Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu öğretici, bilgi edinme ve araçları birlikte kullanan bir yapay zeka ajanı oluşturma işleminde size yol gösterir.
Bu, Databricks'te bir aracın oluşturulması hakkında temel bilgiye sahip olduğunuzu varsayan bir orta düzey eğitimdir. Aracı oluşturmaya yeni başladıysanız bkz. Yapay zeka aracılarını kullanmaya başlama.
örnek not defteri öğreticide kullanılan tüm kodları içerir.
Bu öğretici, üretken yapay zeka uygulamaları oluşturmanın temel zorluklarından bazılarını kapsar:
- Araç oluşturma ve aracı yürütme hatalarını ayıklama gibi yaygın görevler için geliştirme deneyiminin akışını yapma.
- Operasyonel zorluklar:
- Ajan yapılandırmasını izleme
- Girişleri ve çıkışları tahmin edilebilir bir şekilde tanımlama
- Bağımlılıkların sürümlerini yönetme
- Sürüm denetimi ve dağıtımı
- Bir temsilcinin kalitesini ve güvenilirliğini ölçme ve geliştirme.
Kolaylık olması için bu öğreticide, öbeklenmiş Databricks belgelerini içeren bir veri kümesi üzerinde anahtar sözcük aramasını etkinleştirmek için bellek içi bir yaklaşım kullanılır.
Örnek not defteri
Bu tek başına not defteri, örnek bir belge corpus kullanarak Mozaik AI aracılarıyla hızlı bir şekilde çalışmanızı sağlamak için tasarlanmıştır. Kurulum veya veri gerektirmeden çalışmaya hazırdır.
Mozaik yapay zeka aracısı tanıtımı
Ajan ve araçlar oluşturma
Mozaik AI Aracısı Çerçevesi birçok farklı yazma çerçevesini destekler. Bu örnek, kavramları göstermek için LangGraph kullanır, ancak bu bir LangGraph öğreticisi değildir.
Desteklenen diğer çerçevelerin örnekleri için bkz. Bir yapay zeka aracısı yazma ve databricks uygulamalarında dağıtma.
İlk adım bir aracı oluşturmaktır. LlM istemcisi ve araç listesi belirtmeniz gerekir.
databricks-langchain Python paketi hem Databricks LLM'leri hem de Unity Kataloğu'nda kayıtlı araçlar için LangChain ve LangGraph uyumlu istemciler içerir.
Uç nokta, AI Gateway kullanan işlev çağıran bir Temel Model API'si veya Dış Model olmalıdır. Bkz. Desteklenen modeller.
from databricks_langchain import ChatDatabricks
llm = ChatDatabricks(endpoint="databricks-meta-llama-3-3-70b-instruct")
Aşağıdaki kod, modelden ve bazı araçlardan aracı oluşturan bir işlevi tanımlar ve bu aracı kodunun içleri bu sayfanın kapsamı dışındadır. LangGraph aracısı oluşturma hakkında daha fazla bilgi için LangGraph belgelerinebakın.
from typing import Optional, Sequence, Union
from langchain_core.language_models import LanguageModelLike
from langchain_core.runnables import RunnableConfig, RunnableLambda
from langchain_core.tools import BaseTool
from langgraph.graph import END, StateGraph
from langgraph.graph.graph import CompiledGraph
from langgraph.prebuilt.tool_executor import ToolExecutor
from mlflow.langchain.chat_agent_langgraph import ChatAgentState, ChatAgentToolNode
def create_tool_calling_agent(
model: LanguageModelLike,
tools: Union[ToolExecutor, Sequence[BaseTool]],
agent_prompt: Optional[str] = None,
) -> CompiledGraph:
model = model.bind_tools(tools)
def routing_logic(state: ChatAgentState):
last_message = state["messages"][-1]
if last_message.get("tool_calls"):
return "continue"
else:
return "end"
if agent_prompt:
system_message = {"role": "system", "content": agent_prompt}
preprocessor = RunnableLambda(
lambda state: [system_message] + state["messages"]
)
else:
preprocessor = RunnableLambda(lambda state: state["messages"])
model_runnable = preprocessor | model
def call_model(
state: ChatAgentState,
config: RunnableConfig,
):
response = model_runnable.invoke(state, config)
return {"messages": [response]}
workflow = StateGraph(ChatAgentState)
workflow.add_node("agent", RunnableLambda(call_model))
workflow.add_node("tools", ChatAgentToolNode(tools))
workflow.set_entry_point("agent")
workflow.add_conditional_edges(
"agent",
routing_logic,
{
"continue": "tools",
"end": END,
},
)
workflow.add_edge("tools", "agent")
return workflow.compile()
Ajan araçlarını tanımla
Araçlar, ajanlar oluşturmak için temel bir kavramdır. LLM'leri insan tanımlı kodla tümleştirme olanağı sağlar. Bir istem ve araç listesi sağlandığında, bir aracı çağırmak için gerekli parametreleri oluşturan bir LLM devreye girer. Daha fazla bilgi için, araçlar ve bunları Mosaic yapay zeka aracılarıyla kullanma hakkında ayrıntılara bakınız: Mosaic yapay zeka aracısı araçları.
İlk adım , TF-IDF'yi temel alan bir anahtar sözcük ayıklama aracı oluşturmaktır. Bu örnekte scikit-learn ve Unity Kataloğu aracı kullanılır.
databricks-langchain paketi Unity Kataloğu araçlarıyla çalışmak için kullanışlı bir yol sağlar. Aşağıdaki kodda anahtar sözcük ayıklayıcı aracının nasıl uygulanıp kaydedilecekleri gösterilmektedir.
Uyarı
Databricks çalışma alanında, korumalı bir ortamda Python betikleri çalıştırma yeteneğine sahip ajanları genişletmek için kullanabileceğiniz yerleşik bir araç, system.ai.python_exec, bulunmaktadır. Diğer kullanışlı yerleşik araçlar arasında dış bağlantılar ve yapay zeka işlevleri yer alır.
from databricks_langchain.uc_ai import (
DatabricksFunctionClient,
UCFunctionToolkit,
set_uc_function_client,
)
uc_client = DatabricksFunctionClient()
set_uc_function_client(uc_client)
# Change this to your catalog and schema
CATALOG = "main"
SCHEMA = "my_schema"
def tfidf_keywords(text: str) -> list[str]:
"""
Extracts keywords from the provided text using TF-IDF.
Args:
text (string): Input text.
Returns:
list[str]: List of extracted keywords in ascending order of importance.
"""
from sklearn.feature_extraction.text import TfidfVectorizer
def keywords(text, top_n=5):
vec = TfidfVectorizer(stop_words="english")
tfidf = vec.fit_transform([text]) # Convert text to TF-IDF matrix
indices = tfidf.toarray().argsort()[0, -top_n:] # Get indices of top N words
return [vec.get_feature_names_out()[i] for i in indices]
return keywords(text)
# Create the function in the Unity Catalog catalog and schema specified
# When you use `.create_python_function`, the provided function's metadata
# (docstring, parameters, return type) are used to create a tool in the specified catalog and schema.
function_info = uc_client.create_python_function(
func=tfidf_keywords,
catalog=CATALOG,
schema=SCHEMA,
replace=True, # Set to True to overwrite if the function already exists
)
print(function_info)
Yukarıdaki kodun açıklaması aşağıdadır:
- Araçları oluşturmak ve bulmak için Databricks çalışma alanında Unity Kataloğu'nu "kayıt defteri" olarak kullanan bir istemci oluşturur.
- TF-IDF anahtar sözcük ayıklaması gerçekleştiren bir Python işlevi tanımlar.
- Python işlevini Unity Kataloğu işlevi olarak kaydeder.
Bu iş akışı birçok yaygın sorunu çözer. Artık Unity Kataloğu'ndaki diğer nesneler gibi yönetilebilen araçlar için merkezi bir kayıt defteriniz var. Örneğin, bir şirketin iç verim oranını hesaplamak için standart bir yolu varsa, bunu Unity Kataloğu'nda işlev olarak tanımlayabilir ve FinancialAnalyst rolüne sahip tüm kullanıcılara veya aracılara erişim vekleyebilirsiniz.
Bu aracı bir LangChain aracısı tarafından kullanılabilir hale getirmek için LLM'ye seçim için vermek üzere bir araç koleksiyonu oluşturan UCFunctionToolkit'i kullanın:
# Use ".*" here to specify all the tools in the schema, or
# explicitly list functions by name
# uc_tool_names = [f"{CATALOG}.{SCHEMA}.*"]
uc_tool_names = [f"{CATALOG}.{SCHEMA}.tfidf_keywords"]
uc_toolkit = UCFunctionToolkit(function_names=uc_tool_names)
Aşağıdaki kod aracın nasıl test yapılacağını gösterir:
uc_toolkit.tools[0].invoke({ "text": "The quick brown fox jumped over the lazy brown dog." })
Aşağıdaki kod, anahtar sözcük ayıklama aracını kullanan bir aracı oluşturur.
import mlflow
mlflow.langchain.autolog()
agent = create_tool_calling_agent(llm, tools=[*uc_toolkit.tools])
agent.invoke({"messages": [{"role": "user", "content":"What are the keywords for the sentence: 'the quick brown fox jumped over the lazy brown dog'?"}]})
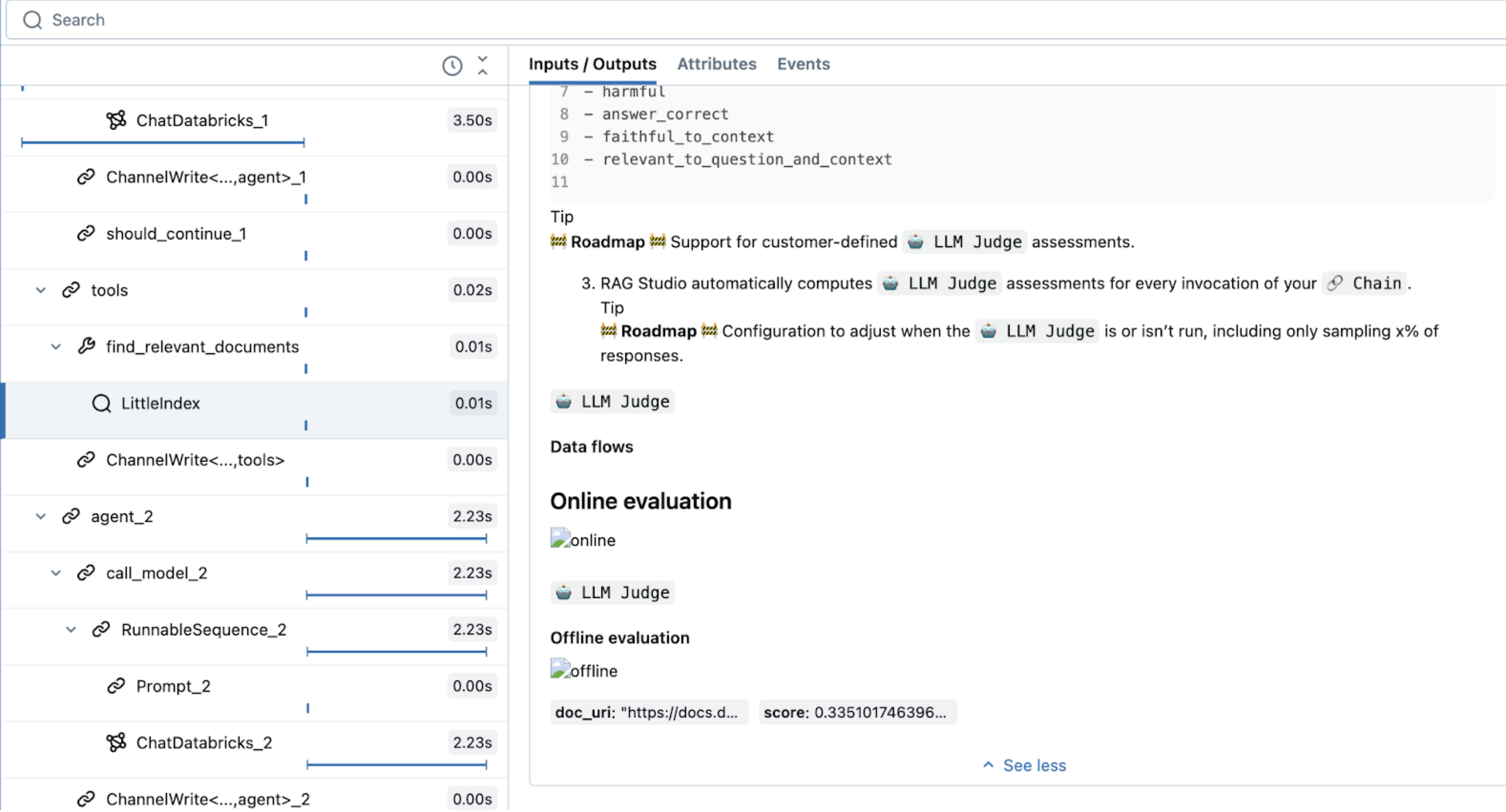
Elde edilen izlemede LLM'nin aracı seçtiğini görebilirsiniz.
Not defterinde araç seçimini gösteren MLflow izleme çıktısını 
Ajanlarda hata ayıklamak için izlemeleri kullanma
MLflow İzleme, aracılar dahil olmak üzere üretken yapay zeka uygulamalarında hata ayıklamaya ve gözlemlemeye yönelik güçlü bir araçtır. Belirli kod parçalarını kapsayan ve giriş, çıkış ile zamanlama verilerini kaydeden spans aracılığıyla ayrıntılı işlem bilgilerini yakalar.
LangChain gibi popüler kitaplıklar için mlflow.langchain.autolog()ile otomatik izlemeyi etkinleştirin. İzlemeyi özelleştirmek için mlflow.start_span()'ı da kullanabilirsiniz. Örneğin, gözlemlenebilirlik için özel veri değeri alanları veya etiketleme ekleyebilirsiniz. Bu yayılma alanı bağlamında çalışan kod, tanımladığınız alanlarla ilişkilendirildi. Bu bellek içi TF-IDF örnekte, ona bir ad ve bir span türü verin.
İzleme hakkında daha fazla bilgi edinmek için bkz. MLflow İzleme - GenAI gözlemlenebilirliği.
Aşağıdaki örnek, basit bir bellek içi TF-IDF dizini kullanarak bir retriever aracı oluşturur. Hem araç yürütmeleri için otomatik kaydetmeyi hem de ilave gözlemlenebilirlik için özel span izlemesini gösterir.
from sklearn.feature_extraction.text import TfidfVectorizer
import mlflow
from langchain_core.tools import tool
documents = parsed_docs_df
doc_vectorizer = TfidfVectorizer(stop_words="english")
tfidf_matrix = doc_vectorizer.fit_transform(documents["content"])
@tool
def find_relevant_documents(query, top_n=5):
"""gets relevant documents for the query"""
with mlflow.start_span(name="LittleIndex", span_type="RETRIEVER") as retriever_span:
retriever_span.set_inputs({"query": query})
retriever_span.set_attributes({"top_n": top_n})
query_tfidf = doc_vectorizer.transform([query])
similarities = (tfidf_matrix @ query_tfidf.T).toarray().flatten()
ranked_docs = sorted(enumerate(similarities), key=lambda x: x[1], reverse=True)
result = []
for idx, score in ranked_docs[:top_n]:
row = documents.iloc[idx]
content = row["content"]
doc_entry = {
"page_content": content,
"metadata": {
"doc_uri": row["doc_uri"],
"score": score,
},
}
result.append(doc_entry)
retriever_span.set_outputs(result)
return result
Bu kod, retriever araçları için özel olarak ayrılmış RETRIEVERözel bir span türü kullanır. Diğer Mozaik AI aracısı özellikleri (AI Playground, gözden geçirme kullanıcı arabirimi ve değerlendirme gibi), alma sonuçlarını görüntülemek için RETRIEVER span türünü kullanır.
Retriever araçları, aşağı akış Databricks özellikleriyle uyumluluğu sağlamak için şemalarını belirtmenizi gerektirir. Daha fazla bilgi için mlflow.models.set_retriever_schema hakkında bkz. Özel retriever şemaları.
import mlflow
from mlflow.models import set_retriever_schema
uc_toolkit = UCFunctionToolkit(function_names=[f"{CATALOG}.{SCHEMA}.*"])
graph = create_tool_calling_agent(llm, tools=[*uc_toolkit.tools, find_relevant_documents])
mlflow.langchain.autolog()
set_retriever_schema(
primary_key="chunk_id",
text_column="chunk_text",
doc_uri="doc_uri",
other_columns=["title"],
)
graph.invoke(input = {"messages": [("user", "How do the docs say I use llm judges on databricks?")]})
Ajanı tanımla
Sonraki adım aracıyı değerlendirmek ve dağıtıma hazırlamaktır. Bu, üst düzeyde aşağıdakileri içerir:
- İmza kullanarak aracı için öngörülebilir bir API tanımlayın.
- Parametreleri yapılandırmayı kolaylaştıran model yapılandırması ekleyin.
- Modeli yeniden üretilebilir bir ortam sağlayan ve kimlik doğrulamasını diğer hizmetlere yapılandırmanıza olanak sağlayan bağımlılıklarla günlüğe kaydedin.
MLflow ChatAgent arabirimi, aracı girişlerini ve çıkışlarını tanımlamayı kolaylaştırır. Bunu kullanmak için aracınızı ChatAgentalt sınıfı olarak tanımlayın; predict işleviyle akış dışı çıkarım ve predict_stream işleviyle akış çıkarımı uygulayın.
ChatAgent, farklı çerçeveleri ve aracı uygulamalarını kolayca test edip kullanmanıza olanak sağlayan aracı yazma çerçevesi seçiminizden bağımsızdır. Tek gereksinim predict ve predict_stream arabirimlerini uygulamaktır.
ChatAgent kullanarak aracınızı yazmak, bir takım avantajlar sağlar, bunlar arasında şunlar vardır:
- Akış çıkışı desteği
- Kapsamlı araç arama ileti geçmişi: Gelişmiş kalite ve konuşma yönetimi için ara araç arama iletileri de dahil olmak üzere birden çok ileti döndürebilirsiniz.
- Çok aracılı sistem desteği
- Databricks özellik entegrasyonu: AI Playground, Aracı Değerlendirmesi ve Aracı İzleme ile kullanıma hazır uyumluluk.
- Yazılan yazma arabirimleri: IDE ve not defteri otomatik tamamlama özelliğinden yararlanarak, yazılan Python sınıflarını kullanarak aracı kodu yazın.
Yazma ChatAgent hakkında daha fazla bilgi için bkz Eski giriş ve çıkış aracısı şeması (Model Sunma).
from mlflow.pyfunc import ChatAgent
from mlflow.types.agent import (
ChatAgentChunk,
ChatAgentMessage,
ChatAgentResponse,
ChatContext,
)
from typing import Any, Optional
class DocsAgent(ChatAgent):
def __init__(self, agent):
self.agent = agent
set_retriever_schema(
primary_key="chunk_id",
text_column="chunk_text",
doc_uri="doc_uri",
other_columns=["title"],
)
def predict(
self,
messages: list[ChatAgentMessage],
context: Optional[ChatContext] = None,
custom_inputs: Optional[dict[str, Any]] = None,
) -> ChatAgentResponse:
# ChatAgent has a built-in helper method to help convert framework-specific messages, like langchain BaseMessage to a python dictionary
request = {"messages": self._convert_messages_to_dict(messages)}
output = agent.invoke(request)
# Here 'output' is already a ChatAgentResponse, but to make the ChatAgent signature explicit for this demonstration, the code returns a new instance
return ChatAgentResponse(**output)
Aşağıdaki kod, ChatAgentnasıl kullanılacağını gösterir.
AGENT = DocsAgent(agent=agent)
AGENT.predict(
{
"messages": [
{"role": "user", "content": "What are Pipelines in Databricks?"},
]
}
)
Aracıları parametrelerle yapılandırma
Agent Framework, aracı yürütmesini parametrelerle denetlemenize olanak tanır. Bu, LLM uç noktalarını değiştirme veya temel kodu değiştirmeden farklı araçları deneme gibi farklı aracı yapılandırmalarını hızlı bir şekilde test edebilirsiniz.
Aşağıdaki kod, modeli başlatırken aracı parametrelerini ayarlayan bir yapılandırma sözlüğü oluşturur.
Aracıları parametreleştirme hakkında daha fazla ayrıntı için bkz. Ortamlar arasında dağıtım için parametrize kodu.
)
from mlflow.models import ModelConfig
baseline_config = {
"endpoint_name": "databricks-meta-llama-3-3-70b-instruct",
"temperature": 0.01,
"max_tokens": 1000,
"system_prompt": """You are a helpful assistant that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
You answer questions using a set of tools. If needed, you ask the user follow-up questions to clarify their request.
""",
"tool_list": ["catalog.schema.*"],
}
class DocsAgent(ChatAgent):
def __init__(self):
self.config = ModelConfig(development_config=baseline_config)
self.agent = self._build_agent_from_config()
def _build_agent_from_config(self):
temperature = config.get("temperature", 0.01)
max_tokens = config.get("max_tokens", 1000)
system_prompt = config.get("system_prompt", """You are a helpful assistant.
You answer questions using a set of tools. If needed you ask the user follow-up questions to clarify their request.""")
llm_endpoint_name = config.get("endpoint_name", "databricks-meta-llama-3-3-70b-instruct")
tool_list = config.get("tool_list", [])
llm = ChatDatabricks(endpoint=llm_endpoint_name, temperature=temperature, max_tokens=max_tokens)
toolkit = UCFunctionToolkit(function_names=tool_list)
agent = create_tool_calling_agent(llm, tools=[*toolkit.tools, find_relevant_documents], prompt=system_prompt)
return agent
Aracıyı günlüğe kaydet
Aracı tanımladıktan sonra artık kaydedilmeye hazırdır. MLflow'da bir aracıyı günlüğe kaydetmek, değerlendirme ve dağıtım için kullanılabilmesi için aracının yapılandırmasını (bağımlılıklar dahil) kaydetme anlamına gelir.
Uyarı
Bir not defterinde aracı geliştirirken, MLflow aracının bağımlılıklarını not defteri ortamından çıkartır.
Bir not defterinden aracıyı günlüğe kaydetmek için, modeli tanımlayan tüm kodu tek bir hücreye yazabilir ve ardından %%writefile sihirli komutunu kullanarak aracının tanımını bir dosyaya kaydedebilirsiniz:
%%writefile agent.py
...
<Code that defines the agent>
Aracı, anahtar sözcük ayıklama aracını yürütmek için Unity Kataloğu gibi dış kaynaklara erişim gerektiriyorsa, aracı dağıtıldığında kaynaklara erişebilmesi için kimlik doğrulamasını yapılandırmanız gerekir.
Databricks kaynaklarının kimlik doğrulamasını basitleştirmek için otomatik kimlik doğrulama geçişetkinleştirin:
from mlflow.models.resources import DatabricksFunction, DatabricksServingEndpoint
resources = [
DatabricksServingEndpoint(endpoint_name=LLM_ENDPOINT_NAME),
DatabricksFunction(function_name=tool.uc_function_name),
]
with mlflow.start_run():
logged_agent_info = mlflow.pyfunc.log_model(
artifact_path="agent",
python_model="agent.py",
pip_requirements=[
"mlflow",
"langchain",
"langgraph",
"databricks-langchain",
"unitycatalog-langchain[databricks]",
"pydantic",
],
resources=resources,
)
Günlükleme ajanları hakkında daha fazla bilgi edinmek için bkz. Kod tabanlı günlük.
Temsilciyi değerlendir
Sonraki adım aracıyı değerlendirerek nasıl performans sergilediğini görmektir. Temsilci Değerlendirmesi zordur ve aşağıdakiler gibi çok sayıda soru gündeme getirir:
- Kaliteyi değerlendirmek için doğru ölçümler nelerdir? Bu ölçümlerin çıkışlarına nasıl güvenebilirim?
- Birçok fikri değerlendirmem gerekiyor - nasıl...
- değerlendirmeyi hızlı yaparak zamanımı bekleyerek harcamamak için mi?
- aracımın bu farklı sürümlerini kalite, maliyet ve gecikme süresi açısından hızla karşılaştırın mı?
- Kalite sorunlarının kök nedenini nasıl hızla belirleyebilirim?
Veri bilimcisi veya geliştirici olarak asıl konu uzmanı olmayabilirsiniz. Bu bölümün geri kalanında iyi bir çıkış tanımlamanıza yardımcı olabilecek Aracı Değerlendirme araçları açıklanmaktadır.
Değerlendirme kümesi oluşturma
Bir aracı için kalitenin ne anlama geldiğini tanımlamak için ölçümleri kullanarak bir değerlendirme kümesindeki aracının performansını ölçersiniz. Bkz. "kalite" tanımlama: Değerlendirme kümeleri.
Aracı Değerlendirmesi ile, değerlendirmeleri çalıştırarak yapay değerlendirme kümeleri oluşturabilir ve kaliteyi ölçebilirsiniz. Fikir, bir dizi belge gibi olgulardan başlamak ve bir dizi soru oluşturmak için bu olguları kullanarak "geriye doğru çalışmak"tır. Bazı yönergeler sağlayarak oluşturulan soruları koşullayabilirsiniz:
from databricks.agents.evals import generate_evals_df
import pandas as pd
databricks_docs_url = "https://raw.githubusercontent.com/databricks/genai-cookbook/refs/heads/main/quick_start_demo/chunked_databricks_docs_filtered.jsonl"
parsed_docs_df = pd.read_json(databricks_docs_url, lines=True)
agent_description = f"""
The agent is a RAG chatbot that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
"""
question_guidelines = f"""
# User personas
- A developer who is new to the Databricks platform
- An experienced, highly technical Data Scientist or Data Engineer
# Example questions
- what API lets me parallelize operations over rows of a delta table?
- Which cluster settings will give me the best performance when using Spark?
# Additional Guidelines
- Questions should be succinct, and human-like
"""
num_evals = 25
evals = generate_evals_df(
docs=parsed_docs_df[
:500
], # Pass your docs. They should be in a Pandas or Spark DataFrame with columns `content STRING` and `doc_uri STRING`.
num_evals=num_evals, # How many synthetic evaluations to generate
agent_description=agent_description,
question_guidelines=question_guidelines,
)
Oluşturulan değerlendirmeler şunları içerir:
Daha önce bahsedilen
ChatAgentRequestgibi görünen bir istek alanı:{"messages":[{"content":"What command must be run at the start of your workload to explicitly target the Workspace Model Registry if your workspace default catalog is in Unity Catalog and you use Databricks Runtime 13.3 LTS or above?","role":"user"}]}"Beklenen alınan içerik" listesi. Retriever şeması
contentvedoc_urialanlarıyla tanımlanmıştır.[{"content":"If your workspace's [default catalog](https://docs.databricks.com/data-governance/unity-catalog/create-catalogs.html#view-the-current-default-catalog) is in Unity Catalog (rather than `hive_metastore`) and you are running a cluster using Databricks Runtime 13.3 LTS or above, models are automatically created in and loaded from the workspace default catalog, with no configuration required. To use the Workspace Model Registry in this case, you must explicitly target it by running `import mlflow; mlflow.set_registry_uri(\"databricks\")` at the start of your workload.","doc_uri":"https://docs.databricks.com/machine-learning/manage-model-lifecycle/workspace-model-registry.html"}]Beklenen olguların listesi. İki yanıtı karşılaştırdığınızda, aralarında küçük farklar bulmak zor olabilir. Beklenen gerçekler, doğru yanıtı kısmen doğru yanıttan ve yanlış yanıttan ayırt etmeye yarar ve hem yapay zeka hakimlerinin kalitesini hem de aracı üzerinde çalışan kişilerin deneyimini geliştirir.
["The command must import the MLflow module.","The command must set the registry URI to \"databricks\"."]Burada
SYNTHETIC_FROM_DOColan bir source_id alanı. Siz daha eksiksiz değerlendirme kümeleri derledikçe örnekler farklı kaynaklardan gelir ve bu nedenle bu alan bunları ayırt eder.
Değerlendirme kümeleri oluşturma hakkında daha fazla bilgi edinmek için bkz. değerlendirme kümelerini sentezleyin.
LLM yargıçlarını kullanarak aracıyı değerlendirme
Oluşturulan birçok örnekte aracının performansını el ile değerlendirmek iyi ölçeklendirilmiyor. Büyük ölçekte, LLM'leri yargıç olarak kullanmak çok daha makul bir çözümdür. Aracı Değerlendirmesi kullanılırken kullanılabilen yerleşik yargıçları kullanmak için aşağıdaki kodu kullanın:
with mlflow.start_run(run_name="my_agent"):
eval_results = mlflow.evaluate(
data=evals, # Your evaluation set
model=model_info.model_uri, # Logged agent from above
model_type="databricks-agent", # activate Mosaic AI Agent Evaluation
)
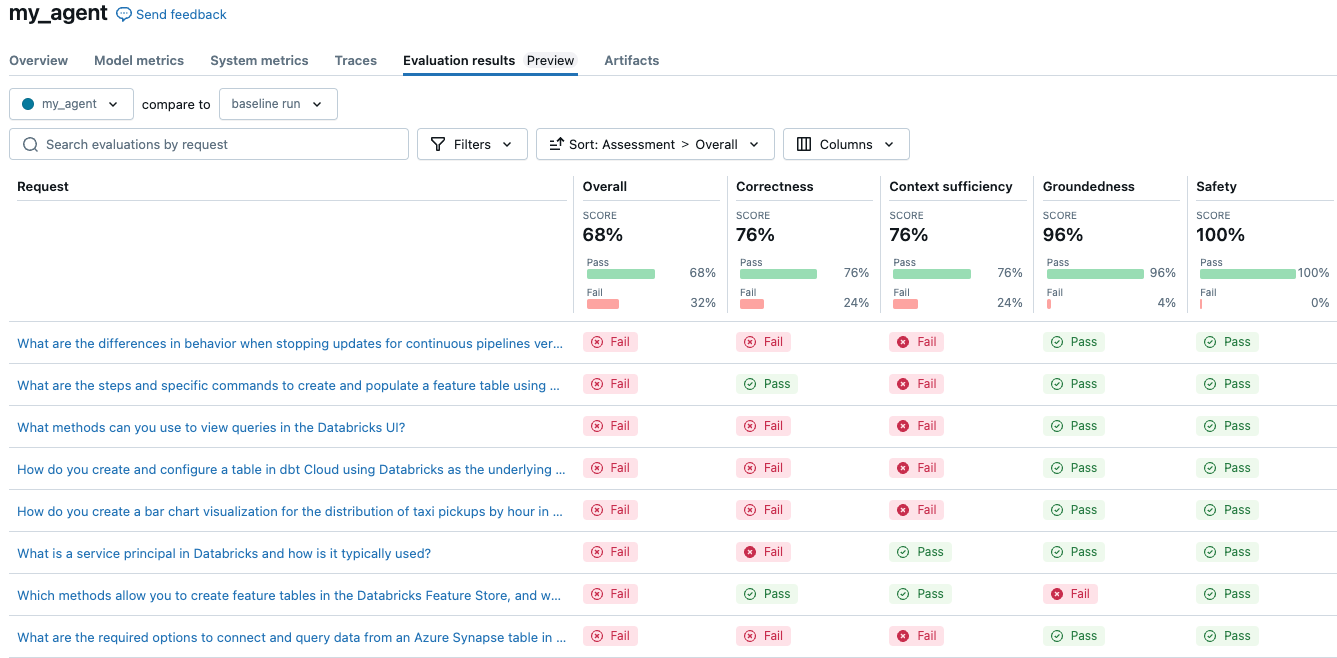
Basit ajan, genel olarak 68% puan aldı. Kullandığınız yapılandırmaya bağlı olarak sonuçlarınız burada farklılık gösterebilir. Maliyet ve kalite açısından üç farklı LLM'yi karşılaştırmak için bir deneme çalıştırmak, yapılandırmayı değiştirmek ve yeniden değerlendirmek kadar kolaydır.
Model yapılandırmasını farklı bir LLM, sistem istemi veya sıcaklık ayarı kullanacak şekilde değiştirmeyi göz önünde bulundurun.
Bu hakimler, insan uzmanların bir yanıtı değerlendirmek için kullanacağı yönergeleri izleyecek şekilde özelleştirilebilir. LLM hakimleri hakkında daha fazla bilgi için bkz. Yerleşik yapay zeka hakimleri (MLflow 2).
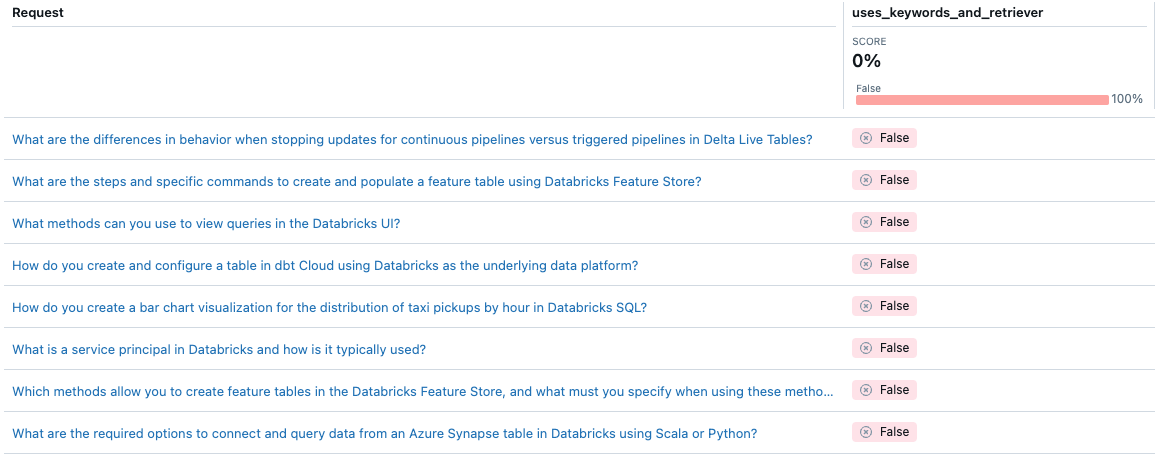
Aracı Değerlendirmesi ile, özel ölçümlerkullanarak belirli bir aracının kalitesini ölçme yönteminizi özelleştirebilirsiniz. Değerlendirmeyi tümleştirme testi ve tek tek ölçümleri birim testleri olarak düşünebilirsiniz. Aşağıdaki örnek, bir ajanın belirli bir istek için hem anahtar sözcük ayıklamayı hem de alma aracını kullanıp kullanmadığını denetlemek için Boolean ölçümü kullanır.
from databricks.agents.evals import metric
@metric
def uses_keywords_and_retriever(request, trace):
retriever_spans = trace.search_spans(span_type="RETRIEVER")
keyword_tool_spans = trace.search_spans(name=f"{CATALOG}__{SCHEMA}__tfidf_keywords")
return len(keyword_tool_spans) > 0 and len(retriever_spans) > 0
# same evaluate as above, with the addition of 'extra_metrics'
with mlflow.start_run(run_name="my_agent"):
eval_results = mlflow.evaluate(
data=evals, # Your evaluation set
model=model_info.model_uri, # Logged agent from above
model_type="databricks-agent", # activate Mosaic AI Agent Evaluation,
extra_metrics=[uses_keywords_and_retriever],
)
Aracın hiçbir zaman anahtar sözcük ayıklama kullanmadığını unutmayın. Bu sorunu nasıl düzeltebilirsiniz?
Ajanı kur ve izle
Aracınızı gerçek kullanıcılarla test etmeye hazır olduğunuzda, Agent Framework aracıya Mozaik Yapay Zeka Modeli Sunma konusunda hizmet vermek için üretime hazır bir çözüm sağlar.
Aracıları Model Sunma'ya dağıtmak aşağıdaki avantajları sağlar:
- Model Sunma, otomatik ölçeklendirmeyi, günlüğe kaydetmeyi, sürüm denetimini ve erişim denetimini yöneterek kalite aracıları geliştirmeye odaklanmanızı sağlar.
- Konu uzmanları, aracıyla etkileşimde bulunmak ve izleme ve değerlendirmelerinize dahil edilebilecek geri bildirim sağlamak için Gözden Geçirme Uygulamasını kullanabilir.
- Canlı trafik üzerinde değerlendirmeler çalıştırarak ajanı izleyebilirsiniz. Kullanıcı trafiği temel gerçeği içermese de, LLM yargıçları (ve oluşturduğunuz özel ölçüm) denetimsiz bir değerlendirme gerçekleştirir.
Aşağıdaki kod temsilcileri bir servis uç noktasına dağıtır. Daha fazla bilgi için bkz. Oluşturucu yapay zeka uygulamaları (Model Sunma) için aracı dağıtma.
from databricks import agents
import mlflow
# Connect to the Unity Catalog model registry
mlflow.set_registry_uri("databricks-uc")
# Configure UC model location
UC_MODEL_NAME = f"{CATALOG}.{SCHEMA}.getting_started_agent"
# REPLACE WITH UC CATALOG/SCHEMA THAT YOU HAVE `CREATE MODEL` permissions in
# Register to Unity Catalog
uc_registered_model_info = mlflow.register_model(
model_uri=model_info.model_uri, name=UC_MODEL_NAME
)
# Deploy to enable the review app and create an API endpoint
deployment_info = agents.deploy(
model_name=UC_MODEL_NAME, model_version=uc_registered_model_info.version
)