การสุ่มตัวอย่างเส้นความหนาแน่นสูงใน Power BI
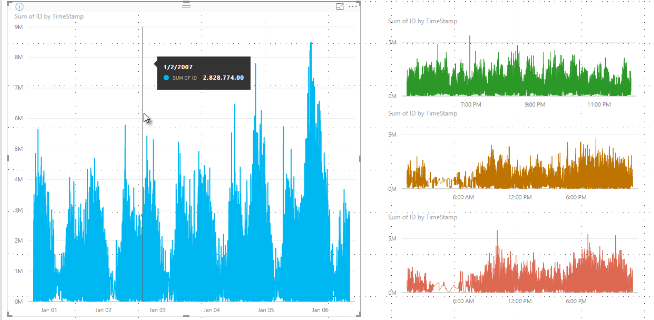
อัลกอริทึมการสุ่มตัวอย่างใน Power BI ช่วยปรับปรุงวิชวลที่สุ่มตัวอย่างข้อมูลที่มีความหนาแน่นสูง ตัวอย่างเช่น คุณอาจสร้างแผนภูมิเส้นจากผลลัพธ์ยอดขายของร้านค้าปลีกของคุณ แต่ละร้านค้ามีมากกว่า 10,000 ใบเสร็จการขายต่อปี แผนภูมิเส้นของข้อมูลดังกล่าวจะสุ่มตัวอย่างข้อมูลจากข้อมูลสําหรับแต่ละร้านค้า และสร้างแผนภูมิเส้นแบบหลายชุดข้อมูลที่แสดงข้อมูลเบื้องต้น ตรวจสอบให้แน่ใจว่าได้เลือกการแสดงที่สื่อความหมายของข้อมูลนั้นเพื่อแสดงให้เห็นว่ายอดขายแตกต่างกันอย่างไรเมื่อเวลาผ่านไป แนวทางปฏิบัตินี้เป็นเรื่องปกติในการแสดงภาพความหนาแน่นสูง รายละเอียดของการสุ่มตัวอย่างข้อมูลความหนาแน่นสูงจะอธิบายไว้ในบทความนี้
หมายเหตุ
อัลกอริทึมการสุ่มตัวอย่างความหนาแน่นสูงที่อธิบายไว้ในบทความนี้ มีทั้งใน Power BI Desktop และบริการของ Power BI
วิธีการทํางานของการสุ่มตัวอย่างเส้นความหนาแน่นสูง
ก่อนหน้านี้ Power BI เลือกคอลเลกชันของจุดข้อมูลตัวอย่างในช่วงทั้งหมดของข้อมูลต้นแบบตามแบบที่กําหนดขึ้น ตัวอย่างเช่น ด้วยข้อมูลความหนาแน่นสูงบนวิชวลที่ครอบคลุมช่วงเวลาหนึ่งปีปฏิทิน อาจมีจุดข้อมูลตัวอย่าง 350 จุดที่แสดงในวิชวล ซึ่งแต่ละจุดข้อมูลถูกเลือกเพื่อให้ได้ช่วงข้อมูลเต็มที่แสดงในวิชวล เพื่อช่วยให้คุณเข้าใจว่าเกิดขึ้นได้อย่างไร สมมติว่า เราลงจุดราคาหุ้นในช่วงเวลาหนึ่งปี และเลือกจุดข้อมูล 365 จุดเพื่อสร้างวิชวลแผนภูมิเส้น นั่นคือหนึ่งจุดข้อมูลสําหรับหนึ่งวัน
ในสถานการณ์นั้น มีค่ามากมายสําหรับราคาหุ้นภายในแต่ละวัน แน่นอนว่ามีค่าสูงสุดและต่ําสุดประจําวัน แต่ค่าเหล่านั้นสามารถเกิดขึ้นได้ตลอดเวลาระหว่างวันเมื่อตลาดหุ้นเปิด สําหรับการสุ่มตัวอย่างของเส้นความหนาแน่นสูง ถ้ามีการสุ่มตัวอย่างข้อมูลเบื้องต้นที่เวลา 10:30 น. และ 12:00 น. ในแต่ละวัน คุณจะได้สแนปช็อตของข้อมูลเบื้องต้น เช่น ราคาที่ 10:30 น. และ 12:00 น. อย่างไรก็ตาม สแนปช็อตอาจไม่จับราคาหุ้นสูงสุดและต่ําสุดตามจริงสําหรับจุดข้อมูลที่เป็นตัวแทนในวันนั้น ในสถานการณ์นั้นและสถานการณ์อื่น ๆ การสุ่มตัวอย่างจะแสดงถึงข้อมูลเบื้องต้น แต่จะอาจไม่จับจุดข้อมูลที่สําคัญเสมอไป ซึ่งในกรณีนี้เป็นการจับข้อมูลสูงสุดและต่ําสุดของราคาหุ้นรายวัน
จากคํานิยาม ข้อมูลความหนาแน่นสูงจะถูกสุ่มตัวอย่างเพื่อสร้างการแสดงภาพได้อย่างรวดเร็วค่อนข้างที่จะตอบสนองต่อการโต้ตอบได้ จุดข้อมูลมากเกินไปบนวิชวลอาจทําให้มันจมลงและขัดข้องจากการมองเห็นของแนวโน้มได้ วิธีที่ใช้สุ่มข้อมูลคือสิ่งที่มาผลักดันการสร้างอัลกอริทึมการสุ่มตัวอย่าง เพื่อสร้างประสบการณ์การแสดงภาพที่ดีที่สุด ใน Power BI Desktop อัลกอริทึมมอบการผสมผสานที่ดีที่สุดระหว่างการตอบสนอง ตัวแทนข้อมูล และการคงจุดข้อมูลที่สําคัญในแต่ละช่วงเวลา
วิธีการทํางานของอัลกอริทึมการสุ่มตัวอย่างของเส้น
อัลกอริทึมสําหรับการสุ่มตัวอย่างเส้นความหนาแน่นสูงพร้อมใช้งานสําหรับวิชวลแผนภูมิเส้นและแผนภูมิพื้นที่ที่มีแกน x แบบต่อเนื่อง
สําหรับวิ ชวลความหนาแน่นสูง Power BI ทําการแบ่งส่วนข้อมูลของคุณเป็นกลุ่มข้อมูลความละเอียดสูงอย่างชาญฉลาด จากนั้นเลือกจุดข้อมูลที่สําคัญเพื่อเป็นตัวแทนสําหรับแต่ละกลุ่ม กระบวนการแบ่งส่วนข้อมูลความละเอียดสูงดําเนินการเพื่อให้แน่ใจว่าผลลัพธ์แผนภูมิที่ได้สามารถแยกความสัมพันธ์ได้ด้วยตาจากจุดข้อมูลพื้นฐานทั้งหมดที่มีให้ แต่จะเร็วกว่าและมีการโต้ตอบได้มากกว่า
ค่าต่ําสุดและสูงสุดสําหรับภาพความหนาแน่นสูงเชิงเส้น
สําหรับการแสดงภาพใด ๆ มีข้อจํากัดดังต่อไปนี้:
3,500 คือจํานวนจุด ข้อมูลสูงสุดที่แสดง บนวิชวลส่วนใหญ่ โดยไม่คํานึงถึงจํานวนของจุดข้อมูลเบื้องต้นหรือชุดข้อมูล โปรดดู ข้อยกเว้น ในรายการต่อไปนี้ ตัวอย่างเช่น ถ้าคุณมี 10 ชุดข้อมูลที่แต่ละชุดข้อมูลมี 350 จุดข้อมูล วิชวลถึงขีดจํากัดสูงสุดของจุดข้อมูลโดยรวมแล้ว ถ้าคุณมีหนึ่งชุดข้อมูล ชุดข้อมูลดังกล่าวอาจมีจุดข้อมูลสูงสุด 3,500 จุดได้ถ้าอัลกอริทึมเข้าขึ้้นว่าการสุ่มตัวอย่างที่ดีที่สุดสําหรับข้อมูลเบื้องต้น
มีชุดข้อมูลได้สูงสุด 60 ชุด สําหรับวิชวลใด ๆ ถ้าคุณมีชุดข้อมูลมากกว่า 60 ชุด ให้แบ่งชุดข้อมูลและสร้างวิชวลหลายวิชวลด้วยชุดข้อมูล 60 ชุดหรือน้อยกว่านั้นในแต่ละวิชวล การใช้ ตัว แบ่งส่วนข้อมูลเพื่อแสดงเฉพาะบางเซกเมนต์ของข้อมูลเท่านั้นเป็นแนวทางปฏิบัติที่ดี ตัวอย่างเช่น ถ้าคุณกําลังแสดงประเภทย่อยทั้งหมดในคําอธิบายแผนภูมิ คุณสามารถใช้ตัวแบ่งส่วนข้อมูลเพื่อกรองตามประเภทโดยรวมบนหน้ารายงานเดียวกันได้
จํานวนขีดจํากัดสูงสุดของข้อมูลจะสูงกว่าสําหรับประเภทวิชวลต่อไปนี้ ซึ่งมี ข้อยกเว้น ที่ขีดจํากัดจุดข้อมูล 3,500 รายการ:
- 150,000 จุดข้อมูลสูงสุดสําหรับวิชวล R
- 30,000 จุดข้อมูลสําหรับวิชวล Azure Map
- 10,000 จุดข้อมูลสําหรับการกําหนดค่าแผนภูมิกระจายบางรายการ (ค่าเริ่มต้นแผนภูมิกระจายเป็น 3500)
- 3,500 สําหรับภาพอื่นๆ ทั้งหมดที่ใช้การสุ่มตัวอย่างความหนาแน่นสูง วิชวลอื่น ๆ บางอย่างอาจแสดงภาพข้อมูลเพิ่มเติม แต่พวกเขาจะไม่ใช้การสุ่มตัวอย่าง
พารามิเตอร์เหล่านี้มีไว้เพื่อให้แน่ใจว่าวิชวลใน Power BI Desktop แสดงได้อย่างรวดเร็ว ตอบสนองต่อการโต้ตอบกับผู้ใช้และไม่ทําให้เกิดค่าใช้จ่ายที่เกินควรในการคํานวณบนคอมพิวเตอร์สําหรับภาพดังกล่าว
ประเมินจุดข้อมูลที่เป็นตัวแทนสําหรับวิชวลเส้นความหนาแน่นสูง
เมื่อมีจํานวนจุดข้อมูลเบื้องต้นเกินกว่าจุดข้อมูลสูงสุดที่สามารถแสดงได้ในวิชวล กระบวนการที่เรียกว่า การจัด ช่องเก็บจะเริ่มต้นขึ้น การจัดช่องเก็บจะรวมกลุ่มข้อมูลเบื้องต้นเป็นกลุ่ม ๆ ที่เรียกว่า ช่องเก็บ และจะปรับปรุงช่องเก็บเหล่านั้นซ้ํา ๆ
อัลกอริทึมสร้างช่องเก็บมากที่สุดเท่าที่เป็นไปได้เพื่อสร้างส่วนประกอบที่ดีที่สุดสําหรับภาพ ภายในแต่ละช่องเก็บ อัลกอริทึมค้นหาค่าข้อมูลต่ําสุดและสูงสุด เพื่อให้แน่ใจว่าค่าที่สําคัญและค่าที่มีนัยสําคัญ เช่น ค่าผิดปกติจะถูกบันทึกไว้และแสดงในวิชวล จากผลลัพธ์ของการจัดช่องเก็บและการประเมินที่ตามมาของข้อมูลโดย Power BI ความละเอียดต่ําสุดสําหรับแกน x ของวิชวลจะถูกกําหนดขึ้นเพื่อให้แน่ใจว่าวิชวลมีความละเอียดสูงสุด
ดังที่กล่าวถึงก่อนหน้านี้ ส่วนประกอบขั้นต่ําสําหรับแต่ละชุดข้อมูลคือ 350 จุดและสูงสุดคือ 3,500 สําหรับภาพส่วนใหญ่ ข้อยกเว้นจะแสดงอยู่ในย่อหน้าก่อนหน้า
แต่ละช่องเก็บจะแสดงด้วยจุดข้อมูลสองจุด ซึ่งจะกลายเป็นจุดข้อมูลที่เป็นตัวแทนของช่องเก็บข้อมูลในภาพ จุดข้อมูลเป็นค่าสูงสุดและต่ําสุดสําหรับช่องเก็บนั้น โดยการเลือกค่าสูงสุดและต่ําสุด กระบวนการการจัดช่องเก็บช่วยให้แน่ใจว่ามีการจับค่าสูงหรือค่าต่ําสุดที่สําคัญหรือที่มีนัยสําคัญในภาพ
ถ้านี่ฟังเหมือนว่าการวิเคราะห์จํานวนมาก มีเพื่อให้แน่ใจว่าได้จับค่าที่ผิดปกติและแสดงอย่างถูกต้องในวิชวล คุณก็ถูกต้อง นั่นคือเหตุผลที่แท้จริงสําหรับอัลกอริทึมและการจัดช่องเก็บ
คําแนะนําเครื่องมือและการสุ่มตัวอย่างเส้นความหนาแน่นสูง
สิ่งสําคัญคือต้องทราบว่า กระบวนการการจัดช่องนี้ ให้ค่าต่ําสุดและสูงสุดที่อยู่ในช่องเก็บได้จัดเก็บและแสดง ซึ่งอาจส่งผลต่อการแสดงข้อมูลของคําแนะนําเครื่องมือ เมื่อคุณโฮเวอร์เหนือจุดข้อมูล เพื่ออธิบายว่าเกิดขึ้นได้อย่างไรและทําไม กลับไปดูตัวอย่างของเราเกี่ยวกับราคาหุ้น
สมมติว่า คุณกําลังสร้างวิชวลจากราคาหุ้น และคุณกําลังเปรียบเทียบหุ้นสองตัว ซึ่งใช้ การสุ่มตัวอย่างความหนาแน่นสูงเหมือนกันทั้งคู่ ข้อมูลพื้นฐานสําหรับแต่ละชุดข้อมูลมีจุดข้อมูลจํานวนมาก ตัวอย่างเช่น บางทีคุณอาจจับราคาหุ้นแต่ละวินาทีของวัน อัลกอริทึมการสุ่มตัวอย่างเส้นความหนาแน่นสูง ดําเนินการกับช่องเก็บสําหรับแต่ละชุดข้อมูลอิสระจากกัน
ตอนนี้สมมติว่าราคาหุ้นตัวแรกกระโดดขึ้นไปที่เวลา 12:02 น. จากนั้นราคาก็ร่วงลงอีก 10 วินาทีต่อมา นั่นเป็นจุดข้อมูลที่สําคัญจุดหนึ่ง เมื่อทําการจัดช่องเก็บสําหรับหุ้นดังกล่าว ค่าสูงสุดที่ 12:02 จะเป็นจุดข้อมูลที่เป็นตัวแทนสําหรับช่องเก็บนั้น
อย่างไรก็ตาม สําหรับหุ้นตัวที่สอง 12:02 ไม่ใช่ค่าสูงสุดหรือต่ําสุดในช่องเก็บที่รวมเวลานั้น บางทีค่าสูงสุดและต่ําสุดสําหรับช่องเก็บนั้นที่รวมเวลา 12:02 น. อาจเกิดขึ้นสามนาทีในภายหลัง ในสถานการณ์นั้น เมื่อมีการสร้างแผนภูมิเส้นและคุณเลื่อนไปเหนือ 12:02 คุณจะเห็นค่าในคําแนะนําเครื่องมือสําหรับหุ้นตัวแรก ทั้งนี้เนื่องจากกระโดดไปที่ 12:02 และค่านั้นถูกเลือกเป็นจุดข้อมูลสูงของช่องเก็บนั้น อย่างไรก็ตาม คุณจะไม่เห็นค่าใด ๆ ในคําแนะนําเครื่องมือที่ 12:02 สําหรับหุ้นตัวที่สอง นั่นเป็นเพราะหุ้นตัวที่สองไม่มีค่าสูงสุดหรือต่ําสุดสําหรับช่องเก็บที่รวม 12:02 ดังนั้นจึงไม่มีข้อมูลที่จะแสดงสําหรับหุ้นตัวที่สองที่เวลา 12:02 ทําให้ไม่มีข้อมูลเคล็ดลับเครื่องมือที่จะแสดง
สถานการณ์นี้จะเกิดขึ้นบ่อยครั้งกับคําแนะนําเครื่องมือ ค่าสูงสุดและต่ําสุดสําหรับช่องเก็บเฉพาะอาจไม่ตรงกับจุดค่าแกน x ที่ปรับมาตราส่วนเท่า ๆ กันอย่างสมบูรณ์แบบ และคําแนะนําเครื่องมือจะไม่แสดงค่า
วิธีการเปิดใช้งานการสุ่มตัวอย่างเส้นความหนาแน่นสูง
ตามค่าเริ่มต้น อัลกอริทึมจะเป็นเปิด เพื่อเปลี่ยนการตั้งค่านี้ ไปที่ บานหน้าต่างการจัดรูปแบบ ใน การ์ดทั่วไป และตามแนวด้านล่าง คุณจะเห็นตัว เลื่อนการสุ่ม ตัวอย่างความหนาแน่นสูง เลือกแถบเลื่อนเพื่อสลับเปิดหรือปิด

ข้อควรพิจารณาและข้อจำกัด
อัลกอริทึมสําหรับการสุ่มตัวอย่างเส้นความหนาแน่นสูงคือการพัฒนาที่สําคัญสําหรับ Power BI แต่ยังมีข้อควรพิจารณาที่คุณจําเป็นต้องทราบเมื่อทํางานกับค่าและข้อมูลที่มีความหนาแน่นสูง
เนื่องด้วยส่วนประกอบและกระบวนการ จัดช่องเก็บที่เพิ่มขึ้น คําแนะนํา เครื่องมืออาจแสดงค่าเฉพาะเมื่อข้อมูลที่เป็นตัวแทนได้รับการจัดแนวด้วยเคอร์เซอร์ของคุณ สําหรับข้อมูลเพิ่มเติม โปรดดูส่วน คําแนะนําเครื่องมือและการสุ่มตัวอย่าง เส้นความหนาแน่นสูง ในบทความนี้
เมื่อขนาดของแหล่งข้อมูลโดยรวมมีขนาดใหญ่เกินไป อัลกอริทึมจะกําจัดชุดข้อมูล (องค์ประกอบคําอธิบายแผนภูมิ) เพื่อให้สอดคล้องกับข้อจํากัดสูงสุดของการนําเข้าข้อมูล
- ในสถานการณ์นี้ อัลกอริทึมจะจัดเรียงชุดข้อมูลคําอธิบายแผนภูมิตามลําดับตัวอักษร โดยเริ่มจากรายการองค์ประกอบคําอธิบายแผนภูมิตามลําดับตัวอักษรจนกว่าจะถึงขีดจํากัดสูงสุดในการนําเข้าข้อมูล และจะไม่นําเข้าชุดข้อมูลเพิ่มเติม
เมื่อชุดข้อมูลเบื้องต้นมีชุดข้อมูลมากกว่า 60 ชุด จํานวนสูงสุดของชุดข้อมูล อัลกอริทึมจะเรียงลําดับชุดข้อมูลตามลําดับตัวอักษร และกําจัดชุดข้อมูลที่มากกว่า 60 ชุดตามลําดับตัวอักษร
ถ้าค่าในข้อมูลไม่ใช่ชนิด ตัวเลข หรือ วันที่/เวลา Power BI จะไม่ใช้อัลกอริทึมและจะแปลงกลับเป็นอัลกอริทึมการสุ่มตัวอย่างที่ไม่ใช่ความหนาแน่นสูงก่อนหน้านี้
การตั้งค่าแสดงรายการที่ไม่มีข้อมูลไม่ได้รับการสนับสนุนด้วยอัลกอริทึม
ไม่สนับสนุนอัลกอริทึมเมื่อใช้การเชื่อมต่อสดไปยังแบบจําลองที่โฮสต์ใน SQL Server Analysis Services เวอร์ชัน 2016 หรือเวอร์ชันก่อนหน้า ได้รับการสนับสนุนในแบบจําลองที่โฮสต์ใน Power BI หรือ Azure Analysis Services