Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Toplu işlem ve akış, veri mühendisliği iş yükleri için kullanılan alım, dönüştürme ve gerçek zamanlı işleme gibi iki veri işleme semantiğidir.
Akış genellikle Apache Kafka gibi ileti kuyrukları tarafından düşük gecikme ve sürekli işleme ile ilişkilendirilir.
Ancak Azure Databricks'te daha kapsamlı bir tanımı vardır. Lakeflow işlem hatlarının (Apache Spark ve Yapılandırılmış Akış) temel altyapısı toplu işlem ve akış işleme için birleşik bir mimariye sahiptir:
- Altyapı, bulut nesne depolaması ve Delta Lake gibi kaynakları verimli artımlı işleme için akış kaynakları olarak değerlendirebilir.
- Akış işleme hem tetiklenmiş hem de sürekli şekilde çalıştırılabilir ve akış iş yüklerinizin maliyet ve performans dengelemenizi sağlamanıza olanak tanır.
Avantajları ve dezavantajları ve bunları iş yükleriniz için seçme konusunda dikkat edilmesi gerekenler de dahil olmak üzere toplu iş ve akışı birbirinden ayıran temel anlamsal farklılıklar aşağıda açıklanmaktadır.
Toplu işlem semantiği
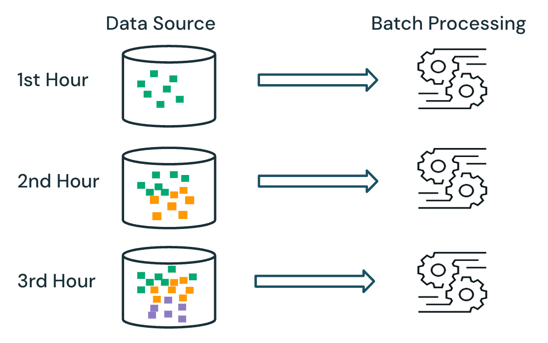
Toplu işleme ile altyapı, kaynakta zaten hangi verilerin işlendiğini izlemez. Kaynakta şu anda kullanılabilir olan tüm veriler işleme sırasında işlenir. Pratikte, bir toplu iş veri kaynağı genellikle verilerin yeniden işlenmesini sınırlamak için güne veya bölgeye göre mantıksal olarak bölümlenmiştir.
Örneğin, bir e-ticaret şirketi tarafından çalıştırılan bir satış etkinliği için saatlik ayrıntı düzeyinde toplanan ortalama madde satış fiyatını hesaplamak, saatte bir ortalama satış fiyatını hesaplamak için toplu işlem olarak zamanlanabilir. Batch ile, önceki saatlere ait veriler her saat yeniden işlenir ve en son sonuçları yansıtacak şekilde önceden hesaplanan sonuçların üzerine yazılır.
Akış semantiği
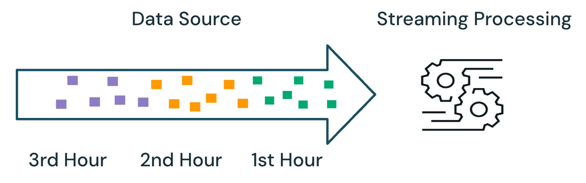
Akış işleme ile altyapı hangi verilerin işlendiğini izler ve sonraki çalıştırmalarda yalnızca yeni verileri işler. Yukarıdaki örnekte, saatte bir ortalama satış fiyatını hesaplamak için toplu işlem yerine akış işleme zamanlayabilirsiniz. Akışla, son çalıştırmadan bu yana kaynakta eklenen yeni veriler işlenir. Tüm sonuçların denetlenebilmesi için yeni hesaplanan sonuçların daha önce hesaplanmış sonuçlara eklenmesi gerekir.
Toplu iş ve akış karşılaştırması
Yukarıdaki örnekte akış, önceki çalıştırmalarda işlenen aynı verileri işlemediğinden toplu işlemden daha iyidir. Ancak akış işlemesi, kaynaktaki sırasız ve geç gelen veriler gibi senaryolarda daha karmaşık hale gelir.
Geç varış verilerine örnek olarak, ilk saatteki bazı satış verilerinin ikinci saate kadar kaynağa ulaşmaması gösteriliyor:
- Toplu işlemede, ilk saate ait geç varış verileri ikinci saatteki verilerle ve ilk saatteki mevcut verilerle işlenir. İlk saate ait önceki sonuçlar, üzerine yazılarak geç gelen verilerle düzeltilir.
- Akış işlemede, ilk saate ait geç gelen veriler, işlenen diğer ilk saat verilerinden hiçbiri olmadan işlenir. İşleme mantığının, önceki sonuçları doğru şekilde güncelleştirmek için ilk saatin ortalama hesaplamalarının toplam ve sayım bilgilerini depolaması gerekir.
Bu akış karmaşıklıkları, birleştirmeler, toplamalar ve yinelenenleri kaldırmalar gibi, işleme durum bilgisi gerektiğinde genellikle ortaya çıkar.
Kaynaktan yeni veri ekleme gibi durum bilgisi olmayan akış işleme işlemleri için, veriler kaynağa ulaştığında geç gelen veriler önceki sonuçlara eklenebileceği için, sıra dışı ve geç varış verilerini işlemek daha az karmaşıktır.
Aşağıdaki tabloda, toplu işlem ve akış işlemenin artıları ve dezavantajları ile Databricks Lakeflow'daki bu iki işleme semantiğini destekleyen farklı ürün özellikleri özetlenmiştir.
| İşleme semantiği | Avantajlar | Dezavantajlar | Veri mühendisliği ürünleri |
|---|---|---|---|
| Toplu işlem |
|
|
|
| Yayın |
|
|
|
Öneriler
Aşağıdaki tabloda, madalyon mimarisinin her katmanındaki veri işleme iş yüklerinin özelliklerine göre önerilen işleme semantiği özetlenmektedir.
| Madalyon katmanı | İş yükü özellikleri | Tavsiye |
|---|---|---|
| Bronz |
|
|
| Gümüş |
|
|
| Altın |
|
|