Databricks Runtime 12.2 LTS ve altı için Databricks Bağlan
Not
Databricks Bağlan bunun yerine Databricks Runtime 13.0 ve üzeri için Databricks Bağlan kullanmanızı önerir.
Databricks, Databricks Runtime 12.2 LTS ve altı için Databricks Bağlan için yeni özellik çalışması planlamıyor.
Databricks Bağlan, Visual Studio Code ve PyCharm, not defteri sunucuları ve diğer özel uygulamalar gibi popüler IDE'leri Azure Databricks kümelerine bağlamanıza olanak tanır.
Bu makalede Databricks Bağlan'ın nasıl çalıştığı açıklanır, Databricks Bağlan kullanmaya başlama adımlarında size yol gösterir, Databricks Bağlan kullanırken ortaya çıkabilecek sorunların nasıl giderildiğini ve Databricks Bağlan kullanarak çalıştırma ile Azure Databricks not defterinde çalışma arasındaki farkların nasıl giderildiğini açıklar.
Genel bakış
Databricks Bağlan, Databricks Runtime için bir istemci kitaplığıdır. Spark API'lerini kullanarak iş yazmanıza ve bunları yerel Spark oturumu yerine bir Azure Databricks kümesinde uzaktan çalıştırmanıza olanak tanır.
Örneğin Databricks Bağlan kullanarak DataFrame komutunu spark.read.format(...).load(...).groupBy(...).agg(...).show() çalıştırdığınızda, komutun mantıksal gösterimi uzak kümede yürütülmek üzere Azure Databricks'te çalışan Spark sunucusuna gönderilir.
Databricks Bağlan ile şunları yapabilirsiniz:
- Herhangi bir Python, R, Scala veya Java uygulamasından büyük ölçekli Spark işleri çalıştırın.
import pysparkrequire(SparkR)Herhangi bir IDE eklentisi yüklemenize veya Spark gönderim betiklerini kullanmanıza gerek kalmadan , veyaimport org.apache.sparkherhangi bir yerde Spark işlerini doğrudan uygulamanızdan çalıştırabilirsiniz. - Uzak kümeyle çalışırken bile IDE'nizde adım adım ilerleyin ve kodun hatalarını ayıklayın.
- Kitaplık geliştirirken hızla yinelenir. Databricks Bağlan Python veya Java kitaplık bağımlılıklarını değiştirdikten sonra kümeyi yeniden başlatmanız gerekmez çünkü her istemci oturumu kümede birbirinden yalıtılır.
- Boşta kalan kümeleri iş kaybı olmadan kapatın. İstemci uygulaması kümeden ayrılmış olduğundan, küme yeniden başlatmalarından veya yükseltmelerinden etkilenmez ve bu durum normalde not defterinde tanımlanan tüm değişkenleri, RDD'leri ve DataFrame nesnelerini kaybetmenize neden olur.
Not
SQL sorgularıyla Python geliştirmesi için Databricks, Databricks Bağlan yerine Python için Databricks SQL Bağlan or kullanmanızı önerir. Python için Databricks SQL Bağlan veya kurulumu Databricks Bağlan'dan daha kolaydır. Ayrıca Databricks Bağlan işleri ayrıştırıp planlarken işler uzak işlem kaynaklarında çalışırken yerel makinenizde çalışır. Bu, çalışma zamanı hatalarının hatalarını ayıklamayı özellikle zorlaştırabilir. Python için Databricks SQL Bağlan or, SQL sorgularını doğrudan uzak işlem kaynaklarına gönderir ve sonuçları getirir.
Gereksinim -leri
Bu bölümde Databricks Bağlan gereksinimleri listelenir.
Yalnızca aşağıdaki Databricks Runtime sürümleri desteklenir:
- Databricks Runtime 12.2 LTS ML, Databricks Runtime 12.2 LTS
- Databricks Runtime 11.3 LTS ML, Databricks Runtime 11.3 LTS
- Databricks Runtime 10.4 LTS ML, Databricks Runtime 10.4 LTS
- Databricks Runtime 9.1 LTS ML, Databricks Runtime 9.1 LTS
- Databricks Runtime 7.3 LTS
Geliştirme makinenize Python 3 yüklemeniz gerekir ve istemci Python yüklemenizin ikincil sürümü Azure Databricks kümenizin ikincil Python sürümüyle aynı olmalıdır. Aşağıdaki tabloda her Databricks Runtime ile yüklenen Python sürümü gösterilmektedir.
Databricks Runtime sürümü Python sürümü 12,2 LTS ML, 12,2 LTS 3.9 11,3 LTS ML, 11,3 LTS 3.9 10,4 LTS ML, 10,4 LTS 3.8 9.1 LTS ML, 9.1 LTS 3.8 7,3 LTS 3.7 Databricks, Databricks Bağlan ile kullandığınız her Python sürümü için etkinleştirilmiş bir Python sanal ortamına sahip olduğunuzu kesinlikle önerir. Python sanal ortamları, Python ve Databricks'in doğru sürümlerini Bağlan birlikte kullandığınızdan emin olmanıza yardımcı olur. Bu, ilgili teknik sorunları çözmek için harcanan süreyi azaltmaya yardımcı olabilir.
Örneğin, geliştirme makinenizde venv kullanıyorsanız ve kümeniz Python 3.9 çalıştırıyorsa, bu sürüme sahip bir
venvortam oluşturmanız gerekir. Aşağıdaki örnek komut, Python 3.9 ile birvenvortamı etkinleştirmek için betikleri oluşturur ve bu komut bu betikleri geçerli çalışma dizininde adlı.venvgizli bir klasöre yerleştirir:# Linux and macOS python3.9 -m venv ./.venv # Windows python3.9 -m venv .\.venvBu betikleri kullanarak bu
venvortamı etkinleştirmek için bkz . Venv'ler nasıl çalışır?Başka bir örnek olarak, geliştirme makinenizde Conda kullanıyorsanız ve kümeniz Python 3.9 çalıştırıyorsa, bu sürümle bir Conda ortamı oluşturmanız gerekir, örneğin:
conda create --name dbconnect python=3.9Conda ortamını bu ortam adıyla etkinleştirmek için komutunu çalıştırın
conda activate dbconnect.Databricks Connect birincil ve ikincil paket sürümü mutlaka Databricks Runtime sürümünüzle eşleşmelidir. Databricks her zaman Databricks Runtime sürümünüzle eşleşen en son Databricks Bağlan paketini kullanmanızı önerir. Örneğin, Bir Databricks Runtime 12.2 LTS kümesi kullandığınızda, paketi de kullanmanız
databricks-connect==12.2.*gerekir.Java Çalışma Zamanı Ortamı (JRE) 8. İstemci OpenJDK 8 JRE ile test edilmiştir. İstemci Java 11'i desteklemez.
Not
Windows'da Databricks'in Bağlan bulamadığını winutils.exebelirten bir hata görürseniz bkz. Windows'da winutils.exe bulunamıyor.
İstemciyi ayarlama
Databricks Bağlan için yerel istemciyi ayarlamak için aşağıdaki adımları tamamlayın.
Not
Yerel Databricks Bağlan istemcisini ayarlamaya başlamadan önce Databricks Bağlan gereksinimlerini karşılamanız gerekir.
1. Adım: Databricks Bağlan istemcisini yükleme
Sanal ortamınız etkinleştirildiğinde, pyspark zaten yüklüyse komutunu çalıştırarak
uninstallkaldırın. Paketin PySpark ile çakışmasıdatabricks-connectnedeniyle bu gereklidir. Ayrıntılar için bkz . Çakışan PySpark yüklemeleri. PySpark'ın zaten yüklü olup olmadığını denetlemek için komutunu çalıştırınshow.# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pysparkSanal ortamınız hala etkinken komutunu çalıştırarak Databricks Bağlan istemcisini
installyükleyin.--upgradeMevcut istemci yüklemelerini belirtilen sürüme yükseltmek için seçeneğini kullanın.pip3 install --upgrade "databricks-connect==12.2.*" # Or X.Y.* to match your cluster version.Not
Databricks, en son paketin yüklendiğinden emin olmak için yerine
databricks-connect=X.Ybelirtmekdatabricks-connect==X.Y.*üzere "nokta-yıldız işareti" gösterimini eklemenizi önerir.
2. Adım: Bağlantı özelliklerini yapılandırma
Aşağıdaki yapılandırma özelliklerini toplayın.
Çalışma alanı başına Azure Databricks URL'si. Bu, kümenizin Sunucu Ana Bilgisayar Adı değeriyle de aynıdır
https://. Bkz. Azure Databricks işlem kaynağı için bağlantı ayrıntılarını alma.Azure Databricks kişisel erişim belirteciniz veya Microsoft Entra Id (eski adıyla Azure Active Directory) belirteciniz.
- Azure Data Lake Depolama (ADLS) kimlik bilgisi geçişi için bir Microsoft Entra Id (eski adıyla Azure Active Directory) belirteci kullanmanız gerekir. Microsoft Entra Id kimlik bilgisi geçişi yalnızca Databricks Runtime 7.3 LTS ve üzerini çalıştıran Standart kümelerde desteklenir ve hizmet sorumlusu kimlik doğrulamasıyla uyumlu değildir.
- Microsoft Entra Id belirteçleriyle kimlik doğrulaması hakkında daha fazla bilgi için bkz . Microsoft Entra Id belirteçlerini kullanarak kimlik doğrulaması.
Kümenizin kimliği. Küme kimliğini URL'den alabilirsiniz. Burada küme kimliği şeklindedir
1108-201635-xxxxxxxx. Ayrıca bkz. Küme URL'si ve kimliği.
Çalışma alanınızın benzersiz kuruluş kimliği. Bkz. Çalışma alanı nesneleri için tanımlayıcıları alma.
Databricks'in Bağlan kümenizde bağlandığını bağlantı noktası. Varsayılan bağlantı noktası şeklindedir
15001. Kümeniz, Azure Databricks için önceki yönergelerde verilen gibi8787farklı bir bağlantı noktası kullanacak şekilde yapılandırılmışsa, yapılandırılan bağlantı noktası numarasını kullanın.
Bağlantıyı aşağıdaki gibi yapılandırın.
CLI, SQL yapılandırmaları veya ortam değişkenlerini kullanabilirsiniz. Yapılandırma yöntemlerinin en yüksekten en düşüğe önceliği: SQL yapılandırma anahtarları, CLI ve ortam değişkenleri.
CLI
databricks-connect'i çalıştırın.databricks-connect configureLisans şu şekilde görüntülenir:
Copyright (2018) Databricks, Inc. This library (the "Software") may not be used except in connection with the Licensee's use of the Databricks Platform Services pursuant to an Agreement ...Lisans ve sağlama yapılandırma değerlerini kabul edin. Databricks Konağı ve Databricks Belirteci için, 1. Adım'da not ettiğiniz çalışma alanı URL'sini ve kişisel erişim belirtecini girin.
Do you accept the above agreement? [y/N] y Set new config values (leave input empty to accept default): Databricks Host [no current value, must start with https://]: <databricks-url> Databricks Token [no current value]: <databricks-token> Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id> Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id> Port [15001]: <port>Microsoft Entra Id belirtecinin çok uzun olduğunu belirten bir ileti alırsanız Databricks Belirteci alanını boş bırakabilir ve belirteci içine
~/.databricks-connectel ile girebilirsiniz.
SQL yapılandırmaları veya ortam değişkenleri. Aşağıdaki tabloda, 1. Adımda not ettiğiniz yapılandırma özelliklerine karşılık gelen SQL yapılandırma anahtarları ve ortam değişkenleri gösterilmektedir. SQL yapılandırma anahtarı ayarlamak için kullanın
sql("set config=value"). Örneğin:sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh").Parametre SQL yapılandırma anahtarı Environment variable name Databricks Konağı spark.databricks.service.address DATABRICKS_ADDRESS Databricks Belirteci spark.databricks.service.token DATABRICKS_API_TOKEN Küme Kimliği spark.databricks.service.clusterId DATABRICKS_CLUSTER_ID Kuruluş Kimliği spark.databricks.service.orgId DATABRICKS_ORG_ID Bağlantı noktası spark.databricks.service.port DATABRICKS_PORT
Sanal ortamınız hala etkinken Azure Databricks bağlantısını aşağıdaki gibi test edin.
databricks-connect testYapılandırdığınız küme çalışmıyorsa, test kümeyi başlatır ve bu küme yapılandırılan otomatik dengeleme süresine kadar çalışır durumda kalır. Çıkış aşağıdakine benzer görünmelidir:
* PySpark is installed at /.../.../pyspark * Checking java version java version "1.8..." Java(TM) SE Runtime Environment (build 1.8...) Java HotSpot(TM) 64-Bit Server VM (build 25..., mixed mode) * Testing scala command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab..., invalidating prev state ../../.. ..:..:.. WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2... /_/ Using Scala version 2.... (Java HotSpot(TM) 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala> spark.range(100).reduce(_ + _) Spark context Web UI available at https://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi View job details at <databricks-url>?o=0#/setting/clusters/<cluster-id>/sparkUi res0: Long = 4950 scala> :quit * Testing python command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab.., invalidating prev state View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUiBağlantıyla ilgili hata gösterilmiyorsa (
WARNiletiler iyi durumdaysa) başarıyla bağlandınız demektir.
Databricks Bağlan kullanma
Bölümünde, tercih ettiğiniz IDE veya not defteri sunucusunun Databricks Bağlan istemcisini kullanacak şekilde nasıl yapılandırıldığı açıklanmaktadır.
Bu bölümde:
- JupyterLab
- Klasik Jupyter Notebook
- PyCharm
- SparkR ve RStudio Desktop
- sparklyr ve RStudio Desktop
- IntelliJ (Scala veya Java)
- Eclipse ile PyDev
- Eclipse
- SBT
- Spark kabuğu
JupyterLab
Not
Databricks Bağlan kullanmaya başlamadan önce gereksinimleri karşılamanız ve Databricks Bağlan için istemciyi ayarlamanız gerekir.
Databricks Bağlan JupyterLab ve Python ile kullanmak için bu yönergeleri izleyin.
JupyterLab'i yüklemek için Python sanal ortamınız etkinleştirildiğinde terminalinizde veya Komut İsteminizde aşağıdaki komutu çalıştırın:
pip3 install jupyterlabJupyterLab'i web tarayıcınızda başlatmak için etkinleştirilmiş Python sanal ortamınızdan aşağıdaki komutu çalıştırın:
jupyter labJupyterLab web tarayıcınızda görünmüyorsa, sanal ortamınızla veya
127.0.0.1sanal ortamınızdan başlayanlocalhostURL'yi kopyalayın ve web tarayıcınızın adres çubuğuna girin.Yeni not defteri oluşturma: JupyterLab'de ana menüden Yeni Not Defteri Dosyala'ya > tıklayın, Python 3 (ipykernel) öğesini seçin ve Seç'e tıklayın.>
Not defterinin ilk hücresine örnek kodu veya kendi kodunuzu girin. Kendi kodunuzu kullanıyorsanız, örnek kodda gösterildiği gibi en azından örneğini
SparkSession.builder.getOrCreate()oluşturmalısınız.Not defterini çalıştırmak için Tüm Hücreleri Çalıştır'a > tıklayın.
Not defterinde hata ayıklamak için, not defterinin araç çubuğunda Python 3 (ipykernel) öğesinin yanındaki hata (Hata Ayıklayıcıyı Etkinleştir) simgesine tıklayın. Bir veya daha fazla kesme noktası ayarlayın ve ardından Tüm Hücreleri Çalıştır'a > tıklayın.
JupyterLab'i kapatmak için Dosya > Kapat'a tıklayın. JupyterLab işlemi terminalinizde veya Komut İsteminizde çalışmaya devam ediyorsa, onaylamak için tuşuna basıp
Ctrl + cgirerekybu işlemi durdurun.
Daha ayrıntılı hata ayıklama yönergeleri için bkz . Hata Ayıklayıcı.
Klasik Jupyter Notebook
Not
Databricks Bağlan kullanmaya başlamadan önce gereksinimleri karşılamanız ve Databricks Bağlan için istemciyi ayarlamanız gerekir.
Databricks için yapılandırma betiği Bağlan paketi proje yapılandırmanıza otomatik olarak ekler. Python çekirdeğine başlamak için şunu çalıştırın:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
SQL sorgularını %sql çalıştırmak ve görselleştirmek için kısaltmayı etkinleştirmek için aşağıdaki kod parçacığını kullanın:
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
Visual Studio Code
Not
Databricks Bağlan kullanmaya başlamadan önce gereksinimleri karşılamanız ve Databricks Bağlan için istemciyi ayarlamanız gerekir.
Visual Studio Code ile Databricks Bağlan kullanmak için aşağıdakileri yapın:
Komut Paleti'ni açın (macOS'ta Command+Shift+P ve Windows/Linux'ta Ctrl+Shift+P ).
Bir Python yorumlayıcısı seçin. Kod > Tercihleri > Ayarlar gidin ve python ayarlarını seçin.
databricks-connect get-jar-dir'i çalıştırın.komutundan döndürülen dizini altındaki
python.venvPathKullanıcı Ayarlar JSON'a ekleyin. Bu, Python Yapılandırması'na eklenmelidir.Linter'i devre dışı bırakın. Sağ taraftaki ... öğesine tıklayın ve json ayarlarını düzenleyin. Değiştirilen ayarlar aşağıdaki gibidir:
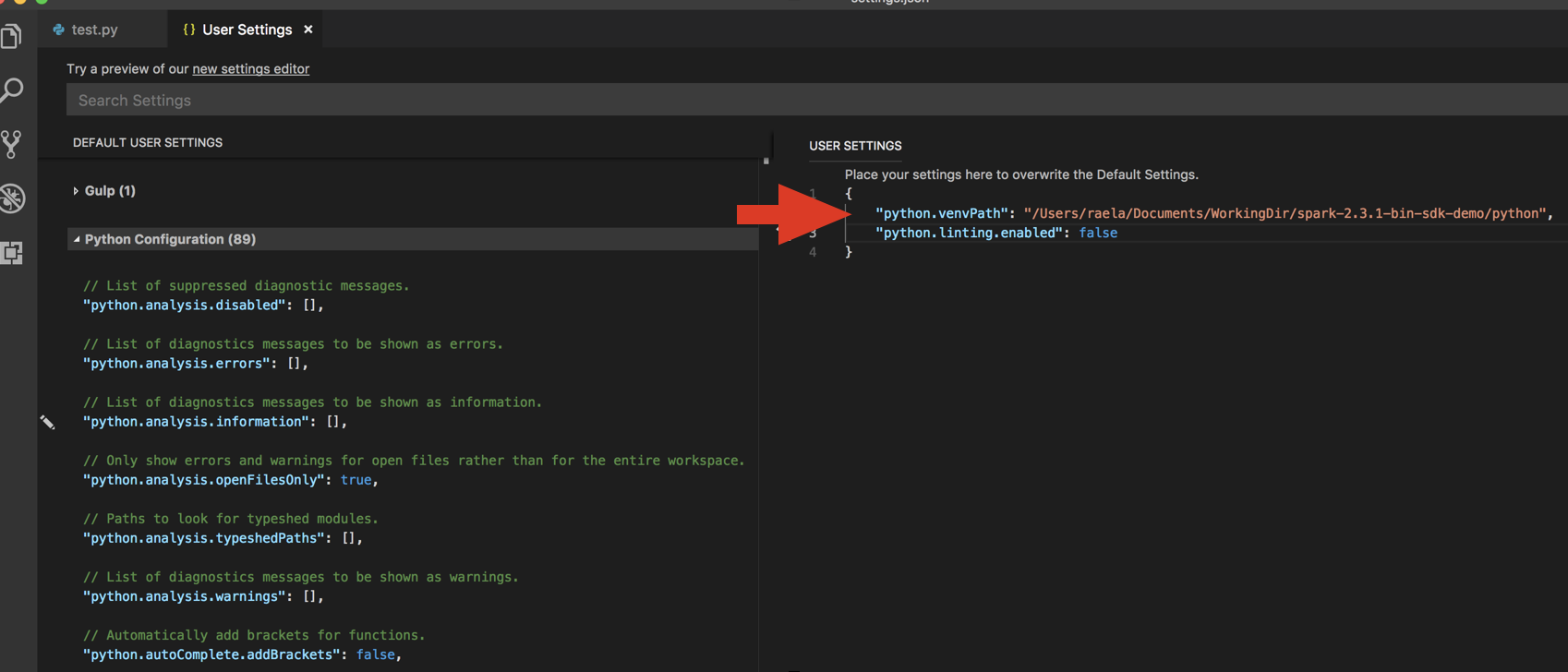
VS Code'da Python için geliştirmenin önerilen yolu olan bir sanal ortamla çalışıyorsanız, Komut Paleti türü'nde
select python interpreterkümenizin Python sürümüyle eşleşen ortamınıza işaret edin.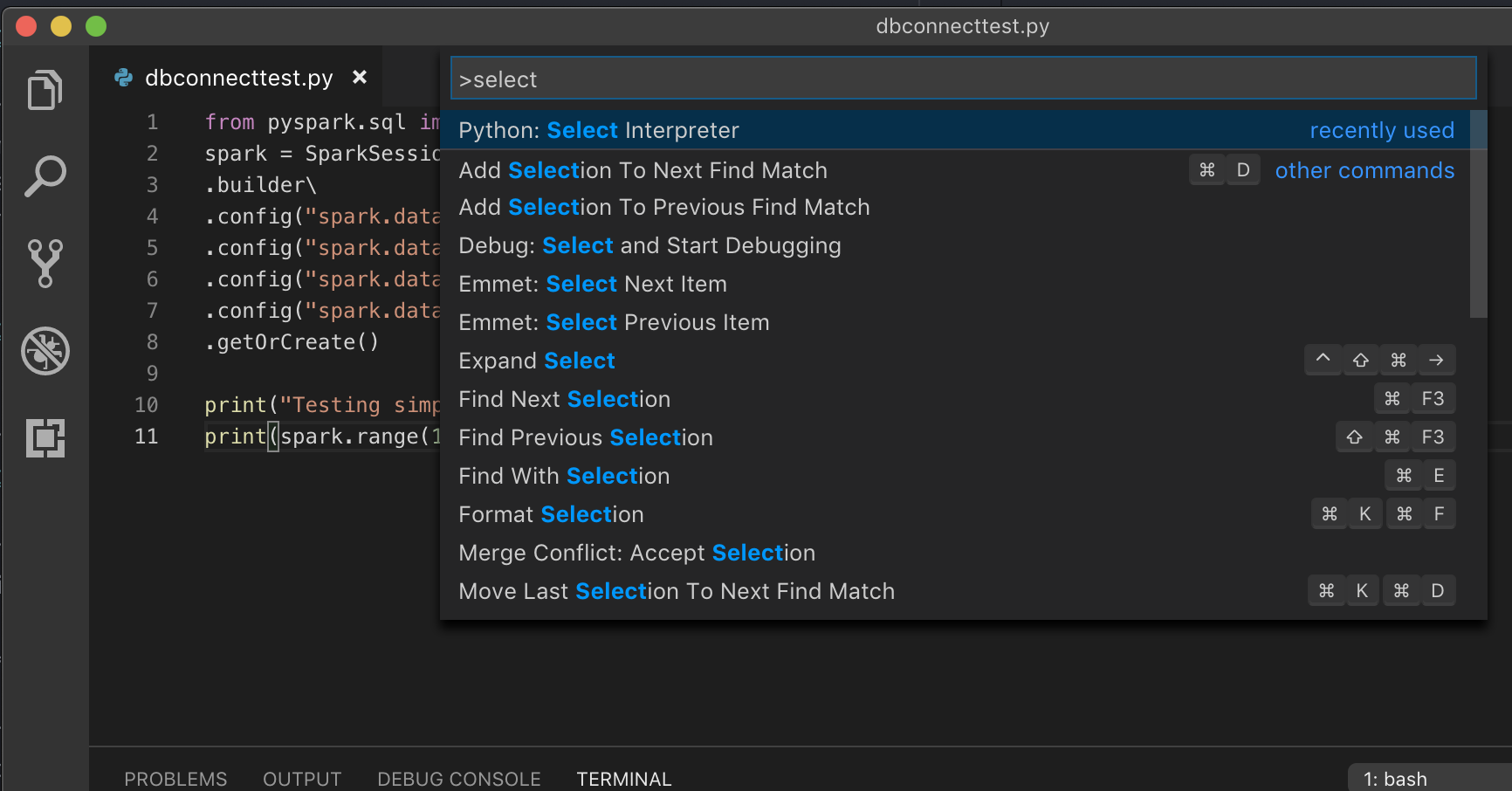
Örneğin, kümeniz Python 3.9 ise geliştirme ortamınız Python 3.9 olmalıdır.
PyCharm
Not
Databricks Bağlan kullanmaya başlamadan önce gereksinimleri karşılamanız ve Databricks Bağlan için istemciyi ayarlamanız gerekir.
Databricks için yapılandırma betiği Bağlan paketi proje yapılandırmanıza otomatik olarak ekler.
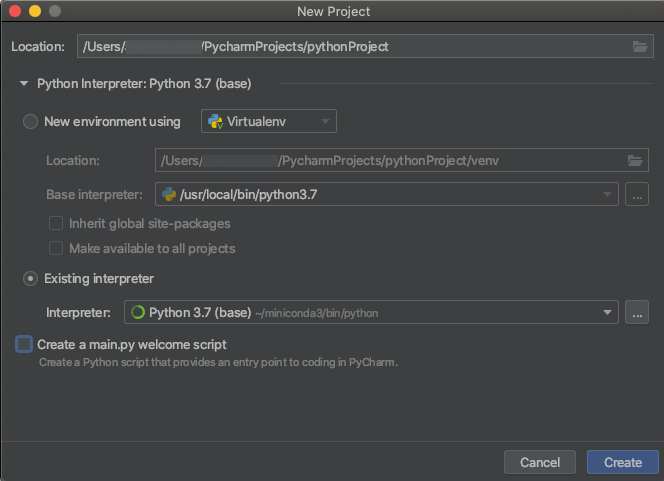
Python 3 kümeleri
PyCharm projesi oluşturduğunuzda Mevcut Yorumlayıcı'yı seçin. Açılan menüden oluşturduğunuz Conda ortamını seçin (bkz . Gereksinimler).
Yapılandırmaları Düzenle'yi Çalıştırma'ya > gidin.
Ortam değişkeni olarak ekleyin
PYSPARK_PYTHON=python3.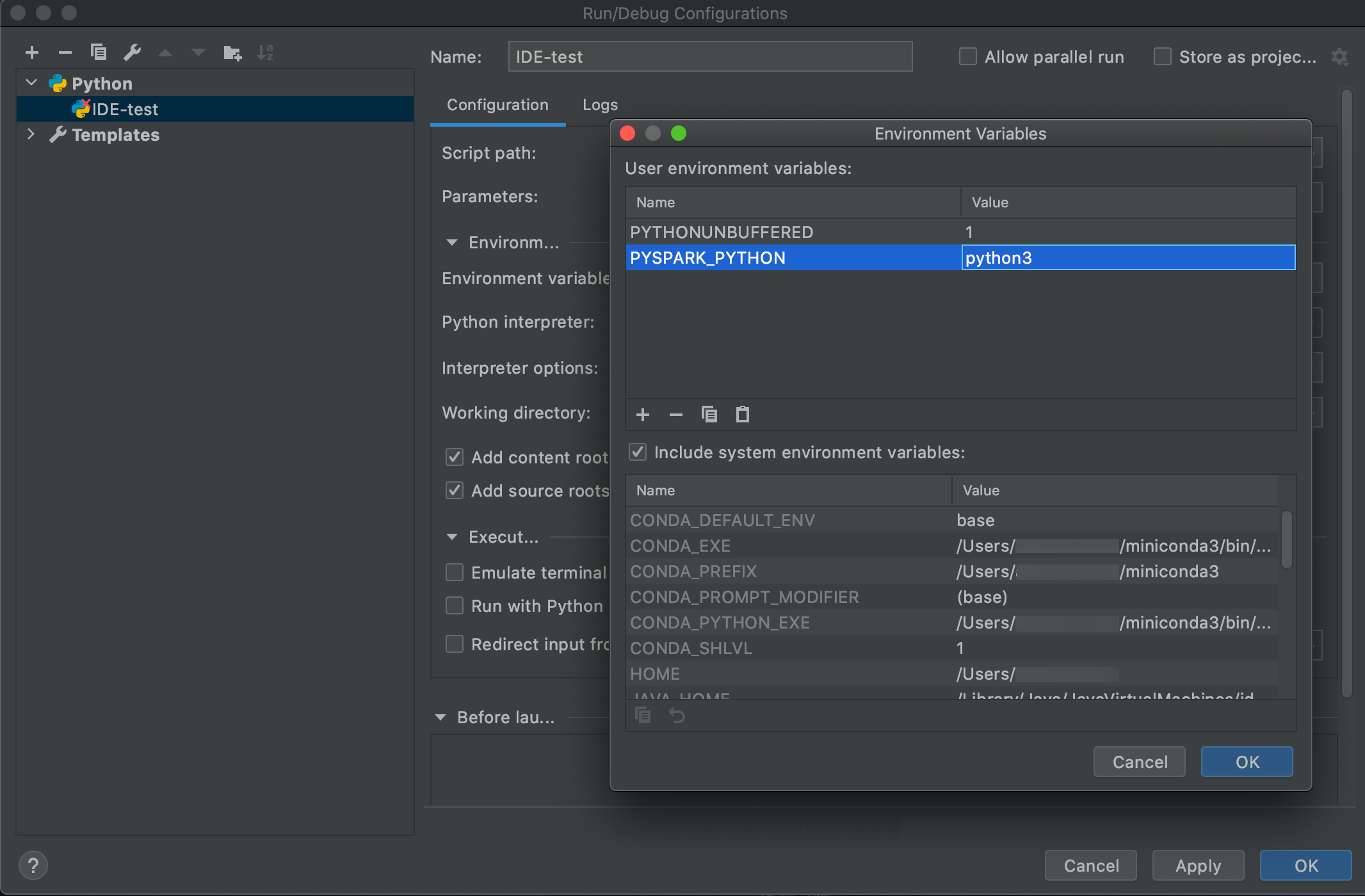
SparkR ve RStudio Desktop
Not
Databricks Bağlan kullanmaya başlamadan önce gereksinimleri karşılamanız ve Databricks Bağlan için istemciyi ayarlamanız gerekir.
Databricks Bağlan SparkR ve RStudio Desktop ile kullanmak için aşağıdakileri yapın:
açık kaynak Spark dağıtımını indirip geliştirme makinenize açın. Azure Databricks kümenizdeki (Hadoop 2.7) aynı sürümü seçin.
databricks-connect get-jar-dir'i çalıştırın. Bu komut gibi/usr/local/lib/python3.5/dist-packages/pyspark/jarsbir yol döndürür. JAR dizin dosya yolunun üzerindeki bir dizinin dosya yolunu kopyalayın; örneğin,/usr/local/lib/python3.5/dist-packages/pysparkdizinidirSPARK_HOME.Spark lib yolunu ve Spark giriş yolunu R betiğinizin en üstüne ekleyerek yapılandırın. 1. adımda açık kaynak Spark paketinin paketini kaldırdığınız dizine ayarlayın
<spark-lib-path>. 2. adımdaki Databricks Bağlan dizinine ayarlayın<spark-home-path>.# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7 library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths()))) # Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark Sys.setenv(SPARK_HOME = "<spark-home-path>")Spark oturumu başlatın ve SparkR komutlarını çalıştırmaya başlayın.
sparkR.session() df <- as.DataFrame(faithful) head(df) df1 <- dapply(df, function(x) { x }, schema(df)) collect(df1)
sparklyr ve RStudio Desktop
Not
Databricks Bağlan kullanmaya başlamadan önce gereksinimleri karşılamanız ve Databricks Bağlan için istemciyi ayarlamanız gerekir.
Önemli
Bu özellik Genel Önizlemededir.
Databricks Bağlan kullanarak yerel olarak geliştirdiğiniz sparklyr bağımlı kodu kopyalayabilir ve azure Databricks not defterinizde veya Azure Databricks çalışma alanınızda barındırılan RStudio Server'da en az kod değişikliğiyle veya hiç değişiklik olmadan çalıştırabilirsiniz.
Bu bölümde:
- Gereksinimler
- Sparklyr'ı yükleme, yapılandırma ve kullanma
- Kaynaklar
- sparklyr ve RStudio Desktop sınırlamaları
Gereksinimler
- sparklyr 1.2 veya üzeri.
- Databricks runtime 7.3 LTS veya üzeri ile eşleşen Databricks Bağlan sürümü.
Sparklyr'ı yükleme, yapılandırma ve kullanma
RStudio Desktop'ta CRAN'dan sparklyr 1.2 veya üzerini yükleyin veya GitHub'dan en son ana sürümü yükleyin.
# Install from CRAN install.packages("sparklyr") # Or install the latest master version from GitHub install.packages("devtools") devtools::install_github("sparklyr/sparklyr")Python ortamını databricks Bağlan doğru sürümü yüklü olarak etkinleştirin ve almak
<spark-home-path>için terminalde aşağıdaki komutu çalıştırın:databricks-connect get-spark-homeSpark oturumu başlatın ve sparklyr komutlarını çalıştırmaya başlayın.
library(sparklyr) sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) library(dplyr) src_tbls(sc) iris_tbl %>% countBağlantıyı kapatın.
spark_disconnect(sc)
Kaynaklar
Daha fazla bilgi için bkz. sparklyr GitHub README.
Kod örnekleri için bkz . sparklyr.
sparklyr ve RStudio Desktop sınırlamaları
Aşağıdaki özellikler desteklenmez:
- sparklyr akış API'leri
- sparklyr ML API'leri
- süpürge API'leri
- csv_file serileştirme modu
- spark gönderme
IntelliJ (Scala veya Java)
Not
Databricks Bağlan kullanmaya başlamadan önce gereksinimleri karşılamanız ve Databricks Bağlan için istemciyi ayarlamanız gerekir.
Databricks Bağlan IntelliJ (Scala veya Java) ile kullanmak için aşağıdakileri yapın:
databricks-connect get-jar-dir'i çalıştırın.Bağımlılıkları komutundan döndürülen dizine işaret edin. Dosya Proje Yapısı > Modülleri Bağımlılıkları >> '+' imza > JAR'leri veya Dizinler'e gidin.>
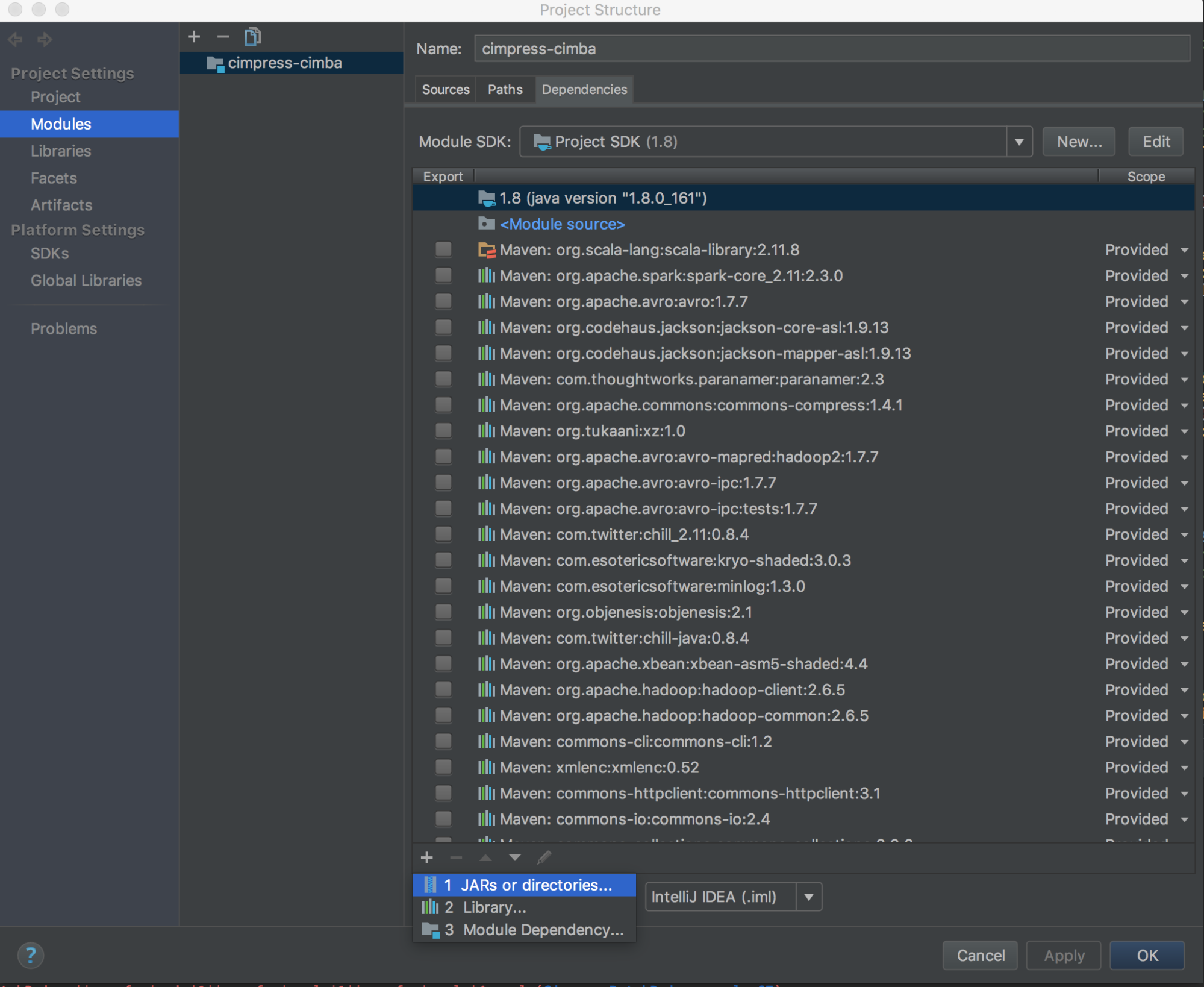
Çakışmaları önlemek için, diğer Spark yüklemelerini sınıf yolunuzdan kaldırmanızı kesinlikle öneririz. Bu mümkün değilse, eklediğiniz JAR'lerin sınıf yolu önünde olduğundan emin olun. Özellikle, Spark'ın yüklü diğer sürümlerinden önce olmaları gerekir (aksi takdirde, diğer Spark sürümlerinden birini kullanır ve yerel olarak çalışır veya bir
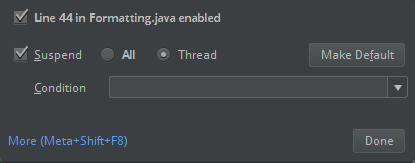
ClassDefNotFoundErroroluşturursunuz).IntelliJ'de tartışma seçeneğinin ayarını denetleyin. Varsayılan değer Tümü'dür ve hata ayıklama için kesme noktaları ayarlarsanız ağ zaman aşımlarına neden olur. Arka plan ağ iş parçacıklarını durdurmaktan kaçınmak için bunu İş Parçacığı olarak ayarlayın.
Eclipse ile PyDev
Not
Databricks Bağlan kullanmaya başlamadan önce gereksinimleri karşılamanız ve Databricks Bağlan için istemciyi ayarlamanız gerekir.
Databricks Bağlan ve PyDev'i Eclipse ile kullanmak için bu yönergeleri izleyin.
- Eclipse'i başlatın.
- Proje oluşturma: Dosya Yeni Proje PyDev PyDev > Projesi'ne ve ardından İleri'ye tıklayın.>>>
- Bir Proje adı belirtin.
- Project içeriği için Python sanal ortamınızın yolunu belirtin.
- Devam etmeden önce Lütfen yorumlayıcı yapılandırın'a tıklayın.
- El ile yapılandırma'ya tıklayın.
- Python/pypy exe için Yeni > Gözat'a tıklayın.
- Sanal ortamdan başvuruda bulunup Python yorumlayıcısının tam yolunu seçin ve ardından Aç'a tıklayın.
- Yorumlayıcı seç iletişim kutusunda Tamam'a tıklayın.
- Seçim gerekiyor iletişim kutusunda Tamam'a tıklayın.
- Tercihler iletişim kutusunda Uygula ve Kapat'a tıklayın.
- PyDev Projesi iletişim kutusunda Son'a tıklayın.
- Perspektif Aç'a tıklayın.
- Projeye örnek kodu veya kendi kodunuzu içeren bir Python kodu (
.py) dosyası ekleyin. Kendi kodunuzu kullanıyorsanız, örnek kodda gösterildiği gibi en azından örneğiniSparkSession.builder.getOrCreate()oluşturmalısınız. - Python kod dosyası açıkken, çalışırken kodunuzun duraklatılmasını istediğiniz kesme noktalarını ayarlayın.
- Çalıştır'a> veya Hata Ayıklamayı Çalıştır'a > tıklayın.
Daha ayrıntılı çalıştırma ve hata ayıklama yönergeleri için bkz . Program Çalıştırma.
Eclipse
Not
Databricks Bağlan kullanmaya başlamadan önce gereksinimleri karşılamanız ve Databricks Bağlan için istemciyi ayarlamanız gerekir.
Databricks Bağlan ve Eclipse'i kullanmak için aşağıdakileri yapın:
databricks-connect get-jar-dir'i çalıştırın.Dış JAR yapılandırmasını komuttan döndürülen dizine işaret edin. Proje menüsü > Özellikleri > Java Derleme Yolu > Kitaplıkları > Dış Jar'lar Ekle'ye gidin.
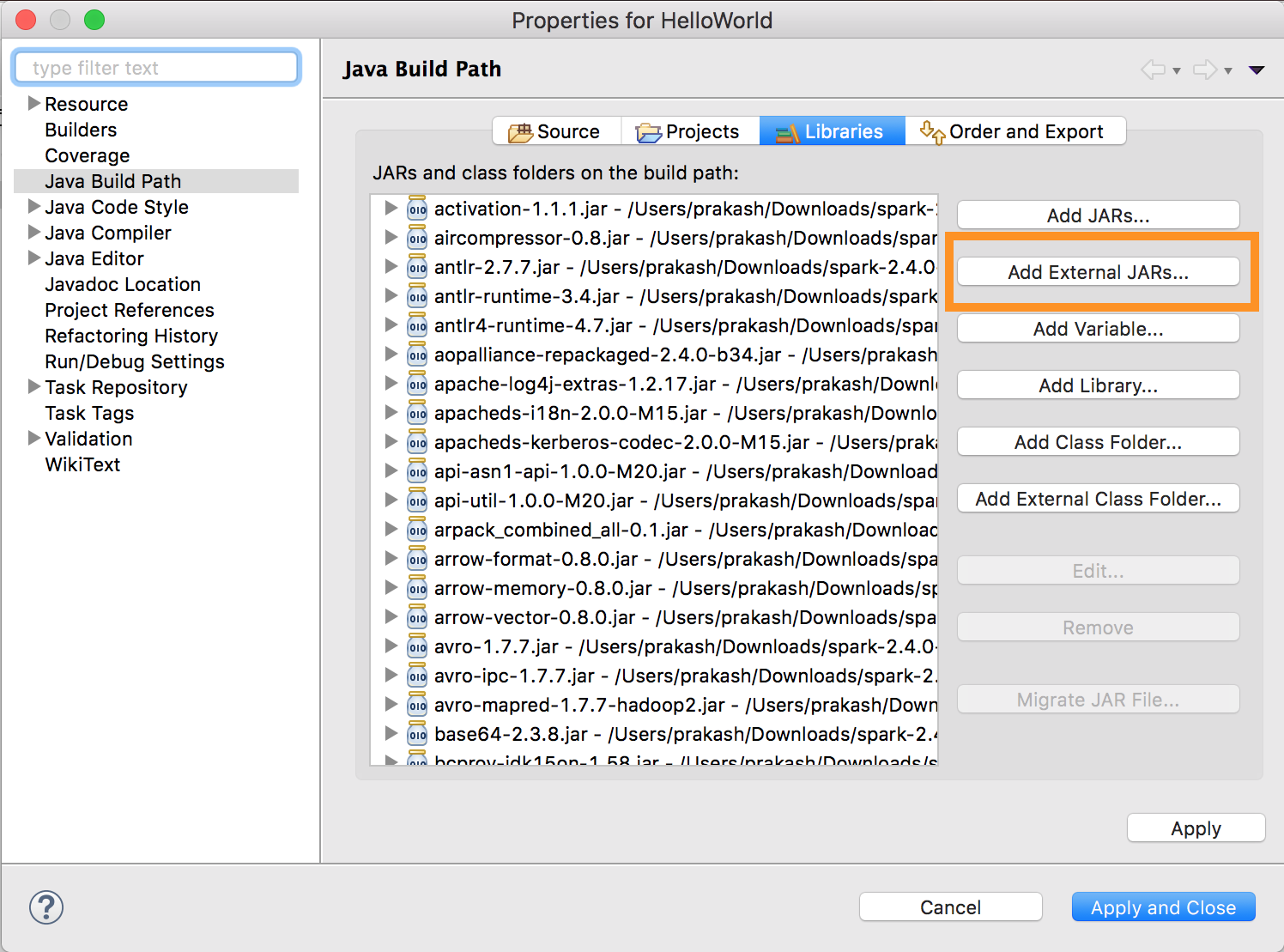
Çakışmaları önlemek için, diğer Spark yüklemelerini sınıf yolunuzdan kaldırmanızı kesinlikle öneririz. Bu mümkün değilse, eklediğiniz JAR'lerin sınıf yolu önünde olduğundan emin olun. Özellikle, Spark'ın yüklü diğer sürümlerinden önce olmaları gerekir (aksi takdirde, diğer Spark sürümlerinden birini kullanır ve yerel olarak çalışır veya bir
ClassDefNotFoundErroroluşturursunuz).
SBT
Not
Databricks Bağlan kullanmaya başlamadan önce gereksinimleri karşılamanız ve Databricks Bağlan için istemciyi ayarlamanız gerekir.
Databricks Bağlan SBT ile kullanmak için dosyanızı her zamanki Spark kitaplığı bağımlılığı yerine Databricks Bağlan JAR'lere bağlanacak şekilde yapılandırmanız build.sbt gerekir. Bunu, ana nesnesi olan bir Scala uygulamasının com.example.Test varsayıldığı aşağıdaki örnek derleme dosyasındaki yönergesiyle unmanagedBase yaparsınız:
build.sbt
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by ``databricks-connect get-jar-dir``
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
Spark kabuğu
Not
Databricks Bağlan kullanmaya başlamadan önce gereksinimleri karşılamanız ve Databricks Bağlan için istemciyi ayarlamanız gerekir.
Databricks Bağlan Spark kabuğu ve Python veya Scala ile kullanmak için bu yönergeleri izleyin.
Sanal ortamınız etkinleştirildiğinde, İstemciyi ayarlama bölümünde komutun
databricks-connect testbaşarıyla çalıştırıldığından emin olun.Sanal ortamınız etkinleştirildiğinde Spark kabuğunu başlatın. Python için komutunu çalıştırın
pyspark. Scala içinspark-shellkomutunu çalıştırın.# For Python: pyspark# For Scala: spark-shellSpark kabuğu görünür, örneğin Python:
Python 3... (v3...) [Clang 6... (clang-6...)] on darwin Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.... /_/ Using Python version 3... (v3...) Spark context Web UI available at http://...:... Spark context available as 'sc' (master = local[*], app id = local-...). SparkSession available as 'spark'. >>>Scala için:
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3... /_/ Using Scala version 2... (OpenJDK 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala>Kümenizde komut çalıştırmak için Spark kabuğunu Python veya Scala ile kullanma hakkında bilgi için Spark Shell ile Etkileşimli Çözümleme bölümüne bakın.
Çalışan kümenizde örneğin Python'ı temsil etmek için yerleşik
sparkdeğişkeniniSparkSessionkullanın:>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsScala için:
>>> val df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsSpark kabuğunu durdurmak için, veya tuşuna basın
Ctrl + dya da komutunuquit()ya da Python ya da:quitexit():qScala için çalıştırın.Ctrl + z
Kod örnekleri
Bu basit kod örneği, belirtilen tabloyu sorgular ve ardından belirtilen tablonun ilk 5 satırını gösterir. Farklı bir tablo kullanmak için çağrısını olarak spark.read.tableayarlayın.
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
Bu uzun kod örneği aşağıdakileri yapar:
- Bellek içi bir DataFrame oluşturur.
- Şema içinde
defaultadıylazzz_demo_temps_tablebir tablo oluşturur. Bu ada sahip tablo zaten varsa, önce tablo silinir. Farklı bir şema veya tablo kullanmak için, çağrıları ,temps.write.saveAsTableveya her ikisi olarakspark.sqlayarlayın. - DataFrame'in içeriğini tabloya kaydeder.
- Tablonun içeriğinde bir
SELECTsorgu çalıştırır. - Sorgunun sonucunu gösterir.
- Tabloyu siler.
Python
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
Scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table")
temps.write.saveAsTable("zzz_demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table")
}
}
Java
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table");
temps.write().saveAsTable("zzz_demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table");
}
}
Bağımlılıklarla çalışma
Genellikle ana sınıfınız veya Python dosyanızda başka bağımlılık JAR'leri ve dosyaları olur. veya sparkContext.addPyFile("path-to-the-file")öğesini çağırarak sparkContext.addJar("path-to-the-jar") bu tür bağımlılık JAR'leri ve dosyaları ekleyebilirsiniz. Ayrıca, Arabirimi ile addPyFile() Egg dosyaları ve zip dosyaları ekleyebilirsiniz. Kodu IDE'nizde her çalıştırdığınızda bağımlılık JAR'leri ve dosyaları kümeye yüklenir.
Python
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
Python + Java UDF'leri
from pyspark.sql import SparkSession
from pyspark.sql.column import _to_java_column, _to_seq, Column
## In this example, udf.jar contains compiled Java / Scala UDFs:
#package com.example
#
#import org.apache.spark.sql._
#import org.apache.spark.sql.expressions._
#import org.apache.spark.sql.functions.udf
#
#object Test {
# val plusOne: UserDefinedFunction = udf((i: Long) => i + 1)
#}
spark = SparkSession.builder \
.config("spark.jars", "/path/to/udf.jar") \
.getOrCreate()
sc = spark.sparkContext
def plus_one_udf(col):
f = sc._jvm.com.example.Test.plusOne()
return Column(f.apply(_to_seq(sc, [col], _to_java_column)))
sc._jsc.addJar("/path/to/udf.jar")
spark.range(100).withColumn("plusOne", plus_one_udf("id")).show()
Scala
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.format("parquet").load("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
Access Databricks Yardımcı Programları
Bu bölümde Databricks Yardımcı Programları'na erişmek için Databricks Bağlan'nin nasıl kullanılacağı açıklanmaktadır.
Databricks Utilities (dbutils) başvuru modülünün ve dbutils.secrets yardımcı programlarını kullanabilirsinizdbutils.fs.
Desteklenen komutlar : dbutils.fs.cp, dbutils.fs.head, dbutils.fs.ls, dbutils.fs.mkdirs, dbutils.fs.mv, dbutils.fs.put, , dbutils.fs.rm, dbutils.secrets.listdbutils.secrets.getdbutils.secrets.getBytes, dbutils.secrets.listScopes.
Bkz. Dosya sistemi yardımcı programı (dbutils.fs) veya run dbutils.fs.help() and Secrets yardımcı programı (dbutils.secrets) veya run dbutils.secrets.help().
Python
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
Databricks Runtime 7.3 LTS veya üzerini kullanırken DBUtils modülüne hem yerel olarak hem de Azure Databricks kümelerinde çalışacak şekilde erişmek için aşağıdakileri get_dbutils()kullanın:
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
Aksi takdirde, aşağıdakileri get_dbutils()kullanın:
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
Scala
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
Yerel ve uzak dosya sistemleri arasında dosya kopyalama
İstemcinizle uzak dosya sistemleri arasında dosya kopyalamak için kullanabilirsiniz dbutils.fs . Düzen file:/ , istemcideki yerel dosya sistemine başvurur.
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
Bu şekilde aktarabileceğiniz dosya boyutu üst sınırı 250 MB'tır.
dbutils.secrets.get öğesini etkinleştirin
Güvenlik kısıtlamaları nedeniyle arama dbutils.secrets.get özelliği varsayılan olarak devre dışı bırakılır. Bu özelliği çalışma alanınızda etkinleştirmek için Azure Databricks desteğine başvurun.
Hadoop yapılandırmalarını ayarlama
İstemcide, SQL ve DataFrame işlemleri için geçerli olan API'yi kullanarak spark.conf.set Hadoop yapılandırmalarını ayarlayabilirsiniz. üzerinde sparkContext ayarlanan Hadoop yapılandırmaları, küme yapılandırmasında veya bir not defteri kullanılarak ayarlanmalıdır. Bunun nedeni, üzerinde sparkContext ayarlanan yapılandırmaların kullanıcı oturumlarına bağlı olmaması ama kümenin tamamına uygulanmasıdır.
Sorun giderme
Bağlantı sorunlarını denetlemek için komutunu çalıştırın databricks-connect test . Bu bölümde Databricks Bağlan ile ilgili karşılaşabileceğiniz bazı yaygın sorunlar ve bunların nasıl çözülebileceği açıklanmaktadır.
Bu bölümde:
- Python sürümü uyuşmazlığı
- Sunucu etkinleştirilmedi
- Çakışan PySpark yüklemeleri
- Çakışan
SPARK_HOME - İkili dosyalar için çakışan veya Eksik
PATHgirdi - Kümede çakışan serileştirme ayarları
- Windows'ta bulunamıyor
winutils.exe - Windows'ta dosya adı, dizin adı veya birim etiketi söz dizimi yanlış
Python sürümü uyuşmazlığı
Yerel olarak kullandığınız Python sürümünün kümedeki sürümle en az aynı ikincil sürüme sahip olup olmadığını denetleyin (örneğin, 3.9.16 yerine 3.9.15 Tamam, 3.9 değil 3.8 ).
Yerel olarak yüklenmiş birden çok Python sürümünüz varsa, ortam değişkenini (örneğin, PYSPARK_PYTHON=python3) ayarlayarak Databricks Bağlan'nin doğru sürümü kullandığından PYSPARK_PYTHON emin olun.
Sunucu etkinleştirilmedi
Kümede Spark sunucusunun ile spark.databricks.service.server.enabled trueetkinleştirildiğinden emin olun. Varsa sürücü günlüğünde aşağıdaki satırları görmeniz gerekir:
../../.. ..:..:.. INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
../../.. ..:..:.. INFO SparkContext: Loading Spark Service RPC Server
../../.. ..:..:.. INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
../../.. ..:..:.. INFO Server: jetty-9...
../../.. ..:..:.. INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
../../.. ..:..:.. INFO Server: Started @5879ms
Çakışan PySpark yüklemeleri
Paket databricks-connect PySpark ile çakıyor. Her ikisinin de yüklü olması, Python'da Spark bağlamını başlatırken hatalara neden olur. Bu, "akış bozuk" veya "sınıf bulunamadı" hataları da dahil olmak üzere çeşitli yollarla bildirimde bulunabilir. Python ortamınızda PySpark yüklüyse databricks-connect'i yüklemeden önce kaldırıldığından emin olun. PySpark'ı kaldırdıktan sonra Databricks Bağlan paketini tamamen yeniden yüklediğinizden emin olun:
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==12.2.*" # or X.Y.* to match your specific cluster version.
Çakışan SPARK_HOME
Makinenizde daha önce Spark kullandıysanız, IDE'niz Databricks Bağlan Spark yerine Spark'ın diğer sürümlerinden birini kullanacak şekilde yapılandırılabilir. Bu, "akış bozuk" veya "sınıf bulunamadı" hataları da dahil olmak üzere çeşitli yollarla bildirimde bulunabilir. Ortam değişkeninin değerini denetleyerek Spark'ın hangi sürümünün SPARK_HOME kullanıldığını görebilirsiniz:
Python
import os
print(os.environ['SPARK_HOME'])
Scala
println(sys.env.get("SPARK_HOME"))
Java
System.out.println(System.getenv("SPARK_HOME"));
Çözüm
Spark'ın istemcideki sürümden başka bir sürümüne ayarlanırsa SPARK_HOME değişkenin SPARK_HOME ayarını kaldırıp yeniden denemeniz gerekir.
IDE ortam değişkeni ayarlarınızı, , .zshrc, veya .bash_profile dosyanızı .bashrcve başka herhangi bir ortam değişkeninin ayarlanabileceğini denetleyin. Eski durumu temizlemek için büyük olasılıkla IDE'nizden çıkmanız ve yeniden başlatmanız gerekir ve sorun devam ederse yeni bir proje oluşturmanız bile gerekebilir.
Yeni bir değere ayarlamanız SPARK_HOME gerekmez; sıfırlanmaması yeterli olmalıdır.
İkili dosyalar için çakışan veya Eksik PATH girdi
PATH'niz, gibi spark-shell komutların Databricks Bağlan ile sağlanan ikili dosya yerine daha önce yüklenmiş başka bir ikili dosya çalıştıracak şekilde yapılandırılmış olması mümkündür. Bu, başarısızlığa neden databricks-connect test olabilir. Databricks Bağlan ikili dosyalarının öncelikli olduğundan emin olmanız veya önceden yüklenmiş olanları kaldırmanız gerekir.
gibi spark-shellkomutları çalıştıramıyorsanız, PATH'iniz tarafından pip3 install otomatik olarak ayarlanmamış olabilir ve yükleme bin dizinini PATH'inize el ile eklemeniz gerekir. Bu ayar olmasa bile Databricks Bağlan IDE'lerle birlikte kullanmak mümkündür. Ancak, databricks-connect test komut çalışmaz.
Kümede çakışan serileştirme ayarları
çalıştırırken databricks-connect test"akış bozuk" hataları görürseniz bunun nedeni uyumsuz küme serileştirme yapılandırmaları olabilir. Örneğin, yapılandırmanın spark.io.compression.codec ayarlanması bu soruna neden olabilir. Bu sorunu çözmek için bu yapılandırmaları küme ayarlarından kaldırmayı veya Databricks Bağlan istemcisinde yapılandırmayı ayarlamayı göz önünde bulundurun.
Windows'ta bulunamıyor winutils.exe
Windows üzerinde Databricks Bağlan kullanıyorsanız ve bkz:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
Windows'ta Hadoop yolunu yapılandırmak için yönergeleri izleyin.
Windows'ta dosya adı, dizin adı veya birim etiketi söz dizimi yanlış
Windows ve Databricks Bağlan kullanıyorsanız aşağıdakilere bakın:
The filename, directory name, or volume label syntax is incorrect.
Java veya Databricks Bağlan yolunuzda bir boşluk bulunan bir dizine yüklendi. Boşluksuz bir dizin yoluna yükleyerek veya kısa ad formunu kullanarak yolunuzu yapılandırarak bu sorunu geçici olarak giderebilirsiniz.
Microsoft Entra ID belirteçlerini kullanarak kimlik doğrulaması
Not
Aşağıdaki bilgiler yalnızca Databricks Bağlan 7.3.5 ile 12.2.x sürümleri için geçerlidir.
Databricks Runtime 13.0 ve üzeri için Databricks Bağlan şu anda Microsoft Entra Id belirteçlerini desteklememektedir.
Databricks Bağlan 7.3.5 ile 12.2.x arası sürümleri kullandığınızda, kişisel erişim belirteci yerine Microsoft Entra ID belirteci kullanarak kimlik doğrulaması yapabilirsiniz. Microsoft Entra Id belirteçlerinin kullanım ömrü sınırlıdır. Microsoft Entra Id belirtecinin süresi dolduğunda Databricks Bağlan bir Invalid Token hatayla başarısız olur.
Databricks Bağlan 7.3.5 ile 12.2.x sürümleri için, çalışan Databricks Bağlan uygulamanızda Microsoft Entra ID belirtecini sağlayabilirsiniz. Uygulamanızın yeni erişim belirtecini alması ve SQL yapılandırma anahtarına ayarlaması spark.databricks.service.token gerekir.
Python
spark.conf.set("spark.databricks.service.token", new_aad_token)
Scala
spark.conf.set("spark.databricks.service.token", newAADToken)
Belirteci güncelleştirdikten sonra, uygulama aynı SparkSession ve oturum bağlamında oluşturulan tüm nesneleri ve durumları kullanmaya devam edebilir. Aralıklı hataları önlemek için Databricks, eski belirtecin süresi dolmadan önce yeni bir belirteç sağlamanızı önerir.
Uygulamanızın yürütülmesi sırasında kalıcı olması için Microsoft Entra ID belirtecinin ömrünü uzatabilirsiniz. Bunu yapmak için, erişim belirtecini almak için kullandığınız Microsoft Entra ID yetkilendirme uygulamasına uygun şekilde uzun ömürlü bir TokenLifetimePolicy ekleyin.
Not
Microsoft Entra Id geçişi iki belirteç kullanır: Databricks Bağlan sürüm 7.3.5 ile 12.2.x arasında yapılandırdığınız daha önce açıklanan Microsoft Entra Id erişim belirteci ve Databricks isteği işlerken Databricks'in oluşturduğu belirli kaynak için ADLS geçiş belirteci. Microsoft Entra ID belirteci yaşam süresi ilkelerini kullanarak ADLS geçiş belirteçlerinin ömrünü uzatamazsınız. Kümeye bir saatten uzun süren bir komut gönderirseniz, komut bir saat işaretinden sonra bir ADLS kaynağına erişirse başarısız olur.
Sınırlamalar
Yapılandırılmış Akış.
Uzak kümede Spark işinin parçası olmayan rastgele kod çalıştırma.
Delta tablosu işlemleri için yerel Scala, Python ve R API'leri (örneğin,
DeltaTable.forPath) desteklenmez. Ancak Delta Lake işlemlerine sahip SQL API'sinin (spark.sql(...)) ve Delta tablolarındaki Spark API'sinin (örneğin,spark.read.load) her ikisi de desteklenir.Öğesinin içine kopyalayın.
Sunucu kataloğunun bir parçası olan SQL işlevlerini, Python veya Scala UDF'lerini kullanma. Ancak, yerel olarak sunulan Scala ve Python UDF'leri çalışır.
Apache Zeppelin 0.7.x ve altı.
İşlem yalıtımı etkinleştirilmiş kümelere Bağlan (başka bir deyişle, burada
spark.databricks.pyspark.enableProcessIsolationolaraktrueayarlanır).Delta
CLONESQL komutu.Genel geçici görünümler.
Koalas ve
pyspark.pandas.CREATE TABLE table AS SELECT ...SQL komutları her zaman çalışmaz. Bunun yerine kullanınspark.sql("SELECT ...").write.saveAsTable("table").Microsoft Entra Id kimlik bilgisi geçişi yalnızca Databricks Runtime 7.3 LTS ve üzerini çalıştıran standart kümelerde desteklenir ve hizmet sorumlusu kimlik doğrulamasıyla uyumlu değildir.
Aşağıdaki Databricks Utilities (dbutils) başvurusu: