Havuzları iyileştirme
Veri akışları havuzlara yazıldığında, herhangi bir özel bölümleme yazmadan hemen önce gerçekleşir. Kaynakta olduğu gibi, çoğu durumda Seçili bölümleme seçeneği olarak geçerli bölümleme kullan seçeneğini tutmanız önerilir. Bölümlenmiş veriler bölümlenmemiş verilerden çok daha hızlı yazılır, hatta hedefiniz bölümlenmez. Aşağıda çeşitli havuz türleri için dikkat edilmesi gereken tek tek noktalar yer alır.
havuzları Azure SQL Veritabanı
Azure SQL Veritabanı ile varsayılan bölümleme çoğu durumda çalışır. Havuzunuzda SQL veritabanınızın işleyebileceği çok fazla bölüm olabilir. Bu durumla karşınıza çıkarsa, SQL Veritabanı havuzunuzun verdiği bölüm sayısını azaltın.
Kaynaktaki eksik satırları temel alarak havuzdaki satırları silmeye yönelik en iyi yöntem
Bu ortak deseni elde etmek için veri akışlarını var olan, satır değiştiren ve havuz dönüşümleriyle nasıl kullanacağınıza yönelik bir video kılavuzu aşağıdadır:
Hata satırı işlemenin performansa etkisi
Havuz dönüşümünde hata satırı işlemeyi ("hataya devam edin") etkinleştirdiğinizde, hizmet uyumlu satırları hedef tablonuza yazmadan önce ek bir adım atar. Bu ek adım, uyumsuz satırları bir günlük dosyasına da yazacak şekilde ayarlarsanız ek küçük bir performans isabetiyle bu adım için eklenen %5 aralığında olabilecek küçük bir performans cezasına sahiptir.
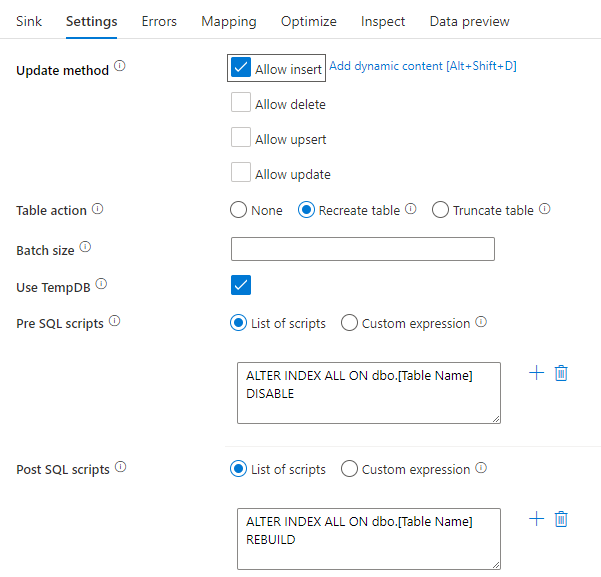
SQL Betiği kullanarak dizinleri devre dışı bırakma
SQL veritabanında bir yük olmadan önce dizinleri devre dışı bırakmak tabloya yazma performansını büyük ölçüde artırabilir. SQL havuzunuza yazmadan önce aşağıdaki komutu çalıştırın.
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
Yazma işlemi tamamlandıktan sonra aşağıdaki komutu kullanarak dizinleri yeniden oluşturun:
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
Bunların her ikisi de veri akışlarını eşlemek için bir Azure SQL Veritabanı veya Synapse havuzu içindeki Pre ve Post-SQL betikleri kullanılarak yerel olarak yapılabilir.
Uyarı
Dizinleri devre dışı bırakırken, veri akışı bir veritabanının denetimini etkili bir şekilde alır ve sorguların şu anda başarılı olma olasılığı düşüktür. Sonuç olarak, bu çakışmayı önlemek için gece yarısı birçok ETL işi tetiklenir. Daha fazla bilgi için SQL dizinlerini devre dışı bırakma kısıtlamaları hakkında bilgi edinin
Veritabanınızın ölçeğini artırma
İşlem hattı çalıştırmadan önce kaynak ve havuz Azure SQL DB ve DW'nizi yeniden boyutlandırmayı zamanlayarak aktarım hızını artırın ve DTU sınırlarına ulaştıktan sonra Azure azaltmayı en aza indirin. İşlem hattı yürütme işleminiz tamamlandıktan sonra veritabanlarınızı yeniden normal çalışma hızına geri döndürebilirsiniz.
Azure Synapse Analytics havuzları
Azure Synapse Analytics'e yazarken Hazırlamayı etkinleştir ayarının true olarak ayarlandığından emin olun. Bu, hizmetin verileri toplu olarak etkili bir şekilde yükleyen SQL COPY Komutunu kullanarak yazmasına olanak tanır. Hazırlama kullanırken verilerin hazırlaması için bir Azure Data Lake Depolama 2. nesil veya Azure Blob Depolama hesabına başvurmanız gerekir.
Hazırlama dışındaki en iyi yöntemler Azure Synapse Analytics için de Azure SQL Veritabanı geçerlidir.
Dosya tabanlı havuzlar
Veri akışları çeşitli dosya türlerini desteklese de, en uygun okuma ve yazma süreleri için Spark yerel Parquet biçimi önerilir.
Veriler eşit bir şekilde dağıtılıyorsa, Dosya yazmak için en hızlı bölümleme seçeneği Geçerli bölümleme kullan seçeneğidir.
Dosya adı seçenekleri
Dosya yazarken, her birinin performans üzerinde etkisi olan adlandırma seçeneklerine sahip olursunuz.
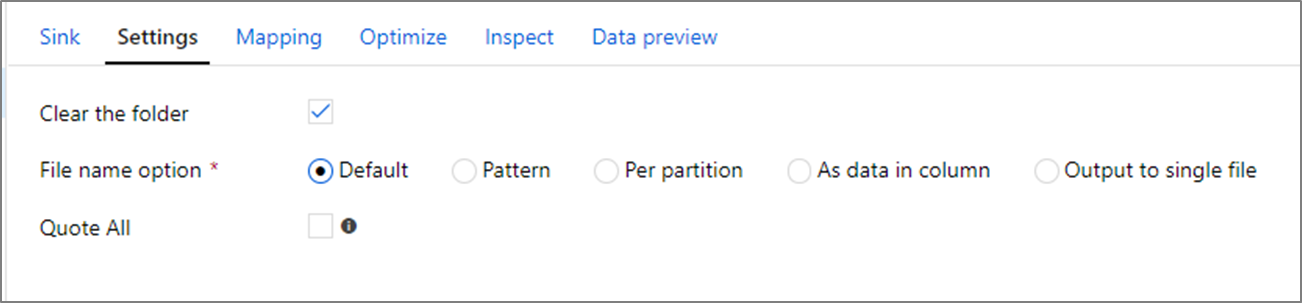
Varsayılan seçeneğinin seçilmesi en hızlı şekilde yazılır. Her bölüm Spark varsayılan adıyla bir dosyaya eşit. Bu, yalnızca veri klasöründen okuyorsanız kullanışlıdır.
Adlandırma Düzeni ayarlamak, her bölüm dosyasını daha kolay bir adla yeniden adlandırır. Bu işlem yazma işleminden sonra gerçekleşir ve varsayılanı seçmekten biraz daha yavaştır.
Bölüm başına, her bir bölümü el ile adlandırmanıza olanak tanır.
Bir sütun, verilerin çıkışını nasıl almak istediğinize karşılık geliyorsa, Dosyayı sütun verileri olarak adlandır'ı seçebilirsiniz. Bu, verileri yeniden dağıtır ve sütunlar eşit olarak dağıtılmadıysa performansı etkileyebilir.
Bir sütun, klasör adlarını oluşturma şeklinize karşılık geliyorsa, Klasörü sütun verileri olarak adlandır'ı seçin.
Tek bir dosyaya çıkış, tüm verileri tek bir bölümde birleştirir. Bu, özellikle büyük veri kümeleri için uzun yazma sürelerine yol açar. Bu seçeneği kullanmak için açık bir iş nedeni olmadığı sürece önerilmez.
Azure Cosmos DB havuzları
Azure Cosmos DB'ye yazarken, veri akışı yürütme sırasında aktarım hızını ve toplu iş boyutunu değiştirmek performansı geliştirebilir. Bu değişiklikler yalnızca veri akışı etkinlik çalıştırması sırasında geçerlilik kazanır ve sonuç elde ettikten sonra özgün koleksiyon ayarlarına döner.
Toplu iş boyutu: Genellikle, varsayılan toplu iş boyutuyla başlamak yeterlidir. Bu değeri daha fazla ayarlamak için verilerinizin kaba nesne boyutunu hesaplayın ve nesne boyutunun * toplu iş boyutunun 2 MB'tan küçük olduğundan emin olun. Bu durumda, daha iyi aktarım hızı elde etmek için toplu iş boyutunu artırabilirsiniz.
Aktarım hızı: Belgelerin Azure Cosmos DB'ye daha hızlı yazabilmesi için burada daha yüksek bir aktarım hızı ayarı ayarlayın. Yüksek aktarım hızı ayarına bağlı olarak daha yüksek RU maliyetlerini göz önünde bulundurun.
Yazma aktarım hızı bütçesi: Dakikada toplam RU'dan daha küçük bir değer kullanın. Çok sayıda Spark bölümü içeren bir veri akışınız varsa, bütçe aktarım hızı ayarlamak bu bölümler arasında daha fazla denge sağlar.
İlgili içerik
- Veri akışı performansına genel bakış
- Kaynakları iyileştirme
- Dönüştürmeleri iyileştirme
- İşlem hatlarında veri akışlarını kullanma
Performansla ilgili diğer Veri Akışı makalelere bakın: