หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
Power Automate ช่วยให้ผู้ใช้สามารถอ่าน แยก และจัดการข้อมูลภายในไฟล์ผ่านการรู้จำอักขระด้วยแสง (OCR)
ในการสร้างโปรแกรม OCR และแยกข้อความจากรูปภาพและเอกสาร ให้ใช้การดำเนินการ แยกข้อความด้วย OCR ตัวอย่างต่อไปนี้จะแยกข้อความจากรูปภาพที่ระบุทั้งหมด
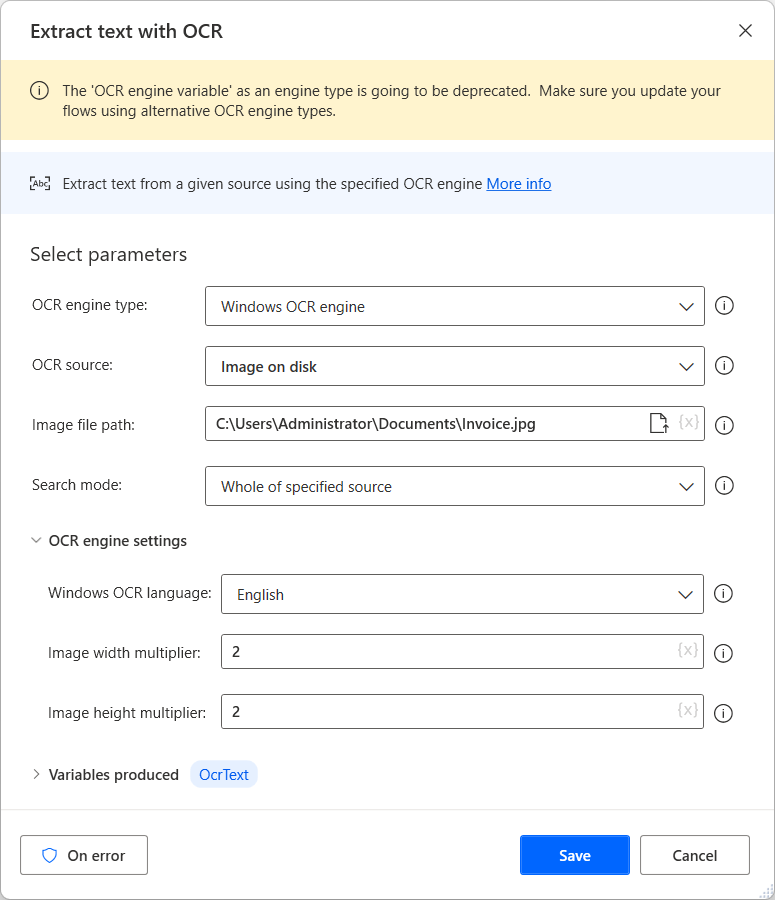
การดำเนินการของ OCR ทั้งหมดสามารถสร้างตัวแปรของโปรแกรม OCR ใหม่หรือใช้ตัวแปรที่มีอยู่ คุณสามารถใช้ตัวแปรโปรแกรม OCR ที่มีอยู่ในการดำเนินการใดๆ ที่มีความสามารถของ OCR
Power Automate รองรับโปรแกรม Windows OCR และโปรแกรม Tesseract ในการกำหนดค่าโปรแกรม OCR ที่เลือก ให้ไปที่ การตั้งค่าโปรแกรม OCR ของการดำเนินการที่เหมาะสม ตัวเลือกที่มีอยู่รวมถึงภาษาและตัวคูณความกว้างและความสูงของรูปภาพ
หมายเหตุ
- โปรแกรม OCR ที่มีอยู่ทั้งหมดได้รับการติดตั้งไว้ล่วงหน้าใน Power Automate และทำงานภายในเครื่องโดยไม่ต้องเชื่อมต่อกับระบบคลาวด์ อย่างไรก็ตาม คุณอาจต้องดาวน์โหลดชุดภาษาหรือไฟล์ข้อมูลเพื่อแยกข้อความในภาษาเฉพาะ
- ตัวคูณรูปภาพจะเพิ่มขนาดรูปภาพเพื่อให้การค้นหาและการแยกข้อความมีประสิทธิภาพมากขึ้น การตั้งค่าที่มากกว่าสามอาจทำให้ได้ผลลัพธ์ที่ผิดพลาด
ใช้โปรแกรม Windows OCR
โปรแกรม OCR เริ่มต้นใน Power Automate คือโปรแกรม Windows OCR ในการแยกข้อความโดยใช้โปรแกรม Windows OCR คุณต้องติดตั้งชุดภาษาที่เหมาะสมสำหรับภาษาที่คุณต้องการแยก
หากไม่ได้ติดตั้งชุดภาษาที่เหมาะสม Power Automate จะส่งข้อผิดพลาดที่แจ้งให้คุณติดตั้ง ในการค้นหาข้อมูลเพิ่มเติมเกี่ยวกับการดาวน์โหลดและติดตั้งชุดภาษา ให้ไปที่ ชุดภาษาสำหรับ Windows
หลังจากติดตั้งชุดภาษาที่เหมาะสมแล้ว ให้ขยาย การตั้งค่าเอ็นจิน OCR ของการดำเนินการของ OCR และเลือกภาษาที่คุณต้องการ โปรแกรม Windows OCR รองรับ 25 ภาษา รวมถึง ภาษาจีน (ตัวย่อและตัวเต็ม) เช็ก เดนมาร์ก ดัตช์ อังกฤษ ฟินแลนด์ ฝรั่งเศส เยอรมัน กรีก ฮังการี อิตาลี ญี่ปุ่น เกาหลี นอร์เวย์ โปแลนด์ โปรตุเกส โรมาเนีย รัสเซีย เซอร์เบีย (ซิริลลิกและละติน) สโลวัก สเปน สวีเดน และตุรกี
ใช้โปรแกรม Tesseract OCR
หมายเหตุ
ในการใช้โปรแกรม Tesseract OCR ตรวจสอบให้แน่ใจว่า CPU ของเครื่องรองรับชุดคำสั่ง AVX2
นอกเหนือจากโปรแกรม Windows OCR แล้ว Power Automate ยังรองรับโปรแกรม Tesseract โปรแกรมนี้สามารถแยกข้อความในห้าภาษาโดยไม่ต้องกำหนดค่าเพิ่มเติม: อังกฤษ เยอรมัน สเปน ฝรั่งเศส และอิตาลี
หากต้องการแยกข้อความในภาษานอกรายการดังกล่าว ให้เปิดใช้งานตัวเลือก ใช้ภาษาอื่น ใน การตั้งค่าโปรแกรม OCR ของการดำเนินการของ OCR เมื่อเปิดใช้งานตัวเลือกนี้ การดำเนินการจะแสดงพารามิเตอร์อีกสองรายการ: ฟิลด์ ตัวย่อภาษา และ เส้นทางข้อมูลภาษา
ฟิลด์ ตัวย่อภาษา ระบุกับโปรแกรมว่าต้องค้นหาภาษาใดระหว่าง OCR ฟิลด์ พาธข้อมูลภาษา มีไฟล์ข้อมูลภาษา (.traineddata) ที่ใช้ในการฝึกอบรมโปรแกรม OCR คุณสามารถค้นหาไฟล์ข้อมูลภาษาสำหรับภาษาที่มีทั้งหมดได้ใน ที่เก็บ GitHub นี้
คุณยังสามารถใช้โปรแกรม Tesseract ยังสามารถใช้เพื่อแยกข้อความจากเอกสารหลายภาษาได้ด้วย ในการค้นหาข้อมูลเพิ่มเติมเกี่ยวกับการแยกข้อความจากเอกสารหลายภาษา ให้ไปที่ ดำเนินการ OCR ในเอกสารหลายภาษา
ถ้าข้อความบนหน้าจอ (OCR)
ทำเครื่องหมายจุดเริ่มต้นของบล็อกการดำเนินการตามเงื่อนไข โดยขึ้นอยู่กับว่าข้อความที่ให้มานั้นปรากฏบนหน้าจอหรือไม่ โดยใช้ OCR
พารามิเตอร์อินพุต
| อาร์กิวเมนต์ | ระบุหรือไม่ก็ได้ | ยอมรับ | ค่าตามค่าเริ่มต้น | คำอธิบาย |
|---|---|---|---|---|
| If text | ไม่พร้อมใช้งาน | มีอยู่ ไม่มีอยู่ | มีอยู่ | ระบุว่าจะตรวจสอบว่ามีข้อความอยู่หรือไม่ บนแหล่งที่มาที่จะวิเคราะห์ |
| ประเภทโปรแกรม OCR | ไม่ | โปรแกรม Windows OCR, โปรแกรม Tesseract, ตัวแปรโปรแกรม OCR | ตัวแปรโปรแกรม OCR | ชนิดโปรแกรม OCR ที่จะใช้ เลือกโปรแกรม OCR ที่กำหนดค่าไว้ล่วงหน้า หรือตั้งค่าใหม่ |
| ตัวแปรโปรแกรม OCR | ไม่ | OCREngineObject | โปรแกรมที่จะใช้สำหรับการดำเนินการของ OCR | |
| Text to find | ไม่ | ค่าข้อความ | ข้อความที่จะค้นหาในแหล่งที่มาที่ระบุ | |
| Is regular expression | ไม่พร้อมใช้งาน | ค่าแบบบูลีน | เท็จ | ระบุว่าจะใช้นิพจน์ทั่วไปเพื่อค้นหาข้อความที่ระบุหรือไม่ |
| Search for text on | ไม่พร้อมใช้งาน | ทั้งหน้าจอ หน้าต่างเบื้องหน้า | หน้าจอทั้งหมด | ระบุว่าจะค้นหาข้อความที่ระบุบนหน้าจอที่มองเห็นทั้งหมด หรือเพียงแค่หน้าต่างเบื้องหน้า |
| Search mode | ไม่ระบุ | แหล่งที่มาที่ระบุทั้งหมด ภูมิภาคย่อยเฉพาะ ภูมิภาคย่อยที่สัมพันธ์กับรูปภาพ | แหล่งที่มาที่ระบุทั้งหมด | ระบุว่าจะสแกนทั้งหน้าจอ (หรือหน้าต่าง) ขอบเขตย่อยที่แคบลง |
| รูปภาพ | ไม่ | รายการ ของ รูปภาพ | ภาพที่ระบุขอบเขตย่อย (สัมพันธ์กับมุมบนซ้ายของภาพ) ที่จะสแกนหาข้อความที่ให้มา | |
| X1 | ใช่ | ค่าตัวเลข | พิกัด X เริ่มต้นของขอบเขตย่อยที่จะสแกนสำหรับข้อความที่ให้มา | |
| Tolerance | ใช่ | ค่าตัวเลข | 10 | ระบุว่ารูปภาพที่ค้นหาอาจแตกต่างจากรูปภาพที่เลือกไว้ในตอนแรกมากเพียงใด |
| Y1 | ใช่ | ค่าตัวเลข | พิกัด Y เริ่มต้นของขอบเขตย่อยที่จะสแกนสำหรับข้อความที่ให้มา | |
| X1 | ใช่ | ค่าตัวเลข | พิกัด X เริ่มต้นของขอบเขตย่อยซึ่งสัมพันธ์กับภาพที่ระบุที่จะสแกนหาข้อความที่ให้มา | |
| X2 | ใช่ | ค่าตัวเลข | พิกัด X สิ้นสุดของขอบเขตย่อยที่จะสแกนสำหรับข้อความที่ให้มา | |
| Y1 | ใช่ | ค่าตัวเลข | พิกัด Y เริ่มต้นของขอบเขตย่อยซึ่งสัมพันธ์กับภาพที่ระบุที่จะสแกนหาข้อความที่ให้มา | |
| Y2 | ใช่ | ค่าตัวเลข | พิกัด Y สิ้นสุดของขอบเขตย่อยที่จะสแกนสำหรับข้อความที่ให้มา | |
| X2 | ใช่ | ค่าตัวเลข | พิกัด X สิ้นสุดของขอบเขตย่อยซึ่งสัมพันธ์กับภาพที่ระบุที่จะสแกนหาข้อความที่ให้มา | |
| Y2 | ใช่ | ค่าตัวเลข | พิกัด Y สิ้นสุดของขอบเขตย่อยซึ่งสัมพันธ์กับภาพที่ระบุที่จะสแกนหาข้อความที่ให้มา | |
| ภาษา Windows OCR | ไม่ระบุ | ภาษาจีน (ตัวย่อ) จีน (เต็ม) เช็ก เดนมาร์ก ดัตช์ อังกฤษ ฟินแลนด์ ฝรั่งเศส เยอรมัน กรีก ฮังการี อิตาลี ญี่ปุ่น เกาหลี นอร์เวย์ โปแลนด์ โปรตุเกส โรมาเนีย รัสเซีย เซอร์เบีย (ซิริลลิก) เซอร์เบีย (ละติน) สโลวัก สเปน สวีเดน และตุรกี | อังกฤษ | ภาษาของข้อความที่โปรแกรม Windows OCR ตรวจพบ |
| ใช้ภาษาอื่น | ไม่ระบุ | ค่าแบบบูลีน | เท็จ | ระบุว่าจะใช้ภาษาที่ไม่ได้กำหนดไว้ในฟิลด์ 'ภาษา Tesseract' หรือไม่ |
| ภาษา Tesseract | ไม่ระบุ | อังกฤษ เยอรมัน สเปน ฝรั่งเศส อิตาลี | อังกฤษ | ภาษาของข้อความที่โปรแกรม Tesseract ตรวจพบ |
| ตัวย่อภาษา | ไม่ | ค่าข้อความ | ตัวย่อของ Tesseract ของภาษาที่ใช้: ตัวอย่างเช่น หากข้อมูลเป็น 'eng.traineddata' ให้ตั้งค่าพารามิเตอร์นี้เป็น 'eng' | |
| พาธข้อมูลภาษา | ไม่ | ค่าข้อความ | พาธของโฟลเดอร์ที่เก็บข้อมูล Tesseract ของภาษาที่ระบุ | |
| ตัวคูณความกว้างของภาพ | ไม่ | ค่าตัวเลข | 1 | ตัวคูณความกว้างของรูปภาพ |
| ตัวคูณความสูงของรูปภาพ | ไม่ | ค่าตัวเลข | 1 | ตัวคูณความสูงของรูปภาพ |
| อัลกอริทึมการจับคู่รูปภาพ | ไม่ระบุ | พื้นฐาน ขั้นสูง | พื้นฐาน | อัลกอริทึมรูปภาพใดที่จะใช้ในการค้นหารูปภาพ |
หมายเหตุ
- โปรแกรมนิพจน์ทั่วไปของ Power Automate คือ .NET ในการค้นหาข้อมูลเพิ่มเติมเกี่ยวกับนิพจน์ทั่วไป ให้ไปที่ ภาษานิพจน์ทั่วไป - ข้อมูลอ้างอิงด่วน
- ตัวเลือก ตัวแปรโปรแกรม OCR มีการวางแผนสำหรับการเลิกใช้งาน
ตัวแปรที่สร้าง
| อาร์กิวเมนต์ | ชนิด | คำอธิบาย |
|---|---|---|
| LocationOfTextFoundX | ค่าตัวเลข | พิกัด X ของจุดที่ข้อความปรากฏบนหน้าจอ ถ้าดำเนินการค้นหาในหน้าต่างเบื้องหน้า พิกัดที่ส่งคืนจะสัมพันธ์กับมุมบนซ้ายของหน้าต่าง |
| LocationOfTextFoundY | ค่าตัวเลข | พิกัด X ของจุดที่ข้อความปรากฏบนหน้าจอ ถ้าดำเนินการค้นหาในหน้าต่างเบื้องหน้า พิกัดที่ส่งคืนจะสัมพันธ์กับมุมบนซ้ายของหน้าต่าง |
ข้อยกเว้น
| ข้อยกเว้น | คำอธิบาย |
|---|---|
| ไม่สามารถตรวจสอบว่ามีข้อความอยู่ในโหมดแบบไม่โต้ตอบหรือไม่ | ระบุว่าไม่สามารถตรวจสอบข้อความบนหน้าจอได้ เมื่ออยู่ในโหมดแบบไม่โต้ตอบ |
| พิกัดของขอบเขตย่อยไม่ถูกต้อง | ระบุว่าพิกัดของขอบเขตย่อยที่ระบุไม่ถูกต้อง |
| ไม่สามารถวิเคราะห์ข้อความด้วย OCR | ระบุข้อผิดพลาดที่เกิดขึ้นขณะที่พยายามวิเคราะห์ข้อความโดยใช้ OCR |
| ไม่สามารถสร้างโปรแกรม OCR ได้ | ระบุข้อผิดพลาดที่เกิดขึ้นขณะที่พยายามสร้างโปรแกรม OCR |
| ไม่มีโฟลเดอร์พาธข้อมูลอยู่ | ระบุว่าไม่มีโฟลเดอร์ที่ระบุสำหรับข้อมูลภาษา |
| ไม่ได้ติดตั้งชุดภาษา Windows ที่เลือกบนเครื่อง | ระบุว่าไม่ได้ติดตั้งชุดภาษา Windows ที่เลือกบนเครื่อง |
| โปรแกรม OCR ไม่ได้ทำงานอยู่ | ระบุว่าโปรแกรม OCR ไม่ได้ทำงานอยู่ |
รอข้อความบนหน้าจอ (OCR)
รอจนกระทั่งข้อความเฉพาะปรากฏขึ้น/หายไปบนหน้าจอ หน้าต่างเบื้องหน้า หรือสัมพันธ์กับภาพบนหน้าจอหรือหน้าต่างเบื้องหน้า โดยใช้ OCR
พารามิเตอร์อินพุต
| อาร์กิวเมนต์ | ระบุหรือไม่ก็ได้ | ยอมรับ | ค่าตามค่าเริ่มต้น | คำอธิบาย |
|---|---|---|---|---|
| Wait for text to | ไม่พร้อมใช้งาน | ปรากฏขึ้น หายไป | ปรากฏ | ระบุว่าจะรอให้ข้อความปรากฏหรือหายไป |
| ประเภทโปรแกรม OCR | ไม่ | โปรแกรม Windows OCR, โปรแกรม Tesseract, ตัวแปรโปรแกรม OCR | ตัวแปรโปรแกรม OCR | ชนิดโปรแกรม OCR ที่จะใช้ เลือกโปรแกรม OCR ที่กำหนดค่าไว้ล่วงหน้า หรือตั้งค่าใหม่ |
| ตัวแปรโปรแกรม OCR | ไม่ | OCREngineObject | โปรแกรมที่จะใช้สำหรับการดำเนินการของ OCR | |
| Text to find | ไม่ | ค่าข้อความ | ข้อความที่จะค้นหาในแหล่งที่มาที่ระบุ | |
| Is regular expression | ไม่พร้อมใช้งาน | ค่าแบบบูลีน | เท็จ | ระบุว่าจะใช้นิพจน์ทั่วไปเพื่อค้นหาข้อความที่ระบุหรือไม่ |
| Search for text on | ไม่พร้อมใช้งาน | ทั้งหน้าจอ หน้าต่างเบื้องหน้า | หน้าจอทั้งหมด | ระบุว่าจะค้นหาข้อความที่ระบุบนหน้าจอที่มองเห็นทั้งหมด หรือเพียงแค่หน้าต่างเบื้องหน้า |
| Search mode | ไม่ระบุ | แหล่งที่มาที่ระบุทั้งหมด ภูมิภาคย่อยเฉพาะ ภูมิภาคย่อยที่สัมพันธ์กับรูปภาพ | แหล่งที่มาที่ระบุทั้งหมด | ระบุว่าจะสแกนทั้งหน้าจอ (หรือหน้าต่าง) ขอบเขตย่อยที่แคบลง |
| รูปภาพ | ไม่ | รายการ ของ รูปภาพ | ภาพที่ระบุขอบเขตย่อย (สัมพันธ์กับมุมบนซ้ายของภาพ) ที่จะสแกนหาข้อความที่ให้มา | |
| X1 | ใช่ | ค่าตัวเลข | พิกัด X เริ่มต้นของขอบเขตย่อยที่จะสแกนสำหรับข้อความที่ให้มา | |
| Tolerance | ใช่ | ค่าตัวเลข | 10 | ระบุว่ารูปภาพที่ค้นหาอาจแตกต่างจากรูปภาพที่เลือกไว้ในตอนแรกมากเพียงใด |
| Y1 | ใช่ | ค่าตัวเลข | พิกัด Y เริ่มต้นของขอบเขตย่อยที่จะสแกนสำหรับข้อความที่ให้มา | |
| X1 | ใช่ | ค่าตัวเลข | พิกัด X เริ่มต้นของขอบเขตย่อยซึ่งสัมพันธ์กับภาพที่ระบุที่จะสแกนหาข้อความที่ให้มา | |
| X2 | ใช่ | ค่าตัวเลข | พิกัด X สิ้นสุดของขอบเขตย่อยที่จะสแกนสำหรับข้อความที่ให้มา | |
| Y1 | ใช่ | ค่าตัวเลข | พิกัด Y เริ่มต้นของขอบเขตย่อยซึ่งสัมพันธ์กับภาพที่ระบุที่จะสแกนหาข้อความที่ให้มา | |
| Y2 | ใช่ | ค่าตัวเลข | พิกัด Y สิ้นสุดของขอบเขตย่อยที่จะสแกนสำหรับข้อความที่ให้มา | |
| X2 | ใช่ | ค่าตัวเลข | พิกัด X สิ้นสุดของขอบเขตย่อยซึ่งสัมพันธ์กับภาพที่ระบุที่จะสแกนหาข้อความที่ให้มา | |
| Y2 | ใช่ | ค่าตัวเลข | พิกัด Y สิ้นสุดของขอบเขตย่อยซึ่งสัมพันธ์กับภาพที่ระบุที่จะสแกนหาข้อความที่ให้มา | |
| ภาษา Windows OCR | ไม่ระบุ | ภาษาจีน (ตัวย่อ) จีน (เต็ม) เช็ก เดนมาร์ก ดัตช์ อังกฤษ ฟินแลนด์ ฝรั่งเศส เยอรมัน กรีก ฮังการี อิตาลี ญี่ปุ่น เกาหลี นอร์เวย์ โปแลนด์ โปรตุเกส โรมาเนีย รัสเซีย เซอร์เบีย (ซิริลลิก) เซอร์เบีย (ละติน) สโลวัก สเปน สวีเดน และตุรกี | อังกฤษ | ภาษาของข้อความที่โปรแกรม Windows OCR ตรวจพบ |
| ใช้ภาษาอื่น | ไม่ระบุ | ค่าแบบบูลีน | เท็จ | ระบุว่าจะใช้ภาษาที่ไม่ได้กำหนดไว้ในฟิลด์ 'ภาษา Tesseract' หรือไม่ |
| ภาษา Tesseract | ไม่ระบุ | อังกฤษ เยอรมัน สเปน ฝรั่งเศส อิตาลี | อังกฤษ | ภาษาของข้อความที่โปรแกรม Tesseract ตรวจพบ |
| ตัวย่อภาษา | ไม่ | ค่าข้อความ | ตัวย่อของ Tesseract ของภาษาที่ใช้: ตัวอย่างเช่น หากข้อมูลเป็น 'eng.traineddata' ให้ตั้งค่าพารามิเตอร์นี้เป็น 'eng' | |
| พาธข้อมูลภาษา | ไม่ | ค่าข้อความ | พาธของโฟลเดอร์ที่เก็บข้อมูล Tesseract ของภาษาที่ระบุ | |
| ตัวคูณความกว้างของภาพ | ไม่ | ค่าตัวเลข | 1 | ตัวคูณความกว้างของรูปภาพ |
| ตัวคูณความสูงของรูปภาพ | ไม่ | ค่าตัวเลข | 1 | ตัวคูณความสูงของรูปภาพ |
| อัลกอริทึมการจับคู่รูปภาพ | ไม่ระบุ | พื้นฐาน ขั้นสูง | พื้นฐาน | อัลกอริทึมรูปภาพใดที่จะใช้ในการค้นหารูปภาพ |
| ล้มเหลวด้วยข้อผิดพลาดการหมดเวลา | ไม่ระบุ | ค่าแบบบูลีน | เท็จ | ระบุว่าคุณต้องการให้การดำเนินการรออย่างไม่มีกำหนดหรือล้มเหลวหลังจากช่วงเวลาที่กำหนด |
หมายเหตุ
- โปรแกรมนิพจน์ทั่วไปของ Power Automate คือ .NET ในการค้นหาข้อมูลเพิ่มเติมเกี่ยวกับนิพจน์ทั่วไป ให้ไปที่ ภาษานิพจน์ทั่วไป - ข้อมูลอ้างอิงด่วน
- ตัวเลือก ตัวแปรโปรแกรม OCR มีการวางแผนสำหรับการเลิกใช้งาน
ตัวแปรที่สร้าง
| อาร์กิวเมนต์ | ชนิด | คำอธิบาย |
|---|---|---|
| LocationOfTextFoundX | ค่าตัวเลข | พิกัด X ของจุดที่ข้อความปรากฏบนหน้าจอ ถ้าดำเนินการค้นหาในหน้าต่างเบื้องหน้า พิกัดที่ส่งคืนจะสัมพันธ์กับมุมบนซ้ายของหน้าต่าง |
| LocationOfTextFoundY | ค่าตัวเลข | พิกัด X ของจุดที่ข้อความปรากฏบนหน้าจอ ถ้าดำเนินการค้นหาในหน้าต่างเบื้องหน้า พิกัดที่ส่งคืนจะสัมพันธ์กับมุมบนซ้ายของหน้าต่าง |
ข้อยกเว้น
| ข้อยกเว้น | คำอธิบาย |
|---|---|
| ไม่สามารถตรวจสอบว่ามีข้อความอยู่ในโหมดแบบไม่โต้ตอบหรือไม่ | ระบุว่าไม่สามารถตรวจสอบข้อความบนหน้าจอได้ เมื่ออยู่ในโหมดแบบไม่โต้ตอบ |
| พิกัดของขอบเขตย่อยไม่ถูกต้อง | ระบุว่าพิกัดของขอบเขตย่อยที่ระบุไม่ถูกต้อง |
| ไม่สามารถวิเคราะห์ข้อความด้วย OCR | ระบุข้อผิดพลาดที่เกิดขึ้นขณะที่พยายามวิเคราะห์ข้อความโดยใช้ OCR |
| ไม่สามารถสร้างโปรแกรม OCR ได้ | ระบุข้อผิดพลาดที่เกิดขึ้นขณะที่พยายามสร้างโปรแกรม OCR |
| ไม่มีโฟลเดอร์พาธข้อมูลอยู่ | ระบุว่าไม่มีโฟลเดอร์ที่ระบุสำหรับข้อมูลภาษา |
| ไม่ได้ติดตั้งชุดภาษา Windows ที่เลือกบนเครื่อง | ระบุว่าไม่ได้ติดตั้งชุดภาษา Windows ที่เลือกบนเครื่อง |
| โปรแกรม OCR ไม่ได้ทำงานอยู่ | ระบุว่าโปรแกรม OCR ไม่ได้ทำงานอยู่ |
| ข้อผิดพลาดการหมดเวลา | แสดงว่าการดำเนินการล้มเหลวหลังจากช่วงเวลาที่กำหนด |
แยกข้อความด้วย OCR
แยกข้อความจากแหล่งที่มาที่ระบุโดยใช้โปรแกรม OCR ที่ให้มา
พารามิเตอร์อินพุต
| อาร์กิวเมนต์ | ระบุหรือไม่ก็ได้ | ยอมรับ | ค่าตามค่าเริ่มต้น | คำอธิบาย |
|---|---|---|---|---|
| โปรแกรม OCR | ไม่ | โปรแกรม Windows OCR, โปรแกรม Tesseract, ตัวแปรโปรแกรม OCR | ตัวแปรโปรแกรม OCR | ชนิดโปรแกรม OCR ที่จะใช้ เลือกโปรแกรม OCR ที่กำหนดค่าไว้ล่วงหน้า หรือตั้งค่าใหม่ |
| ตัวแปรโปรแกรม OCR | ไม่ | OCREngineObject | โปรแกรมที่จะใช้สำหรับการดำเนินการของ OCR | |
| OCR source | ไม่พร้อมใช้งาน | หน้าจอ หน้าต่างเบื้องหน้า ภาพบนดิสก์ | หน้าจอ | แหล่งที่มาของรูปภาพเพื่อทำการดำเนินการของ OCR |
| Image file path | ไม่ | แฟ้ม | พาธของรูปภาพเพื่อทำการดำเนินการของ OCR | |
| Search mode | ไม่พร้อมใช้งาน | แหล่งที่มาที่ระบุทั้งหมด ภูมิภาคย่อยเฉพาะ ภูมิภาคย่อยที่สัมพันธ์กับรูปภาพ | แหล่งที่มาที่ระบุทั้งหมด | โหมดที่เลือกสำหรับการดำเนินการของ OCR |
| รูปภาพ | ไม่ | รายการ ของ รูปภาพ | รูปภาพที่จะใช้เพื่อจำกัดขอบเขตการสแกนให้แคบลงไปยังพื้นที่ย่อยที่สัมพันธ์กับรูปภาพที่ระบุ | |
| Tolerance | ใช่ | ค่าตัวเลข | 10 | ระบุว่ารูปภาพอาจแตกต่างจากรูปภาพที่เลือกไว้ในตอนแรกมากเพียงใด |
| X1 | ใช่ | ค่าตัวเลข | พิกัด X เริ่มต้นของขอบเขตย่อยเพื่อจำกัดการสแกนให้แคบลง | |
| X2 | ใช่ | ค่าตัวเลข | พิกัด X สิ้นสุดของขอบเขตย่อยเพื่อจำกัดการสแกนให้แคบลง | |
| Y1 | ใช่ | ค่าตัวเลข | พิกัด Y เริ่มต้นของขอบเขตย่อยเพื่อจำกัดการสแกนให้แคบลง | |
| Y2 | ใช่ | ค่าตัวเลข | พิกัด Y สิ้นสุดของขอบเขตย่อยเพื่อจำกัดการสแกนให้แคบลง | |
| ภาษา Windows OCR | ไม่ระบุ | ภาษาจีน (ตัวย่อ) จีน (เต็ม) เช็ก เดนมาร์ก ดัตช์ อังกฤษ ฟินแลนด์ ฝรั่งเศส เยอรมัน กรีก ฮังการี อิตาลี ญี่ปุ่น เกาหลี นอร์เวย์ โปแลนด์ โปรตุเกส โรมาเนีย รัสเซีย เซอร์เบีย (ซิริลลิก) เซอร์เบีย (ละติน) สโลวัก สเปน สวีเดน และตุรกี | อังกฤษ | ภาษาของข้อความที่โปรแกรม Windows OCR ตรวจพบ |
| ใช้ภาษาอื่น | ไม่ระบุ | ค่าแบบบูลีน | เท็จ | ระบุว่าจะใช้ภาษาที่ไม่ได้กำหนดไว้ในฟิลด์ 'ภาษา Tesseract' หรือไม่ |
| ภาษา Tesseract | ไม่ระบุ | อังกฤษ เยอรมัน สเปน ฝรั่งเศส อิตาลี | อังกฤษ | ภาษาของข้อความที่โปรแกรม Tesseract ตรวจพบ |
| ตัวย่อภาษา | ไม่ | ค่าข้อความ | ตัวย่อของ Tesseract ของภาษาที่ใช้: ตัวอย่างเช่น หากข้อมูลเป็น 'eng.traineddata' ให้ตั้งค่าพารามิเตอร์นี้เป็น 'eng' | |
| พาธข้อมูลภาษา | ไม่ | ค่าข้อความ | พาธของโฟลเดอร์ที่เก็บข้อมูล Tesseract ของภาษาที่ระบุ | |
| ตัวคูณความกว้างของภาพ | ไม่ | ค่าตัวเลข | 1 | ตัวคูณความกว้างของรูปภาพ |
| ตัวคูณความสูงของรูปภาพ | ไม่ | ค่าตัวเลข | 1 | ตัวคูณความสูงของรูปภาพ |
| รอให้ภาพปรากฏ | ไม่ระบุ | ค่าแบบบูลีน | จริง | ระบุว่าจะรอหรือไม่ เพื่อให้ภาพปรากฏบนหน้าจอหรือหน้าต่างเบื้องหน้า |
| การหมดเวลา | ไม่ | ค่าตัวเลข | 5 | ระบุเวลาที่จะรอให้การดำเนินการเสร็จสิ้น ก่อนที่การดำเนินการจะล้มเหลว |
| อัลกอริทึมการจับคู่รูปภาพ | ไม่ระบุ | พื้นฐาน ขั้นสูง | พื้นฐาน | อัลกอริทึมรูปภาพใดที่จะใช้ในการค้นหารูปภาพ |
หมายเหตุ
ตัวเลือก ตัวแปรโปรแกรม OCR มีการวางแผนสำหรับการเลิกใช้งาน
ตัวแปรที่สร้าง
| อาร์กิวเมนต์ | ชนิด | คำอธิบาย |
|---|---|---|
| OcrText | ค่าข้อความ | ผลลัพธ์หลังการแยกข้อความ |
ข้อยกเว้น
| ข้อยกเว้น | คำอธิบาย |
|---|---|
| ไม่สามารถแยกข้อความด้วย OCR | ระบุข้อผิดพลาดที่เกิดขึ้นขณะที่พยายามแยกข้อความด้วย OCR จากแหล่งที่มาที่ระบุ |
| ไม่พบไฟล์รูปภาพ | ระบุว่าไม่มีไฟล์บนพาธที่กำหนด |
| ไม่พบรูปภาพจุดสังเกต | ระบุว่าไม่มีรูปภาพจุดสังเกตอยู่ |
| ไม่สามารถรับข้อความจากหน้าจอในโหมดแบบไม่โต้ตอบ | ระบุว่าไม่สามารถรับข้อความจากหน้าจอได้ เมื่ออยู่ในโหมดแบบไม่โต้ตอบ |
| ไม่สามารถสร้างโปรแกรม OCR ได้ | ระบุข้อผิดพลาดที่เกิดขึ้นขณะที่พยายามสร้างโปรแกรม OCR |
| ไม่มีโฟลเดอร์พาธข้อมูลอยู่ | ระบุว่าไม่มีโฟลเดอร์ที่ระบุสำหรับข้อมูลภาษา |
| ไม่ได้ติดตั้งชุดภาษา Windows ที่เลือกบนเครื่อง | ระบุว่าไม่ได้ติดตั้งชุดภาษา Windows ที่เลือกบนเครื่อง |
| โปรแกรม OCR ไม่ได้ทำงานอยู่ | ระบุว่าโปรแกรม OCR ไม่ได้ทำงานอยู่ |