Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
ŞUNLARA UYGULANIR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
İpucu
Microsoft Fabric'daki
bir Azure Data Factory veya Synapse Analytics çalışma alanında işlem hattı, bağlı işlem hizmetlerini kullanarak bağlı depolama hizmetlerindeki verileri işler. Her etkinliğin belirli bir işleme işlemini gerçekleştirdiği bir etkinlik dizisi içerir. Bu makalede, Azure Data Lake Analytics işlem bağlı hizmetinde U-SQL betiği çalıştıran Data Lake Analytics U-SQL Etkinliği açıklanmaktadır.
Data Lake Analytics U-SQL Etkinliği ile işlem hattı oluşturmadan önce bir Azure Data Lake Analytics hesabı oluşturun. Azure Data Lake Analytics hakkında bilgi edinmek için bkz. Azure Data Lake Analytics ile çalışmaya başlama.
Kullanıcı arabirimiyle işlem hattına Azure Data Lake Analytics için U-SQL etkinliği ekleme
İşlem hattında Azure Data Lake Analytics için U-SQL etkinliği kullanmak için aşağıdaki adımları tamamlayın:
İşlem hattı Etkinlikleri bölmesinde Veri Gölü arayın ve bir U-SQL etkinliğini işlem hattı tuvaline sürükleyin.
Henüz seçili değilse tuvaldeki yeni U-SQL etkinliğini seçin.
U-SQL etkinliğini yürütmek için kullanılacak yeni bir Azure Data Lake Analytics bağlı hizmeti seçmek veya oluşturmak için ADLA Hesabı sekmesini seçin.
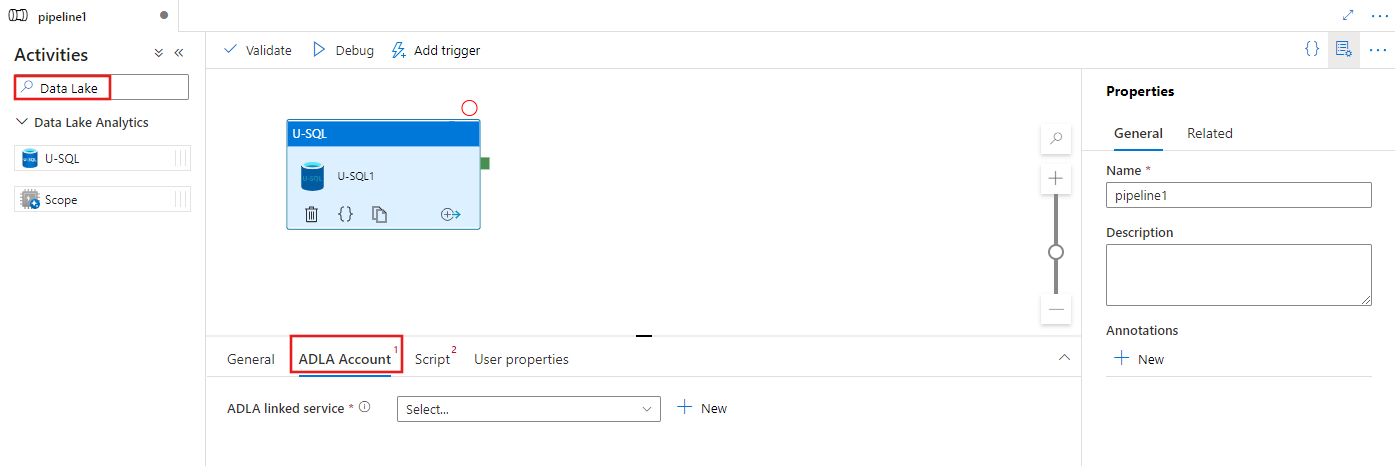
Yeni bir depolama bağlı hizmeti seçmek veya oluşturmak için Betik sekmesini ve betiği barındıracak depolama konumu içinde bir yol seçin.
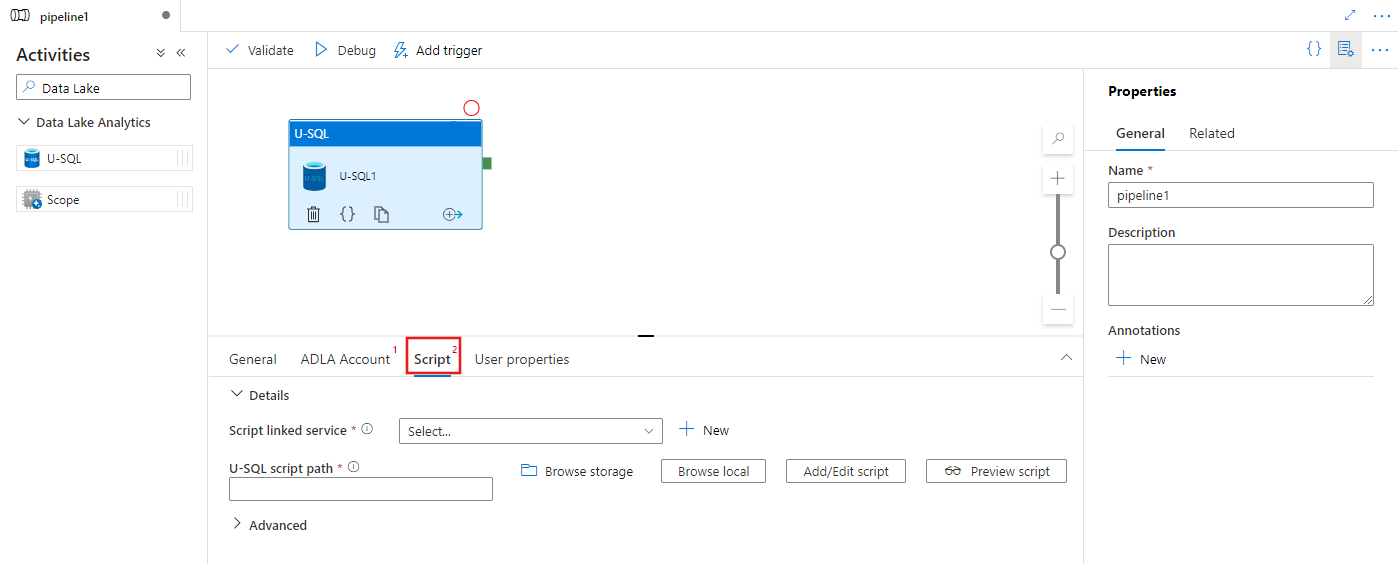
Azure Data Lake Analytics bağlı hizmeti
Azure Data Lake Analytics işlem hizmetini bir Azure Data Factory veya Synapse Analytics çalışma alanına bağlamak için bir Azure Data Lake Analytics bağlı hizmeti oluşturursunuz. İşlem hattındaki Data Lake Analytics U-SQL etkinliği bu bağlı hizmeti ifade eder.
Aşağıdaki tabloda, JSON tanımında kullanılan genel özellikler için açıklamalar sağlanmaktadır.
| Özellik | Açıklama | Gerekli |
|---|---|---|
| tip | type özelliği şu şekilde ayarlanmalıdır: AzureDataLakeAnalytics. | Yes |
| accountName | Hesap Adı'Azure Data Lake Analytics. | Yes |
| dataLakeAnalyticsUri | Azure Data Lake Analytics URI'si. | Hayır |
| subscriptionId | Azure abonelik kimliği | Hayır |
| resourceGroupName | Azure kaynak grubu adı | Hayır |
Hizmet sorumlusu kimlik doğrulaması
bağlı Azure Data Lake Analytics hizmet, Azure Data Lake Analytics hizmetine bağlanmak için hizmet sorumlusu kimlik doğrulaması gerektirir. Hizmet sorumlusu kimlik doğrulamasını kullanmak için bir uygulama varlığını Microsoft Entra ID'a kaydedin ve hem Data Lake Analytics hem de kullandığı Veri Gölü Mağazası'na erişim verin. Ayrıntılı adımlar için bkz . Hizmet-hizmet kimlik doğrulaması. Bağlı hizmeti tanımlamak için kullandığınız aşağıdaki değerleri not edin:
- Uygulama Kimliği
- Uygulama anahtarı
- Kiracı kimliği
Kullanıcı Ekle Sihirbazı kullanarak Azure Data Lake Analytics hizmet sorumlusuna izin verin.
Aşağıdaki özellikleri belirterek hizmet sorumlusu kimlik doğrulamasını kullanın:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| servicePrincipalId | Uygulamanın istemci kimliğini belirtin. | Yes |
| servicePrincipalKey | Uygulamanın anahtarını belirtin. | Yes |
| kiracı | Uygulamanızın bulunduğu kiracı bilgilerini (etki alanı adı veya kiracı kimliği) belirtin. Fareyi Azure portalın sağ üst köşesine getirerek alabilirsiniz. | Yes |
Örnek: Hizmet sorumlusu kimlik doğrulaması
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Bağlı hizmet hakkında daha fazla bilgi edinmek için Bağlı hizmetleri hesaplama'ya bakın.
Data Lake Analytics U-SQL Görevi
Aşağıdaki JSON kod parçacığı, Data Lake Analytics U-SQL Etkinliği ile bir işlem hattı tanımlar. Etkinlik tanımı, daha önce oluşturduğunuz Azure Data Lake Analytics bağlı hizmete başvuru içerir. Data Lake Analytics U-SQL betiğini yürütmek için hizmet, belirttiğiniz betiği Data Lake Analytics'e gönderir ve Data Lake Analytics'in gerekli verileri getirmesi ve çıktı üretmesi için gereken giriş ve çıkışlar betikte tanımlanır.
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
Aşağıdaki tabloda, bu etkinliğe özgü özelliklerin adları ve açıklamaları açıklanmaktadır.
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Adı | İşlem hattındaki etkinliğin adı | Yes |
| açıklama | Etkinliğin ne yaptığını açıklayan metin. | Hayır |
| Tip | Data Lake Analytics U-SQL etkinliği için etkinlik türü DataLakeAnalyticsU-SQL şeklindedir. | Yes |
| bağlantılıHizmetAdı | bağlı hizmet Azure Data Lake Analytics. Bu bağlı hizmet hakkında bilgi edinmek için Bağlı hizmetleri hesaplama makalesine bakın. | Yes |
| scriptPath | U-SQL betiğini içeren klasörün yolu. Dosyanın adı büyük/küçük harfe duyarlıdır. | Yes |
| scriptLinkedService | Betik içeren Azure Data Lake Store veya Azure Depolama ile bağlantı kuran bağlı hizmet | Yes |
| degreeOfParallelism (Paralellik Derecesi) | İşi çalıştırmak için aynı anda kullanılan en fazla düğüm sayısı. | Hayır |
| öncelik | Kuyruğa alınan işler arasından hangilerinin öncelikli olarak çalıştırılmak üzere seçilmesi gerektiğini belirler. Sayı ne kadar düşükse öncelik de o kadar yüksektir. | Hayır |
| parametreler | U-SQL betiğine geçirmek için parametreler. | Hayır |
| runtimeVersion | Kullanılacak U-SQL altyapısının çalışma zamanı sürümü. | Hayır |
| Derleme modu | U-SQL derleme modu. Şu değerlerden biri olmalıdır: Semantik: Yalnızca anlam denetimleri ve gerekli gizlilik denetimleri gerçekleştirin, Tam: Söz dizimi denetimi, iyileştirme, kod oluşturma vb. dahil olmak üzere tam derlemeyi gerçekleştirin, SingleBox: TargetType ayarı singlebox olarak ayarlanır. Bu özellik için bir değer belirtmezseniz, sunucu en uygun derleme modunu belirler. |
Hayır |
Betik tanımı için SearchLogProcessing.txt'e bakın.
Örnek U-SQL betiği
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
Yukarıdaki betik örneğinde, betiğin girişi ve çıkışı @in ve @out parametrelerinde tanımlanır. U-SQL betiğindeki @in ve @out parametreleri için değerler hizmet tarafından 'parameters' bölümü kullanılarak dinamik olarak geçirilir.
Azure Data Lake Analytics hizmetinde çalışan işler için işlem hattı tanımınızda degreeOfParallelism ve priority gibi diğer özellikleri belirtebilirsiniz.
Dinamik parametreler
Örnek işlem hattı tanımında, in ve out parametreleri sabit kodlanmış değerlerle atanır.
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
Bunun yerine dinamik parametreler kullanmak mümkündür. Örneğin:
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
Bu durumda, giriş dosyaları /datalake/input klasöründen alınmaya devam edilir ve çıkış dosyaları /datalake/output klasöründe oluşturulur. Dosya adları, işlem hattı tetiklendiğinde pencerenin başlangıç zamanına bağlı olarak dinamiktir.
İlgili içerik
Verileri başka şekillerde dönüştürmeyi açıklayan aşağıdaki makalelere bakın: