หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
This document describes how Data Deduplication works.
How does Data Deduplication work?
Data Deduplication in Windows Server was created with the following two principles:
Optimization should not get in the way of writes to the disk Data Deduplication optimizes data by using a post-processing model. All data is written unoptimized to the disk and then optimized later by Data Deduplication.
Optimization should not change access semantics Users and applications that access data on an optimized volume are completely unaware that the files they are accessing have been deduplicated.
Once enabled for a volume, Data Deduplication runs in the background to:
- Identify repeated patterns across files on that volume.
- Seamlessly move those portions, or chunks, with special pointers called reparse points that point to a unique copy of that chunk.
This occurs in the following four steps:
- Scan the file system for files meeting the optimization policy.

- Break files into variable-size chunks.

- Identify unique chunks.
- Place chunks in the chunk store and optionally compress.
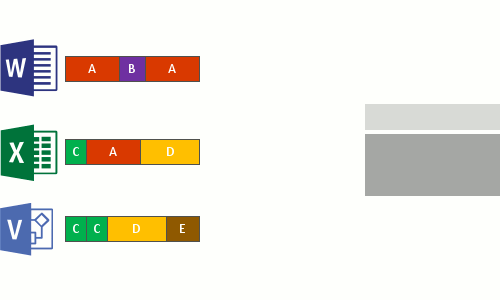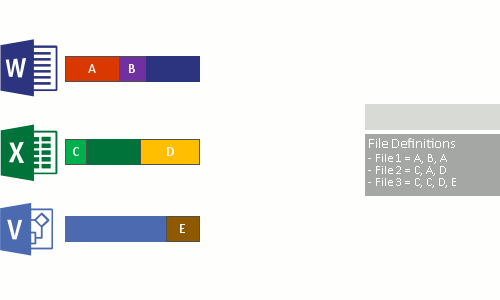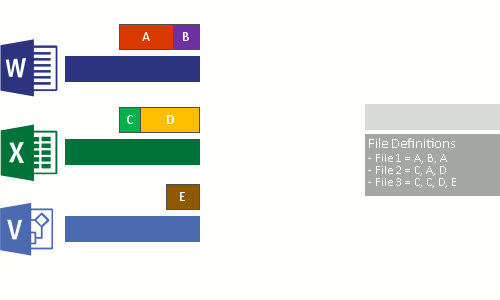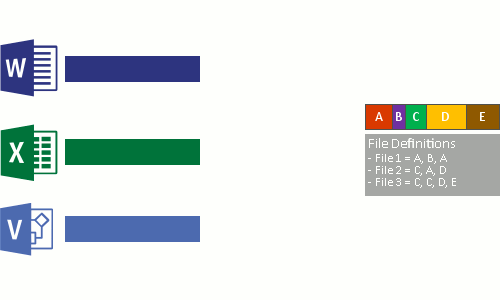
- Replace the original file stream of now optimized files with a reparse point to the chunk store.
When optimized files are read, the file system sends the files with a reparse point to the Data Deduplication file system filter (Dedup.sys). The filter redirects the read operation to the appropriate chunks that constitute the stream for that file in the chunk store. Modifications to ranges of a deduplicated files get written unoptimized to the disk and are optimized by the Optimization job the next time it runs.
Usage Types
The following Usage Types provide reasonable Data Deduplication configuration for common workloads:
| Usage Type | Ideal workloads | What's different |
|---|---|---|
| Default | General purpose file server:
|
|
| Hyper-V | Virtualized Desktop Infrastructure (VDI) servers |
|
| Backup | Virtualized backup applications, such as Microsoft Data Protection Manager (DPM) |
|
Jobs
Data Deduplication uses a post-processing strategy to optimize and maintain a volume's space efficiency.
| Job name | Job descriptions | Default schedule |
|---|---|---|
| Optimization | The Optimization job deduplicates by chunking data on a volume per the volume policy settings, (optionally) compressing those chunks, and storing chunks uniquely in the chunk store. The optimization process that Data Deduplication uses is described in detail in How does Data Deduplication work?. | Once every hour |
| Garbage Collection | The Garbage Collection job reclaims disk space by removing unnecessary chunks that are no longer being referenced by files that have been recently modified or deleted. | Every Saturday at 2:35 AM |
| Integrity Scrubbing | The Integrity Scrubbing job identifies corruption in the chunk store due to disk failures or bad sectors. When possible, Data Deduplication can automatically use volume features (such as mirror or parity on a Storage Spaces volume) to reconstruct the corrupted data. Additionally, Data Deduplication keeps backup copies of popular chunks when they are referenced more than 100 times in an area called the hotspot. | Every Saturday at 3:35 AM |
| Unoptimization | The Unoptimization job, which is a special job that should only be run manually, undoes the optimization done by deduplication and disables Data Deduplication for that volume. | On-demand only |
Data Deduplication terminology
| Term | Definition |
|---|---|
| Chunk | A chunk is a section of a file that has been selected by the Data Deduplication chunking algorithm as likely to occur in other, similar files. |
| Chunk store | The chunk store is an organized series of container files in the System Volume Information folder that Data Deduplication uses to uniquely store chunks. |
| Dedup | An abbreviation for Data Deduplication that's commonly used in PowerShell, Windows Server APIs and components, and the Windows Server community. |
| File metadata | Every file contains metadata that describes interesting properties about the file that are not related to the main content of the file. For instance, Date Created, Last Read Date, Author, etc. |
| File stream | The file stream is the main content of the file. This is the part of the file that Data Deduplication optimizes. |
| File system | The file system is the software and on-disk data structure that the operating system uses to store files on storage media. Data Deduplication is supported on NTFS formatted volumes. |
| File system filter | A file system filter is a plugin that modifies the default behavior of the file system. To preserve access semantics, Data Deduplication uses a file system filter (Dedup.sys) to redirect reads to optimized content completely transparently to the user or application that makes the read request. |
| Optimization | A file is considered optimized (or deduplicated) by Data Deduplication if it has been chunked, and its unique chunks have been stored in the chunk store. |
| Optimization policy | The optimization policy specifies the files that should be considered for Data Deduplication. For example, files may be considered out-of-policy if they are brand new, open, in a certain path on the volume, or a certain file type. |
| Reparse point | A reparse point is a special tag that notifies the file system to pass off I/O to a specified file system filter. When a file's file stream has been optimized, Data Deduplication replaces the file stream with a reparse point, which enables Data Deduplication to preserve the access semantics for that file. |
| Volume | A volume is a Windows construct for a logical storage drive that may span multiple physical storage devices across a one or more servers. Deduplication is enabled on a volume-by-volume basis. |
| Workload | A workload is an application that runs on Windows Server. Example workloads include general purpose file server, Hyper-V, and SQL Server. |
Warning
Unless instructed by authorized Microsoft Support Personnel, do not attempt to manually modify the chunk store. Doing so may result in data corruption or loss.
Frequently asked questions
How does Data Deduplication differ from other optimization products? There are several important differences between Data Deduplication and other common storage optimization products:
How does Data Deduplication differ from Single Instance Store? Single Instance Store, or SIS, is a technology that preceded Data Deduplication and was first introduced in Windows Storage Server 2008 R2. To optimize a volume, Single Instance Store identified files that were completely identical and replaced them with logical links to a single copy of a file that's stored in the SIS common store. Unlike Single Instance Store, Data Deduplication can get space savings from files that are not identical but share many common patterns and from files that themselves contain many repeated patterns. Single Instance Store was deprecated in Windows Server 2012 R2 and removed in Windows Server 2016 in favor of Data Deduplication.
How does Data Deduplication differ from NTFS compression? NTFS compression is a feature of NTFS that you can optionally enable at the volume level. With NTFS compression, each file is optimized individually via compression at write-time. Unlike NTFS compression, Data Deduplication can get spacing savings across all the files on a volume. This is better than NTFS compression because files may have both internal duplication (which is addressed by NTFS compression) and have similarities with other files on the volume (which is not addressed by NTFS compression). Additionally, Data Deduplication has a post-processing model, which means that new or modified files will be written to disk unoptimized and will be optimized later by Data Deduplication.
How does Data Deduplication differ from archive file formats like zip, rar, 7z, cab, etc.? Archive file formats, like zip, rar, 7z, cab, etc., perform compression over a specified set of files. Like Data Deduplication, duplicated patterns within files and duplicated patterns across files are optimized. However, you have to choose the files that you want to include in the archive. Access semantics are different, too. To access a specific file within the archive, you have to open the archive, select a specific file, and decompress that file for use. Data Deduplication operates transparently to users and administrators and requires no manual kick-off. Additionally, Data Deduplication preserves access semantics: optimized files appear unchanged after optimization.
Can I change the Data Deduplication settings for my selected Usage Type? Yes. Although Data Deduplication provides reasonable defaults for Recommended workloads, you might still want to tweak Data Deduplication settings to get the most out of your storage. Additionally, other workloads will require some tweaking to ensure that Data Deduplication does not interfere with the workload.
Can I manually run a Data Deduplication job? Yes, all Data Deduplication jobs may be run manually. This may be desirable if scheduled jobs did not run due to insufficient system resources or because of an error. Additionally, the Unoptimization job can only be run manually.
Can I monitor the historical outcomes of Data Deduplication jobs? Yes, all Data Deduplication jobs make entries in the Windows Event Log.
Can I change the default schedules for the Data Deduplication jobs on my system? Yes, all schedules are configurable. Modifying the default Data Deduplication schedules is particularly desirable to ensure that the Data Deduplication jobs have time to finish and do not compete for resources with the workload.