Scala için Databricks Bağlan
Not
Bu makalede Databricks Runtime 13.3 LTS ve üzeri için Databricks Bağlan yer alır.
Bu makalede, IntelliJ IDEA ile Scala ve Scala eklentisini kullanarak Databricks Bağlan kullanmaya hızlı bir şekilde başlama adımları gösterilmektedir.
- Bu makalenin Python sürümü için bkz. Python için Databricks Bağlan.
- Bu makalenin R sürümü için bkz. R için Databricks Bağlan.
Databricks Bağlan, IntelliJ IDEA, not defteri sunucuları ve diğer özel uygulamalar gibi popüler IDE'leri Azure Databricks kümelerine bağlamanızı sağlar. Bkz. Databricks Bağlan nedir?.
Öğretici
Bu öğreticiyi atlamak ve bunun yerine farklı bir IDE kullanmak için bkz . Sonraki adımlar.
Gereksinimler
Bu öğreticiyi tamamlamak için aşağıdaki gereksinimleri karşılamanız gerekir:
Hedef Azure Databricks çalışma alanınız ve kümeniz Databricks Bağlan için Küme yapılandırması gereksinimlerini karşılamalıdır.
Küme kimliğinizin kullanılabilir olması gerekir. Küme kimliğinizi almak için çalışma alanınızda kenar çubuğunda İşlem'e tıklayın ve ardından kümenizin adına tıklayın. Web tarayıcınızın adres çubuğunda, URL'de ve
configurationarasındaclusterskarakter dizesini kopyalayın.Geliştirme makinenizde Java Geliştirme Seti (JDK) yüklüdür. Databricks, kullandığınız JDK yükleme sürümünün Azure Databricks kümenizdeki JDK sürümüyle eşleşmesini önerir. Aşağıdaki tabloda desteklenen her Databricks Runtime için JDK sürümü gösterilmektedir.
Databricks Runtime sürümü JDK sürümü 13.3 LTS - 15.0,
13,3 ML LTS - 15,0 MLJDK 8 Not
Yüklü bir JDK'niz yoksa veya geliştirme makinenizde birden çok JDK yüklüyse, 1. Adım'ın devamında belirli bir JDK yükleyebilir veya seçebilirsiniz. Kümenizdeki JDK sürümünün altında veya üzerinde bir JDK yüklemesi seçmek beklenmeyen sonuçlara neden olabilir veya kodunuz hiç çalışmayabilir.
IntelliJ IDEA yüklüdür. Bu öğretici IntelliJ IDEA Community Edition 2023.3.6 ile test edilmiştir. IntelliJ IDEA'nın farklı bir sürümünü veya sürümünü kullanıyorsanız aşağıdaki yönergeler farklılık gösterebilir.
IntelliJ IDEA için Scala eklentisi yüklüdür.
1. Adım: Azure Databricks kimlik doğrulamayı yapılandırma
Bu öğreticide Azure Databricks çalışma alanınızla kimlik doğrulaması yapmak için Azure Databricks OAuth kullanıcıdan makineye (U2M) kimlik doğrulaması ve Azure Databricks yapılandırma profili kullanılır. Bunun yerine farklı bir kimlik doğrulama türü kullanmak için bkz . Bağlantı özelliklerini yapılandırma.
OAuth U2M kimlik doğrulamasını yapılandırmak için Databricks CLI gerekir:
Henüz yüklü değilse Databricks CLI'yi aşağıdaki gibi yükleyin:
Linux, macos
Aşağıdaki iki komutu çalıştırarak Databricks CLI'yi yüklemek için Homebrew kullanın:
brew tap databricks/tap brew install databricksWindows
Databricks CLI'yı yüklemek için winget, Chocolatey veya Linux için Windows Alt Sistemi (WSL) kullanabilirsiniz. , Chocolatey veya WSL kullanamıyorsanız
winget, bu yordamı atlayıp Komut İstemi'ni veya PowerShell'i kullanarak Databricks CLI'yi kaynaktan yüklemeniz gerekir.Databricks CLI'yı yüklemek için kullanmak
wingetiçin aşağıdaki iki komutu çalıştırın ve komut isteminizi yeniden başlatın:winget search databricks winget install Databricks.DatabricksCLIChocolatey'yi kullanarak Databricks CLI'yı yüklemek için aşağıdaki komutu çalıştırın:
choco install databricks-cliWSL kullanarak Databricks CLI'yi yüklemek için:
WSL aracılığıyla ve
zipyükleyincurl. Daha fazla bilgi için işletim sisteminizin belgelerine bakın.Aşağıdaki komutu çalıştırarak Databricks CLI'yi yüklemek için WSL kullanın:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
Yüklü Databricks CLI'nın geçerli sürümünü görüntüleyen aşağıdaki komutu çalıştırarak Databricks CLI'nin yüklendiğini onaylayın. Bu sürüm 0.205.0 veya üzeri olmalıdır:
databricks -vNot
komutunu çalıştırır
databricksancak gibicommand not found: databricksbir hata alırsanız veya çalıştırırsanızdatabricks -vve 0,18 veya daha yeni bir sürüm numarası listelenirse, bu, makinenizin Databricks CLI yürütülebilir dosyasının doğru sürümünü bulamadığı anlamına gelir. Bunu düzeltmek için bkz . CLI yüklemenizi doğrulama.
Aşağıdaki gibi OAuth U2M kimlik doğrulamasını başlatın:
-
Aşağıdaki komutta değerini çalışma alanı başına Azure Databricks URL'nizle değiştirin
<workspace-url>, örneğinhttps://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url> Databricks CLI, Azure Databricks yapılandırma profili olarak girdiğiniz bilgileri kaydetmenizi ister. Önerilen profil adını kabul etmek için basın
Enterveya yeni veya mevcut bir profilin adını girin. Girdiğiniz bilgilerle aynı ada sahip mevcut tüm profillerin üzerine yazılır. Birden çok çalışma alanında kimlik doğrulama bağlamınızı hızla değiştirmek için profilleri kullanabilirsiniz.Mevcut profillerin listesini almak için, ayrı bir terminalde veya komut isteminde Databricks CLI'yi kullanarak komutunu
databricks auth profilesçalıştırın. Belirli bir profilin mevcut ayarlarını görüntülemek için komutunudatabricks auth env --profile <profile-name>çalıştırın.Web tarayıcınızda, Azure Databricks çalışma alanınızda oturum açmak için ekrandaki yönergeleri tamamlayın.
Terminalinizde veya komut isteminizde görüntülenen kullanılabilir kümeler listesinde, çalışma alanınızdaki hedef Azure Databricks kümesini seçmek için yukarı ve aşağı ok tuşlarınızı kullanın ve ardından tuşuna basın
Enter. Kullanılabilir kümelerin listesini filtrelemek için kümenin görünen adının herhangi bir bölümünü de yazabilirsiniz.Profilin geçerli OAuth belirteci değerini ve belirtecin yaklaşan süre sonu zaman damgasını görüntülemek için aşağıdaki komutlardan birini çalıştırın:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Aynı
--hostdeğere sahip birden çok profiliniz varsa Databricks CLI'sının--hostdoğru eşleşen OAuth belirteci bilgilerini bulmasına yardımcı olmak için ve-pseçeneklerini birlikte belirtmeniz gerekebilir.
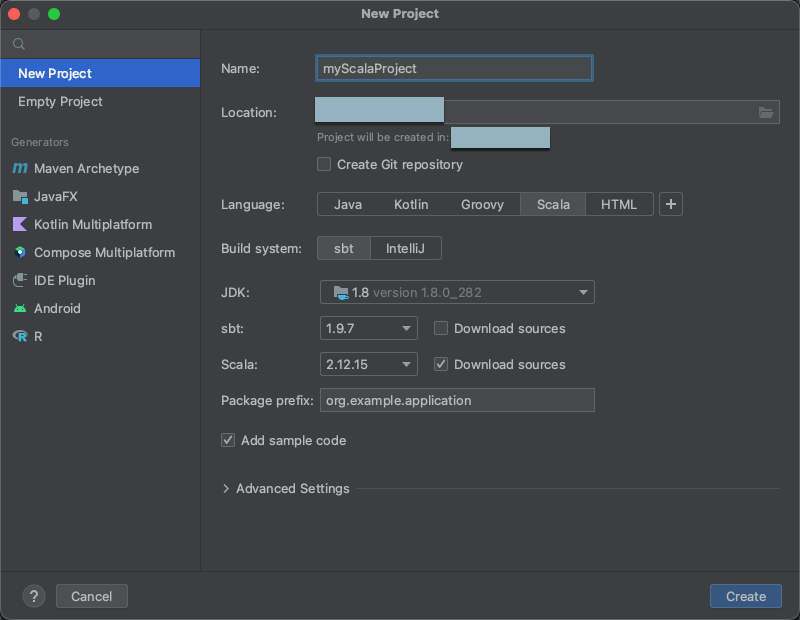
2. Adım: Projeyi oluşturma
IntelliJ IDEA’yı başlatın.
Ana menüde Dosya Yeni Proje'ye> tıklayın>.
Projenize anlamlı bir Ad verin.
Konum için klasör simgesine tıklayın ve yeni Scala projenizin yolunu belirtmek için ekrandaki yönergeleri tamamlayın.
Dil için Scala'ya tıklayın.
Derleme sistemi için sbt'ye tıklayın.
JDK açılan listesinde, geliştirme makinenizde JDK'nin kümenizdeki JDK sürümüyle eşleşen mevcut bir yüklemesini seçin veya JDK'yi İndir'i seçin ve kümenizdeki JDK sürümüyle eşleşen bir JDK indirmek için ekrandaki yönergeleri izleyin.
Not
Kümenizdeki JDK sürümünün üzerinde veya altında bir JDK yüklemesi seçmek beklenmeyen sonuçlara neden olabilir veya kodunuz hiç çalışmayabilir.
sbt açılan listesinde en son sürümü seçin.
Scala açılan listesinde, kümenizdeki Scala sürümüyle eşleşen Scala sürümünü seçin. Aşağıdaki tabloda desteklenen her Databricks Runtime için Scala sürümü gösterilmektedir:
Databricks Runtime sürümü Scala sürümü 13.3 LTS - 15.0,
13,3 ML LTS - 15,0 ML2.12.15 Not
Kümenizdeki Scala sürümünün altında veya üstünde bir Scala sürümü seçmek beklenmeyen sonuçlara neden olabilir veya kodunuz hiç çalışmayabilir.
Scala'nın yanındaki Kaynakları indir kutusunun işaretli olduğundan emin olun.
Paket ön eki için projenizin kaynakları için paket ön eki değeri girin, örneğin
org.example.application.Örnek kod ekle kutusunun işaretli olduğundan emin olun.
Oluştur’a tıklayın.
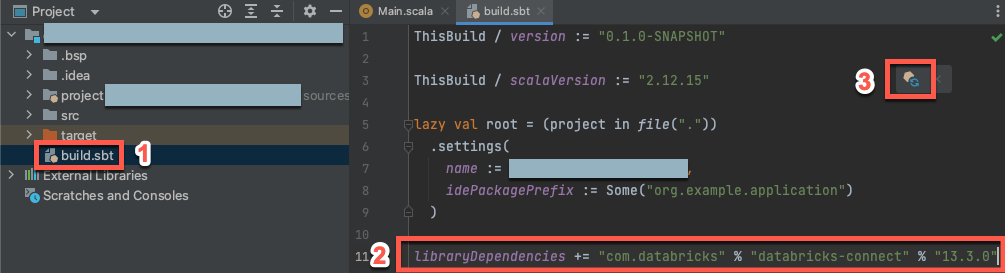
3. Adım: Databricks Bağlan paketini ekleme
Yeni Scala projeniz açıkken, Proje aracı pencerenizde (Görünüm > Aracı Windows > Projesi), adlı
build.sbtdosyayı proje adı> hedefinde açın.Projenizin Scala için Databricks Bağlan kitaplığının belirli bir sürümüne bağımlılığını bildiren dosyanın sonuna
build.sbtaşağıdaki kodu ekleyin:libraryDependencies += "com.databricks" % "databricks-connect" % "14.3.1"değerini, kümenizdeki Databricks Runtime sürümüyle eşleşen Databricks Bağlan kitaplığının sürümüyle değiştirin
14.3.1. Databricks Bağlan kitaplığı sürüm numaralarını Maven merkezi deposunda bulabilirsiniz.Scala projenizi yeni kitaplık konumu ve bağımlılığıyla güncelleştirmek için Sbt değişikliklerini yükle bildirim simgesine tıklayın.
IDE'nin
sbtaltındaki ilerleme göstergesi kaybolana kadar bekleyin. Yükleme işlemininsbttamamlanması birkaç dakika sürebilir.
4. Adım: Kod ekleme
Proje aracı pencerenizde, adlı
Main.scaladosyayı proje adı> src > ana > scala'da açın.Dosyadaki mevcut kodları aşağıdaki kodla değiştirin ve yapılandırma profilinizin adına bağlı olarak dosyayı kaydedin.
1. Adım'daki yapılandırma profilinizin adı
DEFAULTise, dosyadaki mevcut kodları aşağıdaki kodla değiştirin ve dosyayı kaydedin:package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }1. Adım'daki yapılandırma profiliniz olarak adlandırılmıyorsa
DEFAULT, dosyadaki mevcut kodları aşağıdaki kodla değiştirin. Yer tutucuyu<profile-name>1. Adımdaki yapılandırma profilinizin adıyla değiştirin ve dosyayı kaydedin:package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
5. Adım: Kodu çalıştırma
- Hedef kümeyi uzak Azure Databricks çalışma alanınızda başlatın.
- Küme başlatıldıktan sonra, ana menüde Çalıştır 'Ana' çalıştır'a > tıklayın.
- Çalıştır aracı penceresinde (Görünüm > Aracı Windows > Çalıştırması), Ana sekmesinde tablonun ilk 5 satırı
samples.nyctaxi.tripsgörüntülenir.
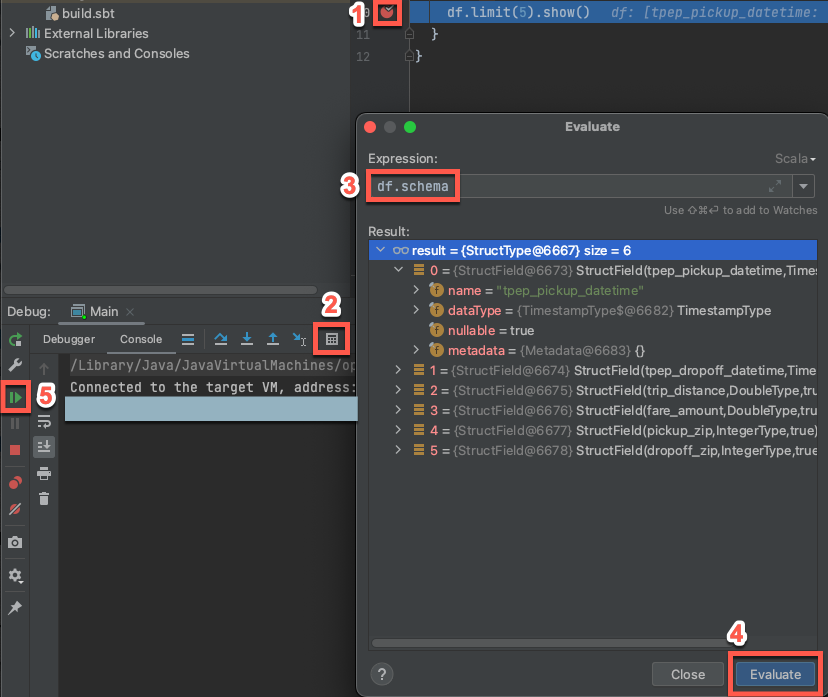
6. Adım: Kodda hata ayıklama
- Hedef küme çalışmaya devam ediyorken, önceki kodda kesme noktası ayarlamak için yanındaki oluk simgesine
df.limit(5).show()tıklayın. - Ana menüde Hata Ayıklamayı 'Ana' Çalıştır'a> tıklayın.
- Hata Ayıklama aracı penceresinde (Görünüm > Aracı Windows > Hata Ayıklama), Konsol sekmesinde hesap makinesi (İfadeyi Değerlendir) simgesine tıklayın.
- İfadeyi
df.schemagirin ve DataFrame şemasını göstermek için Değerlendir'e tıklayın. - Hata ayıklama aracı penceresinin kenar çubuğunda yeşil ok (Programı Sürdür) simgesine tıklayın.
- Konsol bölmesinde tablonun ilk 5 satırı
samples.nyctaxi.tripsgörüntülenir.
Sonraki adımlar
Databricks Bağlan hakkında daha fazla bilgi edinmek için aşağıdakiler gibi makalelere bakın:
Azure Databricks kişisel erişim belirteci dışındaki Azure Databricks kimlik doğrulama türlerini kullanmak için bkz . Bağlantı özelliklerini yapılandırma.
Diğer IDE'leri kullanmak için aşağıdakilere bakın:
Ek basit kod örneklerini görüntülemek için bkz. Scala için Databricks Bağlan kod örnekleri.
Daha karmaşık kod örneklerini görüntülemek için Bkz. GitHub'daki Databricks Bağlan deposu için örnek uygulamalar, özellikle:
Databricks Runtime 12.2 LTS ve altı için Databricks Bağlan'dan Databricks Runtime 13.3 LTS ve üzeri için Databricks Bağlan'a geçiş yapmak için bkz. Scala için Databricks Bağlan'ne geçiş.
Ayrıca bkz. Sorun giderme ve sınırlamalar hakkında bilgi.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin