อมูลเชิงลึกที่ถูกต้องยิ่งขึ้น
ขั้นตอนที่ 4: ฝึกและประเมินแบบจําลอง
ที่นี่คุณฝึกแบบจําลอง LightGBM เพื่อจัดประเภทธุรกรรมการฉ้อโกง คุณฝึกแบบจําลอง LightGBM บนทั้งชุดข้อมูลที่ไม่สมดุลและชุดข้อมูลที่สมดุล จากนั้น คุณเปรียบเทียบประสิทธิภาพของทั้งสองแบบจําลอง
เตรียมการฝึกอบรมและทดสอบชุดข้อมูล
ก่อนการฝึก ให้แยกข้อมูลไปยังชุดข้อมูลการฝึกอบรมและการทดสอบ:
# Split the dataset into training and test datasets
set.seed(42)
train_sample_ids <- base::sample(seq_len(nrow(data_df)), size = floor(0.85 * nrow(data_df)))
train_df <- data_df[train_sample_ids, ]
test_df <- data_df[-train_sample_ids, ]
นํา SMOTE ไปใช้กับชุดข้อมูลการฝึกอบรม
การจัดประเภทแบบไม่สมดุลมีปัญหา มีตัวอย่างคลาสน้อยเกินไปสําหรับแบบจําลองเพื่อเรียนรู้ขอบเขตการตัดสินใจอย่างมีประสิทธิภาพ เทคนิคการสุ่มตัวอย่างเล็กน้อยสังเคราะห์ (SMOTE) สามารถจัดการกับปัญหานี้ได้ SMOTE เป็นวิธีที่ใช้กันอย่างแพร่หลายที่สุดในการสังเคราะห์ตัวอย่างใหม่สําหรับคลาสรอง คุณสามารถเข้าถึง SMOTE ได้โดยใช้ไลบรารี imbalance ที่คุณติดตั้งในขั้นตอนที่ 1
ใช้ SMOTE กับชุดข้อมูลการฝึกอบรมเท่านั้นแทนที่จะเป็นชุดข้อมูลทดสอบ เมื่อคุณให้คะแนนแบบจําลองด้วยข้อมูลทดสอบ คุณต้องมีประมาณประสิทธิภาพของแบบจําลองเกี่ยวกับข้อมูลที่ไม่ได้มองเห็นในการผลิต สําหรับประมาณการที่ถูกต้อง ข้อมูลการทดสอบของคุณขึ้นอยู่กับการกระจายแบบไม่สมดุลเดิมเพื่อแสดงข้อมูลการผลิตให้ใกล้เคียงที่สุดเท่าที่เป็นไปได้
# Apply SMOTE to the training dataset
library(imbalance)
# Print the shape of the original (imbalanced) training dataset
train_y_categ <- train_df %>% select(Class) %>% table
message(
paste0(
"Original dataset shape ",
paste(names(train_y_categ), train_y_categ, sep = ": ", collapse = ", ")
)
)
# Resample the training dataset by using SMOTE
smote_train_df <- train_df %>%
mutate(Class = factor(Class)) %>%
oversample(ratio = 0.99, method = "SMOTE", classAttr = "Class") %>%
mutate(Class = as.integer(as.character(Class)))
# Print the shape of the resampled (balanced) training dataset
smote_train_y_categ <- smote_train_df %>% select(Class) %>% table
message(
paste0(
"Resampled dataset shape ",
paste(names(smote_train_y_categ), smote_train_y_categ, sep = ": ", collapse = ", ")
)
)
สําหรับข้อมูลเพิ่มเติมเกี่ยวกับ SMOTE โปรดดู 'ความไม่สมดุล' ของแพคเกจ
ฝึกแบบจําลองด้วย LightGBM
ฝึกแบบจําลอง LightGBM ด้วยทั้งชุดข้อมูลที่ไม่สมดุลและชุดข้อมูลที่สมดุล (ผ่าน SMOTE) จากนั้น เปรียบเทียบประสิทธิภาพการทํางาน:
# Train LightGBM for both imbalanced and balanced datasets and define the evaluation metrics
library(lightgbm)
# Get the ID of the label column
label_col <- which(names(train_df) == "Class")
# Convert the test dataset for the model
test_mtx <- as.matrix(test_df)
test_x <- test_mtx[, -label_col]
test_y <- test_mtx[, label_col]
# Set up the parameters for training
params <- list(
objective = "binary",
learning_rate = 0.05,
first_metric_only = TRUE
)
# Train for the imbalanced dataset
message("Start training with imbalanced data:")
train_mtx <- as.matrix(train_df)
train_x <- train_mtx[, -label_col]
train_y <- train_mtx[, label_col]
train_data <- lgb.Dataset(train_x, label = train_y)
valid_data <- lgb.Dataset.create.valid(train_data, test_x, label = test_y)
model <- lgb.train(
data = train_data,
params = params,
eval = list("binary_logloss", "auc"),
valids = list(valid = valid_data),
nrounds = 300L
)
# Train for the balanced (via SMOTE) dataset
message("\n\nStart training with balanced data:")
smote_train_mtx <- as.matrix(smote_train_df)
smote_train_x <- smote_train_mtx[, -label_col]
smote_train_y <- smote_train_mtx[, label_col]
smote_train_data <- lgb.Dataset(smote_train_x, label = smote_train_y)
smote_valid_data <- lgb.Dataset.create.valid(smote_train_data, test_x, label = test_y)
smote_model <- lgb.train(
data = smote_train_data,
params = params,
eval = list("binary_logloss", "auc"),
valids = list(valid = smote_valid_data),
nrounds = 300L
)
กําหนดความสําคัญของคุณลักษณะ
กําหนดความสําคัญของคุณลักษณะสําหรับแบบจําลองที่คุณฝึกบนชุดข้อมูลที่ไม่สมดุล:
imp <- lgb.importance(model, percentage = TRUE)
ggplot(imp, aes(x = Frequency, y = reorder(Feature, Frequency), fill = Frequency)) +
scale_fill_gradient(low="steelblue", high="tomato") +
geom_bar(stat = "identity") +
geom_text(aes(label = sprintf("%.4f", Frequency)), hjust = -0.1) +
theme(axis.text.x = element_text(angle = 90)) +
xlim(0, max(imp$Frequency) * 1.1)
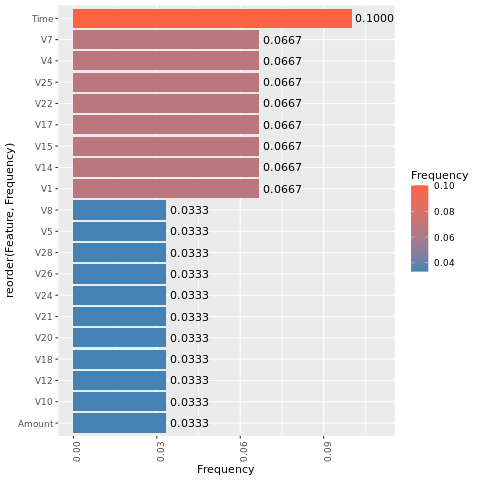
สําหรับแบบจําลองที่คุณฝึกบนชุดข้อมูลที่สมดุล (ผ่าน SMOTE) ให้คํานวณความสําคัญของคุณลักษณะ:
smote_imp <- lgb.importance(smote_model, percentage = TRUE)
ggplot(smote_imp, aes(x = Frequency, y = reorder(Feature, Frequency), fill = Frequency)) +
geom_bar(stat = "identity") +
scale_fill_gradient(low="steelblue", high="tomato") +
geom_text(aes(label = sprintf("%.4f", Frequency)), hjust = -0.1) +
theme(axis.text.x = element_text(angle = 90)) +
xlim(0, max(smote_imp$Frequency) * 1.1)
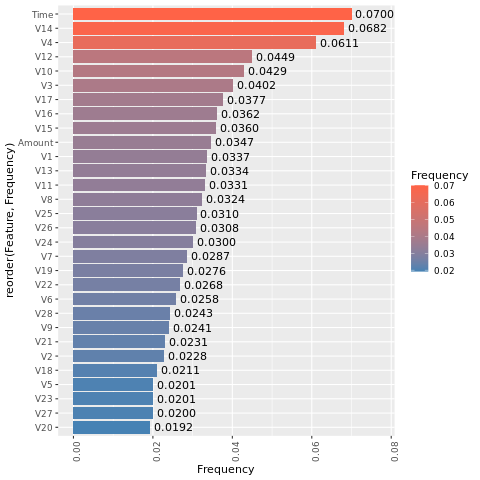
การเปรียบเทียบพล็อตเหล่านี้แสดงให้เห็นอย่างชัดเจนว่าชุดข้อมูลการฝึกอบรมที่สมดุลและไม่สมดุลมีความแตกต่างที่สําคัญของคุณลักษณะอย่างมาก
ประเมินแบบจําลอง
ที่นี่ คุณประเมินแบบจําลองที่ได้รับการฝึกสองแบบ:
-
modelได้รับการฝึกฝนเกี่ยวกับข้อมูลดิบ ที่ไม่สมดุล -
smote_modelได้รับการฝึกฝนบนข้อมูลที่สมดุล
preds <- predict(model, test_mtx[, -label_col])
smote_preds <- predict(smote_model, test_mtx[, -label_col])
ประเมินประสิทธิภาพของแบบจําลองด้วยเมทริกซ์ความสับสน
เมทริกซ์ความสับสน แสดงจํานวนของ
- ผลบวกจริง (TP)
- ผลลบจริง (TN)
- ผลบวกเท็จ (FP)
- ผลลบเท็จ (FN)
ที่สร้างแบบจําลองขึ้นเมื่อให้คะแนนด้วยข้อมูลทดสอบ สําหรับการจัดประเภทไบนารี แบบจําลองส่งกลับเมทริกซ์ความสับสน 2x2 สําหรับการจัดประเภทแบบหลายคลาส แบบจําลองจะแสดงเมทริกซ์ความสับสน nxn โดยที่ n คือจํานวนคลาส
ใช้เมทริกซ์ความสับสนเพื่อสรุปประสิทธิภาพการทํางานของแบบจําลองการเรียนรู้ของเครื่องที่ได้รับการฝึกบนข้อมูลการทดสอบ:
plot_cm <- function(preds, refs, title) { library(caret) cm <- confusionMatrix(factor(refs), factor(preds)) cm_table <- as.data.frame(cm$table) cm_table$Prediction <- factor(cm_table$Prediction, levels=rev(levels(cm_table$Prediction))) ggplot(cm_table, aes(Reference, Prediction, fill = Freq)) + geom_tile() + geom_text(aes(label = Freq)) + scale_fill_gradient(low = "white", high = "steelblue", trans = "log") + labs(x = "Prediction", y = "Reference", title = title) + scale_x_discrete(labels=c("0", "1")) + scale_y_discrete(labels=c("1", "0")) + coord_equal() + theme(legend.position = "none") }ลงจุดเมทริกซ์ความสับสนสําหรับแบบจําลองที่ได้รับการฝึกบนชุดข้อมูลที่ไม่สมดุล:
# The value of the prediction indicates the probability that a transaction is fraud # Use 0.5 as the threshold for fraud/no-fraud transactions plot_cm(ifelse(preds > 0.5, 1, 0), test_df$Class, "Confusion Matrix (Imbalanced dataset)")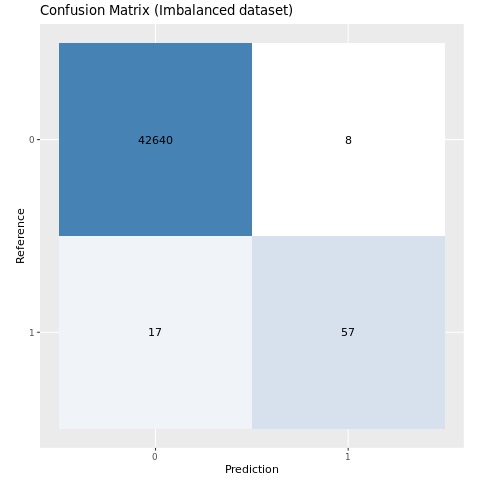
ลงจุดเมทริกซ์ความสับสนสําหรับแบบจําลองที่ได้รับการฝึกบนชุดข้อมูลที่สมดุล:
plot_cm(ifelse(smote_preds > 0.5, 1, 0), test_df$Class, "Confusion Matrix (Balanced dataset)")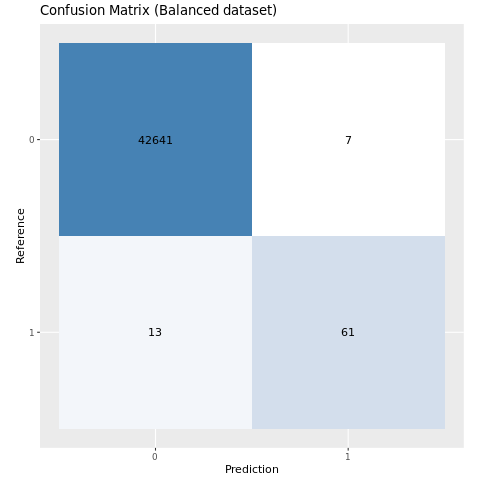
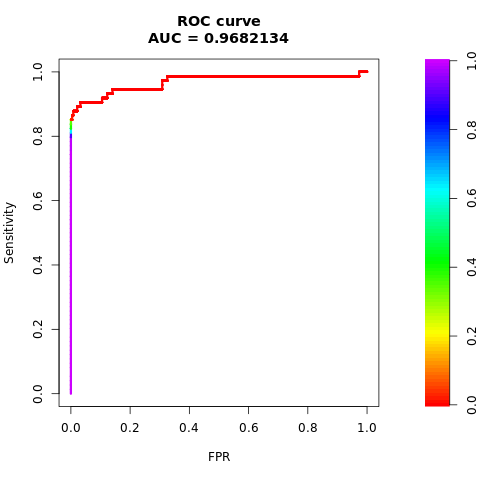
ประเมินประสิทธิภาพของแบบจําลองด้วยหน่วยวัด AUC-ROC และ AUPRC
พื้นที่ภายใต้หน่วยวัดลักษณะการดําเนินงานของตัวรับเส้นโค้ง (AUC-ROC) จะประเมินประสิทธิภาพของตัวจําแนกประเภทไบนารี แผนภูมิ AUC-ROC แสดงภาพการเทรดระหว่างอัตราค่าบวกจริง (TPR) และอัตราบวกเท็จ (FPR)
ในบางกรณี มีความเหมาะสมในการประเมินตัวจําแนกประเภทของคุณโดยยึดตามพื้นที่ภายใต้หน่วยวัดเส้นโค้ง Precision-Recall (AUPRC) เส้นโค้ง AUPRC จะรวมอัตราเหล่านี้:
- ความแม่นยําหรือค่าการคาดการณ์เชิงบวก (PPV)
- ค่าความระลึกหรือ TPR
# Use the PRROC package to help calculate and plot AUC-ROC and AUPRC
install.packages("PRROC", quiet = TRUE)
library(PRROC)
คํานวณเมตริก AUC-ROC และ AUPRC
คํานวณและลงจุด AUC-ROC และเมตริก AUPRC สําหรับสองแบบจําลอง
ชุดข้อมูลที่ไม่สมดุล
คํานวณการคาดการณ์:
fg <- preds[test_df$Class == 1]
bg <- preds[test_df$Class == 0]
พิมพ์พื้นที่ภายใต้เส้นโค้ง AUC-ROC:
# Compute AUC-ROC
roc <- roc.curve(scores.class0 = fg, scores.class1 = bg, curve = TRUE)
print(roc)
ลงจุดเส้นโค้ง AUC-ROC:
# Plot AUC-ROC
plot(roc)
พิมพ์เส้นโค้ง AUPRC:
# Compute AUPRC
pr <- pr.curve(scores.class0 = fg, scores.class1 = bg, curve = TRUE)
print(pr)
ลงจุดเส้นโค้ง AUPRC:
# Plot AUPRC
plot(pr)
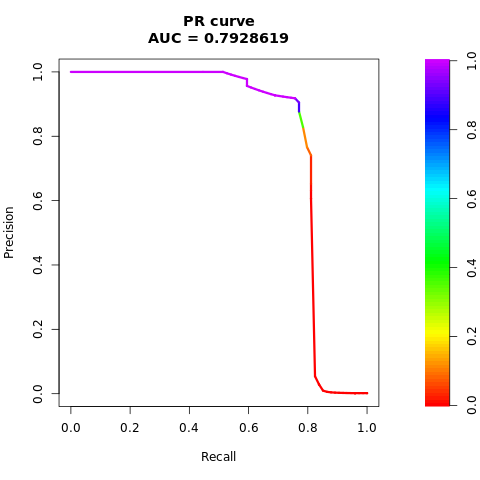
ชุดข้อมูลที่สมดุล (ผ่าน SMOTE)
คํานวณการคาดการณ์:
smote_fg <- smote_preds[test_df$Class == 1]
smote_bg <- smote_preds[test_df$Class == 0]
พิมพ์เส้นโค้ง AUC-ROC:
# Compute AUC-ROC
smote_roc <- roc.curve(scores.class0 = smote_fg, scores.class1 = smote_bg, curve = TRUE)
print(smote_roc)
ลงจุดเส้นโค้ง AUC-ROC:
# Plot AUC-ROC
plot(smote_roc)
พิมพ์เส้นโค้ง AUPRC:
# Compute AUPRC
smote_pr <- pr.curve(scores.class0 = smote_fg, scores.class1 = smote_bg, curve = TRUE)
print(smote_pr)
ลงจุดเส้นโค้ง AUPRC:
# Plot AUPRC
plot(smote_pr)
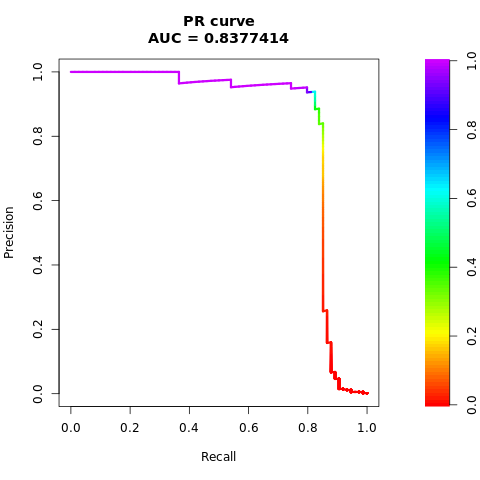
ตัวเลขก่อนหน้านี้แสดงให้เห็นอย่างชัดเจนว่าแบบจําลองที่ได้รับการฝึกบนชุดข้อมูลที่สมดุลมีประสิทธิภาพเหนือกว่าแบบจําลองที่ได้รับการฝึกบนชุดข้อมูลที่ไม่สมดุลสําหรับคะแนน AUC-ROC และ AUPRC ผลลัพธ์นี้แสดงให้เห็นว่า SMOTE ช่วยปรับปรุงประสิทธิภาพของแบบจําลองอย่างมีประสิทธิภาพเมื่อทํางานกับข้อมูลที่ไม่สมดุลสูง
เนื้อหาที่เกี่ยวข้อง
- แบบจําลองการเรียนรู้ของเครื่อง ใน Microsoft Fabric
- แบบจําลองการเรียนรู้ของเครื่อง Train
- การทดลองการเรียนรู้ของเครื่อง ใน Microsoft Fabric