บทช่วยสอน: ล้างข้อมูลด้วยการขึ้นต่อกันที่ใช้งานได้
ในบทช่วยสอนนี้ คุณใช้การขึ้นต่อกันที่ใช้งานได้สําหรับการทําความสะอาดข้อมูล มีการขึ้นต่อกันของฟังก์ชันเมื่อมีหนึ่งคอลัมน์ในแบบจําลองความหมาย (ชุดข้อมูล Power BI) เป็นฟังก์ชันของคอลัมน์อื่น ตัวอย่างเช่น คอลัมน์รหัสไปรษณีย์อาจกําหนดค่าในคอลัมน์เมือง การขึ้นต่อกันของฟังก์ชันการทํางานแสดงตัวเองเป็นความสัมพันธ์แบบหนึ่งต่อกลุ่มระหว่างค่าในสองคอลัมน์หรือมากกว่าภายใน DataFrame บทช่วยสอนนี้ใช้ ชุดข้อมูล Synthea เพื่อแสดงวิธีที่ความสัมพันธ์การทํางานสามารถช่วยในการตรวจหาปัญหาคุณภาพของข้อมูลได้
ในบทช่วยสอนนี้ คุณจะเรียนรู้วิธีการ:
- นําความรู้โดเมนไปใช้เพื่อกําหนดสมมติฐานเกี่ยวกับการขึ้นต่อกันของฟังก์ชันการทํางานในแบบจําลองความหมาย
- ทําความคุ้นเคยกับคอมโพเนนต์ของไลบรารี Python ของลิงก์เชิงความหมาย (SemPy) ที่ช่วยในการวิเคราะห์คุณภาพข้อมูลโดยอัตโนมัติ คอมโพเนนต์เหล่านี้ประกอบด้วย:
- FabricDataFrame - โครงสร้างที่คล้ายกับ pandas เพิ่มขึ้นด้วยข้อมูลความหมายเพิ่มเติม
- ฟังก์ชันที่มีประโยชน์ที่ทําให้การประเมินสมมติฐานเกี่ยวกับการขึ้นต่อกันของการทํางานเป็นแบบอัตโนมัติและระบุการละเมิดความสัมพันธ์ในแบบจําลองความหมายของคุณ
ข้อกำหนดเบื้องต้น
รับการสมัครใช้งาน Microsoft Fabric หรือลงทะเบียนเพื่อทดลองใช้งาน Microsoft Fabric ฟรี
ลงชื่อเข้าใช้ Microsoft Fabric
ใช้ตัวสลับประสบการณ์ทางด้านซ้ายของโฮมเพจของคุณเพื่อสลับไปยังประสบการณ์วิทยาศาสตร์ข้อมูล Synapse
- เลือก พื้นที่ทํางาน จากบานหน้าต่างนําทางด้านซ้ายเพื่อค้นหาและเลือกพื้นที่ทํางานของคุณ พื้นที่ทํางานนี้จะกลายเป็นพื้นที่ทํางานปัจจุบันของคุณ
ติดตามในสมุดบันทึก
สมุดบันทึก data_cleaning_functional_dependencies_tutorial.ipynb มาพร้อมกับบทช่วยสอนนี้
เมื่อต้องการเปิดสมุดบันทึกที่มาพร้อมกับบทช่วยสอนนี้ ให้ทําตามคําแนะนําใน เตรียมระบบของคุณสําหรับบทช่วยสอนวิทยาศาสตร์ข้อมูล เพื่อนําเข้าสมุดบันทึกไปยังพื้นที่ทํางานของคุณ
ถ้าคุณต้องการคัดลอกและวางรหัสจากหน้านี้แทน คุณสามารถสร้าง สมุดบันทึกใหม่ได้
ตรวจสอบให้แน่ใจว่าแนบ lakehouse เข้ากับสมุดบันทึก ก่อนที่คุณจะเริ่มเรียกใช้รหัส
ตั้งค่าสมุดบันทึก
ในส่วนนี้ คุณตั้งค่าสภาพแวดล้อมของสมุดบันทึกด้วยโมดูลและข้อมูลที่จําเป็น
- สําหรับ Spark 3.4 และสูงกว่า ลิงก์ความหมายจะพร้อมใช้งานในรันไทม์เริ่มต้นเมื่อใช้ Fabric และไม่จําเป็นต้องติดตั้ง ถ้าคุณกําลังใช้ Spark 3.3 หรือต่ํากว่า หรือถ้าคุณต้องการอัปเดตเป็นลิงก์ความหมายเวอร์ชันล่าสุด คุณสามารถเรียกใช้คําสั่งได้:
python %pip install -U semantic-link
ทําการนําเข้าโมดูลที่จําเป็นซึ่งคุณจะต้องใช้ในภายหลัง:
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadata from sempy.samples import download_syntheaดึงข้อมูลตัวอย่าง สําหรับบทช่วยสอนนี้ คุณใช้ ชุดข้อมูล Synthea ของเวชระเบียนสังเคราะห์ (เวอร์ชันขนาดเล็กเพื่อความง่าย):
download_synthea(which='small')
สํารวจข้อมูล
เตรียม
FabricDataFrameใช้งาน ด้วยเนื้อหาของ ไฟล์ providers.csv :providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()ตรวจสอบปัญหาคุณภาพของข้อมูลด้วยฟังก์ชันของ
find_dependenciesSemPy โดยการลงจุดกราฟของการขึ้นต่อกันของฟังก์ชันที่ตรวจพบโดยอัตโนมัติ:deps = providers.find_dependencies() plot_dependency_metadata(deps)
กราฟของการขึ้นต่อกันของฟังก์ชันแสดงให้เห็นว่าเป็น
IdตัวกําหนดและORGANIZATION(ระบุด้วยลูกศรทึบ) ซึ่งคาดหมายไว้เนื่องจากIdNAMEเป็นค่าเฉพาะ:ยืนยันว่า
Idไม่ซ้ํากัน:providers.Id.is_uniqueรหัสจะ
Trueส่งกลับเพื่อยืนยันว่าIdไม่ซ้ํากัน

วิเคราะห์การขึ้นต่อกันของฟังก์ชันในเชิงลึก
กราฟการขึ้นต่อกันของฟังก์ชันการทํางานยังแสดงให้เห็นว่า เป็น ORGANIZATION ตัว ADDRESS กําหนด และ ZIPตามที่คาดไว้ อย่างไรก็ตาม คุณอาจคาดว่าจะ ZIP กําหนด CITYด้วย แต่ลูกศรประระบุว่า การขึ้นต่อกันเป็นค่าประมาณเท่านั้น ชี้ไปยังปัญหาคุณภาพของข้อมูล
มีความผิดปกติอื่น ๆ ในกราฟ ตัวอย่างเช่น NAME ไม่ได้กําหนด GENDER, Id, SPECIALITY, หรือORGANIZATION ความผิดปกติเหล่านี้แต่ละรายการอาจคุ้มค่าที่จะตรวจสอบ
ดูความสัมพันธ์โดยประมาณระหว่าง
ZIPและCITYโดยใช้ฟังก์ชันของlist_dependency_violationsSemPy เพื่อดูรายการการละเมิดแบบตาราง:providers.list_dependency_violations('ZIP', 'CITY')วาดกราฟด้วยฟังก์ชันการแสดงผลข้อมูลด้วยภาพของ
plot_dependency_violationsSemPy กราฟนี้จะมีประโยชน์หากจํานวนการละเมิดมีขนาดเล็ก:providers.plot_dependency_violations('ZIP', 'CITY')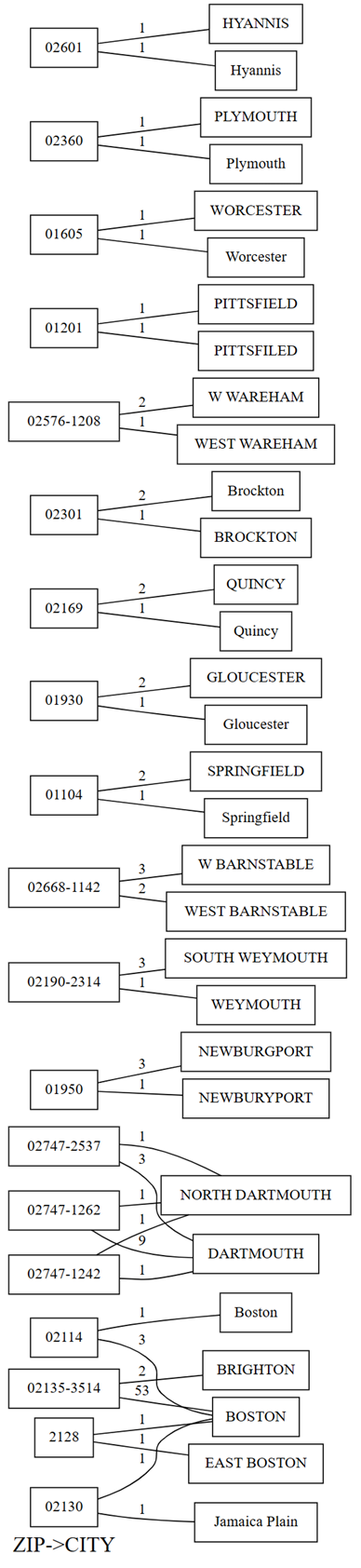
พล็อตของการละเมิดการขึ้นต่อกันแสดงค่าสําหรับ
ZIPทางด้านซ้าย มือ และค่าสําหรับCITYทางด้านขวามือ ขอบเชื่อมต่อรหัสไปรษณีย์ทางด้านซ้ายของแผนภูมิด้วยเมืองทางด้านขวาหากมีแถวที่มีสองค่าเหล่านี้ ขอบจะถูกใส่คําอธิบายประกอบไว้ด้วยการนับจํานวนแถวดังกล่าว ตัวอย่างเช่น มีสองแถวที่มีรหัสไปรษณีย์ 02747-1242 หนึ่งแถวที่มีเมือง "NORTH DARTHMOUTH" และอีกหนึ่งแถวที่มีเมือง "DARTHMOUTH" ดังที่แสดงในแผนภาพก่อนหน้านี้และรหัสต่อไปนี้:ยืนยันการสังเกตการณ์ก่อนหน้าที่คุณดําเนินการกับการลงจุดของการละเมิดการขึ้นต่อกันโดยการเรียกใช้โค้ดต่อไปนี้:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()การลงจุดยังแสดงให้เห็นว่าในแถวที่มี
CITYเป็น "DARTHMOUTH" เก้าแถวมีZIP02747-1262 หนึ่งแถวมีZIP02747-1242 และแถวหนึ่งมีZIP02747-2537 ยืนยันข้อสังเกตเหล่านี้ด้วยโค้ดต่อไปนี้:providers[providers.CITY == 'DARTMOUTH'].ZIP.value_counts()มีรหัสไปรษณีย์อื่น ๆ ที่เกี่ยวข้องกับ "DARTMOUTH" แต่รหัสไปรษณีย์เหล่านี้จะไม่แสดงในกราฟของการละเมิดการขึ้นต่อกันเนื่องจากไม่ได้ให้คําแนะนําเรื่องคุณภาพข้อมูล ตัวอย่างเช่น รหัสไปรษณีย์ "02747-4302" มีความเชื่อมโยงกับ "DARTMOUTH" โดยเฉพาะ และไม่แสดงในกราฟของการละเมิดการขึ้นต่อกัน ยืนยันโดยการเรียกใช้โค้ดต่อไปนี้:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
สรุปปัญหาคุณภาพของข้อมูลที่ตรวจพบด้วย SemPy
ย้อนกลับไปยังกราฟของการละเมิดการขึ้นต่อกัน คุณจะเห็นว่ามีปัญหาคุณภาพของข้อมูลที่น่าสนใจหลายประการที่มีอยู่ในแบบจําลองความหมายนี้:
- ชื่อเมืองบางชื่อเป็นตัวพิมพ์ใหญ่ทั้งหมด ปัญหานี้แก้ไขได้ง่ายโดยใช้วิธีการสตริง
- ชื่อเมืองบางชื่อมีตัวบ่งคุณลักษณะ (หรือคํานําหน้า) เช่น "เหนือ" และ "ตะวันออก" ตัวอย่างเช่น รหัสไปรษณีย์ "2128" แมปไปยัง "EAST BOSTON" หนึ่งครั้งและไปยัง "BOSTON" หนึ่งครั้ง ปัญหาที่คล้ายกันเกิดขึ้นระหว่าง "NORTH DARTHMOUTH" และ "DARTHMOUTH" คุณสามารถลองวางตัวบ่งคุณลักษณะเหล่านี้หรือแมปรหัสไปรษณีย์ไปยังเมืองโดยมีเหตุการณ์ที่พบบ่อยที่สุด
- มีการพิมพ์ผิดในบางเมือง เช่น "PITTSFIELD" เทียบกับ "PITTSFILED" และ "NEWBURGPORT เทียบกับ "NEWBURYPORT" สําหรับ "NEWBURGPORT" การพิมพ์ผิดนี้สามารถแก้ไขได้โดยใช้เหตุการณ์ที่พบบ่อยที่สุด สําหรับ "PITTSFIELD" การปรากฏเพียงครั้งเดียวแต่ละครั้งทําให้ยากขึ้นสําหรับการแก้ความกํากวมอัตโนมัติโดยไม่มีความรู้ภายนอกหรือการใช้แบบจําลองภาษา
