หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
ในบทช่วยสอนนี้ คุณจะได้เรียนรู้วิธีการดําเนินการวิเคราะห์ข้อมูลเชิงสํารวจ (EDA) เพื่อตรวจสอบและตรวจสอบข้อมูลในขณะที่สรุปคุณลักษณะที่สําคัญผ่านการใช้เทคนิคการแสดงผลข้อมูลด้วยภาพ
คุณจะใช้ seabornไลบรารีการแสดงภาพข้อมูล Python ที่มีอินเทอร์เฟซระดับสูงสําหรับการสร้างวิชวลบน dataframes และอาร์เรย์ สําหรับข้อมูลเพิ่มเติมเกี่ยวกับ seabornดูที่ Seaborn: การแสดงภาพข้อมูลทางสถิติ
นอกจากนี้คุณยังจะใช้ Data Wranglerซึ่งเป็นเครื่องมือที่ใช้สมุดบันทึกที่มอบประสบการณ์การใช้งานอันดื่มด่ําให้กับคุณเพื่อดําเนินการวิเคราะห์ข้อมูลและการทําความสะอาดแบบสํารวจ
ขั้นตอนหลักในบทช่วยสอนนี้คือ:
- อ่านข้อมูลที่จัดเก็บจากตารางเดลต้าในเลคเฮาส์
- แปลง Spark DataFrame เป็น Pandas DataFrame ซึ่งไลบรารีการแสดงภาพข้อมูล python รองรับ
- ใช้ Data Wrangler เพื่อดําเนินการทําความสะอาดและแปลงข้อมูลเริ่มต้น
- ทําการวิเคราะห์ข้อมูลการสํารวจโดยใช้
seaborn
ข้อกําหนดเบื้องต้น
รับ การสมัครใช้งาน Microsoft Fabric หรือลงทะเบียนสําหรับ Microsoft Fabric รุ่นทดลองใช้ฟรี
ลงชื่อเข้าใช้ Microsoft Fabric
สลับไปยัง Fabric โดยใช้ตัวสลับประสบการณ์ที่ด้านซ้ายล่างของโฮมเพจของคุณ
นี่คือส่วนที่ 2 จาก 5 ในชุดบทช่วยสอน เมื่อต้องการทําบทช่วยสอนนี้ให้เสร็จสมบูรณ์ ก่อนอื่นให้ทําให้เสร็จสมบูรณ์:
ติดตามพร้อมกับในสมุดบันทึก
2-explore-cleanse-data.ipynb คือสมุดบันทึกที่มาพร้อมกับบทช่วยสอนนี้
เมื่อต้องการเปิดสมุดบันทึกที่มาพร้อมกับบทช่วยสอนนี้ ให้ทําตามคําแนะนําใน เตรียมระบบของคุณสําหรับบทช่วยสอนวิทยาศาสตร์ข้อมูล การนําเข้าสมุดบันทึกไปยังพื้นที่ทํางานของคุณ
ถ้าคุณต้องการคัดลอกและวางโค้ดจากหน้านี้ สร้างสมุดบันทึกใหม่
ตรวจสอบให้แน่ใจว่า แนบ lakehouse เข้ากับ สมุดบันทึกก่อนที่คุณจะเริ่มเรียกใช้โค้ด
สําคัญ
แนบเลคเฮ้าส์เดียวกับที่คุณใช้ในตอนที่ 1
อ่านข้อมูลดิบจากเลคเฮ้าส์
อ่านข้อมูลดิบจากส่วน Files ของเลคเฮ้าส์ คุณได้อัปโหลดข้อมูลนี้ในสมุดบันทึกก่อนหน้าแล้ว ตรวจสอบให้แน่ใจว่าคุณได้แนบ lakehouse เดียวกันกับที่คุณใช้ในตอนที่ 1 กับสมุดบันทึกนี้ก่อนที่คุณจะเรียกใช้โค้ดนี้
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
สร้าง DataFrame ของ pandas จากชุดข้อมูล
แปลง Spark DataFrame เป็น pandas DataFrame เพื่อให้ง่ายต่อการประมวลผลและแสดงภาพ
df = df.toPandas()
แสดงข้อมูลดิบ
สํารวจข้อมูลดิบด้วย displayทําสถิติพื้นฐานบางอย่างและแสดงมุมมองแผนภูมิ โปรดทราบว่าก่อนอื่นคุณต้องนําเข้าไลบรารีที่จําเป็น เช่น Numpy, Pnadas, Seaborn, และ Matplotlib สําหรับการวิเคราะห์ข้อมูลและการแสดงภาพ
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
# Code generated by Data Wrangler for pandas DataFrame
def clean_data(df):
# Drop duplicate rows in columns: 'CustomerId', 'RowNumber'
df = df.drop_duplicates(subset=['CustomerId', 'RowNumber'])
# Drop rows with missing data across all columns
df = df.dropna()
# Drop columns: 'CustomerId', 'RowNumber', 'Surname'
df = df.drop(columns=['CustomerId', 'RowNumber', 'Surname'])
return df
df_clean = clean_data(df.copy())
df_clean.head()
ใช้ Data Wrangler เพื่อดําเนินการทําความสะอาดข้อมูลเริ่มต้น
ในการสํารวจและแปลงดาต้าเฟรมของ pandas ในสมุดบันทึกของคุณ ให้เปิดใช้ Data Wrangler โดยตรงจากสมุดบันทึก
โน้ต
ไม่สามารถเปิด Data Wrangler ได้ในขณะที่เคอร์เนลสมุดบันทึกไม่ว่าง การดําเนินการเซลล์จะต้องเสร็จสมบูรณ์ก่อนที่จะเปิดใช้งาน Data Wrangler
- ภายใต้ริบบอนสมุดบันทึก แท็บ ข้อมูล ให้เลือก เปิดใช้ข้อมูล Wrangler คุณจะเห็นรายการของดาต้าเฟรมของ pandas ที่เปิดใช้งานซึ่งพร้อมสําหรับการแก้ไข
- เลือก DataFrame ที่คุณต้องการเปิดใน Data Wrangler เนื่องจากสมุดบันทึกนี้มี DataFrame เดียวเท่านั้น
dfให้เลือกdf

ข้อมูล Wrangler เปิดใช้งานและสร้างภาพรวมเชิงพรรณาของข้อมูลของคุณ ตารางตรงกลางแสดงแต่ละคอลัมน์ข้อมูล แผง สรุป
สกรีนช็อต 
การดําเนินการแต่ละรายการที่คุณสามารถทําได้ในเรื่องของการคลิก อัปเดตการแสดงผลข้อมูลในแบบเรียลไทม์ และสร้างโค้ดที่คุณสามารถบันทึกลงในสมุดบันทึกของคุณเป็นฟังก์ชันที่นํากลับมาใช้ใหม่ได้
ส่วนที่เหลือของส่วนนี้แนะนําขั้นตอนในการทําความสะอาดข้อมูลด้วย Data Wrangler
ทิ้งแถวที่ซ้ํากัน
บนแผงด้านซ้ายคือรายการของการดําเนินการ (เช่น ค้นหาและแทนที่รูปแบบ สูตร, ตัวเลข) ที่คุณสามารถทําได้ในชุดข้อมูล
ขยาย ค้นหาและแทนที่ และเลือก ลบแถวที่ซ้ํากัน
สกรีนช็อต

แผงจะปรากฏขึ้นเพื่อให้คุณเลือกรายการของคอลัมน์ที่คุณต้องการเปรียบเทียบเพื่อกําหนดแถวที่ซ้ํากัน เลือก RowNumber
และ CustomerId ในแผงตรงกลางคือตัวอย่างของผลลัพธ์ของการดําเนินการนี้ ภายใต้ตัวอย่างเป็นรหัสที่จะดําเนินการ ในอินสแตนซ์นี้ ข้อมูลดูเหมือนจะไม่เปลี่ยนแปลง แต่เนื่องจากคุณกําลังดูมุมมองที่ถูกตัดทอน คุณควรใช้การดําเนินการนี้ต่อไป
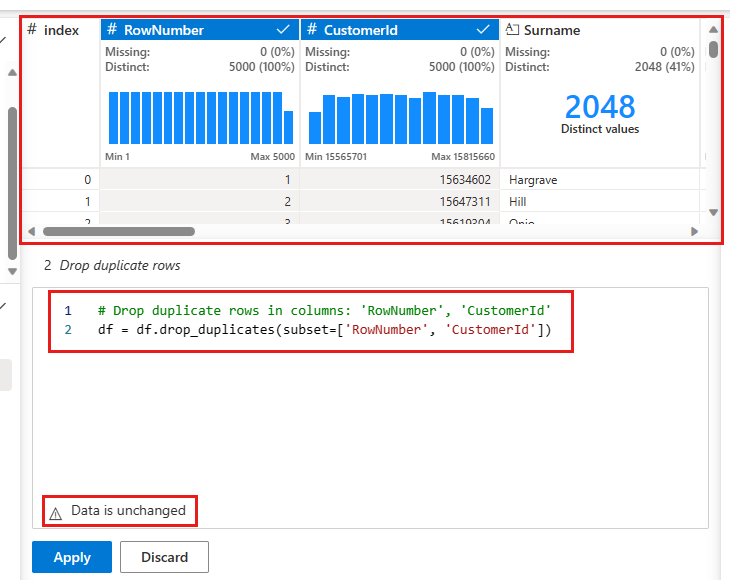
เลือก ใช้ (ที่ด้านข้างหรือด้านล่าง) เพื่อไปยังขั้นตอนถัดไป

