Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Giriş doğrulama , ana sorgu mantığını hatalı biçimlendirilmiş veya beklenmeyen olaylara karşı korumak için kullanılan bir tekniktir. Sorgu, ana mantığı bozamamaları için kayıtları açıkça işleyip denetleyecek şekilde yükseltilir.
Giriş doğrulamasını uygulamak için sorguya iki başlangıç adımı ekleriz. İlk olarak temel iş mantığına gönderilen şemanın beklentileriyle eşleştiğinden emin olacağız. Ardından özel durumları önceliklendirmek ve isteğe bağlı olarak geçersiz kayıtları ikincil bir çıkışa yönlendirmek.
Giriş doğrulamalı bir sorgu aşağıdaki gibi yapılandırılır:
WITH preProcessingStage AS (
SELECT
-- Rename incoming fields, used for audit and debugging
field1 AS in_field1,
field2 AS in_field2,
...
-- Try casting fields in their expected type
TRY_CAST(field1 AS bigint) as field1,
TRY_CAST(field2 AS array) as field2,
...
FROM myInput TIMESTAMP BY myTimestamp
),
triagedOK AS (
SELECT -- Only fields in their new expected type
field1,
field2,
...
FROM preProcessingStage
WHERE ( ... ) -- Clauses make sure that the core business logic expectations are satisfied
),
triagedOut AS (
SELECT -- All fields to ease diagnostic
*
FROM preProcessingStage
WHERE NOT (...) -- Same clauses as triagedOK, opposed with NOT
)
-- Core business logic
SELECT
...
INTO myOutput
FROM triagedOK
...
-- Audit output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- To a storage adapter that doesn't require strong typing, here blob/adls
FROM triagedOut
Giriş doğrulama ile ayarlanmış kapsamlı bir sorgu örneğini görmek için şu bölüme bakın: Giriş doğrulamalı sorgu örneği.
Bu makalede bu tekniğin nasıl uygulandığı gösterilmektedir.
Bağlam
Azure Stream Analytics (ASA) işleri akışlardan gelen verileri işler. Akışlar, seri hale getirilmiş ham veri dizileridir (CSV, JSON, AVRO...). Bir akıştan okumak için uygulamanın kullanılan belirli serileştirme biçimini bilmesi gerekir. ASA'da akış girişi yapılandırırken olay serileştirme biçiminin tanımlanması gerekir.
Veriler seri durumdan çıkarıldıktan sonra, buna anlam kazandırmak için bir şemanın uygulanması gerekir. Şemaya göre akıştaki alanların listesini ve bunların ilgili veri türlerini ifade ediyoruz. ASA ile gelen verilerin şemasının giriş düzeyinde ayarlanması gerekmez. ASA bunun yerine dinamik giriş şemalarını yerel olarak destekler. Alanlar listesinin (sütunlar) ve bunların türlerinin olaylar (satırlar) arasında değişmesini bekler. ASA ayrıca, açıkça sağlanmayan veri türlerini de çıkartır ve gerektiğinde türleri örtük olarak atamaya çalışır.
Dinamik şema işleme , akış işleme için önemli olan güçlü bir özelliktir. Veri akışları genellikle her biri benzersiz bir şemaya sahip birden çok olay türüne sahip birden çok kaynaktan veriler içerir. Bu tür akışlardaki olayları yönlendirmek, filtrelemek ve işlemek için ASA'nın şemaları ne olursa olsun hepsini almaları gerekir.
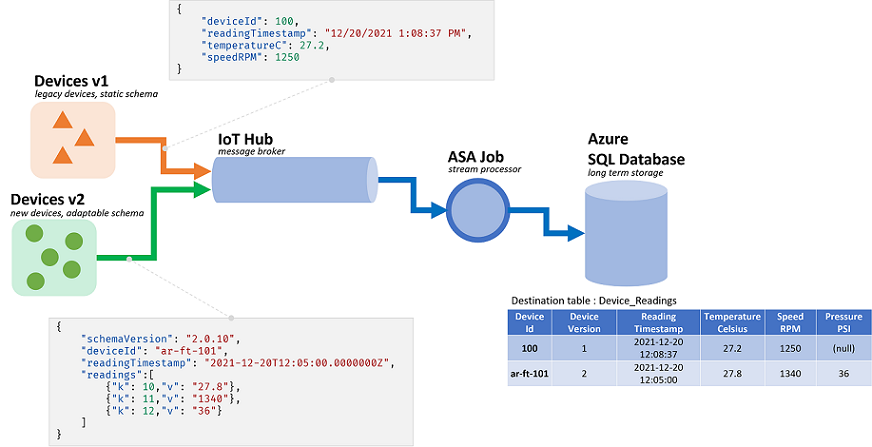
Ancak dinamik şema işleme tarafından sunulan özelliklerin olası bir dezavantajı vardır. Beklenmeyen olaylar ana sorgu mantığı üzerinden akıp bozabilir. Örneğin, türünde NVARCHAR(MAX)bir alanda ROUND kullanabiliriz. ASA, imzasıyla ROUNDeşleşecek şekilde örtük olarak float olarak yayınlar. Burada bu alanın her zaman sayısal değerler içermesini bekliyoruz. Ancak, alanı olarak ayarlanmış "NaN"bir olay aldığımızda veya alan tamamen eksikse, iş başarısız olabilir.
Giriş doğrulama ile, bu tür hatalı biçimlendirilmiş olayları işlemek için sorgumuza ön adımlar ekleriz. Bunu uygulamak için öncelikle WITH ve TRY_CAST kullanacağız.
Senaryo: Güvenilir olmayan olay üreticileri için giriş doğrulaması
Tek bir olay hub'ından veri alacak yeni bir ASA işi oluşturacağız. Çoğu durumda olduğu gibi veri üreticilerinden sorumlu değildir. Burada üreticiler, birden çok donanım satıcısı tarafından satılan IoT cihazlarıdır.
Proje katılımcılarıyla bir araya geldik, serileştirme biçimi ve şema üzerinde anlaşıyoruz. Tüm cihazlar bu tür iletileri ortak bir olay hub'ına( ASA işinin girişi) iletir.
Şema sözleşmesi aşağıdaki gibi tanımlanır:
| Alan adı | Alan türü | Alan açıklaması |
|---|---|---|
deviceId |
Tamsayı | Benzersiz cihaz tanımlayıcısı |
readingTimestamp |
Datetime | Merkezi ağ geçidi tarafından oluşturulan ileti süresi |
readingStr |
String | |
readingNum |
Sayısal | |
readingArray |
Dize Dizisi |
Bu da bize JSON serileştirmesi altında aşağıdaki örnek iletiyi verir:
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7,
"readingArray" : ["A","B"]
}
Şema sözleşmesi ve uygulaması arasında zaten bir tutarsızlık görebilirsiniz. JSON biçiminde datetime için veri türü yoktur. Dize olarak iletilir (yukarıya bakın readingTimestamp ). ASA sorunu kolayca giderebilir, ancak türleri doğrulama ve açıkça atama gereksinimini gösterir. Tüm değerler daha sonra dize olarak iletildiğinden CSV'de seri hale getirilmiş veriler için daha fazlası.
Başka bir tutarsızlık daha var. ASA, gelen sistemle eşleşmeyen kendi tür sistemini kullanır. ASA'da tamsayı (bigint), datetime, dize (nvarchar(max)) ve diziler için yerleşik türler varsa, yalnızca float aracılığıyla sayısalı destekler. Bu uyuşmazlık çoğu uygulama için sorun değildir. Ancak bazı uç durumlarda hassas bir şekilde hafif kaymalara neden olabilir. Bu durumda, sayısal değeri yeni bir alanda dize olarak dönüştürürdük. Ardından aşağı akış, olası kaymaları algılamak ve düzeltmek için sabit ondalık desteği olan bir sistem kullanırız.
Sorgumuza geri dönerek şunları yapmayı planlıyoruz:
- JavaScript UDF'ye geçirme
readingStr - Dizideki kayıt sayısını sayma
- İkinci ondalık basam aya yuvarla
readingNum - Verileri SQL tablosuna ekleme
Hedef SQL tablosu aşağıdaki şemaya sahiptir:
CREATE TABLE [dbo].[readings](
[Device_Id] int NULL,
[Reading_Timestamp] datetime2(7) NULL,
[Reading_String] nvarchar(200) NULL,
[Reading_Num] decimal(18,2) NULL,
[Array_Count] int NULL
) ON [PRIMARY]
İşin içinden geçerken her alana ne olacağını eşlemek iyi bir uygulamadır:
| Alan | Giriş (JSON) | Devralınan tür (ASA) | Çıkış (Azure SQL) | Yorum |
|---|---|---|---|---|
deviceId |
Numara | bigint | integer | |
readingTimestamp |
Dize | nvarchar(MAX) | datetime2 | |
readingStr |
Dize | nvarchar(MAX) | nvarchar(200) | UDF tarafından kullanılır |
readingNum |
Numara | kayan noktalı sayı | ondalık(18,2) | yuvarlanacak |
readingArray |
array(dize) | nvarchar(MAX) dizisi | integer | sayılacak |
Önkoşullar
Sorguyu Visual Studio Code'da ASA Araçları uzantısını kullanarak geliştireceğiz. Bu öğreticinin ilk adımları, gerekli bileşenleri yükleme konusunda size yol gösterir.
VS Code'da, herhangi bir maliyet doğurmamak ve hata ayıklama döngüsünü hızlandırmak için yerel giriş/çıkış ile yerel çalıştırmaları kullanacağız. Olay hub'ı veya Azure SQL Veritabanı ayarlamamız gerekmez.
Temel sorgu
Giriş doğrulaması olmadan temel bir uygulamayla başlayalım. Sonraki bölümde ekleyeceğiz.
VS Code'da yeni bir ASA projesi oluşturacağız
input klasöründe adlı data_readings.json yeni bir JSON dosyası oluşturacak ve bu dosyaya aşağıdaki kayıtları ekleyeceğiz:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingStr" : "Another String",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : -4.85436,
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : ["G","G"]
}
]
Ardından yukarıda oluşturduğumuz JSON dosyasına başvuran adlı readingsyerel bir giriş tanımlayacağız.
Yapılandırıldıktan sonra aşağıdaki gibi görünmelidir:
{
"InputAlias": "readings",
"Type": "Data Stream",
"Format": "Json",
"FilePath": "data_readings.json",
"ScriptType": "InputMock"
}
Önizleme verileriyle kayıtlarımızın düzgün yüklendiğini gözlemleyebiliriz.
Klasörüne sağ tıklayıp Functions öğesini seçerek ASA: Add Functionadlı udfLen yeni bir JavaScript UDF oluşturacağız. Kullanacağımız kod:
// Sample UDF that returns the length of a string for demonstration only: LEN will return the same thing in ASAQL
function main(arg1) {
return arg1.length;
}
Yerel çalıştırmalarda çıkışları tanımlamamız gerekmez. Birden fazla çıkış olmadığı sürece kullanmamız INTO bile gerekmez. .asaql dosyasında, var olan sorguyu şu şekilde değiştirebiliriz:
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
FROM readings AS r TIMESTAMP BY r.readingTimestamp
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
Şimdi gönderdiğimiz sorguyu hızla inceleyelim:
- Her dizideki kayıtların sayısını saymak için önce bunları açmamız gerekir. CROSS APPLY ve GetArrayElements() kullanacağız (burada daha fazla örnek var)
- Bunu yaptığınızda sorguda iki veri kümesi ortaya çıkarıyoruz: özgün giriş ve dizi değerleri. Alanları karıştırmadığınızdan emin olmak için diğer adlar (
AS r) tanımlar ve bunları her yerde kullanırız - Daha sonra dizi
COUNTdeğerleri için GROUP BY ile toplamamız gerekir - Bunun için bir zaman penceresi tanımlamamız gerekir. Burada mantığımız için gerekli olmadığından anlık görüntü penceresi doğru seçimdir
- Bunu yaptığınızda sorguda iki veri kümesi ortaya çıkarıyoruz: özgün giriş ve dizi değerleri. Alanları karıştırmadığınızdan emin olmak için diğer adlar (
- Ayrıca tüm alanlara ihtiyacımız
GROUP BYvar ve bunların tümünü içinde yansıtıyoruzSELECT. Alanları açıkça yansıtmak iyi bir uygulamadır;SELECT *hataların girişten çıkışa akmasına izin verir- Zaman penceresi tanımlarsak TIMESTAMP BY ile bir zaman damgası tanımlamak isteyebiliriz. Burada mantığımızın çalışması gerekli değildir. Yerel çalıştırmalar için, tüm kayıtlar tek bir zaman damgasına yüklenmeden
TIMESTAMP BYçalıştırma başlangıç saati.
- Zaman penceresi tanımlarsak TIMESTAMP BY ile bir zaman damgası tanımlamak isteyebiliriz. Burada mantığımızın çalışması gerekli değildir. Yerel çalıştırmalar için, tüm kayıtlar tek bir zaman damgasına yüklenmeden
- İkiden az karakteri olan
readingStrokumaları filtrelemek için UDF'yi kullanırız. Len'i burada kullanmalıyız. Yalnızca tanıtım amacıyla UDF kullanıyoruz
Bir çalıştırma başlatabilir ve işlenen verileri gözlemleyebiliriz:
| deviceId | readingTimestamp | readingStr | readingNum | arrayCount |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Dize | 1,71 | 2 |
| 2 | 2021-12-10T10:01:00 | Başka Bir Dize | 2.38 | 1 |
| 3 | 2021-12-10T10:01:20 | Üçüncü Dize | -4.85 | 3 |
| 1 | 2021-12-10T10:02:10 | A Forth Dizesi | 1.21 | 2 |
Artık sorgumuzun çalıştığını bildiğimize göre sorguyu daha fazla veriyle test edelim. öğesinin içeriğini data_readings.json aşağıdaki kayıtlara göre değiştirelim:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : "NaN",
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : {}
}
]
Burada aşağıdaki sorunları görebiliriz:
- Cihaz #1 her şeyi doğru yaptı
- 2. cihaz eklemeyi unuttu
readingStr - Numara olarak gönderilen
NaNcihaz #3 - #4 cihazı dizi yerine boş bir kayıt gönderdi
İşi şimdi çalıştırmanın iyi bitmemesi gerekir. Aşağıdaki hata iletilerinden birini alacağız:
Cihaz 2 bize şu şekilde verir:
[Error] 12/22/2021 10:05:59 PM : **System Exception** Function 'udflen' resulted in an error: 'TypeError: Unable to get property 'length' of undefined or null reference' Stack: TypeError: Unable to get property 'length' of undefined or null reference at main (Unknown script code:3:5)
[Error] 12/22/2021 10:05:59 PM : at Microsoft.EventProcessing.HostedRuntimes.JavaScript.JavaScriptHostedFunctionsRuntime.
Cihaz 3 bize şu şekilde verir:
[Error] 12/22/2021 9:52:32 PM : **System Exception** The 1st argument of function round has invalid type 'nvarchar(max)'. Only 'bigint', 'float' is allowed.
[Error] 12/22/2021 9:52:32 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Arithmetics.Round(CompilerPosition pos, Object value, Object length)
Cihaz 4 bize şu şekilde verir:
[Error] 12/22/2021 9:50:41 PM : **System Exception** Cannot cast value of type 'record' to type 'array' in expression 'r . readingArray'. At line '9' and column '30'. TRY_CAST function can be used to handle values with unexpected type.
[Error] 12/22/2021 9:50:41 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Cast.ToArray(CompilerPosition pos, Object value, Boolean isUserCast)
Yanlış biçimlendirilmiş kayıtların doğrulanmadan girişten ana sorgu mantığına akışına her izin verildiğinde. Şimdi giriş doğrulamanın değerini fark ettik.
Giriş doğrulamasını uygulama
Girişi doğrulamak için sorgumuzu genişletelim.
Giriş doğrulamanın ilk adımı, temel iş mantığının şema beklentilerini tanımlamaktır. Özgün gereksinime baktığımızda ana mantığımız şunları yapmaktır:
- Uzunluğunu ölçmek için JavaScript UDF'ye geçin
readingStr - Dizideki kayıt sayısını sayma
- İkinci ondalık basam aya yuvarla
readingNum - Verileri SQL tablosuna ekleme
Her nokta için beklentileri listeleyebiliriz:
- UDF, null olmayan bir tür dizesi (burada nvarchar(max) bağımsız değişkeni gerektirir
GetArrayElements()dizi türünde bir bağımsız değişken veya null değer gerektirirRoundbigint veya float türünde bir bağımsız değişken veya null değer gerektirir- ASA'nın örtük dökümlerine güvenmek yerine bunu kendimiz yapmalı ve sorgudaki tür çakışmalarını işlememiz gerekir
Bunun bir yolu, ana mantığı bu özel durumlarla başa çıkmak için uyarlamaktır. Ancak bu durumda, ana mantığımızın mükemmel olduğuna inanıyoruz. Şimdi bunun yerine gelen verileri doğrulayalım.
İlk olarak, sorgunun ilk adımı olarak bir giriş doğrulama katmanı eklemek için WITH kullanalım. Alanları beklenen türe dönüştürmek ve dönüştürme başarısız olursa olarak NULL ayarlamak için TRY_CAST kullanacağız:
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
)
-- For debugging only
SELECT * FROM readingsValidated
Kullandığımız son giriş dosyasıyla (hata içeren dosya), bu sorgu aşağıdaki kümeyi döndürür:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Dize | 1.7145 | ["A","B"] | 1 | 2021-12-10T10:00:00.0000000Z | Dize | 1.7145 | ["A","B"] |
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00.0000000Z | NULL | 2.378 | ["C"] |
| 3 | 2021-12-10T10:01:20 | Üçüncü Dize | Nan | ["D","E","F"] | 3 | 2021-12-10T10:01:20.0000000Z | Üçüncü Dize | NULL | ["D","E","F"] |
| 4 | 2021-12-10T10:02:10 | A Forth Dizesi | 1.2126 | {} | 4 | 2021-12-10T10:02:10.0000000Z | A Forth Dizesi | 1.2126 | NULL |
İki hatamızın giderildiğini zaten görebiliyoruz. ve {} içine NULLdönüştürdükNaN. Artık bu kayıtların hedef SQL tablosuna düzgün şekilde ekleneceğinden eminiz.
Şimdi eksik veya geçersiz değerlerle kayıtların nasıl ele alıneceğine karar vermemiz gerekiyor. Bir tartışmadan sonra, boş/geçersiz readingArray veya eksik readingStrolan kayıtları reddetmeye karar verdik.
Bu nedenle, doğrulama 1 ile ana mantık arasında kayıtları önceliklendirmek için ikinci bir katman ekleyeceğiz:
WITH readingsValidated AS (
...
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- For debugging only
SELECT * INTO Debug1 FROM readingsToBeProcessed
SELECT * INTO Debug2 FROM readingsToBeRejected
Her iki çıkış için de tek WHERE bir yan tümce yazmak ve ikincisinde kullanmak NOT (...) iyi bir uygulamadır. Bu şekilde hiçbir kayıt her iki çıkıştan da dışlanamaz ve kaybolabilir.
Şimdi iki çıkış elde ediyoruz. Debug1 , ana mantığa gönderilecek kayıtlara sahiptir:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00.0000000Z | Dize | 1.7145 | ["A","B"] |
| 3 | 2021-12-10T10:01:20.0000000Z | Üçüncü Dize | NULL | ["D","E","F"] |
Debug2'de reddedilecek kayıtlar var:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00.0000000Z | NULL | 2.378 | ["C"] |
| 4 | 2021-12-10T10:02:10 | A Forth Dizesi | 1.2126 | {} | 4 | 2021-12-10T10:02:10.0000000Z | A Forth Dizesi | 1.2126 | NULL |
Son adım, ana mantığımızı geri eklemektir. Ayrıca, reddetmeleri toplayan çıkışı da ekleyeceğiz. Burada, depolama hesabı gibi güçlü yazma zorlamayan bir çıkış bağdaştırıcısı kullanmak en iyisidir.
Sorgunun tamamı son bölümde bulunabilir.
WITH
readingsValidated AS (...),
readingsToBeProcessed AS (...),
readingsToBeRejected AS (...)
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
SELECT
*
INTO BlobOutput
FROM readingsToBeRejected
Bu, sqloutput için aşağıdaki kümeyi verir ve olası bir hata vermez:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00.0000000Z | Dize | 1.7145 | 2 |
| 3 | 2021-12-10T10:01:20.0000000Z | Üçüncü Dize | NULL | 3 |
Diğer iki kayıt, insan incelemesi ve işlem sonrası için bir BlobOutput'a gönderilir. Sorgumuz artık güvenli.
Giriş doğrulamalı sorgu örneği
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- Core business logic
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
-- Rejected output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- to a storage adapter that doesn't require strong typing, here blob/adls
FROM readingsToBeRejected
Giriş doğrulamasını genişletme
GetType , bir türü açıkça denetlemek için kullanılabilir. Projeksiyonda CASE veya ayarlanan düzeyde WHERE ile iyi çalışır. GetType gelen şemayı meta veri deposunda dinamik olarak denetlemek için de kullanılabilir. Depo bir başvuru veri kümesi aracılığıyla yüklenebilir.
Birim testi , sorgumuzun dayanıklı olduğundan emin olmak için iyi bir uygulamadır. Giriş dosyalarından ve beklenen çıktılarından oluşan bir dizi test oluşturacağız. Sorgumuzun geçirmek için oluşturduğu çıkışla eşleşmesi gerekir. ASA'da birim testi asa-streamanalytics-cicd npm modülü aracılığıyla yapılır. Çeşitli yanlış biçimlendirilmiş olaylara sahip test çalışmaları, dağıtım işlem hattında oluşturulup test edilmelidir.
Son olarak VS Code'da bazı basit tümleştirme testleri yapabiliriz. Canlı bir çıkışa yerel çalıştırma yoluyla SQL tablosuna kayıt ekleyebilirsiniz.
Destek alın
Daha fazla yardım için Azure Stream Analytics için Microsoft Soru-Cevap soru sayfamızı deneyin.
Sonraki adımlar
- npm paketini kullanarak CI/CD işlem hatlarını ve birim testini ayarlama
- ASA Araçları ile Visual Studio Code'da yerel Stream Analytics çalıştırmalarına genel bakış
- Visual Studio Code kullanarak örnek verilerle Stream Analytics sorgularını yerel olarak test edin
- Visual Studio Code kullanarak Stream Analytics sorgularını canlı akış girişlerinde yerel olarak test etme
- Visual Studio Code ile Azure Stream Analytics işlerini keşfetme (önizleme)