Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Scala'da yazılmış Apache Spark uygulamaları geliştirmek ve bunları doğrudan Eclipse IDE'den bir Azure HDInsight Spark kümesine göndermek için Eclipse için Azure Toolkit'te HDInsight Araçları'nı kullanın. HDInsight Araçları eklentisini birkaç farklı yolla kullanabilirsiniz:
- HDInsight Spark kümesinde Scala Spark uygulaması geliştirmek ve göndermek için.
- Azure HDInsight Spark küme kaynaklarınıza erişmek için.
- Scala Spark uygulamasını yerel olarak geliştirmek ve çalıştırmak için.
Önkoşullar
HDInsight üzerinde Apache Spark kümesi. Yönergeler için bkz. Azure HDInsight'ta Apache Spark kümeleri oluşturma.
Eclipse IDE. Bu makalede Java Geliştiricileri için Eclipse IDE kullanılır.
Gerekli eklentileri yükleme
Azure Toolkit for Eclipse'i yükleme
Yükleme yönergeleri için bkz . Eclipse için Azure Toolkit'i Yükleme.
Scala eklentisini yükleme
Eclipse'i açtığınızda, HDInsight Araçları Scala eklentisini yükleyip yüklemediğiniz otomatik olarak algılar. Devam etmek için Tamam'ı seçin ve ardından Eclipse Market'ten eklentiyi yüklemek için yönergeleri izleyin. Yükleme tamamlandıktan sonra IDE'yi yeniden başlatın.
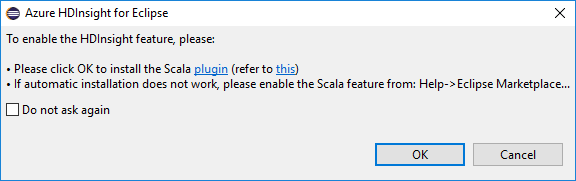
Eklentileri onaylama
Yardım>Eclipse Marketi'ne gidin....
Yüklü sekmesini seçin.
En azından şunu görmeniz gerekir:
- Eclipse <için Azure Toolkit sürümü>.
- Scala IDE <sürümü>.
Azure aboneliğinizde oturum açın
Eclipse IDE'ye başlayın.
Pencere>Diğer Görünümü>Göster'e gidin...>Oturum Aç...
Görünümü Göster iletişim kutusunda Azure>Azure Gezgini'ne gidin ve Aç'ı seçin.
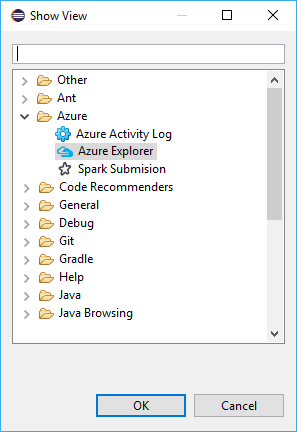
Azure Gezgini'ndeAzure düğümüne sağ tıklayın ve oturum aç'ı seçin.
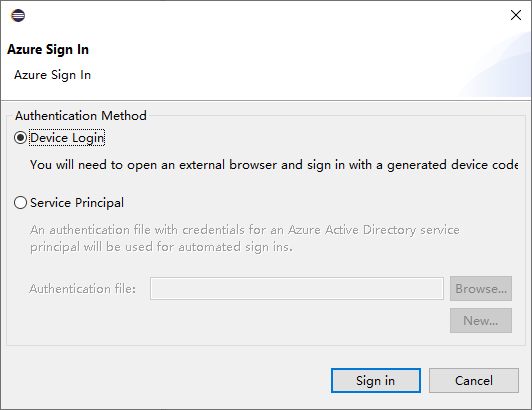
Azure Oturum Açma iletişim kutusunda kimlik doğrulama yöntemini seçin, Oturum aç'ı seçin ve oturum açma işlemini tamamlayın.
Oturum açtıktan sonra Abonelikleriniz iletişim kutusunda kimlik bilgileriyle ilişkili tüm Azure abonelikleri listelenir. İletişim kutusunu kapatmak için Seç'e basın.
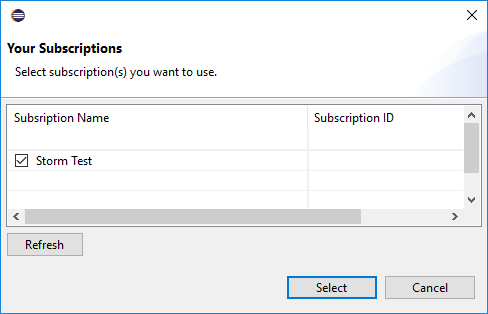
Aboneliğinizin altındaki HDInsight Spark kümelerini görmek için Azure Gezgini'ndenAzure>HDInsight'a gidin.
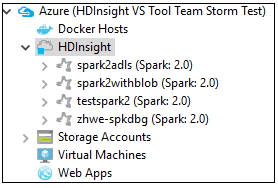
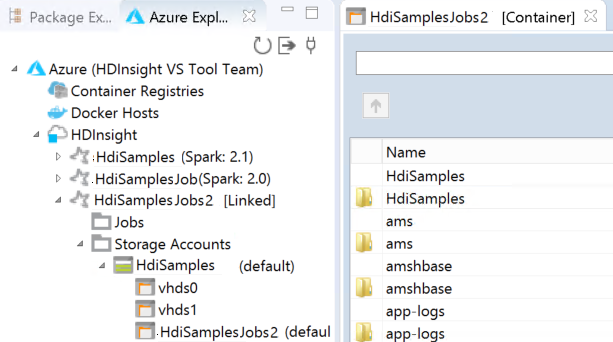
Kümeyle ilişkili kaynakları (örneğin, depolama hesapları) görmek için bir küme adı düğümünü daha da genişletebilirsiniz.
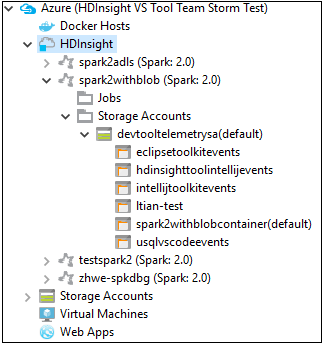
Kümeyi bağlama
Ambari tarafından yönetilen kullanıcı adını kullanarak normal bir kümeyi bağlayabilirsiniz. Benzer şekilde, etki alanına katılmış bir HDInsight kümesi için, etki alanını ve kullanıcı adını kullanarak bağlantı oluşturabilirsiniz; örneğin user1@contoso.com.
Azure Gezgini'ndenHDInsight'a sağ tıklayın ve Küme Bağla'yı seçin.
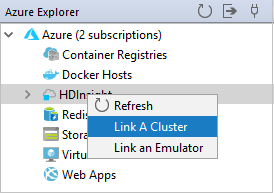
Küme Adı, Kullanıcı Adı ve Parola girin, ardından Tamam'ı seçin. İsteğe bağlı olarak Depolama Hesabı, Depolama Anahtarı girin ve depolama gezgininin sol ağaç görünümünde çalışması için Depolama Kapsayıcısı'nı seçin
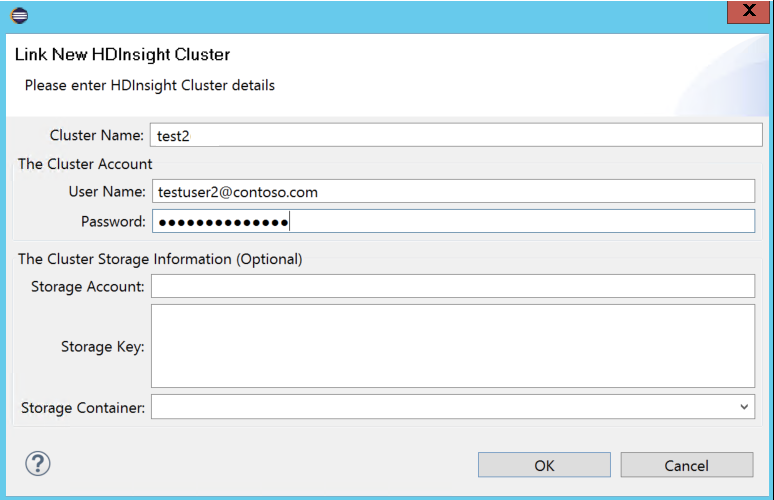
Uyarı
Küme hem Azure aboneliğinde oturum açtıysa hem de Kümeye bağlıysa bağlı depolama anahtarını, kullanıcı adını ve parolayı kullanırız.
Yalnızca klavye kullanıcısı için, geçerli odak Depolama Tuşu'ndayken, iletişim kutusunda bir sonraki alana odaklanmak için Ctrl+SEKME tuşlarını kullanmanız gerekir.
Bağlı kümeyi HDInsight altında görebilirsiniz. Artık bu bağlı kümeye bir uygulama gönderebilirsiniz.
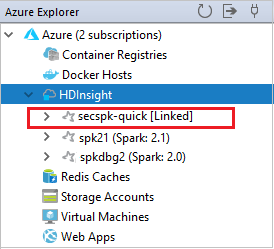
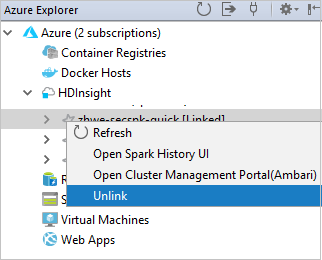
Ayrıca bir kümenin Azure Gezgini bağlantısını da kaldırabilirsiniz.
HDInsight Spark kümesi için Spark Scala projesi ayarlama
Eclipse IDE çalışma alanından Dosya>Yeni>Proje...'i seçin.
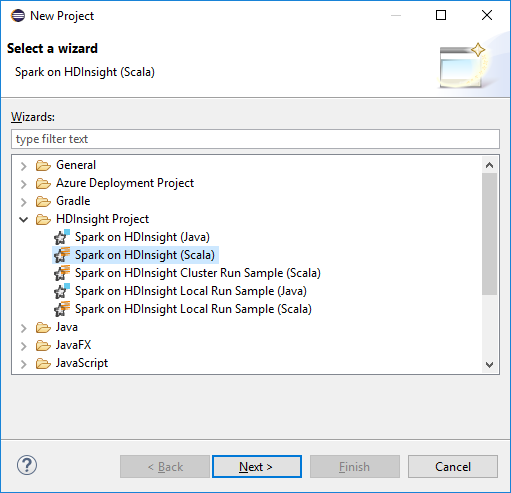
Yeni Proje sihirbazında HDInsight Project>HDInsight üzerinde Spark (Scala) seçeneğini belirleyin. Sonra İleri'yi seçin.
Yeni HDInsight Scala Projesi iletişim kutusunda aşağıdaki değerleri sağlayın ve İleri'yi seçin:
- Proje için bir ad girin.
- JRE alanında Yürütme ortamı kullan JRE'ninJavaSE-1.7 veya üzeri olarak ayarlandığından emin olun.
- Spark Kitaplığı alanında, Spark SDK'sını yapılandırmak için Maven kullan seçeneğini belirleyebilirsiniz. Aracımız Spark SDK ve Scala SDK için uygun sürümü tümleştirir. Ayrıca Spark SDK'sı ekle seçeneğini el ile seçebilir, Spark SDK'yı el ile indirebilir ve ekleyebilirsiniz.
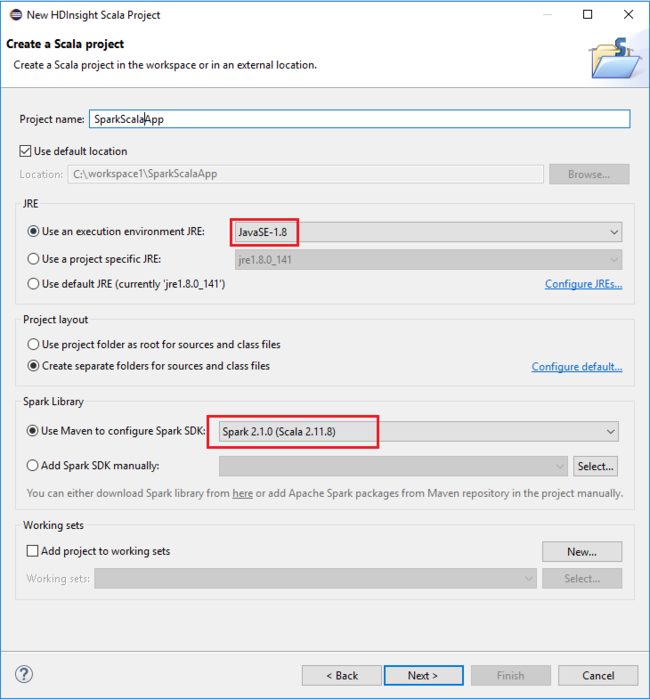
Sonraki iletişim kutusunda ayrıntıları gözden geçirin ve Son'u seçin.
HDInsight Spark kümesi için Scala uygulaması oluşturma
Paket Gezgini'nden daha önce oluşturduğunuz projeyi genişletin. src'ye sağ tıklayın, YeniDiğer...'i> seçin.
Sihirbaz seçin iletişim kutusunda Scala Sihirbazları>Scala Nesnesi'ni seçin. Sonra İleri'yi seçin.
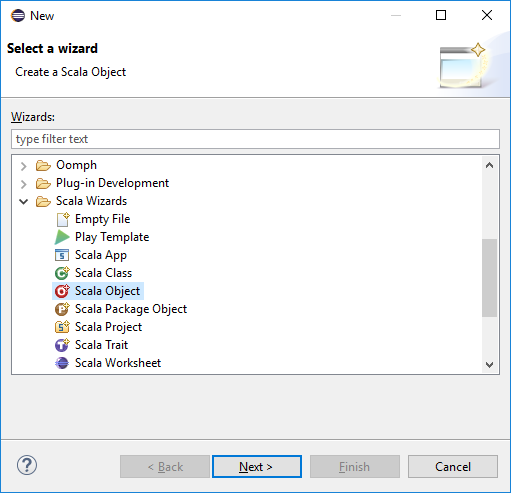
Yeni Dosya Oluştur iletişim kutusunda nesne için bir ad girin ve Son'u seçin. Bir metin düzenleyicisi açılır.
Metin düzenleyicisinde geçerli içeriği aşağıdaki kodla değiştirin:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object MyClusterApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("MyClusterApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Uygulamayı bir HDInsight Spark kümesinde çalıştırın:
a. Paket Gezgini'nden proje adına sağ tıklayın ve spark uygulamasını HDInsight'a gönder'i seçin.
b. Spark Gönderimi iletişim kutusunda aşağıdaki değerleri sağlayın ve gönder'i seçin:
Küme Adı için uygulamanızı çalıştırmak istediğiniz HDInsight Spark kümesini seçin.
Eclipse projesinden bir yapıt seçin veya sabit sürücüden bir yapıt seçin. Varsayılan değer, Paket Gezgini'nden sağ tıkladığınız öğeye bağlıdır.
Ana sınıf adı açılan listesinde, gönderme sihirbazı projenizdeki tüm nesne adlarını görüntüler. Çalıştırmak istediğiniz birini seçin veya girin. Sabit sürücüden bir yapıt seçtiyseniz, ana sınıf adını el ile girmeniz gerekir.
Bu örnekteki uygulama kodu herhangi bir komut satırı bağımsız değişkeni gerektirmediğinden veya JAR'lere veya dosyalara başvurmadığından, kalan metin kutularını boş bırakabilirsiniz.
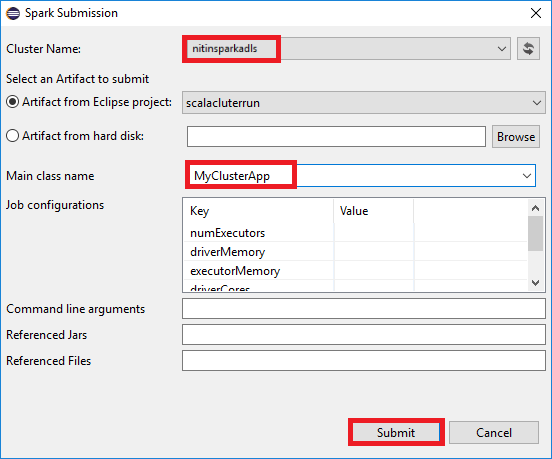
Spark Gönderimi sekmesi ilerleme durumunu görüntülemeye başlamalıdır. Spark Gönderimi penceresindeki kırmızı düğmeyi seçerek uygulamayı durdurabilirsiniz. Bu uygulama çalıştırmasının günlüklerini, dünya simgesini (görüntüdeki mavi kutuyla gösterilir) seçerek de görüntüleyebilirsiniz.
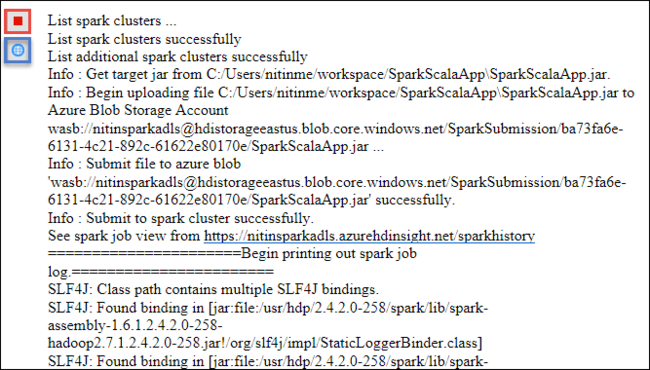
Azure Toolkit for Eclipse'te HDInsight Araçları'nı kullanarak HDInsight Spark kümelerine erişme ve kümelerini yönetme
HDInsight Araçları'nı kullanarak, iş çıkışına erişmek de dahil olmak üzere çeşitli işlemler gerçekleştirebilirsiniz.
İş görünümüne erişme
Azure Gezgini'ndeHDInsight'ı genişletin, ardından Spark kümesi adını genişletin ve İşler'i seçin.
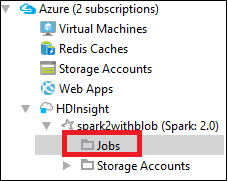
İşler düğümünü seçin. Java sürümü 1.8'den düşükse, HDInsight Araçları E(fx)clipse eklentisini yüklediğinizi otomatik olarak anımsatır. Devam etmek için Tamam'ı seçin ve ardından eclipse Market'ten yüklemek ve Eclipse'i yeniden başlatmak için sihirbazı izleyin.
İşler düğümünden İş Görünümü'nü açın. Sağ bölmede Spark İşi Görünümü sekmesi, kümede çalıştırılan tüm uygulamaları görüntüler. Daha fazla ayrıntı görmek istediğiniz uygulamanın adını seçin.
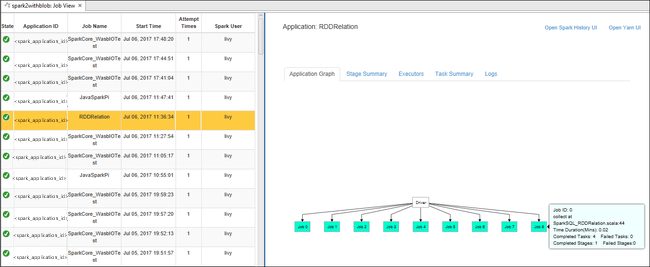
Ardından şu eylemlerden herhangi birini gerçekleştirebilirsiniz:
İş grafiğinin üzerine fareyi getirin. Çalışmakta olan işlem hakkındaki temel bilgileri gösterir. İş grafiğini seçtiğinizde her işin oluşturduğu aşamaları ve bilgileri görebilirsiniz.
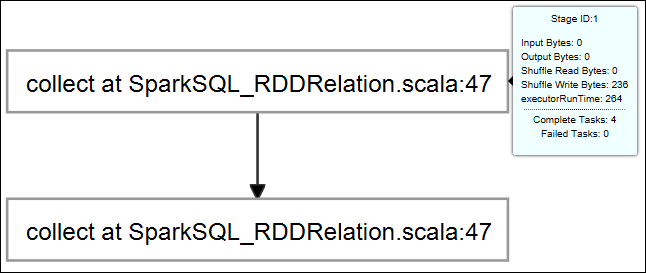
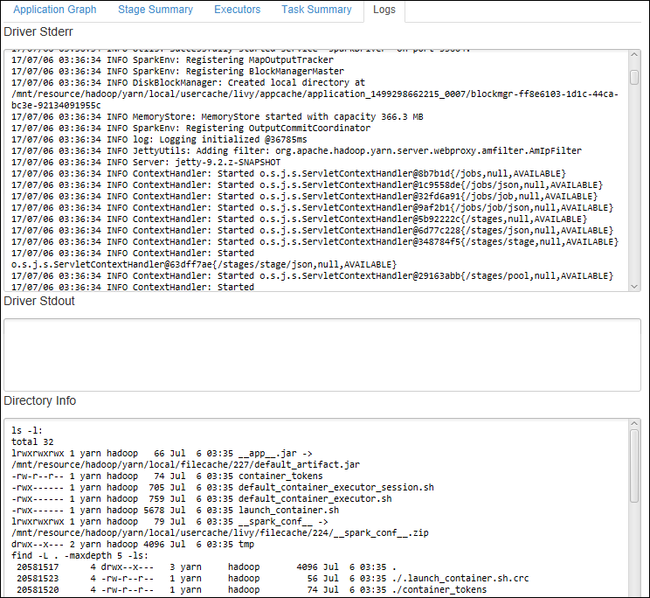
Driver Stderr, Driver Stdout ve Dizin Bilgileri gibi sık kullanılan günlükleri görüntülemek için Günlük sekmesini seçin.
Pencerenin üst kısmındaki köprüleri seçerek Spark geçmişi kullanıcı arabirimini ve Apache Hadoop YARN kullanıcı arabirimini (uygulama düzeyinde) açın.
Küme için depolama kapsayıcısına eriş
Kullanılabilir HDInsight Spark kümelerinin listesini görmek için Azure Gezgini'nde HDInsight kök düğümünü genişletin.
Kümenin depolama hesabını ve varsayılan depolama kapsayıcısını görmek için küme adını genişletin.
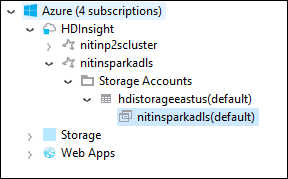
Kümeyle ilişkilendirilmiş depolama kapsayıcısı adını seçin. Sağ bölmede HVACOut klasörüne çift tıklayın. Uygulamanın çıkışını görmek için parça dosyalarından birini açın.
Spark geçmiş sunucusuna erişme
Azure Gezgini'nde Spark kümenizin adına sağ tıklayın ve Spark History UI'yi Aç seçin. İstendiğinde kümenin yönetici kimlik bilgilerini girin. Kümeyi hazırlarken bunları belirttiniz.
Spark geçmişi sunucusu panosunda, çalıştırmayı yeni tamamladığınız uygulamayı aramak için uygulama adını kullanırsınız. Önceki kodda,
val conf = new SparkConf().setAppName("MyClusterApp")kullanarak uygulama adını ayarlarsınız. Spark uygulamanızın adı MyClusterApp oldu.
Apache Ambari portalını başlatma
Azure Gezgini'nde Spark kümenizin adına sağ tıklayın ve ardından Open Cluster Management Portal (Ambari)'yi seçin.
İstendiğinde kümenin yönetici kimlik bilgilerini girin. Kümeyi hazırlarken bunları belirttiniz.
Azure aboneliklerini yönetme
Varsayılan olarak, Eclipse için Azure Toolkit'teki HDInsight Aracı tüm Azure aboneliklerinizdeki Spark kümelerini listeler. Gerekirse, kümeye erişmek istediğiniz abonelikleri belirtebilirsiniz.
Azure Gezgini'nde Azure kök düğümüne sağ tıklayıp Abonelikleri Yönet'i seçin.
İletişim kutusunda, erişmek istemediğiniz aboneliğin onay kutularını temizleyin ve kapat'ı seçin. Azure aboneliğinizin oturumunu kapatmak istiyorsanız Oturumu Kapat'ı da seçebilirsiniz.
Spark Scala uygulamasını yerel olarak çalıştırma
Spark Scala uygulamalarını iş istasyonunuzda yerel olarak çalıştırmak için Azure Toolkit for Eclipse'te HDInsight Araçları'nı kullanabilirsiniz. Genellikle bu uygulamaların depolama kapsayıcısı gibi küme kaynaklarına erişmesi gerekmez ve bunları yerel olarak çalıştırıp test edebilirsiniz.
Önkoşul
Yerel Spark Scala uygulamasını bir Windows bilgisayarında çalıştırırken SPARK-2356'da açıklandığı gibi bir özel durumla karşınıza çıkabilir. Windows'ta WinUtils.exe eksik olduğundan bu özel durum oluşur.
Bu hatayı çözmek için C:\WinUtils\bin gibi bir konuma Winutils.exe ve ardından ortam değişkenini HADOOP_HOME ekleyip değişkenin değerini C\WinUtils olarak ayarlamanız gerekir.
Yerel Spark Scala uygulaması çalıştırma
Eclipse'i başlatın ve bir proje oluşturun. Yeni Proje iletişim kutusunda aşağıdaki seçimleri yapın ve İleri'yi seçin.
Yeni Proje sihirbazında HDInsight Projesi>Yerel Spark Çalıştırma Örneği (Scala) seçeneğini belirleyin. Sonra İleri'yi seçin.
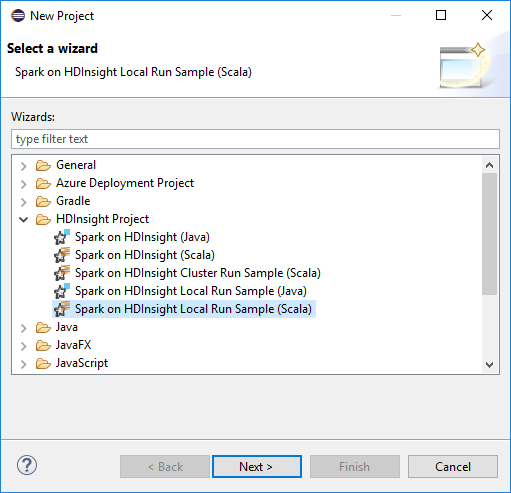
Proje ayrıntılarını sağlamak için HDInsight Spark kümesi için Spark Scala projesi ayarlama bölümünde yer alan 3 ile 6 arasındaki adımları izleyin.
Şablon, src klasörünün altına bilgisayarınızda yerel olarak çalıştırabileceğiniz bir örnek kod (LogQuery) ekler.
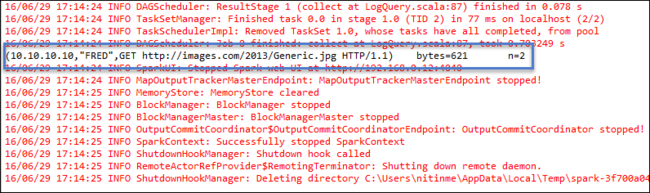
LogQuery.scala öğesine sağ tıklayın ve Farklı Çalıştır1 Scala Uygulaması'yı> seçin. Konsol sekmesinde şuna benzer bir çıkış görünür:
Yalnızca okuyucu rolü
Kullanıcılar işi yalnızca okuyucu rolü izni olan bir kümeye gönderdiğinde Ambari kimlik bilgileri gerekir.
Bağlam menüsünden kümeyi bağlama
Yalnızca okuyucu rol hesabıyla oturum açın.
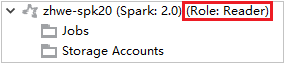
Azure Gezgini'nde, aboneliğinizdeki HDInsight kümelerini görüntülemek için HDInsight'ı genişletin. "Role:Reader" olarak işaretlenen kümelerin yalnızca okuyucu rol izni vardır.
Yalnızca okuyucu rolü iznine sahip kümeye sağ tıklayın. Bağlam menüsünden Kümeyi Bağla'yı seçin. Ambari kullanıcı adını ve parolasını girin.
Küme başarıyla bağlanırsa HDInsight yenilenir. Kümenin aşaması bağlantılı hale gelecek.
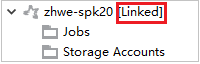
İşler düğümünü genişleterek kümeyi bağlama
İşler düğümü'ne tıklayın, Küme İşi Erişimi Reddedildi penceresi açılır.
Bu kümeyi bağlamak için Kümeyi Bağla'ya tıklayın.
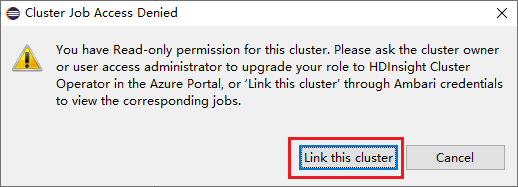
Spark Gönderimi penceresinden kümeyi bağlama
HDInsight Projesi oluşturun.
Pakete sağ tıklayın. Ardından Spark Uygulamasını HDInsight'a Gönder'i seçin.
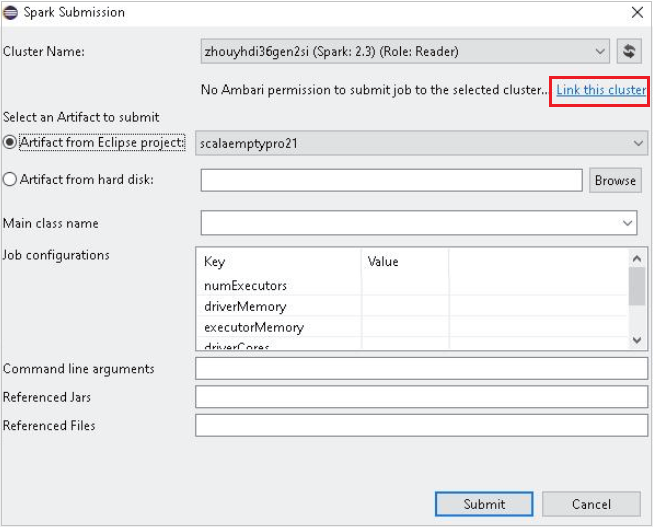
Küme Adı için yalnızca okuyucu rolü izni olan bir küme seçin. Uyarı iletisi çıkar. Küme bağlantısı kurmak için bu kümeyi bağla'ya tıklayabilirsiniz.
Depolama Hesaplarını Görüntüleme
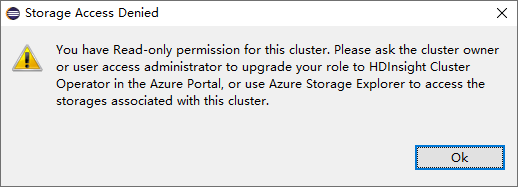
Yalnızca okuyucu rolü izni olan kümeler için Depolama Hesapları düğümüne tıklayın, Depolama Erişimi Reddedildi penceresi açılır.
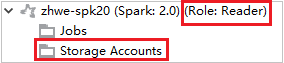
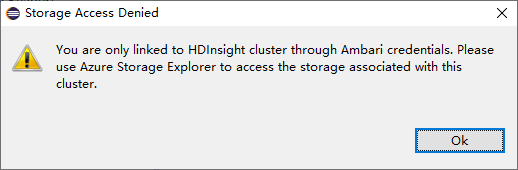
Bağlı kümeler için Depolama Hesapları düğümüne tıklayın, Depolama Erişimi Reddedildi penceresi açılır.
Bilinen sorunlar
Bir Kümeyi Bağla'yı kullanırken, depolama kimlik bilgilerini sağlamanızı öneririm.
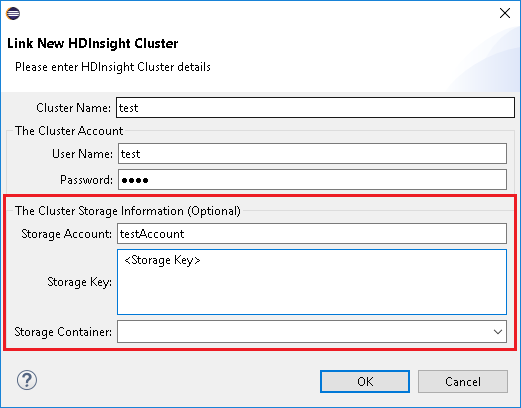
İşleri göndermek için iki mod vardır. Depolama kimlik bilgileri sağlanırsa, iş göndermek için toplu mod kullanılacaktır. Aksi takdirde etkileşimli mod kullanılır. Küme meşgulse aşağıdaki hatayı alabilirsiniz.


Ayrıca bkz.
Senaryo
- BI ile Apache Spark: BI araçlarıyla HDInsight'ta Spark kullanarak etkileşimli veri analizi gerçekleştirme
- Machine Learning ile Apache Spark: HVAC verilerini kullanarak bina sıcaklığını analiz etmek için HDInsight'ta Spark kullanma
- Machine Learning ile Apache Spark: Gıda denetimi sonuçlarını tahmin etmek için HDInsight'ta Spark kullanma
- HDInsight'ta Apache Spark kullanarak web sitesi günlük analizi
Uygulama oluşturma ve çalıştırma
- Scala kullanarak tek başına uygulama oluşturma
- Apache Livy kullanarak apache Spark kümesinde işleri uzaktan çalıştırma
Araçlar ve uzantılar
- Spark Scala uygulamaları oluşturmak ve göndermek için IntelliJ için Azure Toolkit'i kullanma
- Vpn aracılığıyla Apache Spark uygulamalarında uzaktan hata ayıklamak için IntelliJ için Azure Toolkit'i kullanma
- SSH aracılığıyla Apache Spark uygulamalarında uzaktan hata ayıklamak için IntelliJ için Azure Toolkit kullanma
- HDInsight üzerinde Apache Spark kümesiyle Apache Zeppelin not defterlerini kullanma
- HDInsight Apache Spark kümesinde Jupyter Notebook için kullanılabilir çekirdekler
- Jupyter Notebooks ile dış paketleri kullanma
- Jupyter’i bilgisayarınıza yükleme ve bir HDInsight Spark kümesine bağlanma