- ในบางครั้ง คํานําหน้าเช่น "West" ย่อเป็นตัวอักษรตัวเดียว "W" ปัญหานี้อาจได้รับการแก้ไขด้วยการแทนที่อย่างง่ายถ้าการปรากฏทั้งหมดของ "W" หมายถึง "West"
- รหัสไปรษณีย์ "02130" แมปไปยัง "BOSTON" หนึ่งครั้งและ "จาเมกา ธรรมดา" หนึ่งครั้ง ปัญหานี้ไม่สามารถแก้ไขได้ แต่ถ้ามีข้อมูลเพิ่มเติม การแมปไปยังเหตุการณ์ที่พบบ่อยที่สุดอาจเป็นวิธีแก้ปัญหาที่อาจเกิดขึ้นได้
ทําความสะอาดข้อมูล
แก้ไขปัญหาตัวพิมพ์ใหญ่ โดยการเปลี่ยนตัวพิมพ์ใหญ่ทั้งหมดเป็นกรณีชื่อเรื่อง:
providers['CITY'] = providers.CITY.str.title()เรียกใช้การตรวจหาการละเมิดอีกครั้งเพื่อดูว่าบางส่วนของความกํากวมหายไป (จํานวนการละเมิดมีขนาดเล็กลง):
providers.list_dependency_violations('ZIP', 'CITY')ในตอนนี้ คุณสามารถปรับปรุงข้อมูลของคุณด้วยตนเอง แต่งานล้างข้อมูลที่เป็นไปได้อย่างหนึ่งคือการทิ้งแถวที่ละเมิดข้อจํากัดการทํางานระหว่างคอลัมน์ในข้อมูลโดยใช้ฟังก์ชันของ
drop_dependency_violationsSemPyสําหรับแต่ละค่าของตัวแปรที่กําหนด ทํางาน
drop_dependency_violationsโดยการเบิกค่าที่บ่อยที่สุดของตัวแปรพึ่งพาและทิ้งแถวทั้งหมดที่มีค่าอื่น ๆ คุณควรใช้การดําเนินการนี้เฉพาะเมื่อคุณมั่นใจว่าวิทยาการศึกษาทางสถิตินี้จะนําไปสู่ผลลัพธ์ที่ถูกต้องสําหรับข้อมูลของคุณ มิฉะนั้น คุณควรเขียนโค้ดของคุณเองเพื่อจัดการการละเมิดที่ตรวจพบตามความจําเป็นdrop_dependency_violationsเรียกใช้ฟังก์ชันบนZIPคอลัมน์ และCITY:providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')แสดงรายการการละเมิดการขึ้นต่อกันระหว่าง
ZIPและCITY:providers_clean.list_dependency_violations('ZIP', 'CITY')รหัสแสดงรายการว่างเปล่าเพื่อระบุว่า ไม่มีการละเมิดฟังก์ชันของ CITY - > ZIP
เนื้อหาที่เกี่ยวข้อง
ดูบทช่วยสอนอื่น ๆ สําหรับลิงก์ความหมาย / SemPy:
- บทช่วยสอน: วิเคราะห์การขึ้นต่อกันของฟังก์ชันในแบบจําลองความหมายตัวอย่าง
- บทช่วยสอน: แยกและคํานวณหน่วยวัด Power BI จากสมุดบันทึก Jupyter
- บทช่วยสอน: ค้นหาความสัมพันธ์ในแบบจําลองความหมายโดยใช้ลิงก์ความหมาย
- บทช่วยสอน: ค้นหาความสัมพันธ์ใน ชุดข้อมูล Synthea โดยใช้ลิงก์แสดงความหมาย
- บทช่วยสอน: ตรวจสอบข้อมูลโดยใช้ SemPy และความคาดหวังที่ยิ่งใหญ่ (GX)