Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
ŞUNLARA UYGULANIR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
İpucu
Microsoft Fabric'daki
Veri fabrikası ve Synapse işlem hatlarındaki Spark etkinliği, Spark programını kendi veya isteğe bağlı HDInsight kümenizde yürütür. Bu makale , veri dönüştürme ve desteklenen dönüştürme etkinliklerine genel bir genel bakış sunan veri dönüştürme etkinlikleri makalesini oluşturur. İsteğe bağlı Bir Spark bağlı hizmeti kullandığınızda, hizmet verileri tam zamanında işlemeniz için otomatik olarak bir Spark kümesi oluşturur ve işlem tamamlandıktan sonra kümeyi siler.
Kullanıcı arabirimiyle işlem hattına Spark etkinliği ekleme
İşlem hattında Spark etkinliği kullanmak için aşağıdaki adımları tamamlayın:
İşlem hattı Etkinlikleri bölmesinde Spark'ı arayın ve spark etkinliğini işlem hattı tuvaline sürükleyin.
Henüz seçili değilse tuvaldeki yeni Spark etkinliğini seçin.
Spark etkinliğini yürütmek için kullanılacak bir HDInsight kümesine bağlı yeni bir hizmet seçmek veya oluşturmak için HDI Kümesi sekmesini seçin.
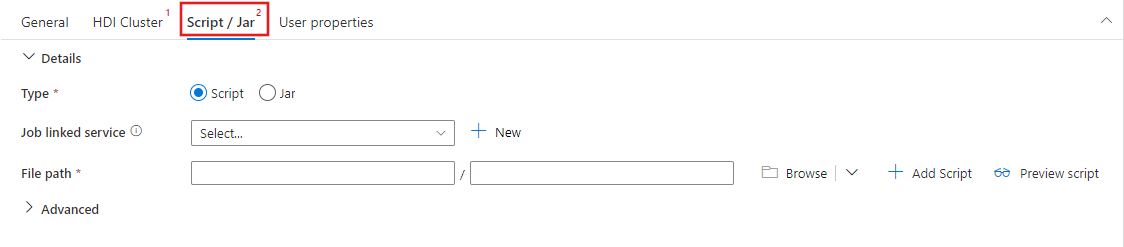
Script / Jar sekmesini seçerek veya yeni bir iş bağlı hizmeti oluşturmak için seçerek, betiğinizi barındıracak olan Azure Depolama hesabına bu hizmeti bağlayın. Orada yürütülecek dosyanın yolunu belirtin. Ayrıca, bir proxy kullanıcısı, hata ayıklama yapılandırması, bağımsız değişkenler ve Spark yapılandırma parametreleri dahil olmak üzere ileri düzey ayrıntıları betiğe iletilecek şekilde yapılandırabilirsiniz.
Spark etkinliği özellikleri
Spark Etkinliğinin örnek JSON tanımı aşağıda verilmiştir:
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
Aşağıdaki tabloda JSON tanımında kullanılan JSON özellikleri açıklanmaktadır:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Adı | İşlem hattındaki etkinliğin adı. | Yes |
| açıklama | Etkinliğin ne yaptığını açıklayan metin. | Hayır |
| Tip | Spark Etkinliği için etkinlik türü HDInsightSpark'tır. | Yes |
| bağlantılıHizmetAdı | Spark programının üzerinde çalıştığı HDInsight Spark Bağlı Hizmeti'nin adı. Bu bağlı hizmet hakkında bilgi edinmek için Compute bağlı hizmetler makalesine bakın. | Yes |
| SparkJobLinkedService | Spark iş dosyasını, bağımlılıklarını ve günlüklerini tutan Azure Depolama bağlantılı hizmet. Burada yalnızca Azure Blob Depolama ve ADLS 2. Nesil bağlı hizmetler desteklenir. Bu özellik için bir değer belirtmezseniz, HDInsight kümesiyle ilişkili depolama alanı kullanılır. Bu özelliğin değeri yalnızca Azure Depolama bağlı bir hizmet olabilir. | Hayır |
| kökDizin | Spark dosyasını içeren Azure Blob kapsayıcısı ve klasörü. Dosya adı büyük/küçük harfe duyarlıdır. Bu klasörün yapısı hakkında ayrıntılı bilgi için klasör yapısı bölümüne (sonraki bölüm) bakın. | Yes |
| girişDosyaYolu | Spark kodunun/paketinin kök klasörünün göreli yolu. Giriş dosyası bir Python dosyası veya .jar dosyası olmalıdır. | Yes |
| className | Uygulamanın Java/Spark ana sınıfı | Hayır |
| Bağımsız değişken | Spark programı için komut satırı bağımsız değişkenlerinin listesi. | Hayır |
| proxyUser | Spark programını yürütmek için kimliğine bürünülecek kullanıcı hesabı | Hayır |
| sparkConfig | Konu başlığında listelenen Spark yapılandırma özellikleri için değerleri belirtin: Spark Yapılandırması - Uygulama özellikleri. | Hayır |
| getDebugInfo | Spark günlük dosyalarının sparkJobLinkedService tarafından belirtilen HDInsight kümesi (veya) tarafından kullanılan Azure depolama alanına ne zaman kopyalandığı belirtir. İzin verilen değerler: Yok, Her Zaman veya Hata. Varsayılan değer: Hiçbiri. | Hayır |
Klasör yapısı
Spark işleri, Pig/Hive işlerinden daha fazla genişletilebilir. Spark işleri için jar paketleri (Java CLASSPATH'e yerleştirilen), Python dosyaları (PYTHONPATH'e yerleştirilen) ve diğer dosyalar gibi birden çok bağımlılık sağlayabilirsiniz.
HDInsight bağlı hizmeti tarafından başvuruda bulunan Azure Blob depolama alanında aşağıdaki klasör yapısını oluşturun. Ardından, bağımlı dosyaları entryFilePath ile temsil edilen kök klasördeki uygun alt klasörlere yükleyin. Örneğin, Python dosyalarını pyFiles alt klasörüne ve jar dosyalarını kök klasörün jars alt klasörüne yükleyin. Çalışma zamanında hizmet, Azure Blob depolamada aşağıdaki klasör yapısını bekler:
| Yol | Açıklama | Gerekli | Tür |
|---|---|---|---|
. (kök dizin) |
Depolama bağlantılı hizmetindeki Spark görevinin kök yolu | Yes | Klasör |
| <kullanıcı tanımlı > | Spark işinin giriş dosyasını gösteren yol | Yes | Dosya |
| ./jars | Bu klasörün altındaki tüm dosyalar karşıya yüklenir ve kümenin Java classpath'ine yerleştirilir. | Hayır | Klasör |
| ./pyFiles | Bu dizin altındaki tüm dosyalar yüklenir ve kümenin PYTHONPATH'ine yerleştirilir. | Hayır | Klasör |
| ./files | Bu klasörün altındaki tüm dosyalar karşıya yüklenir ve yürütücü çalışma dizinine yerleştirilir | Hayır | Klasör |
| ./Arşiv | Bu klasörün altındaki tüm dosyalar sıkıştırılmamış | Hayır | Klasör |
| ./loglar | Spark kümesindeki günlükleri içeren klasör. | Hayır | Klasör |
Azure Blob Depolama’de HDInsight bağlı hizmeti ile başvurulan iki Spark iş dosyası içeren bir depolama alanı örneği burada verilmiştir.
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
İlgili içerik
Verileri başka şekillerde dönüştürmeyi açıklayan aşağıdaki makalelere bakın: