Apache Spark için Azure Veri Gezgini Bağlayıcısı
Önemli
Bu bağlayıcı, Microsoft Fabric'teki Gerçek Zamanlı Analiz'de kullanılabilir. Aşağıdaki özel durumlar için bu makaledeki yönergeleri kullanın:
- Gerekirse KQL veritabanı oluşturma bölümündeki yönergeleri kullanarak veritabanları oluşturun.
- Gerekirse, Boş tablo oluşturma başlığındaki yönergeleri kullanarak tablolar oluşturun.
- Kopyalama URI'sindeki yönergeleri kullanarak sorgu veya alma URI'lerini alın.
- Sorguları bir KQL sorgu kümesinde çalıştırın.
Apache Spark , büyük ölçekli veri işlemeye yönelik birleşik bir analiz altyapısıdır. Azure Veri Gezgini büyük miktarda veri üzerinde gerçek zamanlı analiz yapmaya yönelik hızlı ve tam olarak yönetilen bir veri analizi hizmetidir.
Spark için Azure Veri Gezgini bağlayıcısı, herhangi bir Spark kümesinde çalışabilen açık kaynak bir projedir. Verileri Azure Veri Gezgini ve Spark kümeleri arasında taşımak için veri kaynağı ve veri havuzu uygular. Azure Veri Gezgini ve Apache Spark kullanarak veri temelli senaryoları hedefleyen hızlı ve ölçeklenebilir uygulamalar oluşturabilirsiniz. Örneğin, makine öğrenmesi (ML), Ayıklama-Dönüştürme-Yükleme (ETL) ve Log Analytics. Bağlayıcı ile Azure Veri Gezgini yazma, okuma ve writeStream gibi standart Spark kaynağı ve havuz işlemleri için geçerli bir veri deposu haline gelir.
Kuyruğa alınmış alma veya akış alımı aracılığıyla Azure Veri Gezgini yazabilirsiniz. Azure Veri Gezgini'dan okuma, azure Veri Gezgini verileri filtreleyerek aktarılan veri hacmini azaltan sütun ayıklama ve koşul gönderme işlemlerini destekler.
Not
Azure Veri Gezgini için Synapse Spark bağlayıcısı ile çalışma hakkında bilgi için bkz. Azure Synapse Analytics için Apache Spark kullanarak Azure Veri Gezgini bağlanma.
Bu konuda, Azure Veri Gezgini Spark bağlayıcısının nasıl yükleneceği ve yapılandırıldığı ve Azure Veri Gezgini ile Apache Spark kümeleri arasında verilerin nasıl taşındığı açıklanır.
Not
Aşağıdaki örneklerden bazıları Azure Databricks Spark kümesine başvuruda bulunmakla birlikte, Azure Veri Gezgini Spark bağlayıcısı Databricks'e veya başka bir Spark dağıtımına doğrudan bağımlılıklar almaz.
Önkoşullar
- Azure aboneliği. Ücretsiz bir Azure hesabı oluşturun.
- Azure Veri Gezgini kümesi ve veritabanı. Küme ve veritabanı oluşturma.
- Spark kümesi
- Azure Veri Gezgini bağlayıcı kitaplığını yükleyin:
- Spark 2.4+Scala 2.11 veya Spark 3+scala 2.12 için önceden oluşturulmuş kitaplıklar
- Maven deposu
- Maven 3.x yüklü
İpucu
Spark 2.3.x sürümleri de desteklenir, ancak pom.xml bağımlılıklarında bazı değişiklikler gerekebilir.
Spark bağlayıcısı oluşturma
Sürüm 2.3.0'dan başlayarak spark-kusto-connector: kusto-spark_3.0_2.12, Spark 3.x ve Scala 2.12 ile Spark 2.4.x ve scala 2.11'i hedefleyen kusto-spark_2.4_2.11'in yerini alan yeni yapıt kimlikleri kullanıma sunuldu.
Not
2.5.1 öncesi sürümler artık mevcut bir tabloya almak için çalışmıyor, lütfen daha sonraki bir sürüme güncelleştirin. Bu adım isteğe bağlıdır. Maven gibi önceden oluşturulmuş kitaplıklar kullanıyorsanız bkz. Spark kümesi kurulumu.
Derleme önkoşulları
Önceden oluşturulmuş kitaplıklar kullanmıyorsanız, aşağıdaki Kusto Java SDK kitaplıkları dahil olmak üzere bağımlılıklarda listelenen kitaplıkları yüklemeniz gerekir. Yüklenecek doğru sürümü bulmak için ilgili sürümün pom'una bakın:
Spark Bağlayıcısı oluşturmak için bu kaynağa bakın.
Maven proje tanımlarını kullanan Scala/Java uygulamaları için uygulamanızı aşağıdaki yapıtla bağlayın (en son sürüm farklı olabilir):
<dependency> <groupId>com.microsoft.azure</groupId> <artifactId>kusto-spark_3.0_2.12</artifactId> <version>2.5.1</version> </dependency>
Derleme komutları
Jar oluşturmak ve tüm testleri çalıştırmak için:
mvn clean package
Jar oluşturmak için tüm testleri çalıştırın ve jar dosyasını yerel Maven deponuza yükleyin:
mvn clean install
Daha fazla bilgi için bkz. bağlayıcı kullanımı.
Spark kümesi kurulumu
Not
Aşağıdaki adımları gerçekleştirirken en son Azure Veri Gezgini Spark bağlayıcı sürümünü kullanmanız önerilir.
Spark 2.4.4 ve Scala 2.11 veya Spark 3.0.1 ve Scala 2.12 kullanarak Azure Databricks kümesini temel alan aşağıdaki Spark kümesi ayarlarını yapılandırın:
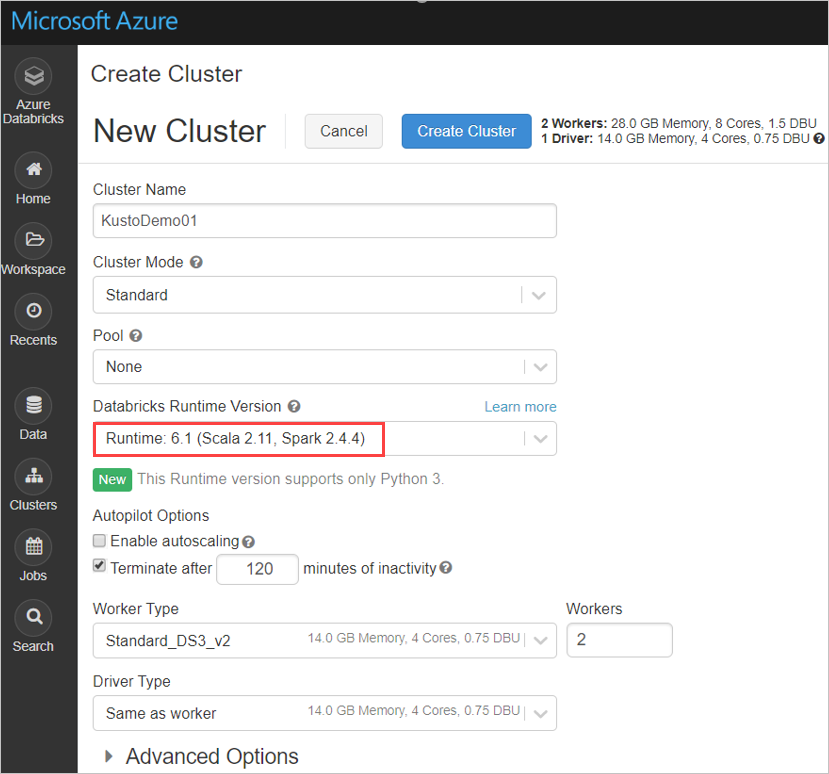
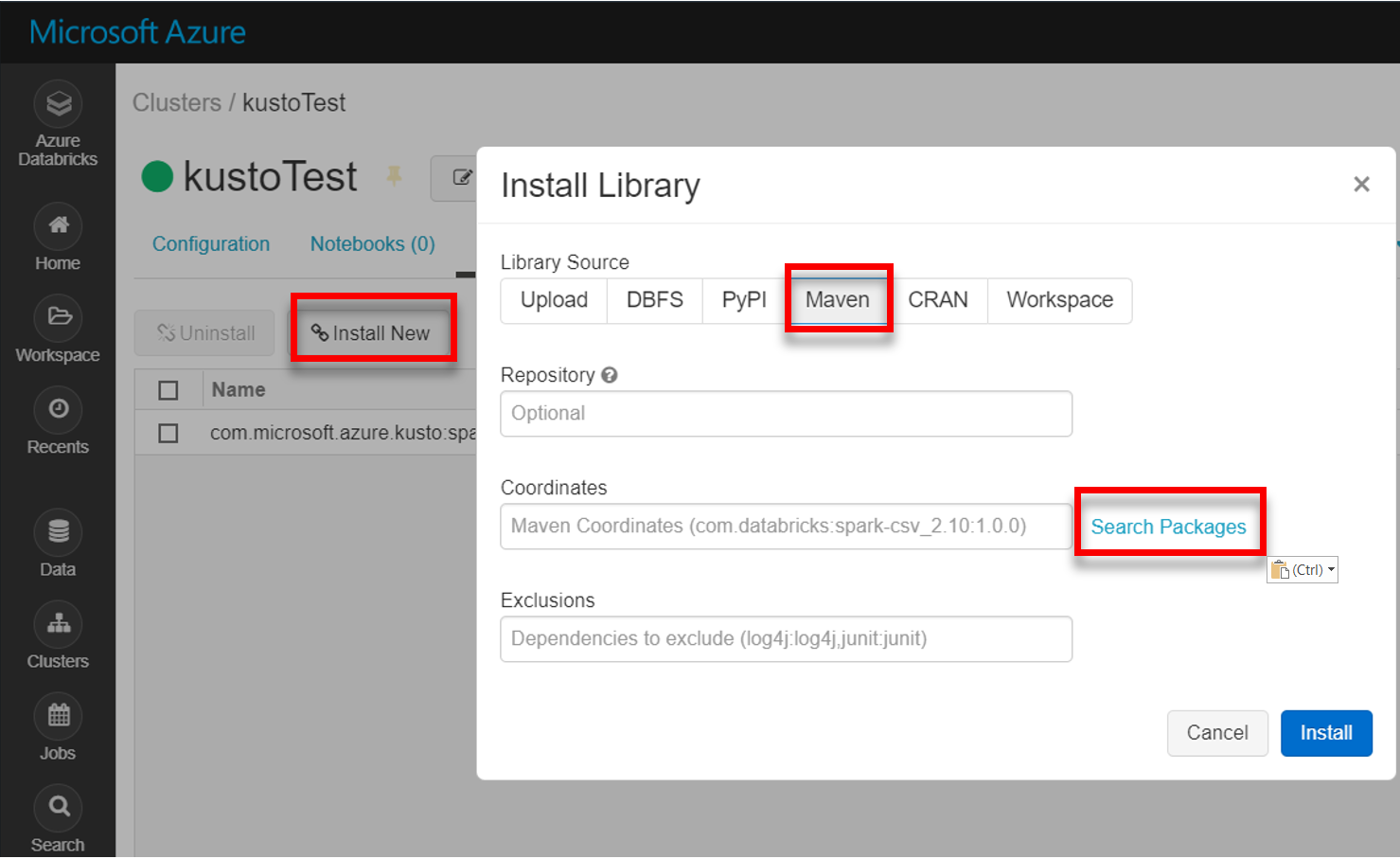
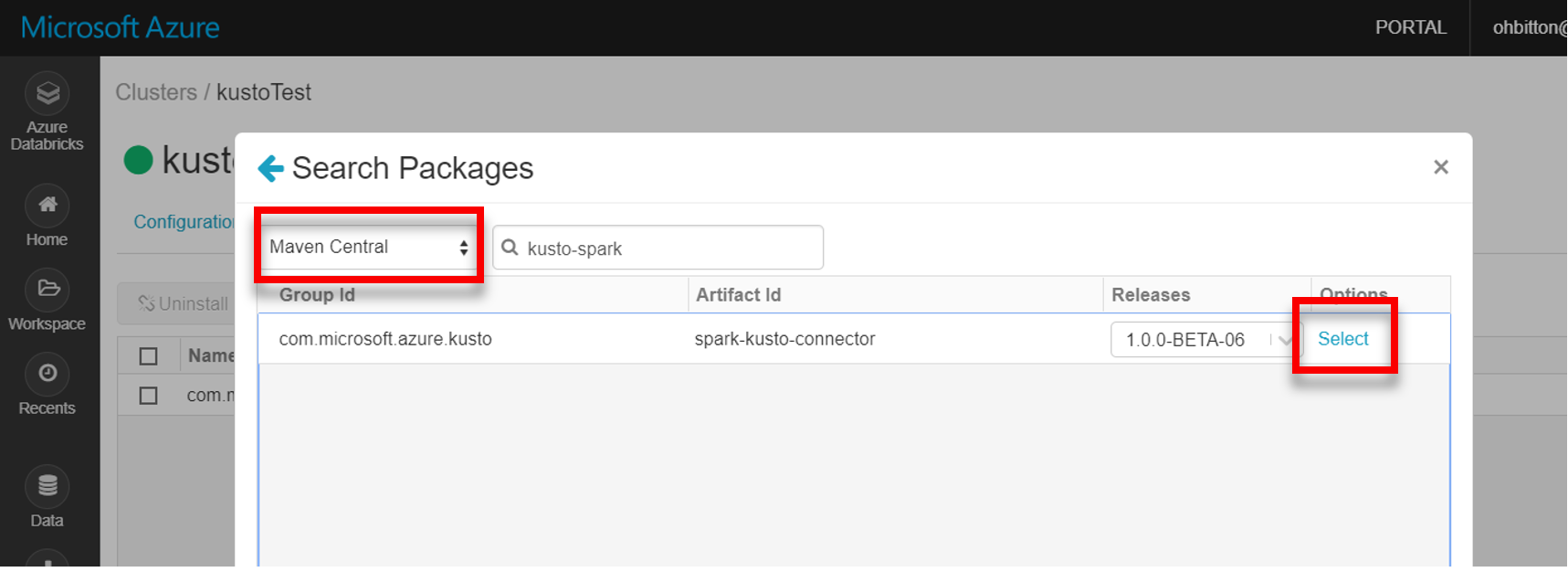
Maven'dan en son spark-kusto-connector kitaplığını yükleyin:
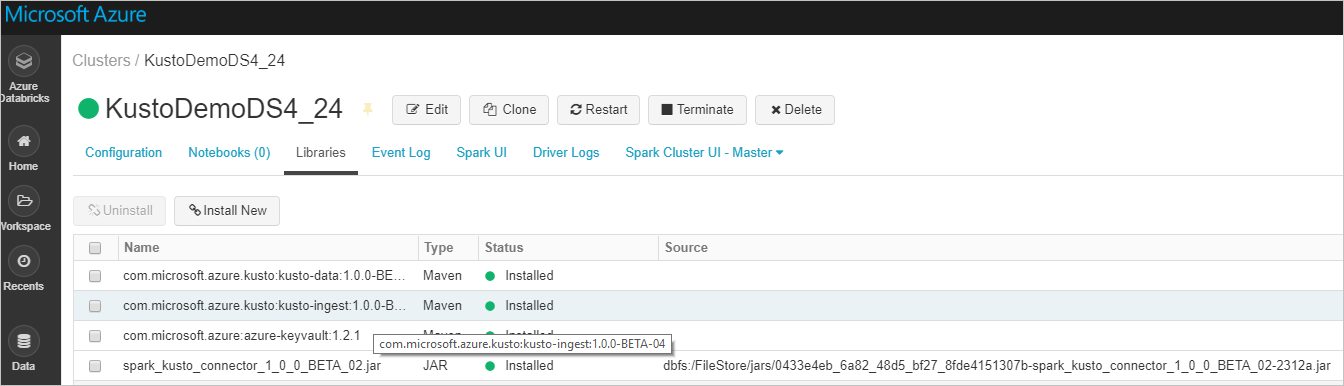
Tüm gerekli kitaplıkların yüklü olduğunu doğrulayın:
JAR dosyası kullanarak yükleme için ek bağımlılıkların yüklendiğini doğrulayın:
Kimlik Doğrulaması
Azure Veri Gezgini Spark bağlayıcısı, aşağıdaki yöntemlerden birini kullanarak Microsoft Entra kimliğiyle kimlik doğrulaması yapmanıza olanak tanır:
- Microsoft Entra uygulaması
- Microsoft Entra erişim belirteci
- Cihaz kimlik doğrulaması (üretim dışı senaryolar için)
- Azure Key Vault Key Vault kaynağına erişmek için azure-keyvault paketini yükleyin ve uygulama kimlik bilgilerini sağlayın.
Uygulama kimlik doğrulamayı Microsoft Entra
Microsoft Entra uygulama kimlik doğrulaması en basit ve en yaygın kimlik doğrulama yöntemidir ve Azure Veri Gezgini Spark bağlayıcısı için önerilir.
| Özellikler | Seçenek Dizesi | Description |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Microsoft Entra uygulama (istemci) tanımlayıcısı. |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | kimlik doğrulama yetkilisini Microsoft Entra. dizin (kiracı) kimliğini Microsoft Entra. İsteğe bağlı - varsayılan olarak microsoft.com. Daha fazla bilgi için bkz. Microsoft Entra yetkilisi. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | İstemci için uygulama anahtarını Microsoft Entra. |
Not
Eski API sürümleri (2.0.0'dan küçük) şu adlandırmaya sahiptir: "kustoAADClientID", "kustoClientAADClientPassword", "kustoAADAuthorityID"
Azure Veri Gezgini ayrıcalıkları
Azure Veri Gezgini kümesinde aşağıdaki ayrıcalıkları verin:
- Okuma (veri kaynağı) için Microsoft Entra kimliğinin hedef veritabanında görüntüleyici ayrıcalıklarına veya hedef tabloda yönetici ayrıcalıklarına sahip olması gerekir.
- Yazma (veri havuzu) için Microsoft Entra kimliğinin hedef veritabanında alma ayrıcalıkları olmalıdır. Ayrıca yeni tablolar oluşturmak için hedef veritabanında kullanıcı ayrıcalıklarına sahip olması gerekir. Hedef tablo zaten varsa, hedef tabloda yönetici ayrıcalıklarını yapılandırmanız gerekir.
Azure Veri Gezgini asıl rolleri hakkında daha fazla bilgi için bkz. rol tabanlı erişim denetimi. Güvenlik rollerini yönetmek için bkz. güvenlik rolleri yönetimi.
Spark havuzu: Azure Veri Gezgini'ye yazma
Havuz parametrelerini ayarlama:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Spark DataFrame'i Azure Veri Gezgini kümesine toplu olarak yazın:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()Veya basitleştirilmiş söz dizimini kullanın:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Akış verileri yazma:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Spark kaynağı: Azure Veri Gezgini'dan okuma
Az miktarda veri okurken veri sorgusunu tanımlayın:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)İsteğe bağlı: Geçici blob depolama (Azure Veri Gezgini değil) sağlarsanız bloblar çağıranın sorumluluğu altında oluşturulur. Buna depolamayı sağlama, erişim anahtarlarını döndürme ve geçici yapıtları silme dahildir. KustoBlobStorageUtils modülü, hesap ve kapsayıcı koordinatları ile hesap kimlik bilgilerini temel alarak blobları silmeye yönelik yardımcı işlevler ya da yazma, okuma ve liste izinlerine sahip tam BIR SAS URL'si içerir. karşılık gelen RDD artık gerekli olmadığında, her işlem geçici blob yapıtlarını ayrı bir dizinde depolar. Bu dizin, Spark Sürücüsü düğümünde bildirilen okuma işlemi bilgi günlüklerinin bir parçası olarak yakalanır.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")Yukarıdaki örnekte bağlayıcı arabirimi kullanılarak Key Vault erişilemiyor; Databricks gizli dizilerini kullanmanın daha basit bir yöntemi kullanılıyor.
Azure Veri Gezgini'dan okuyun.
Geçici blob depolamayı sağlarsanız Azure Veri Gezgini'dan aşağıdaki gibi okuyun:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Azure Veri Gezgini geçici blob depolama alanı sağlıyorsa Azure Veri Gezgini'dan aşağıdaki gibi okuyun:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)
İlgili içerik
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin