SDK ve CLI ile zaman serisi tahmin modelini eğitmek için AutoML'yi ayarlama
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)Python SDK azure-ai-ml v2 (geçerli)
Azure CLI ml uzantısı v2 (geçerli)Python SDK azure-ai-ml v2 (geçerli)
Bu makalede, Azure Machine Learning Python SDK'sında Azure Machine Learning otomatik ML ile zaman serisi tahminleri için AutoML'yi ayarlamayı öğreneceksiniz.
Bunun için şunları yapın:
- Eğitim için veri hazırlama.
- Tahmin İşi'nde belirli zaman serisi parametrelerini yapılandırın.
- Bileşenleri ve işlem hatlarını kullanarak eğitim, çıkarım ve model değerlendirmesini düzenleyin.
Düşük kod deneyimi için öğretici: Azure Machine Learning stüdyosu otomatik ML kullanarak zaman serisi tahmin örneği için otomatik makine öğrenmesi ile talebi tahmin etme bölümüne bakın.
AutoML, tahminler oluşturmak için standart makine öğrenmesi modellerinin yanı sıra iyi bilinen zaman serisi modellerini kullanır. Yaklaşımımız hedef değişken hakkında geçmiş bilgileri, giriş verilerinde kullanıcı tarafından sağlanan özellikleri ve otomatik olarak tasarlanmış özellikleri içerir. Model arama algoritmaları daha sonra en iyi tahmine dayalı doğruluğa sahip bir model bulmak için çalışır. Daha fazla ayrıntı için tahmin metodolojisi ve model arama makalelerimize bakın.
Önkoşullar
Bu makale için,
Azure Machine Learning çalışma alanı. Çalışma alanını oluşturmak için bkz . Çalışma alanı kaynakları oluşturma.
AutoML eğitim işlerini başlatma özelliği. Ayrıntılar için AutoML'yi ayarlamak için nasıl yapılır kılavuzunu izleyin.
Eğitim ve doğrulama verileri
AutoML tahmini için giriş verileri tablo biçiminde geçerli zaman serisi içermelidir. Her değişkenin veri tablosunda kendi karşılık gelen sütunu olmalıdır. AutoML için en az iki sütun gerekir: zaman eksenini temsil eden bir zaman sütunu ve tahmin edilen miktar olan hedef sütun . Diğer sütunlar tahmin aracı görevi görebilir. Daha fazla ayrıntı için bkz . AutoML verilerinizi nasıl kullanır.
Önemli
Gelecekteki değerleri tahmin etme modeli eğitirken, hedeflenen ufukta tahminleri çalıştırırken eğitimde kullanılan tüm özelliklerin kullanılabildiğinden emin olun.
Örneğin, geçerli hisse senedi fiyatına yönelik bir özellik eğitim doğruluğunu büyük ölçüde artırabilir. Bununla birlikte, uzun bir ufukla tahminde bulunabilmek istiyorsanız, gelecekteki zaman serisi noktalarına karşılık gelen gelecekteki hisse senedi değerlerini doğru tahmin edemeyebilirsiniz ve model doğruluğu zarar görebilir.
AutoML tahmin işleri, eğitim verilerinizin mlTable nesnesi olarak gösterilmesini gerektirir. MLTable bir veri kaynağı ve verileri yükleme adımlarını belirtir. Daha fazla bilgi ve kullanım örnekleri için MLTable nasıl yapılır kılavuzuna bakın. Basit bir örnek olarak, eğitim verilerinizin yerel dizindeki bir CSV dosyasında yer aldığı varsayılır ./train_data/timeseries_train.csv.
Aşağıdaki örnekte olduğu gibi mltable Python SDK'sını kullanarak mlTable oluşturabilirsiniz:
import mltable
paths = [
{'file': './train_data/timeseries_train.csv'}
]
train_table = mltable.from_delimited_files(paths)
train_table.save('./train_data')
Bu kod, ./train_data/MLTabledosya biçimini ve yükleme yönergelerini içeren yeni bir dosya oluşturur.
Şimdi, Azure Machine Learning Python SDK'sını kullanarak bir eğitim işi başlatmak için gereken bir giriş veri nesnesi tanımlarsınız:
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml import Input
# Training MLTable defined locally, with local data to be uploaded
my_training_data_input = Input(
type=AssetTypes.MLTABLE, path="./train_data"
)
MlTable oluşturup bir doğrulama veri girişi belirterek doğrulama verilerini benzer şekilde belirtirsiniz. Alternatif olarak, doğrulama verileri sağlamazsanız AutoML otomatik olarak eğitim verilerinizden model seçimi için kullanılacak çapraz doğrulama bölmeleri oluşturur. Daha fazla ayrıntı için model seçimini tahmin etme makalemize bakın. Ayrıca bir tahmin modelini başarılı bir şekilde eğitmek için ne kadar eğitim verisine ihtiyacınız olduğuyla ilgili ayrıntılar için eğitim veri uzunluğu gereksinimlerine bakın.
AutoML'nin aşırı sığdırmayı önlemek için çapraz doğrulamayı nasıl uyguladığı hakkında daha fazla bilgi edinin.
Deneme çalıştırmak için işlem
AutoML, eğitim işini çalıştırmak için tam olarak yönetilen bir işlem kaynağı olan Azure Machine Learning İşlem'i kullanır. Aşağıdaki örnekte adlı cpu-compute bir işlem kümesi oluşturulur:
from azure.ai.ml.entities import AmlCompute
# specify aml compute name.
cpu_compute_target = "cpu-cluster"
try:
ml_client.compute.get(cpu_compute_target)
except Exception:
print("Creating a new cpu compute target...")
compute = AmlCompute(
name=cpu_compute_target, size="STANDARD_D2_V2", min_instances=0, max_instances=4
)
ml_client.compute.begin_create_or_update(compute).result()Denemeyi yapılandırma
Python SDK'sında tahmin işlerini yapılandırmak için automl factory işlevlerini kullanırsınız. Aşağıdaki örnekte, birincil ölçümü ayarlayarak ve eğitim çalıştırması için sınırlar ayarlayarak bir tahmin işinin nasıl oluşturulacağı gösterilmektedir:
from azure.ai.ml import automl
# note that the below is a code snippet -- you might have to modify the variable values to run it successfully
forecasting_job = automl.forecasting(
compute="cpu-compute",
experiment_name="sdk-v2-automl-forecasting-job",
training_data=my_training_data_input,
target_column_name=target_column_name,
primary_metric="normalized_root_mean_squared_error",
n_cross_validations="auto",
)
# Limits are all optional
forecasting_job.set_limits(
timeout_minutes=120,
trial_timeout_minutes=30,
max_concurrent_trials=4,
)
Tahmin işi ayarları
Tahmin görevleri, tahmine özgü birçok ayara sahiptir. Bu ayarlardan en temeli, eğitim verilerindeki zaman sütununun adı ve tahmin ufku'dır.
Bu ayarları yapılandırmak için ForecastingJob yöntemlerini kullanın:
# Forecasting specific configuration
forecasting_job.set_forecast_settings(
time_column_name=time_column_name,
forecast_horizon=24
)
Zaman sütunu adı gerekli bir ayardır ve tahmin ufkunu genellikle tahmin senaryonuza göre ayarlamanız gerekir. Verileriniz birden çok zaman serisi içeriyorsa, zaman serisi kimlik sütunlarının adlarını belirtebilirsiniz. Bu sütunlar gruplandırıldığında tek tek serileri tanımlar. Örneğin, farklı mağaza ve markalardan saatlik satışlardan oluşan verileriniz olduğunu varsayalım. Aşağıdaki örnekte, verilerin "store" ve "brand" adlı sütunlar içerdiği varsayılarak zaman serisi kimlik sütunlarının nasıl ayarlanacağı gösterilmektedir:
# Forecasting specific configuration
# Add time series IDs for store and brand
forecasting_job.set_forecast_settings(
..., # other settings
time_series_id_column_names=['store', 'brand']
)
AutoML, belirtilmemişse verilerinizdeki zaman serisi kimlik sütunlarını otomatik olarak algılamaya çalışır.
Diğer ayarlar isteğe bağlıdır ve sonraki bölümde gözden geçirilir.
İsteğe bağlı tahmin işi ayarları
Derin öğrenmeyi etkinleştirme ve hedef sıralı pencere toplamayı belirtme gibi tahmin görevleri için isteğe bağlı yapılandırmalar kullanılabilir. Parametrelerin tam listesi, tahmin başvurusu belgeleri belgelerinde bulunur.
Model arama ayarları
AutoML'nin en iyi allowed_training_algorithms modeli arayacağı model alanını denetleyebilen iki isteğe bağlı ayar vardır ve blocked_training_algorithms. Arama alanını belirli bir model sınıfları kümesiyle kısıtlamak için aşağıdaki örnekte olduğu gibi parametresini kullanın allowed_training_algorithms :
# Only search ExponentialSmoothing and ElasticNet models
forecasting_job.set_training(
allowed_training_algorithms=["ExponentialSmoothing", "ElasticNet"]
)
Bu durumda, tahmin işi yalnızca Üstel Düzeltme ve Elastik Net model sınıfları üzerinde aramalar sağlar. Arama alanından belirli bir model sınıfı kümesini kaldırmak için aşağıdaki örnekte olduğu gibi blocked_training_algorithms kullanın:
# Search over all model classes except Prophet
forecasting_job.set_training(
blocked_training_algorithms=["Prophet"]
)
Şimdi, iş Kahin dışında tüm model sınıflarını arar. ve blocked_training_algorithmsiçinde allowed_training_algorithms kabul edilen tahmin modeli adlarının listesi için eğitim özellikleri başvuru belgelerine bakın. eğitim çalıştırmasına allowed_training_algorithms blocked_training_algorithms hem de hem de değil uygulanabilir.
Derin öğrenmeyi etkinleştirme
AutoML adlı TCNForecasterözel bir derin sinir ağı (DNN) modeliyle birlikte sunulur. Bu model, zaman serisi modellemesine yaygın görüntüleme görevi yöntemlerini uygulayan bir zamansal kıvrımlı ağ veya TCN'dir. Yani, tek boyutlu "nedensel" convolutions ağın omurgasını oluşturur ve modelin eğitim geçmişinde uzun süreler boyunca karmaşık desenler öğrenmesini sağlar. Diğer ayrıntılar için TCNForecaster makalemize bakın.
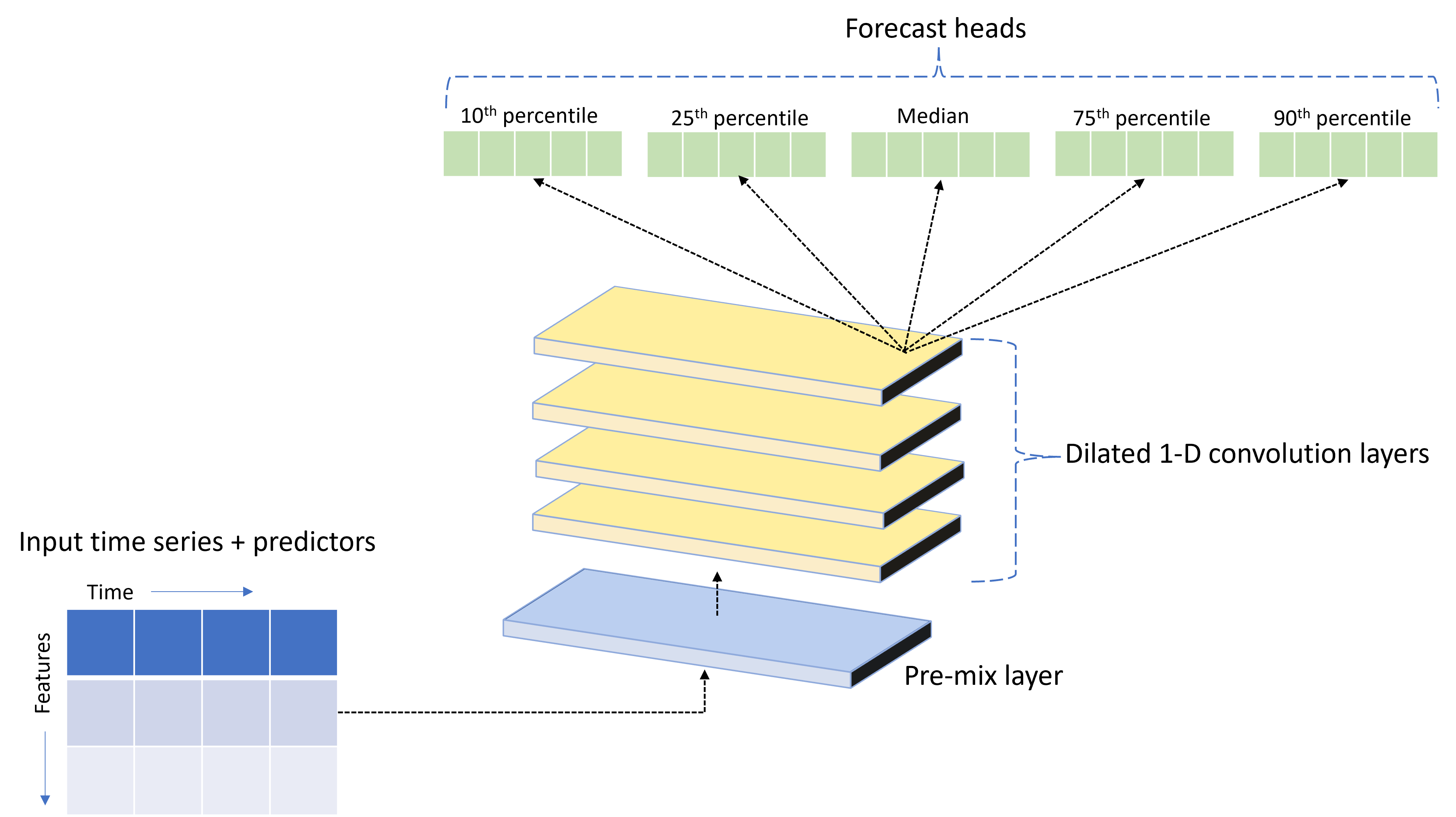
TCNForecaster genellikle eğitim geçmişinde binlerce veya daha fazla gözlem olduğunda standart zaman serisi modellerinden daha yüksek doğruluk elde eder. Ancak, daha yüksek kapasiteleri nedeniyle TCNForecaster modellerini eğitmek ve taramak da daha uzun sürer.
Eğitim yapılandırmasında bayrağını aşağıdaki gibi ayarlayarak enable_dnn_training AutoML'de TCNForecaster'i etkinleştirebilirsiniz:
# Include TCNForecaster models in the model search
forecasting_job.set_training(
enable_dnn_training=True
)
Varsayılan olarak, TCNForecaster eğitimi model denemesi başına tek bir işlem düğümü ve varsa tek bir GPU ile sınırlıdır. Büyük veri senaryoları için her TCNForecaster deneme sürümünü birden çok çekirdek/GPU ve düğüme dağıtmanızı öneririz. Daha fazla bilgi ve kod örnekleri için dağıtılmış eğitim makalesi bölümümüze bakın.
Azure Machine Learning stüdyosu oluşturulan bir AutoML denemesi için DNN'yi etkinleştirmek için, studio kullanıcı arabirimindeki görev türü ayarlarına bakın.
Not
- SDK ile oluşturulan denemeler için DNN'yi etkinleştirdiğinizde, en iyi model açıklamaları devre dışı bırakılır.
- Otomatik Makine Öğrenmesi'nde tahmin için DNN desteği Databricks'te başlatılan çalıştırmalar için desteklenmez.
- DNN eğitimi etkinleştirildiğinde GPU işlem türleri önerilir
Gecikme ve hareketli pencere özellikleri
Hedefin son değerleri genellikle tahmin modelindeki etkili özelliklerdir. Buna göre AutoML, model doğruluğunu artırmak için zaman gecikmeli ve sıralı pencere toplama özellikleri oluşturabilir.
Hava durumu verilerinin ve geçmiş talebin kullanılabildiği bir enerji talebi tahmin senaryosu düşünün. Tablo, en son üç saat içinde pencere toplama uygulandığında ortaya çıkan özellik mühendisliğini gösterir. Minimum, maksimum ve toplam sütunları, tanımlanan ayarlara göre üç saatlik bir kayan pencerede oluşturulur. Örneğin, 8 Eylül 2017 04:00'da geçerli olan gözlem için maksimum, minimum ve toplam değerleri 8 Eylül 2017 13:00 - 03:00 arası talep değerleri kullanılarak hesaplanır. Üç saatlik bu pencere, kalan satırlara ait verileri doldurmak için birlikte kayar. Diğer ayrıntılar ve örnekler için gecikme özelliği makalesine bakın.

Önceki örnekte üç olan sıralı pencere boyutunu ve oluşturmak istediğiniz gecikme siparişlerini ayarlayarak hedef için gecikme ve sıralı pencere toplama özelliklerini etkinleştirebilirsiniz. Ayrıca ayarıyla feature_lags özellikler için gecikmeleri etkinleştirebilirsiniz. Aşağıdaki örnekte, AutoML'nin verilerinizin bağıntı yapısını analiz ederek ayarları otomatik olarak belirlemesi için auto bu ayarların tümünü olarak ayarlayacağız:
forecasting_job.set_forecast_settings(
..., # other settings
target_lags='auto',
target_rolling_window_size='auto',
feature_lags='auto'
)
Kısa seri işleme
Otomatik ML, model geliştirmenin tren ve doğrulama aşamalarını yürütmek için yeterli veri noktası yoksa zaman serisini kısa bir seri olarak değerlendirir. Uzunluk gereksinimleri hakkında daha fazla bilgi için bkz. eğitim veri uzunluğu gereksinimleri.
AutoML'nin kısa seriler için gerçekleştirebileceği çeşitli eylemleri vardır. Bu eylemler ayarıyla short_series_handling_config yapılandırılabilir. Varsayılan değer "otomatik"tir. Aşağıdaki tabloda ayarlar açıklanmaktadır:
| Ayar | Açıklama |
|---|---|
auto |
Kısa seri işleme için varsayılan değer. - Tüm seriler kısaysa, verileri doldurma. - Tüm seriler kısa değilse, kısa seriyi bırakın. |
pad |
ise short_series_handling_config = pad, otomatik ML bulunan her kısa seriye rastgele değerler ekler. Aşağıda sütun türleri ve bunların nelerle dolduruldıkları listelenmiştir: - NaN'leri olan nesne sütunları - 0 içeren sayısal sütunlar - False ile Boole/mantıksal sütunlar - Hedef sütun beyaz gürültü ile doldurulur. |
drop |
ise short_series_handling_config = drop, otomatik ML kısa seriyi bırakır ve eğitim veya tahmin için kullanılmaz. Bu seriler için tahminler NaN'leri döndürür. |
None |
Hiçbir seri doldurulmamış veya bırakılmamış |
Aşağıdaki örnekte, kısa seri işlemeyi tüm kısa serilerin minimum uzunluğa doldurulması için ayarlayacağız:
forecasting_job.set_forecast_settings(
..., # other settings
short_series_handling_config='pad'
)
Uyarı
Doldurma, eğitim hatalarından kaçınmak için yapay veriler kullanıma sunduğumuzdan elde edilen modelin doğruluğunu etkileyebilir. Serilerin birçoğu kısaysa, açıklanabilirlik sonuçlarında da bazı etkiler görebilirsiniz
Sıklık ve hedef veri toplama
Düzensiz verilerin neden olduğu hataları önlemek için sıklık ve veri toplama seçeneklerini kullanın. Saatlik veya günlük gibi belirli bir tempoya uymayan verileriniz düzensizdir. Satış noktası verileri, düzensiz verilere iyi bir örnektir. Bu gibi durumlarda AutoML, verilerinizi istenen sıklıkta toplayabilir ve ardından toplamalardan bir tahmin modeli oluşturabilir.
Düzensiz verileri işlemek için ve target_aggregate_function ayarlarını ayarlamanız frequency gerekir. Sıklık ayarı Pandas DateOffset dizelerini giriş olarak kabul eder. Toplama işlevi için desteklenen değerler şunlardır:
| İşlev | Açıklama |
|---|---|
sum |
Hedef değerlerin toplamı |
mean |
Hedef değerlerin ortalaması veya ortalaması |
min |
Hedefin en düşük değeri |
max |
Hedefin en büyük değeri |
- Hedef sütun değerleri belirtilen işleme göre toplanır. Genellikle, toplam çoğu senaryo için uygundur.
- Verilerinizdeki sayısal tahmin aracı sütunları toplam, ortalama, en düşük değer ve en yüksek değere göre toplanır. Sonuç olarak, otomatik ML toplama işlevi adıyla ekli yeni sütunlar oluşturur ve seçili toplama işlemini uygular.
- Kategorik tahmin sütunları için veriler, penceredeki en belirgin kategori olan moda göre toplanır.
- Tarih tahmincisi sütunları minimum değer, maksimum değer ve mod ile toplanır.
Aşağıdaki örnek sıklığı saatlik olarak, toplama işlevini ise toplama olarak ayarlar:
# Aggregate the data to hourly frequency
forecasting_job.set_forecast_settings(
..., # other settings
frequency='H',
target_aggregate_function='sum'
)
Özel çapraz doğrulama ayarları
Tahmin işleri için çapraz doğrulamayı denetleyebilen iki özelleştirilebilir ayar vardır: katlama sayısı ve katlamalar n_cross_validationsarasındaki zaman uzaklığını tanımlayan adım boyutu. cv_step_size Bu parametrelerin anlamı hakkında daha fazla bilgi için bkz . tahmin modeli seçimi . Varsayılan olarak, AutoML her iki ayarı da verilerinizin özelliklerine göre otomatik olarak ayarlar, ancak ileri düzey kullanıcılar bunları el ile ayarlamak isteyebilir. Örneğin, günlük satış verileriniz olduğunu ve doğrulama kurulumunuzun bitişik katlar arasında yedi günlük uzaklığı olan beş katlamadan oluşmasını istediğinizi varsayalım. Aşağıdaki kod örneğinde bunların nasıl ayarlanacağı gösterilmektedir:
from azure.ai.ml import automl
# Create a job with five CV folds
forecasting_job = automl.forecasting(
..., # other training parameters
n_cross_validations=5,
)
# Set the step size between folds to seven days
forecasting_job.set_forecast_settings(
..., # other settings
cv_step_size=7
)
Özel özellik geliştirme
AutoML, modellerin doğruluğunu artırmak için eğitim verilerini varsayılan olarak tasarlanmış özelliklerle artırır. Daha fazla bilgi için bkz . otomatik özellik mühendisliği . Ön işleme adımlarından bazıları, tahmin işinin özellik oluşturma yapılandırması kullanılarak özelleştirilebilir.
Tahmin için desteklenen özelleştirmeler aşağıdaki tabloda yer alır:
| Özelleştirme | Açıklama | Seçenekler |
|---|---|---|
| Sütun amaçlı güncelleştirme | Belirtilen sütun için otomatik algılanan özellik türünü geçersiz kılın. | "Kategorik", "DateTime", "Sayısal" |
| Transformer parametre güncelleştirmesi | Belirtilen imputer için parametreleri güncelleştirin. | {"strategy": "constant", "fill_value": <value>}, {"strategy": "median"}, {"strategy": "ffill"} |
Örneğin, verilerin fiyatları, "satışta" bayrağını ve ürün türünü içerdiği bir perakende talep senaryonuz olduğunu varsayalım. Aşağıdaki örnek, bu özellikler için özelleştirilmiş türleri ve imputer'leri nasıl ayarlayabileceğinizi gösterir:
from azure.ai.ml.automl import ColumnTransformer
# Customize imputation methods for price and is_on_sale features
# Median value imputation for price, constant value of zero for is_on_sale
transformer_params = {
"imputer": [
ColumnTransformer(fields=["price"], parameters={"strategy": "median"}),
ColumnTransformer(fields=["is_on_sale"], parameters={"strategy": "constant", "fill_value": 0}),
],
}
# Set the featurization
# Ensure that product_type feature is interpreted as categorical
forecasting_job.set_featurization(
mode="custom",
transformer_params=transformer_params,
column_name_and_types={"product_type": "Categorical"},
)
Denemeniz için Azure Machine Learning stüdyosu kullanıyorsanız stüdyoda özellik geliştirmeyi özelleştirme bölümüne bakın.
Tahmin işi gönderme
Tüm ayarlar yapılandırıldıktan sonra tahmin işini şu şekilde başlatırsınız:
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(
forecasting_job
)
print(f"Created job: {returned_job}")
# Get a URL for the job in the AML studio user interface
returned_job.services["Studio"].endpoint
İş gönderildikten sonra AutoML işlem kaynaklarını sağlar, giriş verilerine özellik kazandırma ve diğer hazırlık adımlarını uygular ve ardından tahmin modellerini süpürmeye başlar. Daha fazla ayrıntı için tahmin metodolojisi ve model arama makalelerimize bakın.
Bileşenler ve işlem hatları ile eğitim, çıkarım ve değerlendirmeyi düzenleme
Önemli
Bu özellik şu anda genel önizlemededir. Bu önizleme sürümü hizmet düzeyi sözleşmesi olmadan sağlanır ve üretim iş yükleri için bu sürümü önermeyiz. Bazı özellikler desteklenmiyor olabileceği gibi özellikleri sınırlandırılmış da olabilir.
Daha fazla bilgi için bkz. Microsoft Azure Önizlemeleri Ek Kullanım Koşulları.
ML iş akışınız büyük olasılıkla eğitimden fazlasını gerektirir. Çıkarım veya daha yeni verilerle ilgili model tahminlerini alma ve bilinen hedef değerleri içeren bir test kümesindeki model doğruluğunun değerlendirilmesi, Eğitim işleriyle birlikte AzureML'de düzenleyebileceğiniz diğer yaygın görevlerdir. Çıkarım ve değerlendirme görevlerini desteklemek için AzureML, AzureML işlem hattında bir adım gerçekleştiren bağımsız kod parçaları olan bileşenler sağlar.
Aşağıdaki örnekte, bileşen kodunu bir istemci kayıt defterinden alıyoruz:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Create a client for accessing assets in the AzureML preview registry
ml_client_registry = MLClient(
credential=credential,
registry_name="azureml-preview"
)
# Create a client for accessing assets in the AzureML preview registry
ml_client_metrics_registry = MLClient(
credential=credential,
registry_name="azureml"
)
# Get an inference component from the registry
inference_component = ml_client_registry.components.get(
name="automl_forecasting_inference",
label="latest"
)
# Get a component for computing evaluation metrics from the registry
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
Ardından, eğitim, çıkarım ve ölçüm hesaplamasını düzenleyen işlem hatları oluşturan bir fabrika işlevi tanımlayacağız. Eğitim ayarları hakkında daha fazla bilgi için eğitim yapılandırması bölümüne bakın.
from azure.ai.ml import automl
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml.dsl import pipeline
@pipeline(description="AutoML Forecasting Pipeline")
def forecasting_train_and_evaluate_factory(
train_data_input,
test_data_input,
target_column_name,
time_column_name,
forecast_horizon,
primary_metric='normalized_root_mean_squared_error',
cv_folds='auto'
):
# Configure the training node of the pipeline
training_node = automl.forecasting(
training_data=train_data_input,
target_column_name=target_column_name,
primary_metric=primary_metric,
n_cross_validations=cv_folds,
outputs={"best_model": Output(type=AssetTypes.MLFLOW_MODEL)},
)
training_node.set_forecasting_settings(
time_column_name=time_column_name,
forecast_horizon=max_horizon,
frequency=frequency,
# other settings
...
)
training_node.set_training(
# training parameters
...
)
training_node.set_limits(
# limit settings
...
)
# Configure the inference node to make rolling forecasts on the test set
inference_node = inference_component(
test_data=test_data_input,
model_path=training_node.outputs.best_model,
target_column_name=target_column_name,
forecast_mode='rolling',
forecast_step=1
)
# Configure the metrics calculation node
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
ground_truth=inference_node.outputs.inference_output_file,
prediction=inference_node.outputs.inference_output_file,
evaluation_config=inference_node.outputs.evaluation_config_output_file
)
# return a dictionary with the evaluation metrics and the raw test set forecasts
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result,
"rolling_fcst_result": inference_node.outputs.inference_output_file
}
Şimdi, yerel klasörlerde ./train_data yer aldıklarını varsayarak veri girişlerini eğitip test ediyoruz ve ./test_data:
my_train_data_input = Input(
type=AssetTypes.MLTABLE,
path="./train_data"
)
my_test_data_input = Input(
type=AssetTypes.URI_FOLDER,
path='./test_data',
)
Son olarak işlem hattını oluşturur, varsayılan işlemini ayarlar ve işi göndeririz:
pipeline_job = forecasting_train_and_evaluate_factory(
my_train_data_input,
my_test_data_input,
target_column_name,
time_column_name,
forecast_horizon
)
# set pipeline level compute
pipeline_job.settings.default_compute = compute_name
# submit the pipeline job
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name
)
returned_pipeline_job
İşlem hattı gönderildikten sonra AutoML eğitimini, sıralı değerlendirme çıkarımını ve ölçüm hesaplamasını sırayla çalıştırır. Çalıştırmayı stüdyo kullanıcı arabiriminde izleyebilir ve inceleyebilirsiniz. Çalıştırma tamamlandığında, sıralı tahminler ve değerlendirme ölçümleri yerel çalışma dizinine indirilebilir:
# Download the metrics json
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='metrics_result')
# Download the rolling forecasts
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='rolling_fcst_result')
Ardından, içindeki ölçüm sonuçlarını ./named-outputs/metrics_results/evaluationResult/metrics.json ve tahminleri JSON satırları biçiminde, içinde ./named-outputs/rolling_fcst_result/inference_output_filebulabilirsiniz.
Sıralı değerlendirme hakkında daha fazla bilgi için tahmin modeli değerlendirme makalemize bakın.
Büyük ölçekte tahmin: birçok model
Önemli
Bu özellik şu anda genel önizlemededir. Bu önizleme sürümü hizmet düzeyi sözleşmesi olmadan sağlanır ve üretim iş yükleri için bu sürümü önermeyiz. Bazı özellikler desteklenmiyor olabileceği gibi özellikleri sınırlandırılmış da olabilir.
Daha fazla bilgi için bkz. Microsoft Azure Önizlemeleri Ek Kullanım Koşulları.
AutoML'deki birçok model bileşeni, milyonlarca modeli paralel olarak eğitip yönetmenizi sağlar. Birçok model kavramı hakkında daha fazla bilgi için birçok model makalesi bölümüne bakın.
Birçok model eğitim yapılandırması
Birçok model eğitim bileşeni, AutoML eğitim ayarlarının YAML biçimli yapılandırma dosyasını kabul eder. Bileşen, bu ayarları başlattığı her AutoML örneğine uygular. Bu YAML dosyası Tahmin İşi ile aynı belirtime ek olarak ve allow_multi_partitionsparametreleriyle partition_column_names aynı belirtime sahiptir.
| Parametre | Açıklama |
|---|---|
| partition_column_names | Gruplandırıldığında veri bölümlerini tanımlayan verilerdeki sütun adları. Birçok model eğitim bileşeni her bölümde bağımsız bir eğitim işi başlatır. |
| allow_multi_partitions | Her bölüm birden fazla benzersiz zaman serisi içerdiğinde bölüm başına bir model eğitmesini sağlayan isteğe bağlı bir bayrak. Varsayılan değer False'tur. |
Aşağıdaki örnek bir yapılandırma şablonu sağlar:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:<cluster-name>
task: forecasting
primary_metric: normalized_root_mean_squared_error
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: date
time_series_id_column_names: ["state", "store"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
partition_column_names: ["state", "store"]
allow_multi_partitions: false
Sonraki örneklerde, yapılandırmanın yolunda ./automl_settings_mm.ymldepolandığını varsayarız.
Birçok model işlem hattı
Ardından, birçok modelin eğitimi, çıkarımı ve ölçüm hesaplamasını düzenlemek için işlem hatları oluşturan bir fabrika işlevi tanımlayacağız. Bu fabrika işlevinin parametreleri aşağıdaki tabloda ayrıntılı olarak gösterilmiştir:
| Parametre | Açıklama |
|---|---|
| max_nodes | Eğitim işinde kullanılacak işlem düğümlerinin sayısı |
| max_concurrency_per_node | Her düğümde çalıştırılacak AutoML işlemlerinin sayısı. Bu nedenle, birçok model işinin toplam eşzamanlılığı şeklindedir max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | Saniye sayısı olarak verilen birçok model bileşeni zaman aşımı. |
| retrain_failed_models | Başarısız modeller için yeniden eğitimi etkinleştirmek için bayrak ekleyin. Bu, bazı veri bölümlerinde AutoML işlerinin başarısız olmasıyla sonuçlanan önceki birçok model çalıştırmasını yaptıysanız kullanışlıdır. Bu bayrak etkinleştirildiğinde, birçok model yalnızca daha önce başarısız olan bölümler için eğitim işlerini başlatır. |
| forecast_mode | Model değerlendirmesi için çıkarım modu. Geçerli değerler ve "recursive" "rolling". Daha fazla bilgi için model değerlendirme makalesine bakın. |
| forecast_step | Sıralı tahmin için adım boyutu. Daha fazla bilgi için model değerlendirme makalesine bakın. |
Aşağıdaki örnekte, birçok model eğitim ve model değerlendirme işlem hattı oluşturmak için bir fabrika yöntemi gösterilmektedir:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a many models training component
mm_train_component = ml_client_registry.components.get(
name='automl_many_models_training',
version='latest'
)
# Get a many models inference component
mm_inference_component = ml_client_registry.components.get(
name='automl_many_models_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML Many Models Forecasting Pipeline")
def many_models_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
compute_name,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
retrain_failed_model=False,
forecast_mode="rolling",
forecast_step=1
):
mm_train_node = mm_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
retrain_failed_model=retrain_failed_model,
compute_name=compute_name
)
mm_inference_node = mm_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=mm_train_node.outputs.run_output,
forecast_mode=forecast_mode,
forecast_step=forecast_step,
compute_name=compute_name
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=mm_inference_node.outputs.evaluation_data,
ground_truth=mm_inference_node.outputs.evaluation_data,
evaluation_config=mm_inference_node.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Şimdi, eğitim ve test verilerinin sırasıyla yerel klasörlerde ./data/train ve ./data/testolduğunu varsayarak işlem hattını fabrika işlevi aracılığıyla oluşturacağız. Son olarak, varsayılan işlemi ayarlayıp işi aşağıdaki örnekte olduğu gibi göndereceğiz:
pipeline_job = many_models_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_mm.yml"
),
compute_name="<cluster name>"
)
pipeline_job.settings.default_compute = "<cluster name>"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
İş tamamlandıktan sonra değerlendirme ölçümleri, tek eğitim çalıştırma işlem hattındakiyle aynı yordam kullanılarak yerel olarak indirilebilir.
Ayrıca daha ayrıntılı bir örnek için birçok model not defteriyle talep tahmini bölümüne bakın.
Not
Birçok model eğitim ve çıkarım bileşeni, her bölümün kendi dosyasında olması için verilerinizi ayara partition_column_names göre koşullu olarak bölümler. Bu işlem çok yavaş olabilir veya veriler çok büyük olduğunda başarısız olabilir. Bu durumda, birçok model eğitimi veya çıkarımı çalıştırmadan önce verilerinizi el ile bölümlemenizi öneririz.
Büyük ölçekte tahmin: hiyerarşik zaman serisi
Önemli
Bu özellik şu anda genel önizlemededir. Bu önizleme sürümü hizmet düzeyi sözleşmesi olmadan sağlanır ve üretim iş yükleri için bu sürümü önermeyiz. Bazı özellikler desteklenmiyor olabileceği gibi özellikleri sınırlandırılmış da olabilir.
Daha fazla bilgi için bkz. Microsoft Azure Önizlemeleri Ek Kullanım Koşulları.
AutoML'deki hiyerarşik zaman serisi (HTS) bileşenleri, hiyerarşik yapıya sahip veriler üzerinde çok sayıda model eğitebilirsiniz. Daha fazla bilgi için HTS makalesi bölümüne bakın.
HTS eğitim yapılandırması
HTS eğitim bileşeni, AutoML eğitim ayarlarının YAML biçimli yapılandırma dosyasını kabul eder. Bileşen, bu ayarları başlattığı her AutoML örneğine uygular. Bu YAML dosyası, Tahmin İşi ile aynı belirtime ve hiyerarşi bilgileriyle ilgili ek parametrelere sahiptir:
| Parametre | Açıklama |
|---|---|
| hierarchy_column_names | Verilerin hiyerarşik yapısını tanımlayan verilerdeki sütun adlarının listesi. Bu listedeki sütunların sırası hiyerarşi düzeylerini belirler; toplama derecesi, liste diziniyle birlikte azalır. Yani, listedeki son sütun hiyerarşinin yaprak (en fazla ayrılmış) düzeyini tanımlar. |
| hierarchy_training_level | Tahmin modeli eğitimi için kullanılacak hiyerarşi düzeyi. |
Aşağıda örnek bir yapılandırma gösterilmektedir:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:cluster-name
task: forecasting
primary_metric: normalized_root_mean_squared_error
log_verbosity: info
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: "date"
time_series_id_column_names: ["state", "store", "SKU"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
hierarchy_column_names: ["state", "store", "SKU"]
hierarchy_training_level: "store"
Sonraki örneklerde, yapılandırmanın yolunda ./automl_settings_hts.ymldepolandığını varsayarız.
HTS işlem hattı
Daha sonra HTS eğitimi, çıkarım ve ölçüm hesaplamasını düzenlemek için işlem hatları oluşturan bir fabrika işlevi tanımlayacağız. Bu fabrika işlevinin parametreleri aşağıdaki tabloda ayrıntılı olarak gösterilmiştir:
| Parametre | Açıklama |
|---|---|
| forecast_level | Tahminleri alınacak hiyerarşinin düzeyi |
| allocation_method | Tahminler toplandığında kullanılacak ayırma yöntemi. Geçerli değerler: "proportions_of_historical_average" ve "average_historical_proportions". |
| max_nodes | Eğitim işinde kullanılacak işlem düğümlerinin sayısı |
| max_concurrency_per_node | Her düğümde çalıştırılacak AutoML işlemlerinin sayısı. Bu nedenle, bir HTS işinin toplam eşzamanlılığı olur max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | Saniye sayısı olarak verilen birçok model bileşeni zaman aşımı. |
| forecast_mode | Model değerlendirmesi için çıkarım modu. Geçerli değerler ve "recursive" "rolling". Daha fazla bilgi için model değerlendirme makalesine bakın. |
| forecast_step | Sıralı tahmin için adım boyutu. Daha fazla bilgi için model değerlendirme makalesine bakın. |
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a HTS training component
hts_train_component = ml_client_registry.components.get(
name='automl_hts_training',
version='latest'
)
# Get a HTS inference component
hts_inference_component = ml_client_registry.components.get(
name='automl_hts_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML HTS Forecasting Pipeline")
def hts_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
forecast_mode="rolling",
forecast_step=1,
forecast_level="SKU",
allocation_method='proportions_of_historical_average'
):
hts_train = hts_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
max_nodes=max_nodes
)
hts_inference = hts_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=hts_train.outputs.run_output,
forecast_level=forecast_level,
allocation_method=allocation_method,
forecast_mode=forecast_mode,
forecast_step=forecast_step
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=hts_inference.outputs.evaluation_data,
ground_truth=hts_inference.outputs.evaluation_data,
evaluation_config=hts_inference.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Şimdi, eğitim ve test verilerinin sırasıyla yerel klasörlerde ./data/train ve ./data/testolduğunu varsayarak işlem hattını fabrika işlevi aracılığıyla oluşturacağız. Son olarak, varsayılan işlemi ayarlayıp işi aşağıdaki örnekte olduğu gibi göndereceğiz:
pipeline_job = hts_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_hts.yml"
)
)
pipeline_job.settings.default_compute = "cluster-name"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
İş tamamlandıktan sonra değerlendirme ölçümleri, tek eğitim çalıştırma işlem hattındakiyle aynı yordam kullanılarak yerel olarak indirilebilir.
Daha ayrıntılı bir örnek için hiyerarşik zaman serisi not defteriyle talep tahmini konusuna da bakın.
Not
HTS eğitim ve çıkarım bileşenleri, her bölümün kendi dosyasında olması için verilerinizi ayara hierarchy_column_names göre koşullu olarak bölümler. Bu işlem çok yavaş olabilir veya veriler çok büyük olduğunda başarısız olabilir. Bu durumda, HTS eğitimini veya çıkarımını çalıştırmadan önce verilerinizi el ile bölümlemenizi öneririz.
Büyük ölçekte tahmin: dağıtılmış DNN eğitimi
- Dağıtılmış eğitimin tahmin görevleri için nasıl çalıştığını öğrenmek için ölçek düzeyinde tahmin makalemize bakın.
- Kod örnekleri için tablosal veriler için dağıtılmış eğitim kurulumu makale bölümümüze bakın.
Örnek not defterleri
Gelişmiş tahmin yapılandırmasının ayrıntılı kod örnekleri için tahmin örneği not defterlerine bakın:
- Talep tahmini işlem hattı örnekleri
- Derin öğrenme modelleri
- Tatil algılama ve özellik geliştirme
- Gecikmeler ve sıralı pencere toplama özellikleri için el ile yapılandırma
Sonraki adımlar
- AutoML modelini çevrimiçi uç noktaya dağıtma hakkında daha fazla bilgi edinin.
- Yorumlanabilirlik: otomatik makine öğrenmesinde model açıklamaları (önizleme) hakkında bilgi edinin.
- AutoML'nin tahmin modellerini nasıl derleyeceğinizi öğrenin.
- Uygun ölçekte tahmin hakkında bilgi edinin.
- Çeşitli tahmin senaryoları için AutoML'yi yapılandırmayı öğrenin.
- Tahmin modellerinin çıkarımı ve değerlendirilmesi hakkında bilgi edinin.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin