Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Veri düzenleme ve Otomatik Yükleyici için Lakeflow işlem hatlarını kullanarak değişiklik veri yakalama (CDC) ile bir ETL (ayıklama, dönüştürme ve yükleme) işlem hattı oluşturup dağıtırsınız. ETL işlem hattı, kaynak sistemlerden verileri okuma, veri kalitesi denetimleri ve yinelenenleri kaldırma gibi gereksinimlere göre bu verileri dönüştürme ve verileri veri ambarı veya veri gölü gibi bir hedef sisteme yazma adımlarını uygular.
Bu öğreticide, MySQL veritabanındaki bir customers tablodaki verileri kullanarak şunları yapacaksınız:
- Debezium veya başka bir araç kullanarak işlem veritabanındaki değişiklikleri ayıklayın ve bunları bulut nesne depolamasına (S3, ADLS veya GCS) kaydedin. Bu öğreticide, bir dış CDC sistemi ayarlamayı atlar ve bunun yerine öğreticiyi basitleştirmek için sahte veriler oluşturursunuz.
- Bulut nesne depolamasından iletileri artımlı olarak yüklemek ve ham iletileri tabloda depolamak için Otomatik Yükleyici'yi
customers_cdckullanın. Otomatik Yükleyici şemayı çıkarsar ve şema evrimini işler. -
customers_cdc_cleanBeklentileri kullanarak veri kalitesini denetlemek için tabloyu oluşturun. Örneğin,id, upsert işlemlerini çalıştırmak için kullanıldığından, aslanullolmamalıdır. - Son tabloya değişiklikleri eklemek için temizlenen CDC verilerinde gerçekleştirin
AUTO CDC ... INTOcustomers. - İşlem hattının tüm değişiklikleri izlemek için nasıl tür 2 yavaş değişen boyut (SCD2) tablosu oluşturabileceğini gösterin.
Hedef, ham verileri neredeyse gerçek zamanlı olarak almak ve analist ekibiniz için bir tablo oluştururken veri kalitesini sağlamaktır.
Öğretici, bronz katman aracılığıyla ham verileri alıp veri girişini yaptığı, gümüş katmanla verileri temizleyip doğruladığı ve altın katmanı kullanarak boyutsal modelleme ve verinin toplamasını gerçekleştirdiği Medallion Lakehouse mimarisini kullanmaktadır. Daha fazla bilgi için bkz. Madalyon göl evi mimarisi nedir?
Uygulanan akış şöyle görünür:
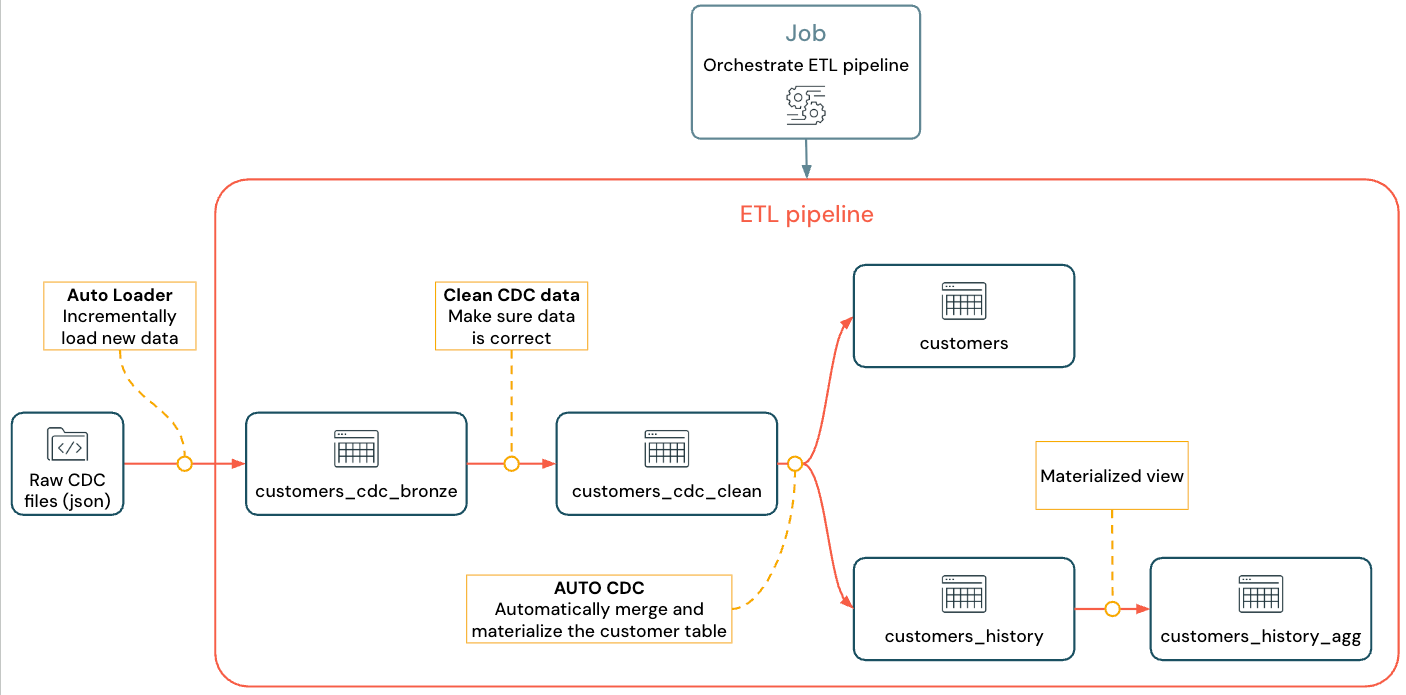
İşlem hattı, Otomatik Yükleyici ve CDC hakkında daha fazla bilgi için bkz. Spark Bildirimli İşlem Hatları, Otomatik Yükleyici nedir? ve Veri yakalama ve anlık görüntüleri değiştirme
Gereksinimler
Bu öğreticiyi tamamlamak için aşağıdaki gereksinimleri karşılamanız gerekir:
- Unity Kataloğu çalışma alanınız için etkinleştirildi.
- Sunucusuz işlem çalışma alanınızda kullanılabilir (Unity Kataloğu ile çalışma alanlarında varsayılan olarak etkindir). Sunucusuz Lakeflow işlem hatları tüm çalışma alanı bölgelerinde kullanılamaz. Bkz. Kullanılabilir bölgeler için sınırlı bölgesel kullanılabilirliğe sahip özellikler . Sunucusuz işlem kullanılamıyorsa, adımlar çalışma alanınız için varsayılan işlemle çalışmalıdır.
- İşlem kaynağı oluşturma veya işlem kaynağınaerişim izni.
-
Katalogda yeni şema oluşturma izinleri. Gerekli izinler
USE CATALOGveCREATE SCHEMA'dir. -
Mevcut şemada yeni birim oluşturma izinleri. Gerekli izinler
USE SCHEMAveCREATE VOLUME'dir. - İşlem hatlarını ve bunların çıkışını oluşturmak, çalıştırmak, yenilemek ve görüntülemek için gereken tüm ayrıcalıklar için bkz. İşlem hatları için kimlikleri, izinleri ve ayrıcalıkları yönetme.
ETL işlem hattında veri yakalamayı değiştirme
Değişiklik veri yakalama (CDC), işlem veritabanında (örneğin, MySQL veya PostgreSQL) veya bir veri ambarında yapılan kayıtlardaki değişiklikleri yakalayan işlemdir. CDC, veri silme, ekleme ve güncelleştirme gibi işlemleri genellikle dış sistemlerdeki tabloları yeniden gerçekleştirmek için bir akış olarak yakalar. CDC, toplu yükleme güncelleştirmeleri gereksinimini ortadan kaldırırken artımlı yüklemeyi etkinleştirir.
Uyarı
Bu öğreticiyi daha basit hale getirmek için dış CDC sistem kurulumu aşamasını atlayın. CDC verilerini bulut nesne depolama alanında (S3, ADLS veya GCS) JSON dosyaları olarak çalıştırdığını ve kaydettiğinizi varsayalım. Bu öğretici, öğretici boyunca kullanılan verileri oluşturmak için Faker kitaplığını kullanır.
CDC'yi yakalama
Çeşitli CDC araçları mevcuttur. Önde gelen açık kaynak çözümlerinden biri Debezium'dır ancak Fivetran, Qlik Replicate, StreamSets, Talend, Oracle GoldenGate ve AWS DMS gibi veri kaynaklarını basitleştiren başka uygulamalar da mevcuttur.
Bu öğreticide, Debezium veya DMS gibi bir dış sistemdeki CDC verilerini kullanacaksınız. Debezium değişen her satırı yakalar. Genellikle veri değişikliklerinin geçmişini Kafka konularına gönderir veya dosya olarak kaydeder.
CDC bilgilerini customers tablodan (JSON biçimi) içeri aktarmalı, doğruluğunu kontrol etmeli ve ardından Lakehouse'da müşteriler tablosunu oluşturmalısınız.
Debezium'dan CDC girişi
Her değişiklik için güncelleştirilmekte olan satırın tüm alanlarını (id, firstname, , lastname, emailaddress) içeren bir JSON iletisi alırsınız. İleti ayrıca ek meta veriler içerir:
-
operation: Genellikle (DELETE,APPEND,UPDATE) bir işlem kodu. -
operation_date: Her işlem eylemi için kaydın tarih ve zaman damgası.
Debezium gibi araçlar, değişiklik öncesi satır değeri gibi daha gelişmiş çıkışlar üretebilir, ancak bu öğreticide kolaylık olması için bunlar atlanabilir.
1. Adım: İşlem hattı oluşturma
CDC veri kaynağınızı sorgulamak ve çalışma alanınızda tablolar oluşturmak için yeni bir ETL işlem hattı oluşturun.
Çalışma alanınızda
 Kenar çubuğunda yeni, ardından ETL İşlem Hattı'nı seçin. Bu,
Kenar çubuğunda yeni, ardından ETL İşlem Hattı'nı seçin. Bu, New Pipeline <date> <time>gibi varsayılan bir işlem hattı adıyla işlem hattı düzenleyicisini açar.Adı seçin ve gibi
Pipelines with CDC tutorialaçıklayıcı bir ad girin.Adın sağındaki kataloğa ve şemaya tıklayarak yazma izinlerine sahip olduğunuz varsayılan değerleri seçin.
Kodunuzda bir katalog veya şema belirtmezseniz, bu katalog ve şema varsayılan olarak kullanılır. Kodunuz, tam yolu belirterek herhangi bir kataloğa veya şemaya yazabilir. Bu öğreticide burada belirttiğiniz varsayılan değerler kullanılır.
(İsteğe bağlı) Sizin için oluşturulan
my_transformationkaynak dosyasında, dil açılan listesinden Python veya SQL seçin. Örnek kodu kullanın.
Örnek kodu kullanın.
Lakeflow Pipelines Düzenleyicisi, işlem hattınızda örnek dosyalar ile birlikte açılır. Sonraki adımlarda kendi dönüştürme dosyalarınızı ekleyebilirsiniz. Ardından, öğreticide içeri aktaracak örnek verileri ayarlayın.
2. Adım: Bu öğreticide içeri aktaracak örnek verileri oluşturma
Mevcut bir kaynaktan kendi verilerinizi içeri aktarıyorsanız bu adım gerekli değildir. Bu öğreticide, öğreticiye bir örnek olarak sahte veriler oluşturun. Python veri oluşturma betiğini çalıştırmak için bir not defteri oluşturun. Örnek verileri oluşturmak için bu kodun yalnızca bir kez çalıştırılması gerekir, bu nedenle işlem hattı güncelleştirmesinin bir parçası olarak çalıştırılmayan işlem hattının explorations klasöründe oluşturun.
Uyarı
Bu kod, örnek CDC verilerini oluşturmak için Faker kullanır. Faker otomatik olarak yüklenebilir, bu yüzden öğretici %pip install faker kullanır. Not defteri için faker'a bağımlılık da ayarlayabilirsiniz. Bkz. Not defterine bağımlılık ekleme.
Lakeflow Pipelines Düzenleyicisi'nin içinden, düzenleyicinin solundaki varlık tarayıcısı kenar çubuğunda
Ekle'yi ve ardından Keşif'i seçin.gibi bir
Setup dataverin, Python öğesini seçin. Yeniexplorationsbir klasör olan varsayılan hedef klasörü bırakabilirsiniz.Oluştur'utıklayın. Bu, yeni klasörde bir not defteri oluşturur.
İlk hücreye aşağıdaki kodu girin. Önceki adımda seçtiğiniz varsayılan katalog ve şemayla eşleşmesi için
<my_catalog>ve<my_schema>tanımlarını değiştirmelisiniz:%pip install faker # Update these to match the catalog and schema # that you used for the pipeline in step 1. catalog = "<my_catalog>" schema = dbName = db = "<my_schema>" spark.sql(f'USE CATALOG `{catalog}`') spark.sql(f'USE SCHEMA `{schema}`') spark.sql(f'CREATE VOLUME IF NOT EXISTS `{catalog}`.`{db}`.`raw_data`') volume_folder = f"/Volumes/{catalog}/{db}/raw_data" try: dbutils.fs.ls(volume_folder+"/customers") except: print(f"folder doesn't exist, generating the data under {volume_folder}...") from pyspark.sql import functions as F from faker import Faker from collections import OrderedDict import uuid fake = Faker() import random fake_firstname = F.udf(fake.first_name) fake_lastname = F.udf(fake.last_name) fake_email = F.udf(fake.ascii_company_email) fake_date = F.udf(lambda:fake.date_time_this_month().strftime("%m-%d-%Y %H:%M:%S")) fake_address = F.udf(fake.address) operations = OrderedDict([("APPEND", 0.5),("DELETE", 0.1),("UPDATE", 0.3),(None, 0.01)]) fake_operation = F.udf(lambda:fake.random_elements(elements=operations, length=1)[0]) fake_id = F.udf(lambda: str(uuid.uuid4()) if random.uniform(0, 1) < 0.98 else None) df = spark.range(0, 100000).repartition(100) df = df.withColumn("id", fake_id()) df = df.withColumn("firstname", fake_firstname()) df = df.withColumn("lastname", fake_lastname()) df = df.withColumn("email", fake_email()) df = df.withColumn("address", fake_address()) df = df.withColumn("operation", fake_operation()) df_customers = df.withColumn("operation_date", fake_date()) df_customers.repartition(100).write.format("json").mode("overwrite").save(volume_folder+"/customers")Öğreticide kullanılan veri kümesini oluşturmak için Shift + Enter yazın ve kodu çalıştırın:
Optional. Bu öğreticide kullanılan verilerin önizlemesini görüntülemek için sonraki hücreye aşağıdaki kodu girin ve kodu çalıştırın. Kataloğu ve şemayı önceki koddaki yolla eşleşecek şekilde güncelleştirin.
# Update these to match the catalog and schema # that you used for the pipeline in step 1. catalog = "<my_catalog>" schema = "<my_schema>" display(spark.read.json(f"/Volumes/{catalog}/{schema}/raw_data/customers"))
Bu, öğreticinin geri kalan kısmında kullanabileceğiniz büyük bir veri kümesi oluşturur (sahte CDC verileriyle). Sonraki adımda Otomatik Yükleyici'yi kullanarak verileri alın.
3. Adım: Otomatik Yükleyici ile verileri artımlı olarak alma
Bir sonraki adım ham verileri (sahte) bulut depolama alanından bronz bir katmana almaktır.
Bu, birden çok nedenden dolayı zor olabilir, örneğin:
- Büyük ölçekte çalışın ve milyonlarca küçük dosyayı alma potansiyeline sahip olun.
- Şemayı ve JSON türünü belirle.
- Hatalı kayıtları yanlış JSON şemasıyla işleme.
- Şema evrimini (örneğin, müşteri tablosundaki yeni bir sütun) halledin.
Auto Loader, şema çıkarımı ve şema evrimini içeren bu alımı basitleştirir ve milyonlarca gelen dosyaya ölçeklenir. Otomatik Yükleyici, cloudFiles kullanılarak Python ve SELECT * FROM STREAM read_files(...) kullanılarak SQL'de kullanılabilir ve çeşitli biçimlerle (JSON, CSV, Apache Avro vb.) kullanılabilir:
Tabloyu akış tablosu olarak tanımlamak, yalnızca yeni gelen verileri kullanmanıza garanti eder. Akış tablosu olarak tanımlamazsanız, tüm kullanılabilir verileri tarar ve alır. Daha fazla bilgi için bkz . Akış tabloları .
Otomatik Yükleyici'yi kullanarak gelen CDC verilerini almak için aşağıdaki kodu kopyalayıp işlem hattınızla oluşturulan kod dosyasına yapıştırın (veya
my_transformation.pyolarak adlandırılırmy_transformation.sql). İşlem hattını oluştururken seçtiğiniz dile bağlı olarak Python veya SQL kullanabilirsiniz.<catalog>ve<schema>öğelerini, işlem hattı için varsayılan olarak ayarladığınız değerlerle değiştirdiğinizden emin olun.Python
from pyspark import pipelines as dp from pyspark.sql.functions import * # Replace with the catalog and schema name that # you are using: path = "/Volumes/<catalog>/<schema>/raw_data/customers" # Create the target bronze table dp.create_streaming_table("customers_cdc_bronze", comment="New customer data incrementally ingested from cloud object storage landing zone") # Create an Append Flow to ingest the raw data into the bronze table @dp.append_flow( target = "customers_cdc_bronze", name = "customers_bronze_ingest_flow" ) def customers_bronze_ingest_flow(): return ( spark.readStream .format("cloudFiles") .option("cloudFiles.format", "json") .option("cloudFiles.inferColumnTypes", "true") .load(f"{path}") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_bronze COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_bronze_ingest_flow AS INSERT INTO customers_cdc_bronze BY NAME SELECT * FROM STREAM read_files( -- replace with the catalog/schema you are using: "/Volumes/<catalog>/<schema>/raw_data/customers", format => "json", inferColumnTypes => "true" ) Bağlı işlem hattı için bir güncelleştirme başlatmak için dosyayı çalıştırın veya işlem hattını çalıştırın. İşlem hattınızda yalnızca bir kaynak dosyası varsa bunlar işlevsel olarak eşdeğerdir.
Bağlı işlem hattı için bir güncelleştirme başlatmak için dosyayı çalıştırın veya işlem hattını çalıştırın. İşlem hattınızda yalnızca bir kaynak dosyası varsa bunlar işlevsel olarak eşdeğerdir.
Güncelleştirme tamamlandığında, düzenleyicideki veriler işlem hattınız hakkında bilgilerle güncellenir.
- Kodunuzun sağ kenar çubuğunda bulunan, yönlendirilmiş döngüsüz grafik (DAG) olarak da adlandırılan işlem hattı grafiği,
customers_cdc_bronzetek bir tabloyu gösterir. - İşlem hattı varlık tarayıcısının üst kısmında güncellemenin özeti görüntülenir.
- Oluşturulan tablonun ayrıntıları alt bölmede gösterilir ve tabloyu seçerek tablodaki verilere göz atabilirsiniz.
Bu, bulut depolama alanından içeri aktarılan ham bronz katman verileridir. Sonraki adımda, gümüş katmanlı bir tablo oluşturmak için verileri temizleyin.
4. Adım: Veri kalitesini izlemeye yönelik temizleme ve beklentiler
Bronz katman tanımlandıktan sonra, veri kalitesini kontrol etmek için beklentiler ekleyerek gümüş katmanı oluşturun. Aşağıdaki koşulları denetleyin:
- ID hiçbir zaman
nullolamaz. - CDC işlem türü geçerli olmalıdır.
- JSON, Otomatik Yükleyici tarafından doğru okunmalıdır.
Bu koşullara uymayan satırlar çıkarılır.
Daha fazla bilgi için bkz. İşlem hattı beklentileriyle veri kalitesini yönetme .
İşlem hattı varlık tarayıcısı kenar çubuğunda
Ekle'yi ve ardından Dönüştürme'yi seçin.Name (örneğin,
customers_silver) girin ve kaynak kod dosyası için bir dil (Python veya SQL) seçin..pyveya.sqluzantısı, dil seçiminize göre eklenir. İşlem hattı içindeki dilleri karıştırabilir ve eşleştirebilirsiniz, böylece bu adım için birini seçebilirsiniz.Temizlenmiş bir tabloyla gümüş katman oluşturmak ve kısıtlamalar getirmek için aşağıdaki kodu kopyalayıp yeni dosyaya yapıştırın (dosyanın diline göre Python veya SQL'i seçin).
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * dp.create_streaming_table( name = "customers_cdc_clean", expect_all_or_drop = {"no_rescued_data": "_rescued_data IS NULL","valid_id": "id IS NOT NULL","valid_operation": "operation IN ('APPEND', 'DELETE', 'UPDATE')"} ) @dp.append_flow( target = "customers_cdc_clean", name = "customers_cdc_clean_flow" ) def customers_cdc_clean_flow(): return ( spark.readStream.table("customers_cdc_bronze") .select("address", "email", "id", "firstname", "lastname", "operation", "operation_date", "_rescued_data") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_clean ( CONSTRAINT no_rescued_data EXPECT (_rescued_data IS NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_id EXPECT (id IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_operation EXPECT (operation IN ('APPEND', 'DELETE', 'UPDATE')) ON VIOLATION DROP ROW ) COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_cdc_clean_flow AS INSERT INTO customers_cdc_clean BY NAME SELECT * FROM STREAM customers_cdc_bronze;-
Bağlı işlem hattı için bir güncelleştirme başlatmak için dosyayı çalıştırın veya işlem hattını çalıştırın.
Artık iki kaynak dosya olduğundan, bunlar aynı şeyi yapmaz, ancak bu durumda çıkış aynıdır.
- İşlem hattını çalıştırma , 3. adımdaki kod da dahil olmak üzere tüm işlem hattınızı çalıştırır. Giriş verileriniz güncelleştiriliyorsa bu, bu kaynaktan bronz katmanınıza yapılan tüm değişiklikleri çeker. Veri kurulum adımındaki kod, keşifler klasöründe olduğu ve işlem hattınızın kaynağının bir parçası olmadığı için çalıştırılmaz.
- Çalıştırma dosyası yalnızca geçerli kaynak dosyayı çalıştırır. Bu durumda, giriş verileriniz güncelleştirilmeden, önbelleğe alınmış bronz tablodan gümüş verileri oluşturur. İşlem hattı kodunuzu oluştururken veya düzenlerken daha hızlı yineleme için yalnızca bu dosyayı çalıştırmak yararlı olabilir.
Güncelleştirme tamamlandığında, bronz katmana bağlı olan gümüş katmanla birlikte iki tablonun işlem hattı grafiğinde gösterildiğini ve alt panelde her iki tablonun ayrıntılarının yer aldığını görebilirsiniz. İşlem hattı varlık tarayıcısının üst kısmında artık birden çok çalıştırmanın zamanı gösterilir, ancak yalnızca en son çalıştırmanın ayrıntıları gösterilir.
Ardından, tablonun son altın katman sürümünü customers oluşturun.
5. Adım: AUTO CDC akışı ile müşteriler tablosunu oluşturma
Bu noktaya kadar, tablolar her adımda CDC verilerini aktarmaktaydı. Şimdi, hem en güncel görünümü içerecek hem de orijinal tablonun bir kopyası olacak, onu oluşturan CDC işlemlerinin listesi olmayan customers tablosunu oluşturun.
Bunu elle uygulamak zor bir iştir. En son satırı tutmak için yinelenen verileri kaldırma gibi şeyleri dikkate almanız gerekir.
Ancak işlem hatları bu zorlukları işlemle AUTO CDC çözer.
İşlem hattı varlık tarayıcısının kenar çubuğunda
Ardından Ekle ve Dönüştürme öğelerine tıklayın.bir Name girin ve yeni kaynak kod dosyası için bir dil (Python veya SQL) seçin. Bu adım için iki dilden birini yeniden seçebilirsiniz, ancak aşağıdaki doğru kodu kullanın.
kullanarak
AUTO CDCCDC verilerini işlemek için aşağıdaki kodu kopyalayıp yeni dosyaya yapıştırın.Python
from pyspark import pipelines as dp from pyspark.sql.functions import * dp.create_streaming_table(name="customers", comment="Clean, materialized customers") dp.create_auto_cdc_flow( target="customers", # The customer table being materialized source="customers_cdc_clean", # the incoming CDC keys=["id"], # what we'll be using to match the rows to upsert sequence_by=col("operation_date"), # de-duplicate by operation date, getting the most recent value ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), # DELETE condition except_column_list=["operation", "operation_date", "_rescued_data"], )SQL
CREATE OR REFRESH STREAMING TABLE customers; CREATE FLOW customers_cdc_flow AS AUTO CDC INTO customers FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 1;-
Bağlı işlem hattı için bir güncelleştirme başlatmak için dosyayı çalıştırın.
Güncelleştirme tamamlandığında, işlem hattı grafiğinde bronzdan gümüşe ve sonra altına doğru ilerleyen 3 tablo olduğunu görebilirsiniz.
Adım 6: Yavaş değişen boyut türü 2 (SCD2) ile güncelleştirme geçmişini izleme
Genellikle, APPEND, UPDATE ve DELETE kaynaklarından kaynaklanan tüm değişiklikleri izleyen bir tablo oluşturmak gerekir.
- Geçmiş: Tablonuzda yapılan tüm değişikliklerin geçmişini tutmak istiyorsunuz.
- İzlenebilirlik: Hangi işlemin gerçekleştiğini görmek istiyorsunuz.
Lakeflow işlem hatları ile SCD2
Delta, değişiklik veri akışını (CDF) destekler ve table_change SQL ve Python tablo değişikliklerini sorgulayabilir. Ancak CDF'nin ana kullanım örneği, tablo değişikliklerinin baştan tam görünümünü oluşturmak yerine işlem hattındaki değişiklikleri yakalamaktır.
Sıra dışı olaylarınız varsa bazı şeyleri uygulamak özellikle karmaşık olur. Değişikliklerinizi bir zaman damgasına göre sıralamanız ve geçmişte gerçekleşen bir değişikliği almanız gerekiyorsa, SCD tablonuza yeni bir girdi eklemeniz ve önceki girişleri güncelleştirmeniz gerekir.
Lakeflow işlem hatları bu karmaşıklığı ortadan kaldırır. Başlangıçtan itibaren yapılan tüm değişiklikleri içeren ve işlem hattı tarafından otomatik olarak sürdürülen ayrı bir tablo oluşturabilirsiniz. Bu tablo, akışkan kümeleme gibi veri düzeni iyileştirmelerini destekler ve _sequence_by temel alarak sırasız kayıtları otomatik olarak işler. Bkz Tablolar için sıvı kümeleme kullanma.
SCD2 tablosu oluşturmak için SQL'de STORED AS SCD TYPE 2 veya Python'da stored_as_scd_type="2" seçeneğini kullanın.
Uyarı
Ayrıca şu seçeneği kullanarak özelliğin hangi sütunları izlediğini sınırlayabilirsiniz: TRACK HISTORY ON {columnList | EXCEPT(exceptColumnList)}
İşlem hattı varlık tarayıcısının kenar çubuğunda
Ardından Ekle ve Dönüştürme öğelerine tıklayın.bir Name girin ve yeni kaynak kod dosyası için bir dil (Python veya SQL) seçin.
Aşağıdaki kodu kopyalayıp yeni dosyaya yapıştırın.
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * # create the table dp.create_streaming_table( name="customers_history", comment="Slowly Changing Dimension Type 2 for customers" ) # store all changes as SCD2 dp.create_auto_cdc_flow( target="customers_history", source="customers_cdc_clean", keys=["id"], sequence_by=col("operation_date"), ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), except_column_list=["operation", "operation_date", "_rescued_data"], stored_as_scd_type="2", ) # Enable SCD2 and store individual updatesSQL
CREATE OR REFRESH STREAMING TABLE customers_history; CREATE FLOW customers_history_cdc AS AUTO CDC INTO customers_history FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 2;-
Bağlı işlem hattı için bir güncelleştirme başlatmak için dosyayı çalıştırın.
Güncelleştirme tamamlandığında işlem hattı grafiği, gümüş katman tablosuna da bağımlı olan yeni customers_history tabloyu içerir ve alt panelde 4 tablonun da ayrıntıları gösterilir.
7. Adım: Bilgilerini en çok kimin değiştirdiğini izleyen gerçekleştirilmiş bir görünüm oluşturma
Tablo customers_history , kullanıcının bilgilerinde yaptığı tüm geçmiş değişiklikleri içerir. Altın katmanda bilgilerini en çok değiştiren kişileri takip eden basit bir soyut görünüm oluşturun. Bu, gerçek dünya senaryosunda sahtekarlık algılama analizi veya kullanıcı önerileri için kullanılabilir. Ayrıca, SCD2 ile yapılan değişikliklerin uygulanması yinelenenleri zaten kaldırmıştır, böylece satırları kullanıcı kimliği başına doğrudan sayabilirsiniz.
İşlem hattı varlık tarayıcısının kenar çubuğunda
Ardından Ekle ve Dönüştürme öğelerine tıklayın.bir Name girin ve yeni kaynak kod dosyası için bir dil (Python veya SQL) seçin.
Aşağıdaki kodu kopyalayıp yeni kaynak dosyaya yapıştırın.
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * @dp.table( name = "customers_history_agg", comment = "Aggregated customer history" ) def customers_history_agg(): return ( spark.read.table("customers_history") .groupBy("id") .agg( count_distinct("address").alias("address_count"), count_distinct("email").alias("email_count"), count_distinct("firstname").alias("firstname_count"), count_distinct("lastname").alias("lastname_count") ) )SQL
CREATE OR REPLACE MATERIALIZED VIEW customers_history_agg AS SELECT id, count(distinct address) as address_count, count(distinct email) AS email_count, count(distinct firstname) AS firstname_count, count(distinct lastname) AS lastname_count FROM customers_history GROUP BY id-
Bağlı işlem hattı için bir güncelleştirme başlatmak için dosyayı çalıştırın.
Güncelleştirme tamamlandıktan sonra, işlem hattı grafiğinde customers_history tablosuna bağlı yeni bir tablo bulunmaktadır ve bunu alt panelde görüntüleyebilirsiniz. Veri hattınız tamamlandı. Tam bir işlem hattı çalıştırarak bunu test edebilirsiniz. Geriye kalan tek adım, işlem hattını düzenli olarak güncelleştirilecek şekilde zamanlamaktır.
8. Adım: ETL işlem hattını çalıştırmak için iş oluşturma
Ardından, databricks işini kullanarak işlem hattınızdaki veri alımı, işleme ve analiz adımlarını otomatikleştirmek için bir iş akışı oluşturun.
- Düzenleyicinin üst kısmında Zamanla düğmesini seçin.
- Zamanlamalar iletişim kutusu görüntülenirse Zamanlama ekle'yi seçin.
- Bu, Yeni zamanlama iletişim kutusunu açar, burada işlem hattınızı belirli bir zaman çizelgesine göre çalıştırmak için bir iş oluşturabilirsiniz.
- İsteğe bağlı olarak, işe bir ad verin.
- Varsayılan olarak, zamanlama günde bir kez çalışacak şekilde ayarlanır. Bu varsayılanı kabul edebilir veya kendi zamanlamanızı ayarlayabilirsiniz. Gelişmiş'i seçtiğinizde işin çalıştırılacağı belirli bir zamanı ayarlayabilirsiniz. Diğer seçenekler'i seçtiğinizde iş çalıştırıldığında bildirim oluşturabilirsiniz.
- Değişiklikleri uygulamak ve işi oluşturmak için Oluştur'u seçin.
Artık iş, işlem hattınızı güncel tutmak için günlük olarak çalışır. Zamanlama listesini görüntülemek için Yeniden Zamanla'yı seçebilirsiniz. İşlem hattınız için takvimleri ekleme, düzenleme veya kaldırma gibi zamanlamaları bu iletişim kutusundan yönetebilirsiniz.
Zamanlamanın (veya işin) adına tıklanması, sizi İşler ve işlem hatları listesindeki işin sayfasına götürür. Buradan çalıştırmaların geçmişi de dahil olmak üzere iş çalıştırmalarıyla ilgili ayrıntıları görüntüleyebilir veya şimdi çalıştır düğmesiyle işi hemen çalıştırabilirsiniz.
İş çalıştırmaları hakkında daha fazla bilgi için bkz. Lakeflow İşlerini İzleme.