Kaynakları iyileştirme
Azure SQL Veritabanı dışındaki her kaynak için Seçili değer olarak Geçerli bölümleyi kullan seçeneğini tutmanız önerilir. Diğer tüm kaynak sistemlerden okurken, veri akışları verilerin boyutuna göre verileri otomatik olarak eşit olarak bölümler. Yaklaşık her 128 MB veri için yeni bir bölüm oluşturulur. Veri boyutunuz arttıkça bölüm sayısı artar.
Spark verileri okuduktan ve veri akışı performansınızı olumsuz etkiledikten sonra özel bölümlemeler gerçekleşir. Veriler okumada eşit olarak bölümlendiğinden, önce verilerinizin şeklini ve kardinalitesini anlamadığınız sürece önerilmez.
Dekont
Okuma hızları, kaynak sisteminizin aktarım hızıyla sınırlanabilir.
Azure SQL Veritabanı kaynakları
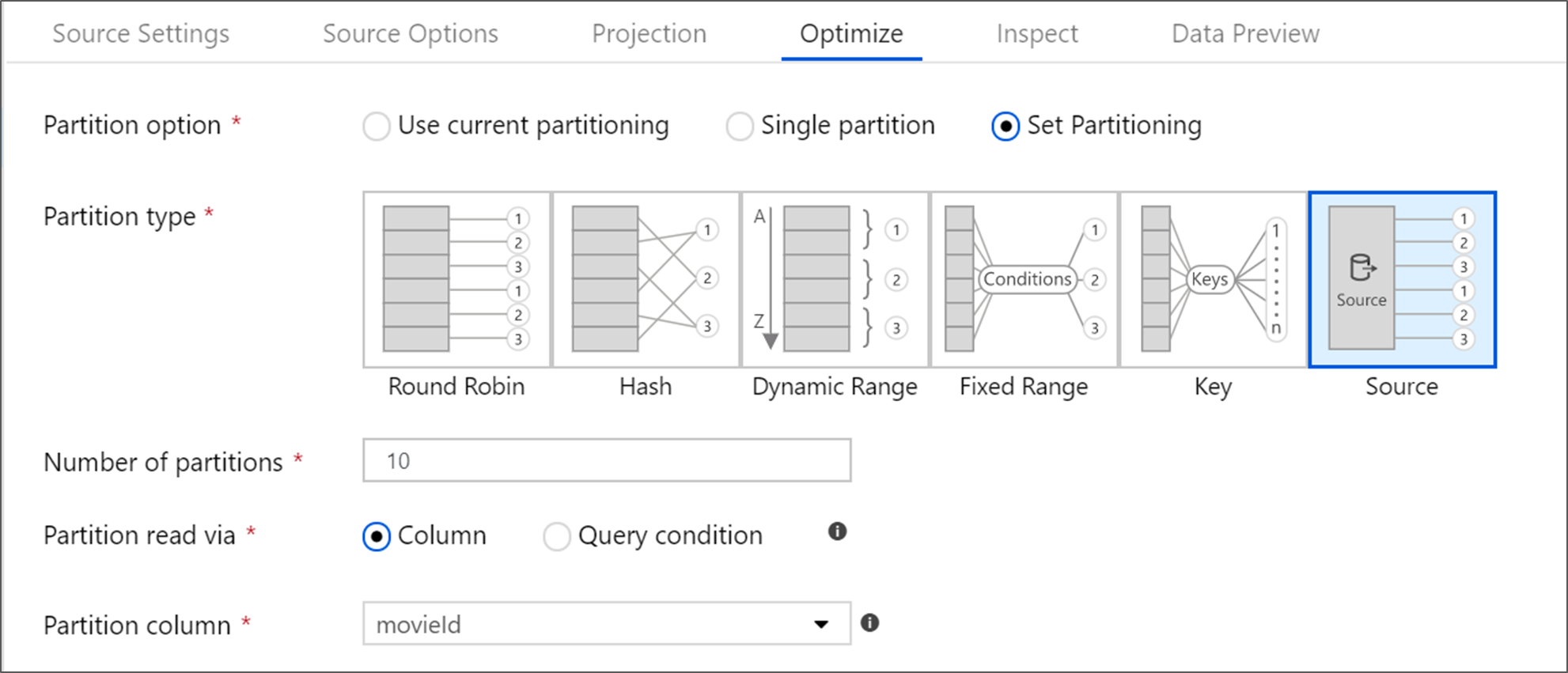
Azure SQL Veritabanı 'Kaynak' bölümleme adlı benzersiz bir bölümleme seçeneğine sahiptir. Kaynak bölümlemenin etkinleştirilmesi, kaynak sistemde paralel bağlantıları etkinleştirerek Azure SQL Veritabanı okuma sürelerinizi iyileştirebilir. Bölüm sayısını ve verilerinizin nasıl bölümleneceğini belirtin. Yüksek kardinaliteye sahip bir bölüm sütunu kullanın. Kaynak tablonuzun bölümleme düzeniyle eşleşen bir sorgu da girebilirsiniz.
Bahşiş
Kaynak bölümleme için SQL Server'ın G/Ç'sinde performans sorunu vardır. Çok fazla bölüm eklemek kaynak veritabanınızı doyurabilir. Bu seçenek kullanıldığında genellikle dört veya beş bölüm idealdir.
Yalıtım düzeyi
Azure SQL kaynak sistemindeki okumanın yalıtım düzeyi performansı etkiler. 'Okunmadı' seçildiğinde en hızlı performans sağlanır ve veritabanı kilitleri engellenir. SQL Yalıtım düzeyleri hakkında daha fazla bilgi edinmek için bkz . Yalıtım düzeylerini anlama.
Sorgu kullanarak okuma
Tablo veya SQL sorgusu kullanarak Azure SQL Veritabanı okuyabilirsiniz. SQL sorgusu yürütüyorsanız, dönüştürmenin başlayabilmesi için önce sorgunun tamamlanması gerekir. SQL Sorguları daha hızlı yürütülebilecek işlemleri göndermek ve SELECT, WHERE ve JOIN deyimleri gibi bir SQL Server'dan okunan veri miktarını azaltmak için yararlı olabilir. İşlemleri aşağı doğru iterken, veriler veri akışına girmeden önce köken ve dönüşümlerin performansını izleme özelliğini kaybedersiniz.
Azure Synapse Analytics kaynakları
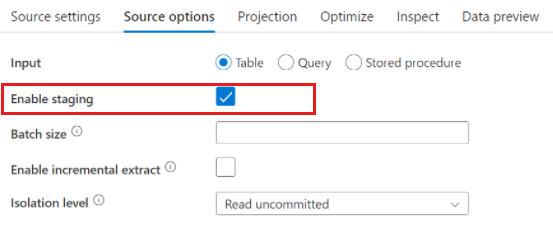
Azure Synapse Analytics kullanırken, kaynak seçeneklerde Hazırlamayı etkinleştir adlı bir ayar bulunur. Bu, hizmetin kullanarak Synapse'den Stagingokumasına olanak tanır. Bu, CETAS ve COPY komutu gibi en yüksek performanslı toplu yükleme özelliğini kullanarak okuma performansını büyük ölçüde artırır. Etkinleştirme, Staging veri akışı etkinlik ayarlarında bir Azure Blob Depolama veya Azure Data Lake Depolama 2. nesil hazırlama konumu belirtmenizi gerektirir.
Dosya tabanlı kaynaklar
Parquet ve sınırlandırılmış metin karşılaştırması
Veri akışları çeşitli dosya türlerini desteklese de, en uygun okuma ve yazma süreleri için Spark yerel Parquet biçimi önerilir.
Bir dosya kümesinde aynı veri akışını çalıştırıyorsanız, joker karakter yollarını kullanarak veya dosya listesinden okuma kullanarak bir klasörden okumanızı öneririz. Tek bir veri akışı etkinlik çalıştırması, tüm dosyalarınızı toplu olarak işleyebilir. Bu ayarları yapılandırma hakkında daha fazla bilgi Azure Blob Depolama bağlayıcısı belgelerinin Kaynak dönüştürme bölümünde bulunabilir.
Mümkünse, veri akışlarını bir dosya kümesi üzerinde çalıştırmak için For-Each etkinliğini kullanmaktan kaçının. Bu, for-each için her yinelemenin genellikle gerekli olmayan ve pahalı olabilecek kendi Spark kümesini oluşturmasına neden olur.
Satır içi veri kümeleri ile paylaşılan veri kümeleri karşılaştırması
ADF ve Synapse veri kümeleri, fabrikalarınızda ve çalışma alanlarınızda paylaşılan kaynaklardır. Ancak, sınırlandırılmış metin ve JSON kaynaklarıyla çok sayıda kaynak klasör ve dosya okurken Projeksiyon | içinde "Kullanıcı tarafından yansıtılan şema" seçeneğini ayarlayarak veri akışı dosya bulma performansını geliştirebilirsiniz Şema seçenekleri iletişim kutusu. Bu seçenek, ADF'nin varsayılan şema otomatik bulmasını kapatır ve dosya bulma performansını büyük ölçüde artırır. Bu seçeneği ayarlamadan önce, ADF'nin projeksiyon için mevcut bir şeması olması için projeksiyonu içeri aktardığından emin olun. Bu seçenek şema kayması ile çalışmaz.
İlgili içerik
- Veri akışı performansına genel bakış
- Havuzları iyileştirme
- Dönüştürmeleri iyileştirme
- İşlem hatlarında veri akışlarını kullanma
Performansla ilgili diğer Veri Akışı makalelere bakın: