การสุ่มตัวอย่างความหนาแน่นสูงในแผนภูมิกระจาย Power BI
อัลกอริทึมการสุ่มตัวอย่างของ Power BI ช่วยปรับปรุงวิธีที่แผนภูมิกระจายแสดงข้อมูลที่มีความหนาแน่นสูง
ตัวอย่างเช่น คุณอาจสร้างแผนภูมิกระจายจากกิจกรรมการขายขององค์กรของคุณ โดยร้านค้าแต่ละแห่งจะมีหลายหมื่นจุดข้อมูลในแต่ละปี แผนภูมิกระจายของข้อมูลดังกล่าวจะสุ่มตัวอย่างข้อมูลจากตัวแทนที่มีความหมายของข้อมูลนั้นเพื่อแสดงว่าการขายเกิดขึ้นเมื่อเวลาผ่านไปอย่างไร รายละเอียดของการสุ่มตัวอย่างข้อมูลความหนาแน่นสูงจะอธิบายไว้ในบทความนี้

หมายเหตุ
อัลกอริทึมการสุ่มตัวอย่างความหนาแน่นสูงที่อธิบายไว้ในบทความนี้ มีอยู่ในแผนภูมิกระจายสําหรับทั้ง Power BI Desktop และบริการของ Power BI
วิธีการทํางานของแผนภูมิกราฟจุดที่มีความหนาแน่นสูง
ก่อนหน้านี้ Power BI เลือกคอลเลกชันของจุดข้อมูลตัวอย่างในช่วงทั้งหมดของข้อมูลต้นแบบตามแบบที่กําหนดขึ้นเพื่อสร้างแผนภูมิกราฟจุด โดยเฉพาะ Power BI จะเลือกแถวแรกและแถวสุดท้ายของข้อมูลในชุดข้อมูลแผนภูมิกระจาย จากนั้นแบ่งแถวที่เหลือเท่า ๆ กัน เพื่อให้จุดข้อมูลทั้งหมด 3,500 จุดถูกลงจุดบนแผนภูมิกราฟจุด ตัวอย่างเช่น ถ้าตัวอย่างที่มีแถว 35,000 แถว แถวแรกและแถวสุดท้ายถูกเลือกสําหรับการลงจุด จากนั้นทุก ๆ แถวที่สิบจะมีการลงจุดด้วย (35,000 / 10 = ทุกแถวที่สิบ = 3,500 จุดข้อมูล) และก่อนหน้านี้ ค่า null หรือจุดที่ไม่สามารถลงจุดได้ เช่นค่าข้อความ ในชุดข้อมูลจะไม่ถูกแสดง ดังนั้นจะไม่ถูกพิจารณาเมื่อสร้างวิชวล ด้วยการสุ่มตัวอย่างดังกล่าว ความหนาแน่นที่มองเห็นของแผนภูมิกระจายจะขึ้นอยู่กับตัวแทนของจุดข้อมูล ดังนั้นความหนาแน่นของภาพโดยนัยเป็นสถานการณ์ของจุดที่เลือกมาเป็นตัวอย่าง ไม่ใช่คอลเลกชันทั้งหมดของข้อมูลเบื้องต้น
เมื่อคุณเปิดใช้งาน การสุ่มตัวอย่างความหนาแน่นสูง Power BI ประมวลผลอัลกอริทึมที่ลบจุดที่ซ้อนกัน และตรวจสอบว่าจุดบนภาพสามารถเข้าถึงได้เมื่อมีการโต้ตอบการแสดงผลด้วยภาพ อัลกอริทึมยังทําให้แน่ใจอีกว่า จุดทั้งหมดในชุดข้อมูลถูกแสดงในวิชวล โดยให้บริบทที่เป็นความหมายของจุดที่เลือก แทนที่จะลงจุดตัวอย่างที่เป็นตัวแทน
จากคํานิยาม ข้อมูลความหนาแน่นสูงจะถูกสุ่มตัวอย่างเพื่อสร้างการแสดงภาพที่ตอบสนองต่อการโต้ตอบได้ จุดข้อมูลมากเกินไปบนวิชวลสามารถทําให้ช้าลงและดึงความสนใจจากแนวโน้มได้ วิธีที่ใช้สุ่มข้อมูล ขับเคลื่อนการสร้างอัลกอริทึมการสุ่มตัวอย่าง เพื่อสร้างประสบการณ์การแสดงภาพที่ดีที่สุด และทําให้แน่ใจว่าข้อมูลทั้งหมดถูกแสดง ใน Power BI อัลกอริทึมได้รับการปรับปรุงเพื่อให้ได้การผสมผสานที่ดีที่สุด ระหว่างการตอบสนอง, ตัวแทนข้อมูล และการคงจุดข้อมูลที่สําคัญในชุดข้อมูลโดยรวม
หมายเหตุ
แผนภูมิกระจายใช้ อัลกอริทึมการ สุ่มตัวอย่างความหนาแน่นสูง เหมาะที่สุดที่จะลงจุดบนวิชวลสี่เหลี่ยมจตุรัส เช่นแผนภูมิกระจายทั้งหลาย
วิธีการทํางานของอัลกอริทึมการสุ่มตัวอย่างแผนภูมิกระจาย
อัลกอริทึมสําหรับการ สุ่มตัวอย่าง ความหนาแน่นสูงสําหรับแผนภูมิกระจาย ใช้วิธีที่จับภาพและแทนข้อมูลเบื้องต้นได้อย่างมีประสิทธิภาพขึ้น และกําจัดจุดที่ซ้อนทับกัน อัลกอริทึมเริ่มต้นด้วยรัศมีขนาดเล็กสําหรับแต่ละจุดข้อมูล ซึ่งเป็นขนาดวงกลมภาพสําหรับจุดที่ระบุบนการแสดงภาพ จากนั้นเพิ่มรัศมีของจุดข้อมูลทั้งหมด เมื่อจุดข้อมูลสองจุดหรือมากกว่าทับซ้อนกัน วงกลมเดียวของขนาดรัศมีที่เพิ่มขึ้นแสดงจุดข้อมูลที่ซ้อนกันเหล่านั้น อัลกอริทึมยังเพิ่มรัศมีของจุดข้อมูลอย่างต่อเนื่องจนกว่าค่ารัศมีแสดงจํานวนจุดข้อมูลอย่างสมเหตุสมผล (3,500) ในแผนภูมิกราฟจุด
วิธีการในอัลกอริทึมนี้ทําให้แน่ใจว่าค่าผิดปกติจะถูกแสดงในวิชวลผลลัพธ์ อัลกอริทึมเคารพมาตราส่วนเมื่อกําหนดการซ้อน เช่นเดียวกับระดับโพเนนเชียลที่ถูกแสดงภาพด้วยความเที่ยงตรงไปยังจุดต้นแบบ
อัลกอริทึมยังรักษารูปร่างโดยรวมของแผนภูมิกระจาย
หมายเหตุ
เมื่อใช้ อัลกอริทึมการ สุ่มตัวอย่างความหนาแน่นสูงสําหรับแผนภูมิ กราฟจุด การแจกจ่าย ที่แม่นยําของข้อมูลเป็นเป้าหมาย ไม่ใช่ ความหนาแน่นของภาพโดยนัย ตัวอย่างเช่น คุณอาจเห็นแผนภูมิกระจายมีวงกลมจํานวนมากที่ทับซ้อนกัน (ความหนาแน่น) ในบางพื้นที่ และลองนึกถึงจุดข้อมูลจํานวนมากที่ต้องทําการคลัสเตอร์ที่นั่น เนื่องจากอัลกอริทึมการสุ่มตัวอย่างความหนาแน่นสูงสามารถใช้วงกลมหนึ่งเพื่อแสดงจุดข้อมูลจํานวนมาก ดังกล่าวโดยนัยความหนาแน่นของภาพหรือ "การคลัสเตอร์" จะไม่แสดงขึ้น เมื่อต้องรับรายละเอียดเพิ่มเติมในพื้นที่ที่กําหนด คุณสามารถใช้ตัวแบ่งส่วนข้อมูลเพื่อขยายได้
นอกจากนี้ จุดข้อมูลที่ไม่สามารถลงจุดได้ เช่น ค่า null หรือค่าข้อความจะถูกละเว้น ดังนั้นค่าอื่นที่สามารถลงจุดได้จะถูกเลือก การดําเนินการนี้ยังช่วยให้แน่ใจว่ามีการเก็บรักษารูปร่างจริงของแผนภูมิกระจายไว้
เมื่อใช้อัลกอริทึมมาตรฐานสําหรับแผนภูมิกระจาย
อาจมีกรณีซึ่ง การสุ่ม ตัวอย่างความหนาแน่นสูงไม่สามารถนําไปใช้ได้กับแผนภูมิกระจาย และอัลกอริทึมเดิมถูกใช้แทน สถานการณ์เหล่านั้นคือ:
ถ้าคุณคลิกขวาที่ค่าภายใต้ ค่า และตั้งค่าเป็น แสดงรายการที่ไม่มีข้อมูลจาก เมนู แผนภูมิกระจายจะแปลงกลับเป็นอัลกอริทึมต้นฉบับ
ค่าใด ๆ ใน เขตข้อมูล Play Axis จะส่งผลให้แผนภูมิกระจายแปลงกลับเป็นอัลกอริทึมต้นฉบับ
ถ้าทั้งแกน X และ Y หายไปจากแผนภูมิกระจาย แผนภูมิแปลงกลับเป็นอัลกอริทึมต้นฉบับ
การใช้เส้นอัตราส่วนในบานหน้าต่างการวิเคราะห์ส่งผลให้แผนภูมิแปลงกลับเป็นอัลกอริทึมต้นฉบับ
วิธีการเปิดใช้งานการสุ่มตัวอย่างความหนาแน่นสูงสําหรับแผนภูมิกระจาย
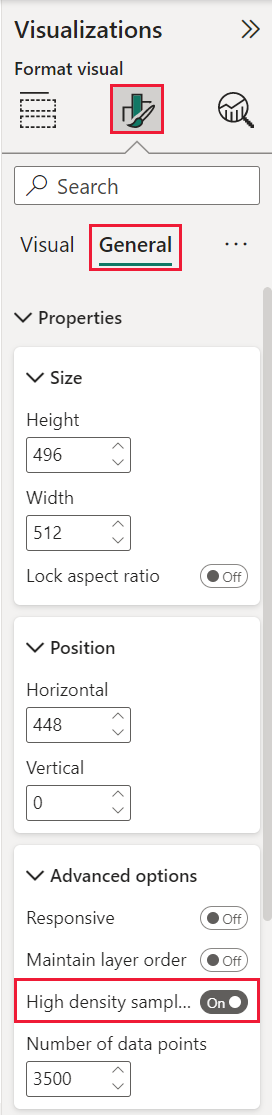
เพื่อสลับการสุ่มตัวอย่างความหนาแน่นสูงเป็นเปิด เลือกแผนภูมิกระจาย ไปที่บานหน้าต่างวิชวลรูปแบบ ขยายการ์ดทั่วไป และใกล้กับด้านล่างของการ์ด เลื่อนตัวเลื่อนการสุ่มตัวอย่างความหนาแน่นสูงให้เป็นเปิด
หมายเหตุ
หลังจากเปิดสวิตช์แล้ว Power BI จะพยายามใช้ อัลกอริทึมการสุ่ม ตัวอย่างความหนาแน่นสูงเมื่อใดก็ตามที่เป็นไปได้ เมื่อไม่สามารถใช้อัลกอริทึมได้ เช่น เมื่อคุณใส่ค่าในแกนเคลื่อนไหว สวิตช์จะยังคงเปิดอยู่ แม้ว่าแผนภูมิจะแปลงกลับเป็นอัลกอริทึมมาตรฐานแล้ว ถ้าคุณลบค่าจาก แกน Play หรือถ้ามีการเปลี่ยนแปลงเงื่อนไขเพื่อให้สามารถใช้อัลกอริทึมการสุ่มตัวอย่างความหนาแน่นสูง แผนภูมิจะใช้การสุ่มตัวอย่างความหนาแน่นสูงโดยอัตโนมัติสําหรับแผนภูมินั้นเนื่องจากคุณลักษณะเปิดใช้งานอยู่
หมายเหตุ
จุดข้อมูลจะถูกจัดกลุ่มหรือเลือกโดยดัชนี การมีคําอธิบายแผนภูมิไม่มีผลต่อการสุ่มตัวอย่างสําหรับอัลกอริทึม ซึ่งจะมีผลต่อการเรียงลําดับของวิชวลเท่านั้น
ข้อควรพิจารณาและข้อจำกัด
อัลกอริทึมการสุ่มตัวอย่างความหนาแน่นสูงเป็นการพัฒนาที่สําคัญสําหรับ Power BI อย่างไรก็ตาม อัลกอริทึมการสุ่มตัวอย่างความหนาแน่นสูง ทํางานกับการเชื่อมต่อแบบสดไปยังแบบจําลองบริการของ Power BI แบบจําลองที่นําเข้า หรือ DirectQuery