ทิ้งแถวที่มีข้อมูลที่ขาดหายไป
ใช้ Data Wrangler เพื่อปล่อยแถวที่มีข้อมูลที่ขาดหายไปในทุกคอลัมน์
เลือก ปล่อยค่าที่หายไป จาก ค้นหาและแทนที่
เลือก เลือก ทั้งหมด จากคอลัมน์เป้าหมาย
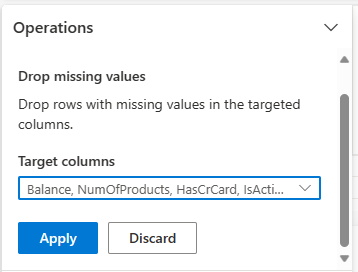
เลือก ใช้ เพื่อไปยังขั้นตอนถัดไป

ปล่อยคอลัมน์
ใช้ Data Wrangler เพื่อวางคอลัมน์ที่คุณไม่ต้องการ
ขยาย Schema
และเลือกคอลัมน์ดรอป เลือก
RowNumber CustomerId นามสกุลคอลัมน์เหล่านี้จะปรากฏเป็นสีแดงในการแสดงตัวอย่าง เพื่อแสดงว่ามีการเปลี่ยนแปลงโดยโค้ด (ในกรณีนี้จะลดลง) 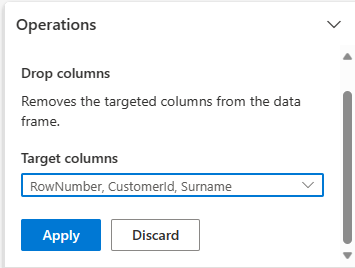
เลือก ใช้ เพื่อไปยังขั้นตอนถัดไป

เพิ่มรหัสลงในสมุดบันทึก
แต่ละครั้งที่คุณเลือก ใช้ขั้นตอนใหม่จะถูกสร้างขึ้นในขั้นตอนการทําความสะอาด แผงที่ด้านล่างซ้าย ที่ด้านล่างของแผง เลือก รหัสตัวอย่างสําหรับขั้นตอนทั้งหมด เพื่อดูชุดของขั้นตอนที่แยกต่างหากทั้งหมด
เลือก เพิ่มรหัสลงในสมุดบันทึก ที่ด้านบนซ้ายเพื่อปิด Data Wrangler และเพิ่มรหัสโดยอัตโนมัติ เพิ่มรหัสลงในสมุดบันทึก ครอบโค้ดในฟังก์ชัน แล้วเรียกใช้ฟังก์ชัน

ปลาย
โค้ดที่สร้างขึ้นโดย Data Wrangler จะไม่ถูกนําไปใช้จนกว่าคุณจะเรียกใช้เซลล์ใหม่ด้วยตนเอง
ถ้าคุณไม่ได้ใช้ Data Wrangler คุณสามารถใช้เซลล์โค้ดถัดไปนี้ได้แทน
รหัสนี้คล้ายกับรหัสที่สร้างโดย Data Wrangler แต่เพิ่มในอาร์กิวเมนต์ inplace=True ไปยังแต่ละขั้นตอนที่สร้างขึ้น โดยการตั้งค่า inplace=Truepandas จะเขียนทับ DataFrame ต้นฉบับแทนการผลิต DataFrame ใหม่เป็นเอาต์พุต
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
สํารวจข้อมูล
แสดงข้อมูลสรุปและการแสดงภาพของข้อมูลที่ได้รับการทําความสะอาดแล้ว
กําหนดแอตทริบิวต์จัดกลุ่ม ตัวเลข และเป้าหมาย
ใช้รหัสนี้เพื่อกําหนดแอตทริบิวต์จัดกลุ่ม ตัวเลข และเป้าหมาย
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
ข้อมูลสรุปห้าตัวเลข
แสดงข้อมูลสรุปแบบห้าตัวเลข (คะแนนต่ําสุด คะแนนแรก ควอร์ไทล์ ค่ามัธยฐาน ควอร์ไทล์ที่สาม คะแนนสูงสุด) สําหรับแอตทริบิวต์ตัวเลข โดยใช้แผนภูมิกล่อง
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
กราฟ 
การกระจายของลูกค้าที่ออกจากงานและไม่มี
แสดงการกระจายของลูกค้าที่ออกจากระบบเทียบกับลูกค้าที่ไม่ได้รับการรับรองทั่วทั้งแอตทริบิวต์ประเภท
df_clean['Exited'] = df_clean['Exited'].astype(str)
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
df_clean['Exited'] = df_clean['Exited'].astype(str)
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
print(ind, item)
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
df_clean['Exited'] = df_clean['Exited'].astype(int)

การกระจายของแอตทริบิวต์ตัวเลข
แสดงการกระจายความถี่ของแอตทริบิวต์ตัวเลขโดยใช้ฮิสโทแกรม
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()
กราฟ 
ดําเนินการวิศวกรรมคุณลักษณะ
ดําเนินการวิศวกรรมคุณลักษณะเพื่อสร้างแอตทริบิวต์ใหม่ตามแอตทริบิวต์ปัจจุบัน:
df_clean['Tenure'] = df_clean['Tenure'].astype(int)
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
ใช้ Data Wrangler เพื่อดําเนินการเข้ารหัสอย่างหนึ่งร้อน
Data Wrangler ยังสามารถใช้เพื่อดําเนินการเข้ารหัสแบบหนึ่งร้อนได้ เมื่อต้องการทําเช่นนั้น ให้เปิด Data Wrangler อีกครั้ง ในครั้งนี้ ให้เลือกข้อมูล df_clean
- ขยาย สูตร และเลือก การเข้ารหัสอย่างหนึ่งร้อน
- แผงจะปรากฏขึ้นเพื่อให้คุณเลือกรายการคอลัมน์ที่คุณต้องการทําการเข้ารหัสแบบฮอตหนึ่งครั้ง เลือก
ภูมิศาสตร์และเพศ
คุณสามารถคัดลอกโค้ดที่สร้างขึ้น ปิด Data Wrangler เพื่อกลับไปยังสมุดบันทึกจากนั้นวางลงในเซลล์ใหม่ได้ หรือเลือก เพิ่มรหัสลงในสมุดบันทึก ที่ด้านบนซ้ายเพื่อปิด Data Wrangler และเพิ่มรหัสโดยอัตโนมัติ
ถ้าคุณไม่ได้ใช้ Data Wrangler คุณสามารถใช้เซลล์โค้ดถัดไปแทนได้:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
for column in ['Geography', 'Gender']:
insert_loc = df_clean.columns.get_loc(column)
df_clean = pd.concat([df_clean.iloc[:,:insert_loc], pd.get_dummies(df_clean.loc[:, [column]]), df_clean.iloc[:,insert_loc+1:]], axis=1)
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
ข้อมูลสรุปของการสังเกตการณ์จากการวิเคราะห์ข้อมูลการสํารวจ
- ลูกค้าส่วนใหญ่มาจากฝรั่งเศสเปรียบเทียบกับสเปนและเยอรมนี ในขณะที่ประเทศสเปนมีอัตราการเลิกใช้บริการต่ําที่สุดเมื่อเทียบกับประเทศฝรั่งเศสและเยอรมนี
- ลูกค้าส่วนใหญ่มีบัตรเครดิต
- มีลูกค้าที่มีอายุและคะแนนเครดิตมากกว่า 60 ปีขึ้นไปต่ํากว่า 400 ตามลําดับ แต่ไม่ถือว่าเป็นค่าผิดปกติ
- ลูกค้าน้อยมากมีผลิตภัณฑ์ของธนาคารมากกว่าสองรายการ
- ลูกค้าที่ไม่ได้ใช้งานมีอัตราการเลิกใช้บริการที่สูงกว่า
- ดูเหมือนว่าเพศและระยะเวลาการครอบครองจะไม่มีผลกระทบต่อการตัดสินใจของลูกค้าในการปิดบัญชีธนาคาร
สร้างตารางส่วนที่แตกต่างสําหรับข้อมูลที่ทําความสะอาดแล้ว
คุณจะใช้ข้อมูลนี้ในสมุดบันทึกถัดไปของชุดข้อมูลนี้
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
ขั้นตอนถัดไป
ฝึกและลงทะเบียนแบบจําลองการเรียนรู้ของเครื่องด้วยข้อมูลนี้: