Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Data Box cihazı kullanarak Hadoop kümenizin şirket içi HDFS deposundaki verileri Azure Depolama'ya (blob depolama veya Data Lake Storage) geçirebilirsiniz. Data Box Disk, 80, 120 veya 525 TiB kapasiteye sahip bir Data Box ya da 770 TiB Data Box Heavy arasından seçim yapabilirsiniz.
Bu makale şu görevleri tamamlamanıza yardımcı olur:
- Verilerinizi geçirmeye hazırlanma
- Verilerinizi bir Data Box Diskine, Data Box'a veya Data Box Heavy cihazına kopyalama
- Cihazı Microsoft'a geri gönderme
- Dosyalara ve dizinlere erişim izinleri uygulama (yalnızca Data Lake Storage)
Önkoşullar
Geçişi tamamlamak için bu işlemlere ihtiyacınız vardır.
Bir Azure Depolama hesabı.
Kaynak verilerinizi içeren bir şirket içi Hadoop kümesi.
Azure Data Box cihazı.
Data Box veya Data Box Heavy sipariş edin.
Data Box veya Data Box Heavy'i bir ağ kablosu kullanarak şirket içi ağa bağlayın.
Hazırsanız başlayalım.
Verilerinizi Data Box cihazına kopyalama
Verileriniz tek bir Data Box cihazına sığıyorsa, verileri Data Box cihazına kopyalarsınız.
Veri boyutunuz Data Box cihazının kapasitesini aşıyorsa, isteğe bağlı yordamı kullanarak verileri birden çok Data Box cihazına bölün ve bu adımı gerçekleştirin.
Şirket içi HDFS deponuzdaki verileri data Box cihazına kopyalamak için birkaç şey ayarlayıp DistCp aracını kullanırsınız.
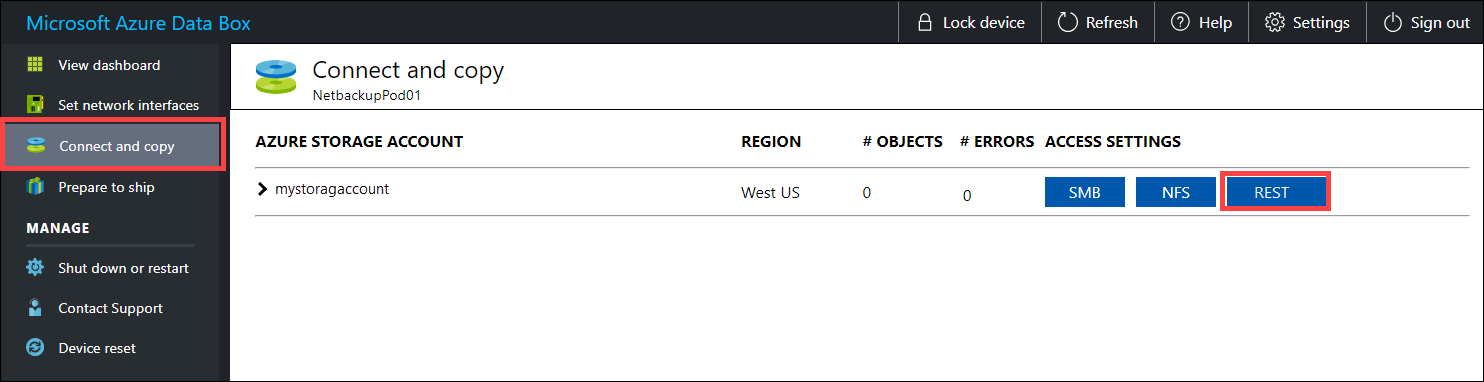
Blob/Nesne depolamanın REST API'leri aracılığıyla Data Box cihazınıza veri kopyalamak için bu adımları izleyin. REST API arabirimi, cihazın kümenizde HDFS deposu olarak görünmesini sağlar.
VERILERI REST aracılığıyla kopyalamadan önce Data Box veya Data Box Heavy'de REST arabirimine bağlanmak için güvenlik ve bağlantı temel öğelerini belirleyin. Data Box'ın yerel web kullanıcı arabiriminde oturum açın ve Bağlan ve kopyala sayfasına gidin. Cihazınızın Azure depolama hesaplarında, Erişim ayarları'nın altında REST'i bulun ve seçin.
Depolama hesabına erişme ve verileri karşıya yükleme iletişim kutusunda Blob hizmet uç noktasını ve Depolama hesabı anahtarını kopyalayın. Blob hizmeti uç noktasından
https://ve sonundaki eğik çizgiyi çıkartın.Bu durumda uç nokta:
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/. Kullandığınız URI'nin konak kısmı:mystorageaccount.blob.mydataboxno.microsoftdatabox.com. Bir örnek için bkz. HTTP üzerinden REST'e bağlanma.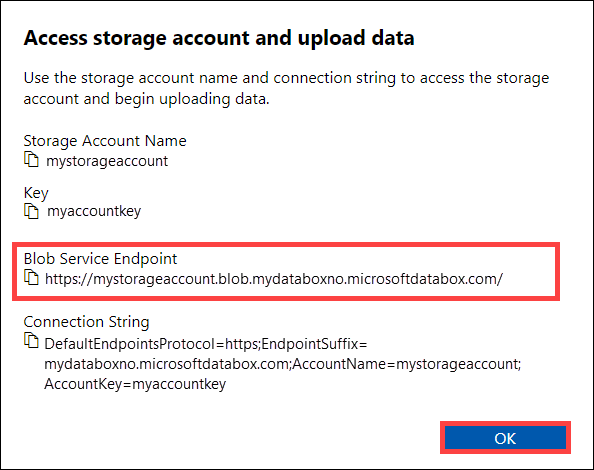
Her düğüme uç noktayı ve Data Box veya Data Box Heavy düğüm IP adresini
/etc/hostsekleyin.10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.comDNS için başka bir mekanizma kullanıyorsanız Data Box uç noktasının çözümlenebilmesini sağlamanız gerekir.
Kabuk değişkenini
azjars,hadoop-azureveazure-storagejar dosyalarının konumuna ayarlayın. Bu dosyaları Hadoop yükleme dizini altında bulabilirsiniz.Bu dosyaların mevcut olup olmadığını belirlemek için şu komutu kullanın:
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure. Yüklediğiniz Hadoop dizininin yolunu<hadoop_install_dir>yer tutucusunun yerine koyun. Tam nitelikli yolları kullandığınızdan emin olun.Örnekler:
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jarVeri kopyalama için kullanmak istediğiniz depolama kapsayıcısını oluşturun. Bu komutun bir parçası olarak bir hedef dizin de belirtmelisiniz. Bu noktada bu, sahte bir hedef dizin olabilir.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Yer tutucusunu
<blob_service_endpoint>blob hizmet uç noktanızın adıyla değiştirin.<account_key>yer tutucusunu hesabınızın erişim anahtarıyla değiştirin.Yer tutucuyu
<container-name>kapsayıcınızın adıyla değiştirin.Yer tutucuyu
<destination_directory>, verilerinizi kopyalamak istediğiniz dizinin adıyla değiştirin.
Kapsayıcınızın ve dizininizin oluşturulduğunu sağlamak için bir liste komutu çalıştırın.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/Yer tutucusunu
<blob_service_endpoint>blob hizmet uç noktanızın adıyla değiştirin.<account_key>yer tutucusunu hesabınızın erişim anahtarıyla değiştirin.Yer tutucuyu
<container-name>kapsayıcınızın adıyla değiştirin.
Hadoop HDFS'den Data Box Blob depolama alanına verileri daha önce oluşturduğunuz kapsayıcıya kopyalayın. Kopyaladığınız dizin bulunamazsa, komut dizini otomatik olarak oluşturur.
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Yer tutucusunu
<blob_service_endpoint>blob hizmet uç noktanızın adıyla değiştirin.<account_key>yer tutucusunu hesabınızın erişim anahtarıyla değiştirin.Yer tutucuyu
<container-name>kapsayıcınızın adıyla değiştirin.Yer tutucuyu
<exclusion_filelist_file>, dosya dışlama listenizi içeren dosyanın adıyla değiştirin.Yer tutucuyu
<source_directory>, kopyalamak istediğiniz verileri içeren dizinin adıyla değiştirin.Yer tutucuyu
<destination_directory>, verilerinizi kopyalamak istediğiniz dizinin adıyla değiştirin.
-libjarsseçeneği,hadoop-azure*.jarve bağımlıazure-storage*.jardosyalarınıdistcpiçin kullanılabilir hale getirmek amacıyla kullanılır. Bazı kümeler için bu, zaten gerçekleşebilir.Aşağıdaki örnekte, komutun
distcpverileri kopyalamak için nasıl kullanıldığı gösterilmektedir.hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/dataKopyalama hızını artırmak için:
Eşleştirici sayısını değiştirmeyi deneyin. (Varsayılan eşleştirici sayısı 20'dir. Yukarıdaki örnekte = 4 eşleyici kullanılır
m.)Deneyin
-D fs.azure.concurrentRequestCount.out=<thread_number>. değerini eşleyici başına iş parçacığı sayısıyla değiştirin<thread_number>. Eşleyici sayısının ve eşleyici başınam*<thread_number>iş parçacığı sayısının çarpımının 32'yi aşmaması gerekir.Birden çok
distcpöğesini paralel olarak çalıştırmayı deneyin.Büyük dosyaların küçük dosyalardan daha iyi performans sergilediğini unutmayın.
200 GB'tan büyük dosyalarınız varsa, aşağıdaki parametrelerle blok boyutunu 100 MB olarak değiştirmenizi öneririz:
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
Data Box'ı Microsoft'a gönderme
Data Box cihazını hazırlamak ve Microsoft'a göndermek için bu adımları izleyin.
İlk olarak, Data Box veya Data Box Heavy'nizde gönderim için hazırlanın.
Cihaz hazırlığı tamamlandıktan sonra BOM dosyalarını indir. Daha sonra Azure'a yüklenen verileri doğrulamak için bu BOM veya manifest dosyalarını kullanırsınız.
Cihazı kapatın ve kabloları çıkarın.
UPS ile teslim alma zamanı planlayın.
Data Box cihazları için bkz Data Box'unuzu Gönderme.
Data Box Heavy cihazları için 'Data Box Heavy'i Gönderme' kısmına bakın.
Microsoft cihazınızı aldıktan sonra veri merkezi ağına bağlanır ve veriler, cihaz siparişini gönderdiğinizde belirttiğiniz depolama hesabına yüklenir. Ürün reçetesi dosyalarında tüm verilerinizin Azure'a yüklendiğini doğrulayın.
Dosyalara ve dizinlere erişim izinleri uygulama (yalnızca Data Lake Storage)
Veriler Azure Depolama hesabınızda zaten var. Artık dosyalara ve dizinlere erişim izinleri uygulayacaksınız.
Not
Bu adım yalnızca veri deponuz olarak Azure Data Lake Storage kullanıyorsanız gereklidir. Veri deponuz olarak hiyerarşik ad alanı olmayan yalnızca bir blob depolama hesabı kullanıyorsanız, bu bölümü atlayabilirsiniz.
Azure Data Lake Storage özellikli hesabınız için hizmet sorumlusu oluşturma
Hizmet sorumlusu oluşturmak için bkz . Nasıl yapılır: Kaynaklara erişebilen bir Microsoft Entra uygulaması ve hizmet sorumlusu oluşturmak için portalı kullanma.
Makalenin Uygulamayı bir role atama bölümündeki adımları gerçekleştirirken, Depolama Blob Verileri Katkıda Bulunan rolünü hizmet sorumlusuna atadığınızdan emin olun.
Makalenin Oturum açmak için değerleri alma bölümündeki adımları gerçekleştirirken, uygulama kimliğini ve istemci gizli dizi değerlerini bir metin dosyasına kaydedin. Yakında lazım olacak.
İzinleriyle kopyalanan dosyaların listesini oluşturma
Şirket içi Hadoop kümesinden şu komutu çalıştırın:
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
Bu komut, izinleriyle kopyalanan dosyaların listesini oluşturur.
Not
HDFS'deki dosya sayısına bağlı olarak, bu komutun çalıştırılması uzun sürebilir.
Kimlik listesi oluşturma ve bunları Microsoft Entra kimliklerine eşleme
Betiği
copy-acls.pyindirin. Bu makalenin Yardımcı betikleri indirme ve bunları çalıştıracak şekilde kenar düğümünüzü ayarlama bölümüne bakın.Benzersiz kimliklerin listesini oluşturmak için bu komutu çalıştırın.
./copy-acls.py -s ./filelist.json -i ./id_map.json -gBu betik, ADD tabanlı kimliklerle eşlemeniz gereken kimlikleri içeren adlı
id_map.jsonbir dosya oluşturur.id_map.jsondosyasını bir metin düzenleyicisinde açın.tr-TR: Dosyada görünen her JSON nesnesi için, bir Microsoft Entra kullanıcı asıl adı (UPN) veya ObjectId (OID) özniteliğini uygun eşlenmiş kimlikle güncelleyiniz
target. İşiniz bittiğinde dosyayı kaydedin. Sonraki adımda bu dosyaya ihtiyacınız olacak.
Kopyalanan dosyalara izinler uygulama ve kimlik eşlemeleri uygulama
Data Lake Storage etkin hesabına kopyaladığınız verilere izinler uygulamak için şu komutu çalıştırın:
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
Yer tutucuyu
<storage-account-name>depolama hesabınızın adıyla değiştirin.Yer tutucuyu
<container-name>kapsayıcınızın adıyla değiştirin.<application-id>ve<client-secret>yer tutucularını, hizmet sorumlusunu oluştururken topladığınız uygulama kimliği ve istemci gizli anahtarıyla değiştirin.
Ek: Verileri birden çok Data Box cihazı arasında bölme
Verilerinizi bir Data Box cihazına taşımadan önce bazı yardımcı betikleri indirmeniz, verilerinizin bir Data Box cihazına sığacak şekilde düzenlendiğinden emin olmanız ve gereksiz dosyaları dışlamanız gerekir.
Yardımcı betikleri indirin ve uç düğümünüzü bunları çalıştıracak şekilde ayarlayın.
Şirket içi Hadoop kümenizin kenar veya baş düğümünden şu komutu çalıştırın:
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loaderBu komut, yardımcı betikleri içeren GitHub deposunu klonlar.
Yerel bilgisayarınızda yüklü olan jq paketinin bu olduğundan emin olun.
sudo apt-get install jqİstekler python paketini yükleyin.
pip install requestsGerekli betiklerde yürütme izinlerini ayarlayın.
chmod +x *.py *.sh
Verilerinizin bir Data Box cihazına sığacak şekilde düzenlendiğinden emin olun
Verilerinizin boyutu tek bir Data Box cihazının boyutunu aşarsa, dosyaları birden çok Data Box cihazına depolayabileceğiniz gruplara bölebilirsiniz.
Verileriniz tek bir Data Box cihazının boyutunu aşmazsa sonraki bölüme geçebilirsiniz.
Yükseltilmiş izinlerle, önceki bölümdeki
generate-file-listyönergeleri izleyerek indirdiğiniz betiği çalıştırın.Komut parametrelerinin açıklaması aşağıdadır:
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.Oluşturulan dosya listelerini HDFS'ye kopyalayarak DistCp işi tarafından erişilebilir olmasını sağlayın.
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
Gereksiz dosyaları dışlama
Bazı dizinleri DisCp işinin dışında tutmanız gerekir. Örneğin, kümeyi çalışır durumda tutan durum bilgileri içeren dizinleri hariç tutun.
DistCp işini başlatmayı planladığınız şirket içi Hadoop kümesinde, dışlamak istediğiniz dizinlerin listesini belirten bir dosya oluşturun.
Bir örnek aşağıda verilmiştir:
.*ranger/audit.*
.*/hbase/data/WALs.*
Sonraki adımlar
Data Lake Storage'ın HDInsight kümeleriyle nasıl çalıştığını öğrenin. Daha fazla bilgi için bkz . Azure HDInsight kümeleri ile Azure Data Lake Storage'ı kullanma.