Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu öğreticide , IntelliJ IDEA ve Scala eklentisini kullanarak Scala için Databricks Connect'i kullanmaya başlama adımları gösterilmektedir.
Bu öğreticide IntelliJ IDEA'da bir proje oluşturacak, Databricks Runtime 13.3 LTS ve üzeri için Databricks Connect'i yükleyecek ve IntelliJ IDEA'dan Databricks çalışma alanınızda işlem üzerinde basit kod çalıştıracaksınız.
Tavsiye
Bildirim temelli Otomasyon Paketlerini kullanarak sunucusuz işlem üzerinde kod çalıştıran bir Scala projesi oluşturmayı öğrenmek için bkz. Bildirim temelli Otomasyon Paketlerini kullanarak Scala JAR oluşturma.
Gereksinimler
Bu öğreticiyi tamamlamak için aşağıdaki gereksinimleri karşılamanız gerekir:
Çalışma alanınız, yerel ortamınız ve işleminiz Scala için Databricks Connect gereksinimlerini karşılar. Bkz. Databricks Connect kullanım gereksinimleri.
Küme kimliğinizin kullanılabilir olması gerekir. Küme kimliğinizi almak için çalışma alanınızda kenar çubuğunda İşlem'e tıklayın ve ardından kümenizin adına tıklayın. Web tarayıcınızın adres çubuğunda, URL'deki
clustersveconfigurationarasındaki karakter dizesini kopyalayın.Geliştirme makinenizde Java Geliştirme Seti (JDK) yüklüdür. Yüklenecek sürüm hakkında bilgi için bkz. sürüm destek matrisi.
Uyarı
Yüklü bir JDK'niz yoksa veya geliştirme makinenizde birden çok JDK yüklüyse, 1. Adım'ın devamında belirli bir JDK yükleyebilir veya seçebilirsiniz. Kümenizdeki JDK sürümünün altında veya üzerinde bir JDK yüklemesi seçmek beklenmeyen sonuçlara neden olabilir veya kodunuz hiç çalışmayabilir.
IntelliJ IDEA yüklüdür. Bu öğretici IntelliJ IDEA Community Edition 2023.3.6 ile test edilmiştir. IntelliJ IDEA'nın farklı bir sürümünü veya sürümünü kullanıyorsanız aşağıdaki yönergeler farklılık gösterebilir.
IntelliJ IDEA için Scala eklentisi yüklüdür.
1. Adım: Azure Databricks kimlik doğrulamayı yapılandırma
Bu öğreticide Azure Databricks çalışma alanınızla kimlik doğrulaması yapmak için Azure Databricks OAuth kullanıcıdan makineye (U2M) kimlik doğrulaması ve Azure Databricks yapılandırma profili kullanılır. Bunun yerine farklı bir kimlik doğrulama türü kullanmak için bkz . Bağlantı özelliklerini yapılandırma.
OAuth U2M kimlik doğrulamasını yapılandırmak için Databricks CLI gerekir:
Databricks CLI'yi yükleyin:
Linux, macOS
Aşağıdaki iki komutu çalıştırarak Databricks CLI'yi yüklemek için Homebrew kullanın:
brew tap databricks/tap brew install databricksWindows
Databricks CLI'yı yüklemek için winget, Chocolatey veya Linux için Windows Alt Sistemi (WSL) kullanabilirsiniz. , Chocolatey veya WSL kullanamıyorsanız
winget, bu yordamı atlayıp Komut İstemi'ni veya PowerShell'i kullanarak Databricks CLI'yi kaynaktan yüklemeniz gerekir.Databricks CLI'yi kurmak için
wingetkullanarak aşağıdaki iki komutu çalıştırın ve sonra Komut İstemini yeniden başlatın.winget search databricks winget install Databricks.DatabricksCLIChocolatey'yi kullanarak Databricks CLI'yı yüklemek için aşağıdaki komutu çalıştırın:
choco install databricks-cliWSL kullanarak Databricks CLI'yi yüklemek için:
curlvezip'yi WSL aracılığıyla yükleyin. Daha fazla bilgi için işletim sisteminizin belgelerine bakın.Aşağıdaki komutu çalıştırarak Databricks CLI'yi yüklemek için WSL kullanın:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
Yüklü Databricks CLI'nın geçerli sürümünü görüntüleyen aşağıdaki komutu çalıştırarak Databricks CLI'nin yüklendiğini onaylayın. Bu sürüm 0.205.0 veya üzeri olmalıdır:
databricks -v
Aşağıdaki gibi OAuth U2M kimlik doğrulamasını başlatın:
-
Aşağıdaki komutta,
<workspace-url>öğesini Azure Databricks çalışma alanı başı URL'nizle değiştirin, örneğinhttps://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url> Databricks CLI, Azure Databricks yapılandırma profili olarak girdiğiniz bilgileri kaydetmenizi ister. Önerilen profil adını kabul etmek için basın
Enterveya yeni veya mevcut bir profilin adını girin. Aynı ada sahip herhangi bir mevcut profil, girdiğiniz bilgilerle üzerine yazılır. Birden çok çalışma alanında kimlik doğrulama bağlamınızı hızla değiştirmek için profilleri kullanabilirsiniz.Mevcut profillerin listesini almak için, ayrı bir terminalde veya komut isteminde Databricks CLI'yı kullanarak komutunu
databricks auth profilesçalıştırın. Belirli bir profilin mevcut ayarlarını görüntülemek için komutunudatabricks auth env --profile <profile-name>çalıştırın.Web tarayıcınızda, Azure Databricks çalışma alanınızda oturum açmak için ekrandaki yönergeleri tamamlayın.
Terminalinizde veya komut isteminizde görüntülenen kullanılabilir kümeler listesinde, çalışma alanınızdaki hedef Azure Databricks kümesini seçmek için yukarı ve aşağı ok tuşlarınızı kullanın ve ardından
Entertuşuna basın. Kullanılabilir kümelerin listesini filtrelemek için kümenin görünen adının herhangi bir bölümünü de yazabilirsiniz.Profilin geçerli OAuth belirteci değerini ve belirtecin yaklaşan süre sonu zaman damgasını görüntülemek için aşağıdaki komutlardan birini çalıştırın:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Aynı
--hostdeğere sahip birden çok profiliniz varsa Databricks CLI'sının--hostdoğru eşleşen OAuth belirteci bilgilerini bulmasına yardımcı olmak için ve-pseçeneklerini birlikte belirtmeniz gerekebilir.
2. Adım: Projeyi oluşturma
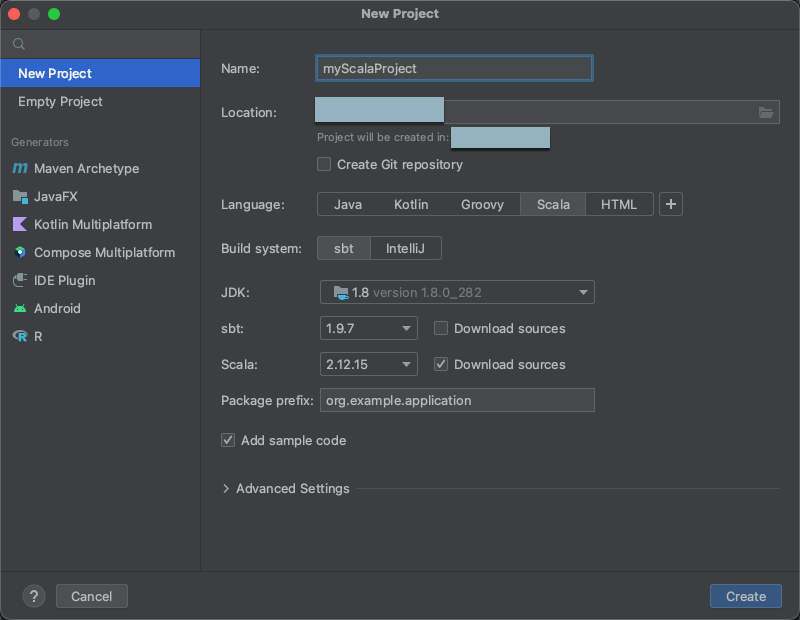
IntelliJ IDEA'ya başlayın.
Ana menüde, Dosya > Yeni > Proje'ye tıklayın.
Projenize anlamlı Adverin.
Konumiçin klasör simgesine tıklayın ve yeni Scala projenizin yolunu belirtmek için ekrandaki yönergeleri tamamlayın.
Diliçin Scala'e tıklayın.
Derleme sistemiiçin sbt'e tıklayın.
JDK açılan listesinde, geliştirme makinenizde JDK'nin kümenizdeki JDK sürümüyle eşleşen mevcut bir yüklemesini seçin veya JDK indirin'i seçin ve kümenizdeki JDK sürümüyle eşleşen bir JDK indirmek için ekrandaki yönergeleri izleyin. Bkz . Gereksinimler.
Uyarı
Kümenizdeki JDK sürümünün üzerinde veya altında bir JDK yüklemesi seçmek beklenmeyen sonuçlara neden olabilir veya kodunuz hiç çalışmayabilir.
sbt açılan listesinde en son sürümü seçin.
Scala açılan listesinde, kümenizdeki Scala sürümüyle eşleşen Scala sürümünü seçin. Bkz . Gereksinimler.
Uyarı
Kümenizdeki Scala sürümünün altında veya üstünde bir Scala sürümü seçmek beklenmeyen sonuçlara neden olabilir veya kodunuz hiç çalışmayabilir.
Scala'nın yanındaki Kaynakları indir kutusunun işaretli olduğundan emin olun.
Paket ön eki için projenizin kaynakları için paket ön eki değeri girin, örneğin
org.example.application.Örnek kod ekle kutusunun işaretli olduğundan emin olun.
Oluştur'utıklayın.
3. Adım: Databricks Connect paketini ekleme
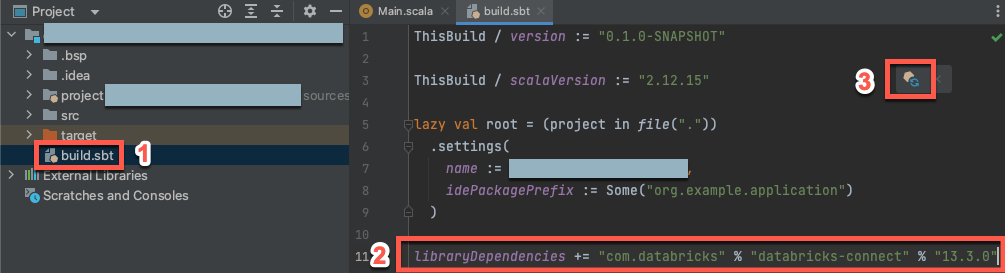
Yeni Scala projeniz açıkken, Proje araç penceresinde (Görünüm > Araç Pencereleri > Proje),
build.sbtadlı dosyayı açın; bu dosya, proje adı> hedefaltında bulunur.Aşağıdaki kodu dosyanın sonuna
build.sbtekleyin. Bu kod, projenizin kümenizin Databricks Runtime sürümüyle uyumlu olan Scala için Databricks Connect kitaplığının belirli bir sürümüne bağımlılığını bildirir:libraryDependencies += "com.databricks" %% "databricks-connect" % "17.3.+"17.3değerini, kümenizdeki Databricks Runtime sürümüyle eşleşen Databricks Connect kitaplığının sürümüyle değiştirin. Örneğin Databricks Connect 17.3.+, Databricks Runtime 17.3 LTS ile eşleşir. Databricks Connect kitaplığı sürüm numaralarını Maven merkezi deposundabulabilirsiniz.Uyarı
Databricks Connect ile derleme yaparken projenizde olduğu gibi
org.apache.spark:spark-coreApache Spark yapıtlarını eklemeyin. Bunun yerine, doğrudan Databricks Connect'e karşı derleyin.Scala projenizi yeni kitaplık konumu ve bağımlılıklarıyla güncelleştirmek için SBT değişikliklerini yükle bildirim simgesine basarak güncelleyin.
IDE'nin altındaki
sbtilerleme göstergesinin kaybolmasını bekleyin.sbtyükleme işleminin tamamlanması birkaç dakika sürebilir.
4. Adım: Kod ekleme
Project araç pencerenizde
Main.scalaadlı dosyayı proje adı> src > main > scalaaçın.Dosyadaki mevcut kodları aşağıdaki kodla değiştirin ve yapılandırma profilinizin adına bağlı olarak dosyayı kaydedin.
1. Adım'daki yapılandırma profilinizin adı
DEFAULTise, dosyadaki mevcut kodları aşağıdaki kodla değiştirin ve dosyayı kaydedin:package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }Adım 1'deki yapılandırma profiliniz "
DEFAULT" olarak adlandırılmamışsa, dosyadaki mevcut kodu aşağıdaki kodla değiştirin. Yer tutucuyu<profile-name>1. Adımdaki yapılandırma profilinizin adıyla değiştirin ve dosyayı kaydedin:package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
5. Adım: VM seçeneklerini yapılandırma
IntelliJ IDE'nizde
build.sbtkonumunda bulunan geçerli dizini içe aktarın.IntelliJ'de Java 17'yi seçin. Dosya>Proje Yapısı>SDK'larına gidin.
src/main/scala/com/examples/Main.scala'ı açın.VM seçenekleri eklemek için Main yapılandırmasına gidin:
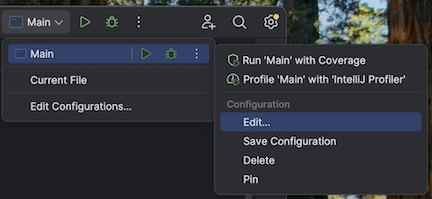
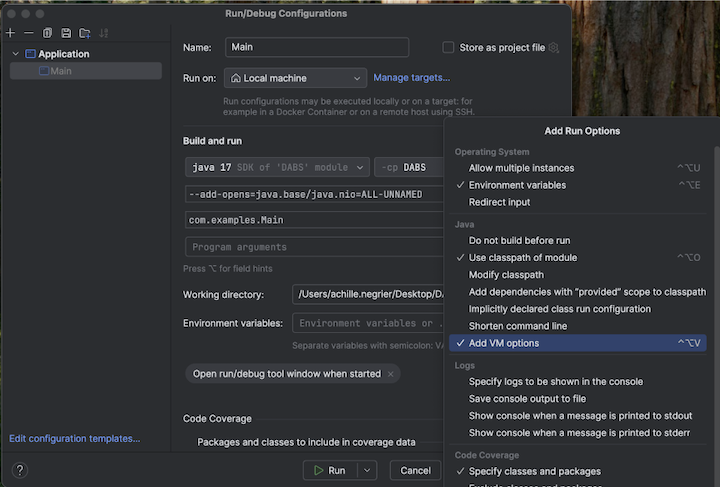
VM seçeneklerinize aşağıdakileri ekleyin:
--add-opens=java.base/java.nio=ALL-UNNAMED
Tavsiye
Alternatif olarak veya Visual Studio Code kullanıyorsanız sbt derleme dosyanıza aşağıdakileri ekleyin:
fork := true
javaOptions += "--add-opens=java.base/java.nio=ALL-UNNAMED"
Ardından uygulamanızı terminalden çalıştırın:
sbt run
6. Adım: Kodu çalıştırma
- Hedef kümeyi uzak Azure Databricks çalışma alanınızda başlatın.
- Küme başlatıldıktan sonra, ana menüde
'Main'i çalıştır< c0 /> seçeneğine tıklayın. -
Çalıştır aracı penceresinde (Görünüm > Aracı Windows >Çalıştır ) Ana sekmesinde,
samples.nyctaxi.tripstablosunun ilk 5 satırı görüntülenir.
7. Adım: Kodda hata ayıklama
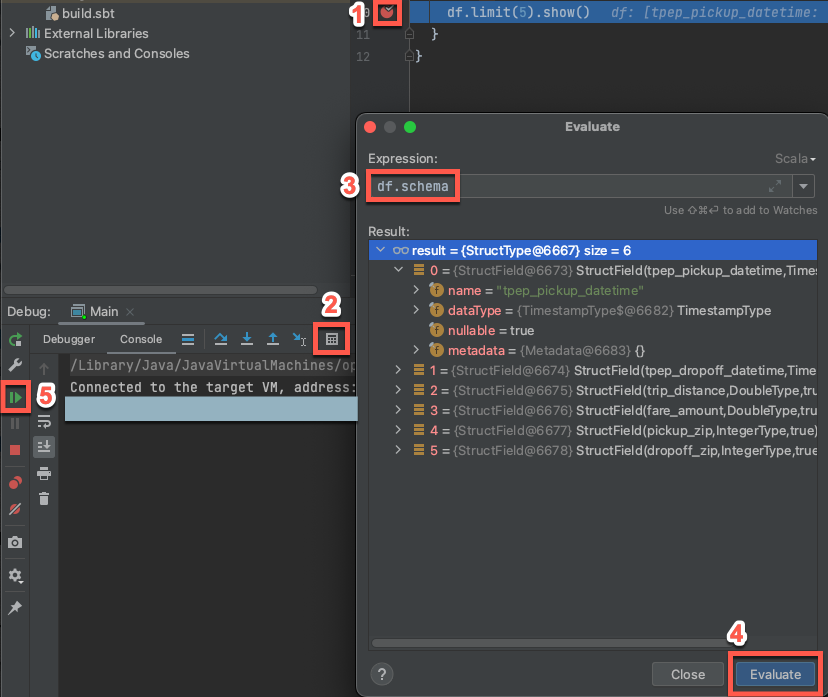
Hedef küme hâlâ çalışıyorken, yukarıdaki kodda
df.limit(5).show()'ın yanındaki kenar boşluğuna tıklayarak bir kesme noktası ayarlayın.Ana menüde, 'Ana' Hata Ayıklamayı Çalıştır> üzerine tıklayın. Hata Ayıklama aracı penceresinde (Görünüm > Aracı Windows > Hata Ayıklama), Konsolu sekmesinde hesap makinesine (İfadeyi Değerlendir) simgesine tıklayın.
ifadesini
df.schemagirin.DataFrame şemasını göstermek için Değerlendir'e tıklayın.
Hata ayıklama aracı penceresinin kenar çubuğunda yeşil ok (Programı Sürdür) simgesine tıklayın. Tablonun ilk 5 satırı
samples.nyctaxi.tripsKonsol bölmesinde görünür.