Dönüştürmeleri iyileştirme
Azure Data Factory ve Azure Synapse Analytics işlem hatlarındaki eşleme veri akışlarında dönüşümlerin performansını iyileştirmek için aşağıdaki stratejileri kullanın.
Birleştirmeleri, Var Olan ve Aramaları İyileştiren
Yayın
Birleştirmelerde, aramalarda ve var olan dönüştürmelerde, veri akışlarından biri veya her ikisi de çalışan düğümü belleğine sığacak kadar küçükse, Yayını etkinleştirerek performansı en iyi duruma getirebilirsiniz. Yayın, kümedeki tüm düğümlere küçük veri çerçeveleri gönderdiğiniz zamandır. Bu, Spark altyapısının büyük akıştaki verileri yeniden birleştirmeden birleştirme gerçekleştirmesine olanak tanır. Varsayılan olarak Spark altyapısı, birleştirmenin bir tarafının yayınlanıp yayınlanmaymayacağına otomatik olarak karar verir. Gelen verileriniz hakkında bilgi sahibiyseniz ve bir akışın diğerinden küçük olduğunu biliyorsanız Sabit yayın'ı seçebilirsiniz. Sabit yayın, Spark'ı seçili akışı yayınlamaya zorlar.
Yayınlanan verilerin boyutu Spark düğümü için çok büyükse bellek yetersiz hatası alabilirsiniz. Yetersiz bellek hatalarını önlemek için bellek için iyileştirilmiş kümeleri kullanın. Veri akışı yürütmeleri sırasında yayın zaman aşımlarıyla karşılaşırsanız yayın iyileştirmesini kapatabilirsiniz. Ancak bu, veri akışlarının daha yavaş gerçekleştirilerek sonuçlanmasıyla sonuçlanıyor.
Büyük veritabanı sorguları gibi sorgulaması daha uzun sürebilecek veri kaynaklarıyla çalışırken, birleştirmeler için yayının kapatılması önerilir. Uzun sorgu süreleri olan kaynak, küme işlem düğümlerine yayınlamayı denediğinde Spark zaman aşımlarına neden olabilir. Yayını kapatmak için bir diğer iyi seçenek de veri akışınızda daha sonra arama dönüşümünde kullanılacak değerleri toplayan bir akışınız olmasıdır. Bu düzen Spark iyileştiricisinin kafasını karıştırabilir ve zaman aşımlarına neden olabilir.
Çapraz birleşimler
Birleştirme koşullarınızda değişmez değerler kullanıyorsanız veya birleştirmenin her iki tarafında birden çok eşleşme varsa Spark, birleştirmeyi çapraz birleşim olarak çalıştırır. Çapraz birleşim, daha sonra birleştirilen değerleri filtreleyen tam kartezyen bir üründür. Bu, diğer birleştirme türlerinden daha yavaştır. Performans etkisini önlemek için birleştirme koşullarınızın her iki tarafında da sütun başvuruları olduğundan emin olun.
Birleştirmelerden önce sıralama
SSIS gibi araçlarda birleştirme birleştirme işleminden farklı olarak birleştirme dönüşümü zorunlu birleştirme birleştirme işlemi değildir. Birleştirme anahtarları, dönüştürmeden önce sıralama gerektirmez. Eşleme veri akışlarında Sıralama dönüşümlerinin kullanılması önerilmez.
Pencere dönüştürme performansı
Eşleme veri akışındaki Pencere dönüşümü, dönüştürme ayarlarında yan tümcesinin over() bir parçası olarak seçtiğiniz sütunlarda verilerinizi değere göre bölümler. Windows dönüşümünde kullanıma sunulan birçok popüler toplama ve analiz işlevi vardır. Ancak, kullanım örneğiniz derecelendirme rank() veya satır numarası rowNumber()için veri kümenizin tamamı üzerinde bir pencere oluşturmaksa, bunun yerine Derece dönüştürmesini ve Vekil Anahtar dönüştürmesini kullanmanız önerilir. Bu dönüşümler, bu işlevleri kullanarak tam veri kümesi işlemlerini yeniden daha iyi gerçekleştirir.
Çarpık verileri yeniden bölümleme
Birleştirmeler ve toplamalar gibi bazı dönüştürmeler veri bölümlerinizi yeniden karıştırır ve bazen verilerin dengesiz hale getirilmesine neden olabilir. Çarpık veriler, verilerin bölümler arasında eşit bir şekilde dağıtıldığı anlamına gelir. Yoğun şekilde dengesiz veriler, daha yavaş aşağı akış dönüşümlerine ve havuz yazma işlemlerine yol açabilir. İzleme ekranındaki dönüştürmeye tıklayarak bir veri akışı çalıştırmasının herhangi bir noktasında verilerinizin dengesizliğini de kontrol edebilirsiniz.
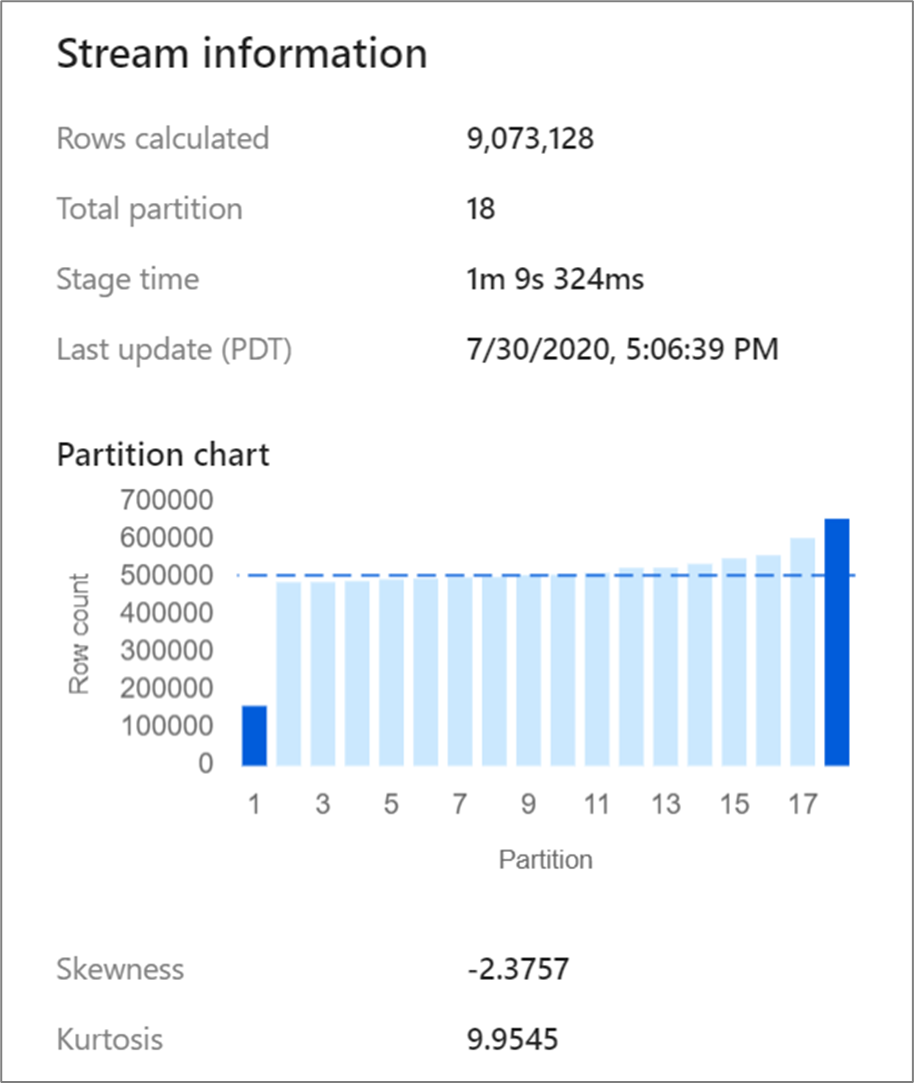
İzleme ekranı, iki ölçümle birlikte verilerin her bölüme nasıl dağıtıldığını gösterir: çarpıklık ve basıklık. Çarpıklık , verilerin ne kadar asimetrik olduğunu gösteren bir ölçüdür ve pozitif, sıfır, negatif veya tanımsız bir değere sahip olabilir. Negatif eğme, sol kuyruğun sağdan daha uzun olduğu anlamına gelir. Kurtosis , verilerin ağır kuyruklu veya hafif kuyruklu olup olmadığının ölçüsüdür. Yüksek basıklık değerleri arzu edilmez. İdeal eğrilik aralıkları -3 ile 3 arasındadır ve kurtoz aralıkları 10'dan azdır. Bu sayıları yorumlamanın kolay bir yolu, bölüm grafiğine bakmak ve 1 çubuğun diğerlerinden daha büyük olup olmadığını görmektir.
Verileriniz bir dönüştürmeden sonra eşit bir şekilde bölümlenmezse, yeniden bölümlendirmek için en iyi duruma getirme sekmesini kullanabilirsiniz. Verilerin yeniden yapılandırılması zaman alır ve veri akışı performansınızı geliştirmeyebilir.
Bahşiş
Verilerinizi yeniden bölümlemenize rağmen verilerinizi yeniden oluşturan aşağı akış dönüşümleriniz varsa birleştirme anahtarı olarak kullanılan bir sütunda karma bölümleme kullanın.
Dekont
Veri akışınızdaki dönüştürmeler (Havuz dönüşümü dışında), bekleyen verilerin dosya ve klasör bölümlemesi üzerinde değişiklik yapmaz. Her dönüştürmede bölümleme, verileri ADF'nin veri akışı yürütmelerinizin her biri için yönettiği geçici sunucusuz Spark kümesinin veri çerçeveleri içinde yeniden bölümler.
İlgili içerik
- Veri akışı performansına genel bakış
- Kaynakları iyileştirme
- Havuzları iyileştirme
- İşlem hatlarında veri akışlarını kullanma
Performansla ilgili diğer Veri Akışı makalelere bakın:
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin