Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu makalede aşağıdaki adımları uygulayacaksınız.
Azure HDInsight Spark kümesine Microsoft Bilişsel Araç Seti yüklemek için özel bir betik çalıştırın.
Spark Python API'sini (PySpark) kullanarak Bir Azure Blob Depolama Hesabındaki dosyalara eğitilmiş bir Microsoft Bilişsel Araç Seti derin öğrenme modelinin nasıl uygulanacağını görmek için Apache Spark kümesine jupyter not defteri yükleyin
Önkoşullar
HDInsight üzerinde bir Apache Spark kümesi. Bkz . Apache Spark kümesi oluşturma.
HDInsight üzerinde Spark ile Jupyter Notebook kullanma bilgisi. Daha fazla bilgi için bkz . HDInsight üzerinde Apache Spark ile veri yükleme ve sorgu çalıştırma.
Bu çözüm nasıl akıyor?
Bu çözüm, bu makale ile bu makalenin bir parçası olarak karşıya yüklediğiniz Jupyter Not Defteri arasında bölünmüştür. Bu makalede aşağıdaki adımları tamamlaacaksınız:
- Microsoft Bilişsel Araç Seti ve Python paketlerini yüklemek için HDInsight Spark kümesinde bir betik eylemi çalıştırın.
- Çözümü çalıştıran Jupyter Not Defteri'ni HDInsight Spark kümesine yükleyin.
Aşağıdaki kalan adımlar Jupyter Not Defteri'nde ele alınmıştır.
- Örnek görüntüleri Spark Dayanıklı Dağıtılmış Veri Kümesine veya RDD'ye yükleyin.
- Modülleri yükleyin ve ön ayarları tanımlayın.
- Veri kümesini Spark kümesinde yerel olarak indirin.
- Veri kümesini RDD'ye dönüştürün.
- Eğitilmiş bir Bilişsel Araç Seti modeli kullanarak görüntüleri puanlar.
- Eğitilen Bilişsel Araç Seti modelini Spark kümesine indirin.
- Çalışan düğümleri tarafından kullanılacak işlevleri tanımlayın.
- Çalışan düğümlerinde görüntüleri puanlar.
- Model doğruluğunu değerlendirme.
Microsoft Bilişsel Araç Seti'ni yükleme
Betik eylemini kullanarak Bir Spark kümesine Microsoft Bilişsel Araç Seti yükleyebilirsiniz. Betik eylemi, varsayılan olarak kullanılabilir olmayan bileşenleri kümeye yüklemek için özel betikler kullanır. Özel betiği Azure portalından, HDInsight .NET SDK'sını veya Azure PowerShell'i kullanarak kullanabilirsiniz. Küme oluşturmanın bir parçası olarak veya küme çalışır duruma geldikten sonra araç setini yüklemek için betiği de kullanabilirsiniz.
Bu makalede, küme oluşturulduktan sonra araç setini yüklemek için portalı kullanacağız. Özel betiği çalıştırmanın diğer yolları için bkz. Betik Eylemini kullanarak HDInsight kümelerini özelleştirme.
Azure portalını kullanma
Betik eylemini çalıştırmak için Azure portalını kullanma yönergeleri için bkz. Betik Eylemi kullanarak HDInsight kümelerini özelleştirme. Microsoft Bilişsel Araç Seti'ni yüklemek için aşağıdaki girişleri sağladığınıza emin olun. Senaryonuz için aşağıdaki değerleri kullanın.
| Mülkiyet | Değer |
|---|---|
| Betik türü | -Özel |
| İsim | MCT'yi yükleme |
| Bash betik URI'si | https://raw.githubusercontent.com/Azure-Samples/hdinsight-pyspark-cntk-integration/master/cntk-install.sh |
| Düğüm türleri: | Yönetici, Çalışan |
| Parametreler | Hiç kimse |
Jupyter Notebook'u Azure HDInsight Spark kümesine yükleme
Microsoft Bilişsel Araç Seti'ni Azure HDInsight Spark kümesiyle kullanmak için Jupyter Notebook CNTK_model_scoring_on_Spark_walkthrough.ipynb dosyasını Azure HDInsight Spark kümesine yüklemeniz gerekir. Bu not defteri gitHub'da https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integrationbulunabilir.
Dosyayı indirin ve sıkıştırılmış dosyayı açın.
Bir web tarayıcısından
https://CLUSTERNAME.azurehdinsight.net/jupyteradresine gidin. BuradaCLUSTERNAME, kümenizin adıdır.Jupyter Not Defteri'nden sağ üst köşedeki Karşıya Yükle'yi seçin ve ardından indirmeye gidip dosyayı
CNTK_model_scoring_on_Spark_walkthrough.ipynbseçin.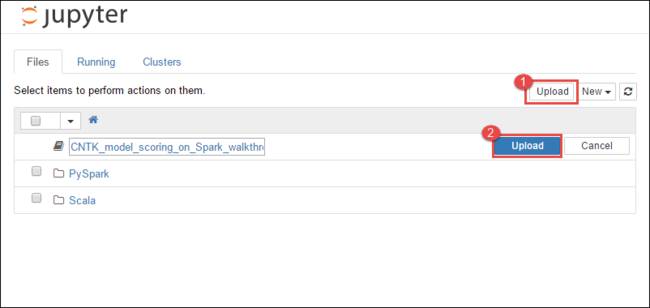
Yeniden Karşıya Yükle'yi seçin.
Not defteri karşıya yüklendikten sonra, not defterinin adına tıklayın ve ardından veri kümesini yükleme ve makaleyi çalıştırma yönergelerini içeren talimatları not defterinin kendisinde takip edin.
Ayrıca bkz.
Senaryo
- BI ile Apache Spark: BI araçlarıyla HDInsight'ta Spark kullanarak etkileşimli veri analizi gerçekleştirme
- Machine Learning ile Apache Spark: HVAC verilerini kullanarak bina sıcaklığını analiz etmek için HDInsight'ta Spark kullanma
- Machine Learning ile Apache Spark: Gıda denetimi sonuçlarını tahmin etmek için HDInsight'ta Spark kullanma
- HDInsight'ta Apache Spark kullanarak web sitesi günlük analizi
- HDInsight'ta Apache Spark kullanarak Application Insight telemetri veri analizi
Uygulamaları oluşturma ve çalıştırma
- Scala kullanarak tek başına uygulama oluşturma
- Apache Livy kullanarak apache Spark kümesinde işleri uzaktan çalıştırma
Araçlar ve uzantılar
- Spark Scala uygulamaları oluşturmak ve göndermek amacıyla IntelliJ IDEA için HDInsight Araçları Eklentisini kullanma
- Apache Spark uygulamalarında uzaktan hata ayıklamak için IntelliJ IDEA için HDInsight Araçları Eklentisi'ni kullanma
- HDInsight üzerinde Apache Spark kümesiyle Apache Zeppelin not defterlerini kullanma
- HDInsight için Apache Spark kümesinde Jupyter Notebook için kullanılabilir çekirdekler
- Jupyter Notebooks ile dış paketleri kullanma
- Jupyter’i bilgisayarınıza yükleme ve bir HDInsight Spark kümesine bağlanma