Azure Data Factory'de bir Spark etkinliği kullanarak verileri bulutta dönüştürme
UYGULANANLAR:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
İpucu
Kuruluşlar için hepsi bir arada analiz çözümü olan Microsoft Fabric'te Data Factory'yi deneyin. Microsoft Fabric , veri taşımadan veri bilimine, gerçek zamanlı analize, iş zekasına ve raporlamaya kadar her şeyi kapsar. Yeni bir deneme sürümünü ücretsiz olarak başlatmayı öğrenin!
Bu öğreticide, Azure portalını kullanarak bir Azure Data Factory işlem hattı oluşturursunuz. Bu işlem hattı bir Spark etkinliği ve isteğe bağlı bir Azure HDInsight bağlı hizmetini kullanarak verileri dönüştürür.
Bu öğreticide aşağıdaki adımları gerçekleştireceksiniz:
- Veri fabrikası oluşturma.
- Spark etkinliği kullanan bir işlem hattı oluşturun.
- İşlem hattı çalıştırması tetikleyin.
- İşlem hattı çalıştırmasını izleme.
Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun.
Önkoşullar
Not
Azure ile etkileşim kurmak için Azure Az PowerShell modülünü kullanmanızı öneririz. Başlamak için bkz . Azure PowerShell'i yükleme. Az PowerShell modülüne nasıl geçeceğinizi öğrenmek için bkz. Azure PowerShell’i AzureRM’den Az’ye geçirme.
- Azure depolama hesabı. Bir Python betiği ve giriş dosyası oluşturup Azure Depolama hizmetine yüklersiniz. Spark programının çıktısı bu depolama hesabında depolanır. İsteğe bağlı Spark kümesi, birincil depolama alanıyla aynı depolama hesabını kullanır.
Not
HdInsight standart katmanda yalnızca genel amaçlı depolama hesaplarını destekler. Hesabın premium veya yalnızca blob depolama hesabı olmadığından emin olun.
- Azure PowerShell. Azure PowerShell’i yükleme ve yapılandırma bölümündeki yönergeleri izleyin.
Python betiğini Blob depolama hesabınıza yükleme
Aşağıdaki içeriğe sahip WordCount_Spark.py adlı bir Python dosyası oluşturun:
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()<storageAccountName>’i Azure depolama hesabınızın adıyla değiştirin. Ardından dosyayı kaydedin.
Azure Blob depolama alanında henüz yoksa adftutorial adlı bir kapsayıcı oluşturun.
Spark adlı bir klasör oluşturun.
Spark klasörünün altında script adlı bir alt klasör oluşturun.
WordCount_Spark.py dosyasını script alt klasörüne yükleyin.
Girdi dosyasını yükleme
- Bazı metinlerle minecraftstory.txt adlı bir dosya oluşturun. Spark programı bu metindeki sözcükleri sayar.
- Spark klasörünün altında inputfiles adlı bir alt klasör oluşturun.
- minecraftstory.txt dosyasını inputfiles alt klasörüne yükleyin.
Veri fabrikası oluşturma
Hızlı Başlangıç: Çalışmak için henüz bir veri fabrikanız yoksa veri fabrikası oluşturmak için Azure portalını kullanarak veri fabrikası oluşturma makalesindeki adımları izleyin.
Bağlı hizmetler oluşturma
Bu bölümde iki bağlı hizmet oluşturacaksınız:
- Bir Azure depolama hesabını veri fabrikasına bağlayan Azure Depolama bağlı hizmeti. Bu depolama alanı, isteğe bağlı HDInsight kümesi tarafından kullanılır. Ayrıca, çalıştırılacak Spark betiğini içerir.
- İsteğe bağlı HDInsight bağlı hizmeti. Azure Data Factory otomatik olarak bir HDInsight kümesi oluşturur ve Spark programını çalıştırır. Daha sonra, küme önceden yapılandırılmış bir süre boyunca boşta kaldığında HDInsight kümesini siler.
Azure Depolama bağlı hizmeti oluşturma
Giriş sayfasında, sol paneldeki Yönet sekmesine geçin.
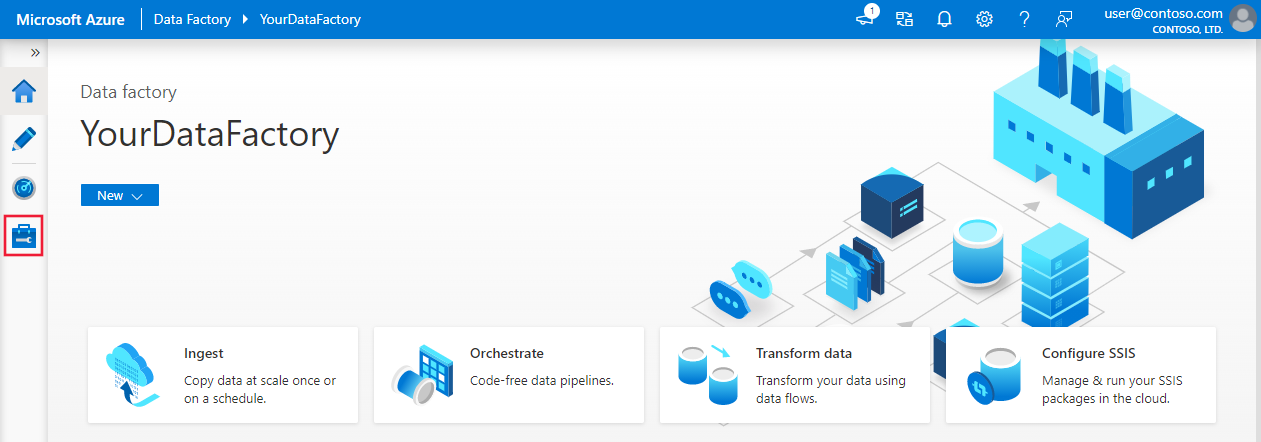
Pencerenin alt kısmındaki Bağlantılar’ı ve sonra + Yeni’yi seçin.
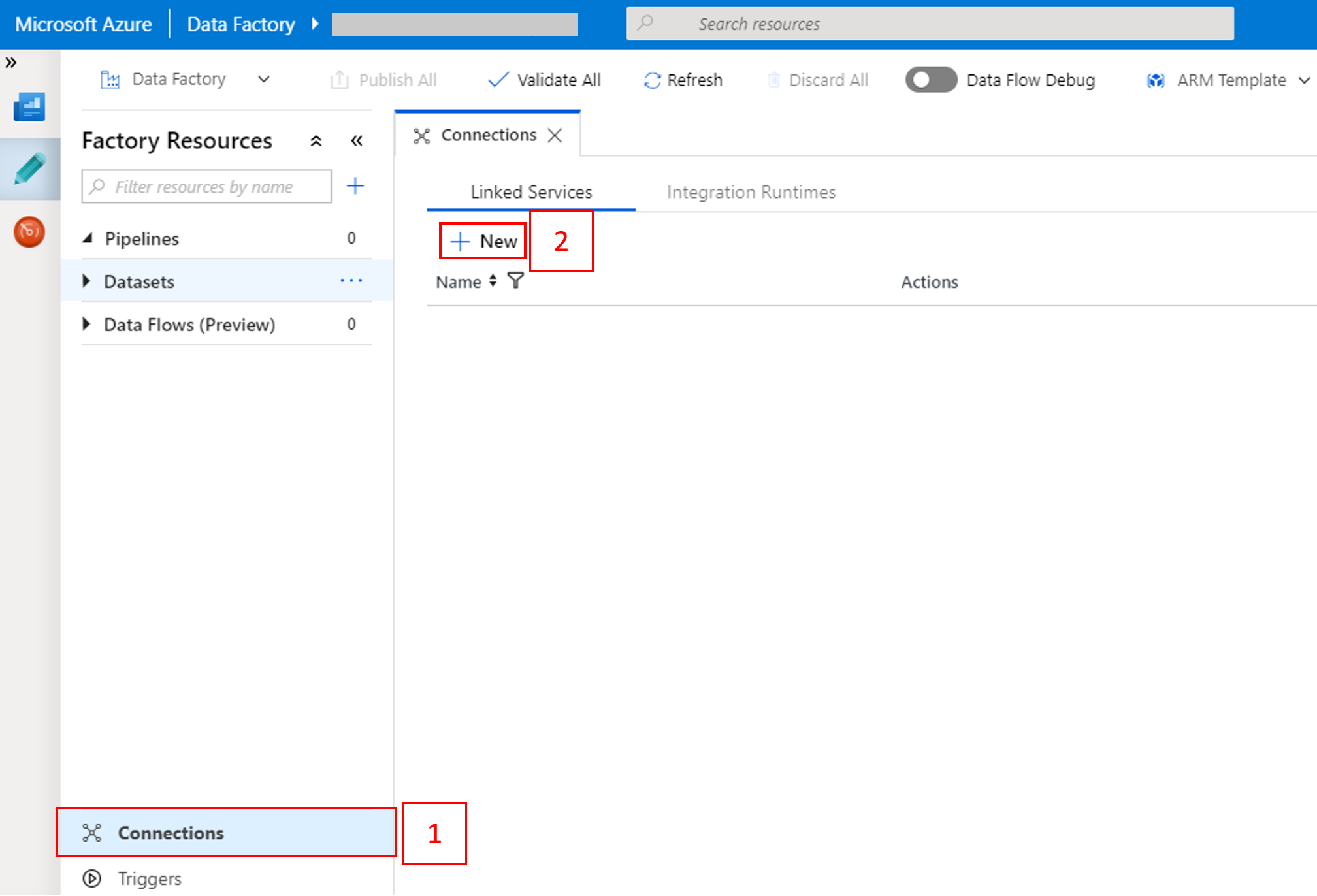
Yeni Bağlı Hizmet penceresinde Veri Deposu>Azure Blob Depolama’yı ve sonra Devam’ı seçin.

Depolama hesabı adı için listeden ad seçip Kaydet öğesini seçin.
İsteğe bağlı bir HDInsight bağlı hizmeti oluşturma
Başka bir bağlı hizmet oluşturmak için + Yeni düğmesini tekrar seçin.
Yeni Bağlı Hizmet penceresinde İşlem>Azure HDInsight’ı ve sonra Devam’ı seçin.

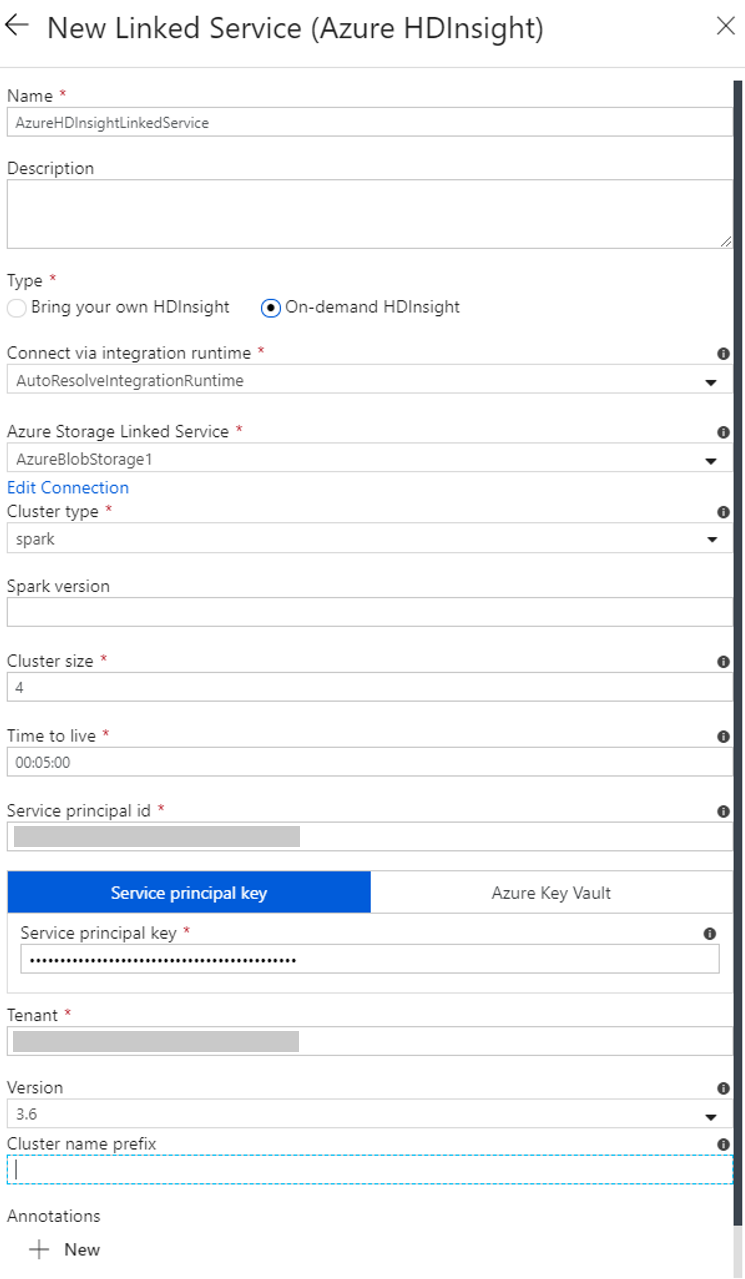
Yeni Bağlı Hizmet penceresinde aşağıdaki adımları tamamlayın:
a. Ad için AzureHDInsightLinkedService girin.
b. Tür içinİsteğe Bağlı HDInsight’ın seçili olduğunu onaylayın.
c. Azure Depolama Bağlı Hizmeti için AzureBlobStorage1'i seçin. Bu bağlı hizmeti daha önce oluşturmuştunuz. Farklı bir ad kullandıysanız, doğru adı burada belirtin.
d. Küme türü için spark’ı seçin.
e. Hizmet sorumlusu kimliği için, HDInsight kümesi oluşturma iznine sahip hizmet sorumlusunun kimliğini girin.
Bu hizmet sorumlusu, abonelikte ya da kümenin oluşturulduğu kaynak grubunda Katkıda Bulunan rolünün bir üyesi olmalıdır. Daha fazla bilgi için bkz . Microsoft Entra uygulaması ve hizmet sorumlusu oluşturma. Hizmet sorumlusu kimliği Uygulama Kimliği ile eşdeğerdir ve Hizmet sorumlusu anahtarı bir İstemci gizli dizisinin değerine eşdeğerdir.
f. Hizmet sorumlusu anahtarı için anahtarı girin.
r. Kaynak grubu için veri fabrikası oluştururken kullandığınız kaynak grubunun aynısını seçin. Spark kümesi bu kaynak grubunda oluşturulur.
h. İşletim sistemi türü seçeneğini genişletin.
i. Küme kullanıcısı adı için bir ad girin.
j. Kullanıcı için Küme parolası girin.
k. Bitir'i seçin.
Not
Azure HDInsight, desteklediği her bir Azure bölgesinde kullanabileceğiniz toplam çekirdek sayısını sınırlar. İsteğe bağlı HDInsight bağlı hizmeti için HDInsight kümesi, birincil depolama olarak kullanılan Azure Depolama konumunda oluşturulur. Kümenin başarıyla oluşturulabilmesi için yeterince çekirdek kotanızın olduğundan emin olun. Daha fazla bilgi için bkz. HDInsight’ta Hadoop, Spark, Kafka ve daha fazlası ile küme ayarlama.
İşlem hattı oluşturma
+ (artı) düğmesini ve sonra menüden İşlem Hattı'nı seçin.
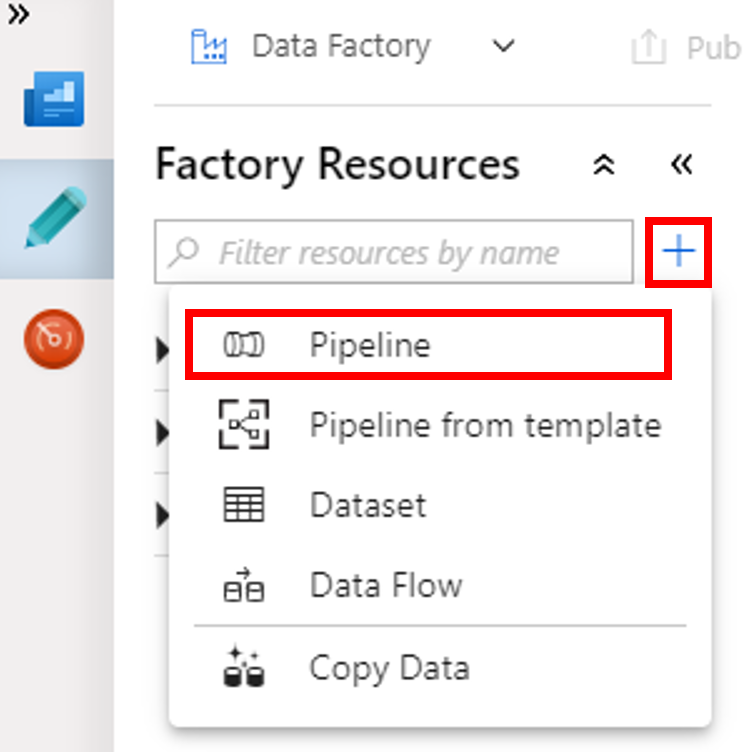
Etkinlikler araç kutusunda HDInsight’ı genişletin. Etkinlikler araç kutusundan Spark etkinliğini işlem hattı tasarımcısının yüzeyine sürükleyin.
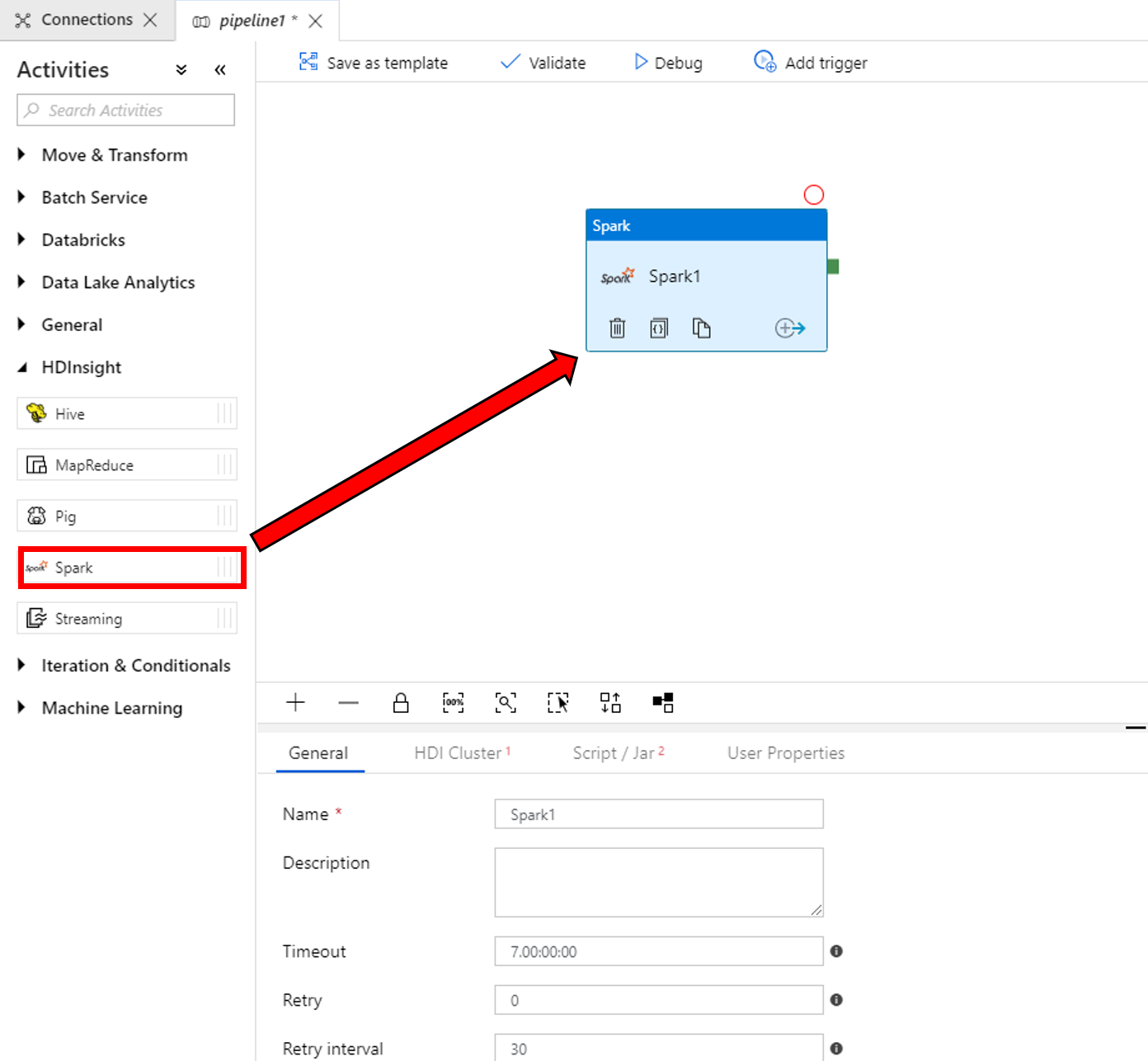
Alt kısımdaki Spark etkinlik penceresinin özellikler bölümünde aşağıdaki adımları tamamlayın:
a. HDI Kümesi sekmesine geçin.
b. Önceki yordamda oluşturduğunuz AzureHDInsightLinkedService hizmetini seçin.
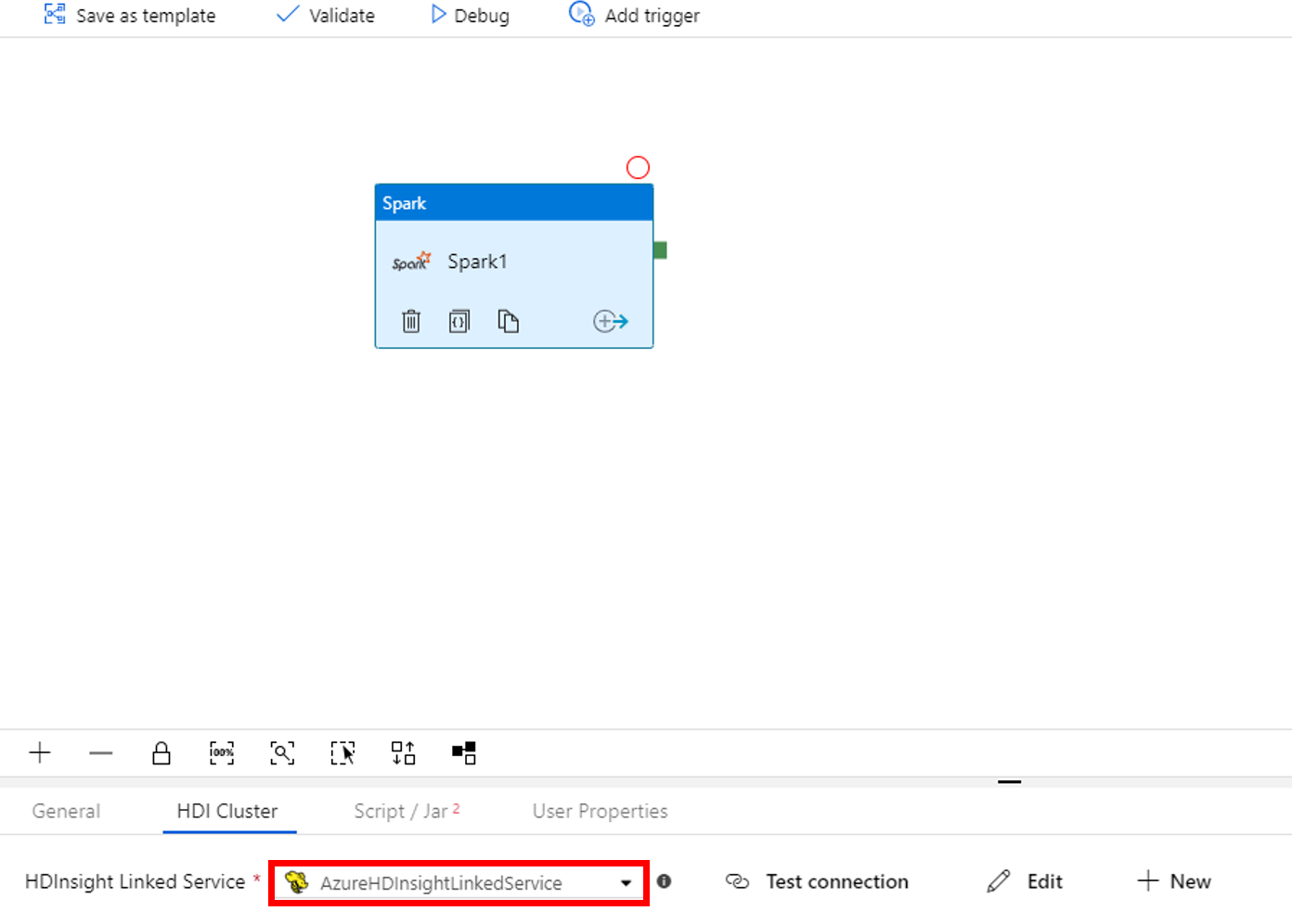
Betik/Jar sekmesine geçin ve aşağıdaki adımları tamamlayın:
a. İş Bağlı Hizmeti için AzureBlobStorage1'i seçin.
b. Depolamaya Gözat’ı seçin.

c. adftutorial/spark/script klasörüne göz atın, WordCount_Spark.py dosyasını seçin ve Son’a tıklayın.
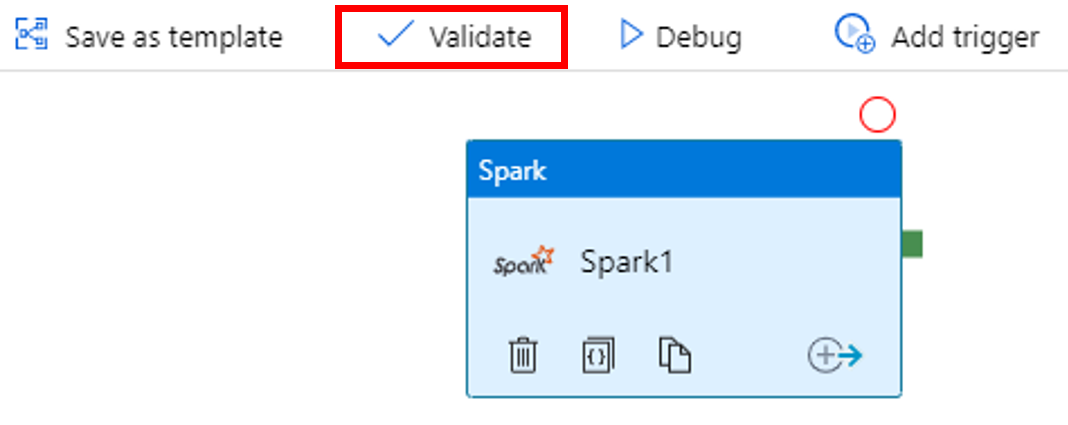
İşlem hattını doğrulamak için araç çubuğundaki Doğrula düğmesini seçin. Doğrulama penceresini kapatmak için >> (sağ ok) düğmesini seçin.
Tümünü Yayımla. Data Factory kullanıcı arabirimi, varlıkları (bağlı hizmetler ve işlem hattı) Azure Data Factory hizmetinde yayımlar.
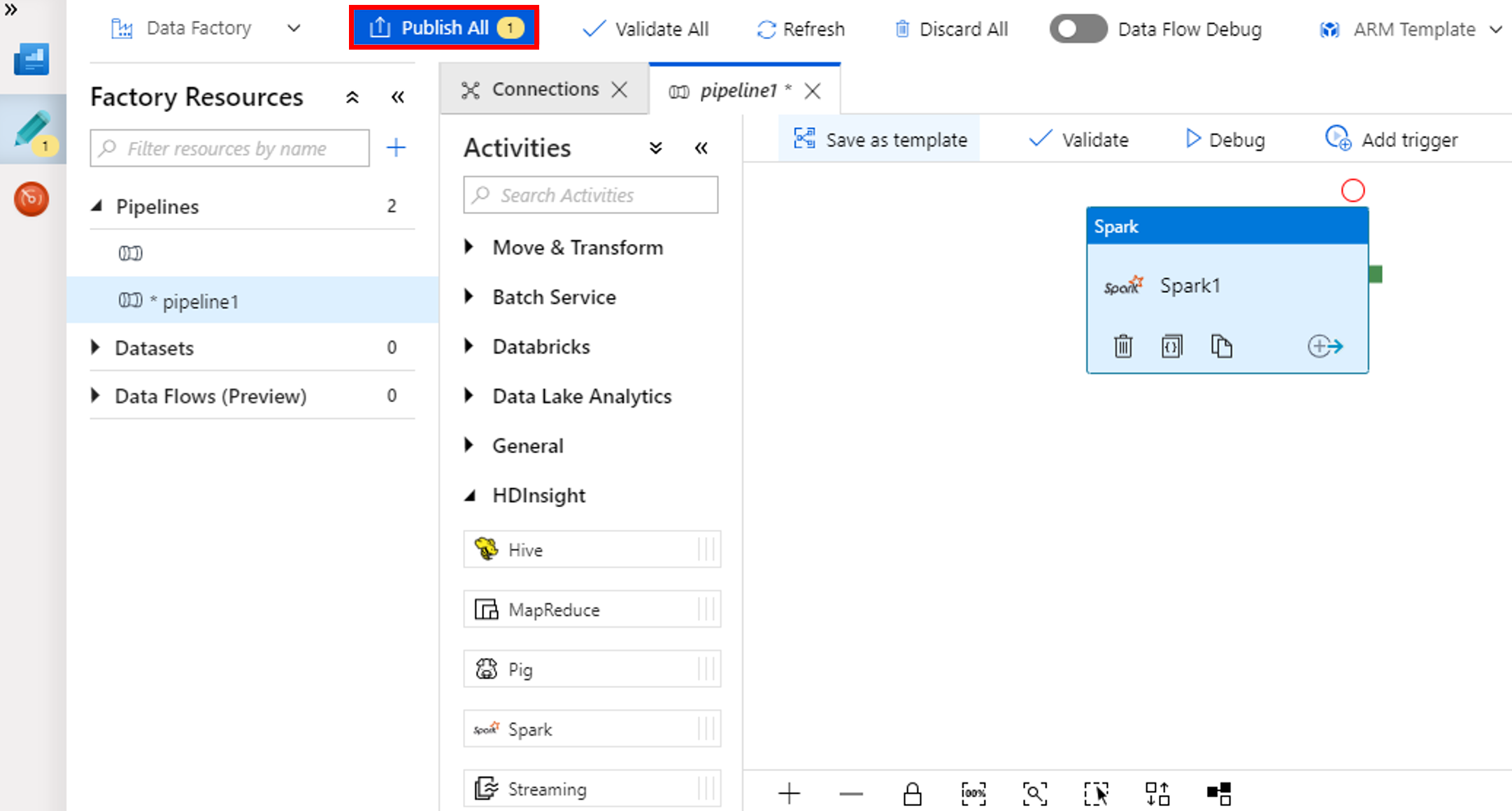
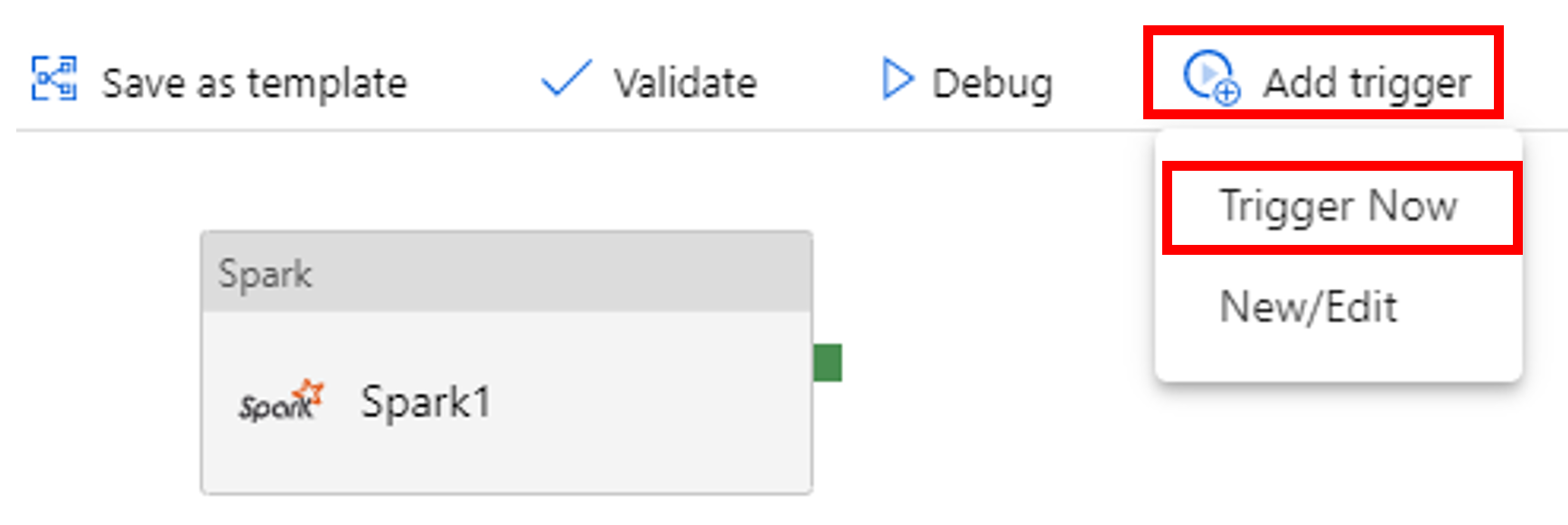
İşlem hattı çalıştırmasını tetikleme
Araç çubuğunda Tetikleyici Ekle'yi ve ardından Şimdi Tetikle'yi seçin.
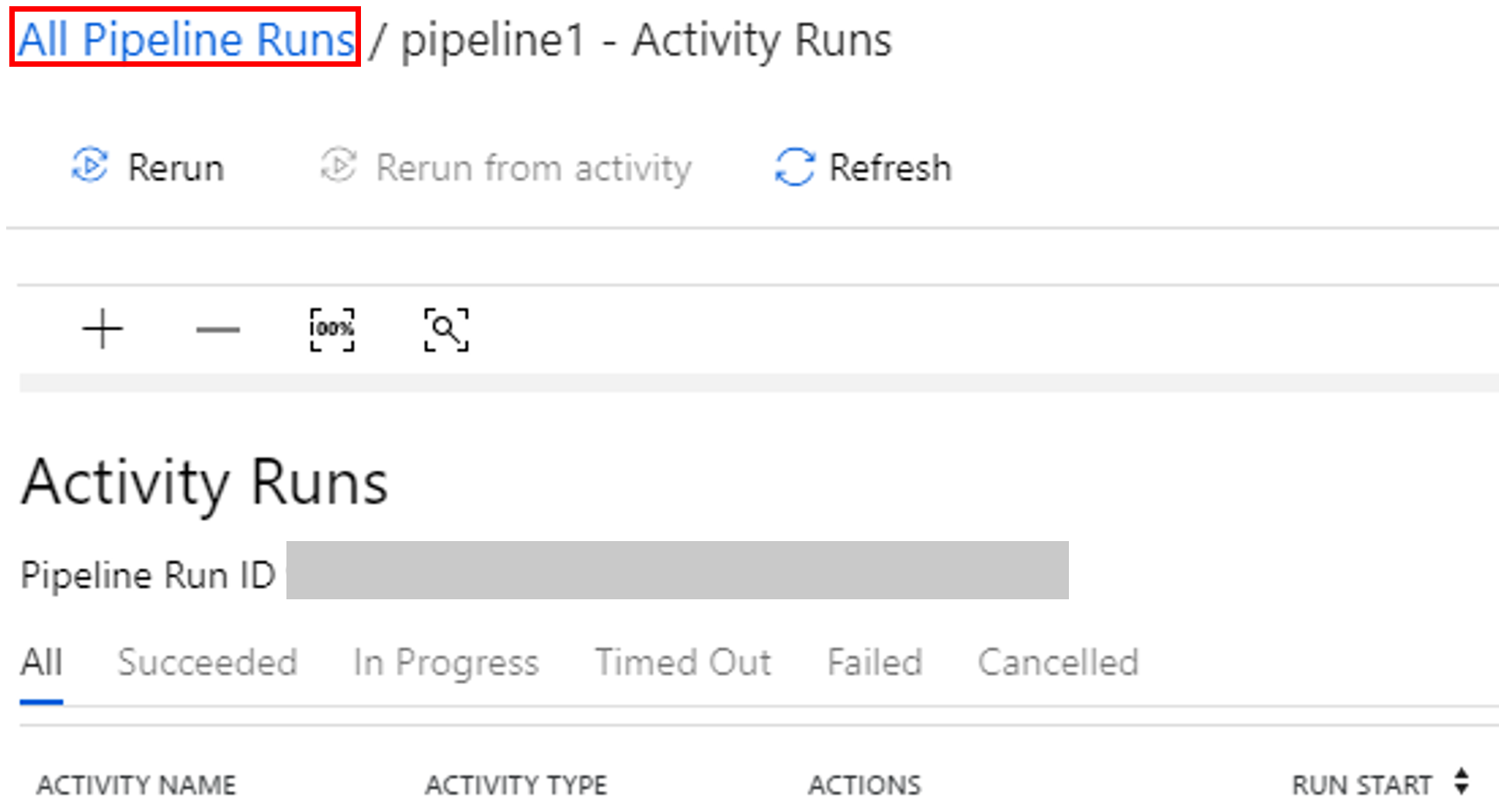
İşlem hattı çalıştırmasını izleme
İzleyici sekmesine geçin. İşlem hattı çalıştırması gördüğünüzden emin olun. Spark kümesi oluşturma işlemi yaklaşık 20 dakika sürer.
Düzenli aralıklarla Yenile’yi seçerek işlem hattı çalıştırmasının durumunu denetleyin.
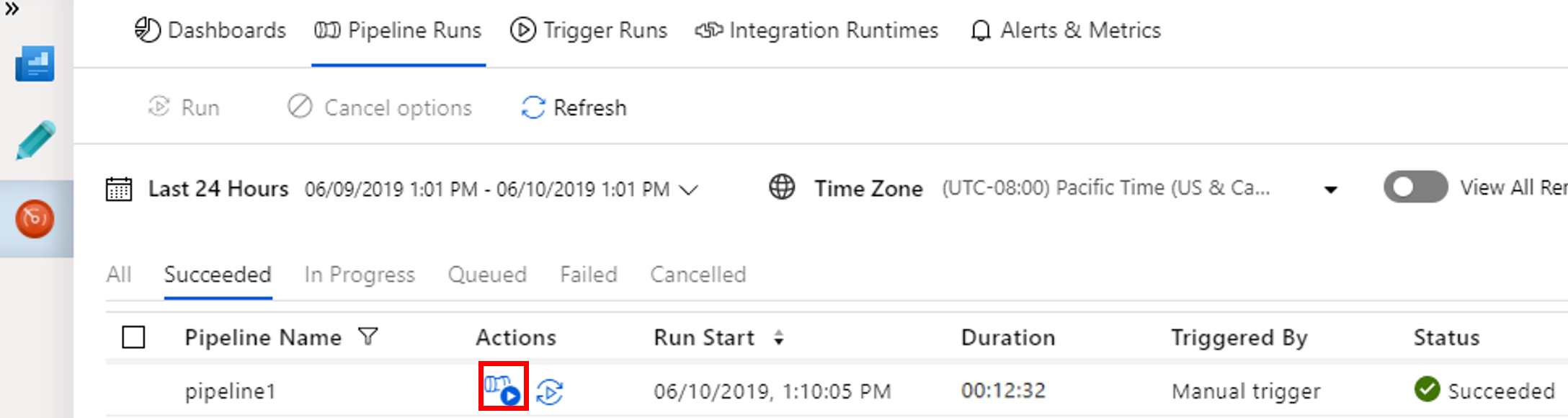
İşlem hattı çalıştırmasıyla ilişkili etkinlik çalıştırmalarını görmek için Eylemler sütunundaki Etkinlik Çalıştırmalarını Göster’i seçin.
Üst kısımdaki Tüm İşlem Hattı Çalıştırmaları bağlantısını seçerek işlem hattı çalıştırmaları görünümüne geri dönebilirsiniz.
Çıktıyı doğrulama
adftutorial kapsayıcısının spark/otuputfiles/wordcount klasöründe çıktı dosyasının oluşturulduğunu doğrulayın.
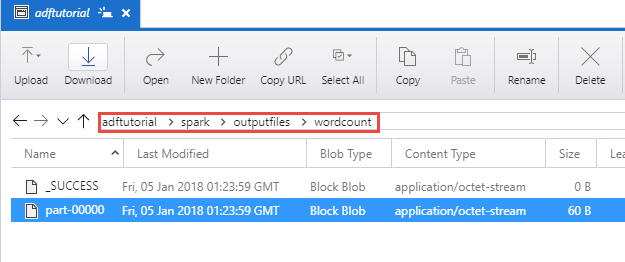
Dosya, girdi metin dosyasındaki her bir sözcüğü ve sözcüğün dosyada görünme sayısını içermelidir. Örneğin:
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
İlgili içerik
Bu örnekteki işlem hattı, Spark etkinliğini ve isteğe bağlı bir HDInsight bağlı hizmetini kullanarak verileri dönüştürür. Şunları öğrendiniz:
- Veri fabrikası oluşturma.
- Spark etkinliği kullanan bir işlem hattı oluşturun.
- İşlem hattı çalıştırması tetikleyin.
- İşlem hattı çalıştırmasını izleme.
Sanal ağdaki bir Azure HDInsight kümesinde Hive betiği çalıştırarak verileri dönüştürme hakkında bilgi almak için sonraki öğreticiye ilerleyin: