Synapse POC playbook'u: Azure Synapse Analytics'te Apache Spark havuzu ile büyük veri analizi
Bu makalede Apache Spark havuzu için etkili bir Azure Synapse Analytics kavram kanıtı (POC) projesi hazırlamaya ve çalıştırmaya yönelik üst düzey bir metodoloji sunun.
Not
Bu makale, Azure Synapse kavram kanıtı playbook makale serisinin bir bölümünü oluşturur. Seriye genel bakış için bkz . Azure Synapse kavram kanıtı playbook'u.
POC için hazırlanma
POC projesi, Azure Synapse'te Apache Spark havuzundan yararlanan bulut tabanlı bir platformda büyük veri ve gelişmiş analiz ortamı uygulama konusunda bilinçli bir iş kararı alma konusunda size yardımcı olabilir.
POC projesi, bulut tabanlı büyük veri ve gelişmiş analiz platformlarının desteklemesi gereken temel hedeflerinizi ve iş etmenlerinizi belirler. Önemli ölçümleri test edecek ve veri mühendisliği, makine öğrenmesi modeli oluşturma ve eğitim gereksinimlerinizin başarısı için kritik öneme sahip önemli davranışları kanıtlayacak. POC, üretim ortamına dağıtılacak şekilde tasarlanmamıştır. Bunun yerine, önemli sorulara odaklanan kısa vadeli bir projedir ve sonucu atılabilir.
Spark POC projenizi planlamaya başlamadan önce:
- Kuruluşunuzun verileri buluta taşımayla ilgili tüm kısıtlamalarını veya yönergelerini belirleyin.
- Büyük veri ve gelişmiş analiz platformu projesi için yönetici veya iş sponsorlarını belirleme. Buluta geçiş için desteklerinin güvenliğini sağlayın.
- POC yürütmesi sırasında sizi destekleyecek teknik uzmanların ve iş kullanıcılarının kullanılabilirliğini belirleyin.
POC projesine hazırlanmaya başlamadan önce Apache Spark belgelerini okumanızı öneririz.
İpucu
Spark havuzlarını kullanmaya yeniyseniz Azure Synapse Apache Spark Havuzları ile veri mühendisliği gerçekleştirme öğrenme yolu üzerinde çalışmanızı öneririz.
Şimdiye kadar hemen engelleyici olmadığını belirlemiş olmanız gerekir ve ardından POC'niz için hazırlanmaya başlayabilirsiniz. Azure Synapse Analytics'te Apache Spark Havuzları'nı kullanmaya yeniyseniz, Spark mimarisine genel bir bakış elde edip Azure Synapse'te nasıl çalıştığını öğrenebileceğiniz bu belgelere bakabilirsiniz.
Bu temel kavramlar hakkında bir anlayış geliştirin:
- Apache Spark ve dağıtılmış mimarisi.
- Dayanıklı Dağıtılmış Veri Kümeleri (RDD) ve bölümler (bellek içi ve fiziksel) gibi Spark kavramları.
- Azure Synapse çalışma alanı, farklı işlem altyapıları, işlem hattı ve izleme.
- Spark havuzundaki işlem ve depolamanın ayrılması.
- Azure Synapse'te kimlik doğrulaması ve yetkilendirme.
- Azure Synapse ayrılmış SQL havuzu, Azure Cosmos DB ve diğerleriyle tümleşen yerel bağlayıcılar.
Azure Synapse, veri işleme gereksinimlerinizi daha iyi yönetebilmeniz ve maliyetleri denetleyebilmeniz için işlem kaynaklarını depolama alanından ayırır. Spark havuzunun sunucusuz mimarisi, spark kümenizi depolama alanınızdan bağımsız olarak büyütmenize ve küçültmenize olanak tanır. Spark kümesini tamamen duraklatabilir (veya otomatik duraklatma ayarlayabilirsiniz). Bu şekilde işlem için yalnızca kullanımda olduğunda ödemeniz gerekir. Kullanımda olmadığında yalnızca depolama alanı için ödeme alırsınız. Yoğun veri işleme gereksinimleri veya büyük yükler için Spark kümenizin ölçeğini artırabilir ve daha az yoğun işlem sürelerinde ölçeğini geri küçültebilirsiniz (veya tamamen kapatabilirsiniz). Maliyetleri azaltmak için kümeyi etkili bir şekilde ölçeklendirebilir ve duraklatabilirsiniz. Spark POC testleriniz, farklı ölçekte fiyat ve performansı karşılaştırmak için farklı ölçeklerde (küçük, orta ve büyük) veri alımını ve veri işlemeyi içermelidir. Daha fazla bilgi için bkz . Azure Synapse Analytics Apache Spark havuzlarını otomatik olarak ölçeklendirme.
Senaryonuz için en iyi sonucu verebilmeniz için farklı Spark API'leri kümeleri arasındaki farkı anlamanız önemlidir. Ekibinizin mevcut beceri kümelerinden yararlanarak daha iyi performans veya kullanım kolaylığı sağlayan birini seçebilirsiniz. Daha fazla bilgi için bkz . Üç Apache Spark API'sinin Hikayesi: RDD'ler, Veri Çerçeveleri ve Veri Kümeleri.
Veri ve dosya bölümleme Spark'ta biraz farklı çalışır. Farklılıkları anlamak, performansı iyileştirmenize yardımcı olur. Daha fazla bilgi için bkz. Apache Spark belgeleri: Bölüm Bulma ve Bölüm Yapılandırma Seçenekleri.
Hedefleri belirleme
Başarılı bir POC projesi planlama gerektirir. Gerçek motivasyonları tam olarak anlamak için neden poc yaptığınızı belirleyerek başlayın. Motivasyonlar arasında modernleştirme, maliyet tasarrufu, performans geliştirme veya tümleşik deneyim sayılabilir. POC'nizin net hedeflerini ve başarısını tanımlayacak ölçütleri belgelemeye özen gösterin. Kendinize sorun:
- POC'nizin çıktıları olarak ne istiyorsunuz?
- Bu çıkışlarla ne yapacaksınız?
- Çıkışları kimler kullanacak?
- Başarılı bir POC'nin tanımlaması nedir?
PoC'nin sınırlı bir kavram ve yetenek kümesini hızla kanıtlamak için kısa ve odaklanmış bir çaba olması gerektiğini unutmayın. Bu kavramlar ve özellikler, genel iş yükünü temsil etmelidir. Kanıtlayacak uzun bir öğe listenize sahipseniz, birden fazla POC planlamak isteyebilirsiniz. Bu durumda, bir sonrakiyle devam etmeniz gerekip gerekmediğini belirlemek için POC'ler arasındaki geçitleri tanımlayın. Azure Synapse'te Spark havuzlarını ve not defterlerini kullanabilen farklı profesyonel roller göz önünde bulundurulduğunda, birden çok POC yürütmeyi seçebilirsiniz. Örneğin, bir POC veri mühendisliği rolüne yönelik alım ve işleme gibi gereksinimlere odaklanabilir. Başka bir POC, makine öğrenmesi (ML) modeli geliştirmeye odaklanabilir.
POC hedeflerinizi göz önünde bulundurarak hedefleri şekillendirmenize yardımcı olmak için kendinize aşağıdaki soruları sorun:
- Mevcut büyük veri ve gelişmiş analiz platformundan (şirket içi veya bulut) geçiş mi gerçekleştiriyorsunuz?
- Geçiş yapıyor ancak mevcut alım ve veri işlemede mümkün olduğunca az değişiklik yapmak mı istiyorsunuz? Örneğin, Spark'ı Spark'a geçirme veya Hadoop/Hive'ı Spark'a geçirme.
- Geçiş yapıyor ancak yol boyunca bazı kapsamlı geliştirmeler yapmak mı istiyorsunuz? Örneğin, MapReduce işlerini Spark işleri olarak yeniden yazın veya eski RDD tabanlı kodu DataFrame/Dataset tabanlı koda dönüştürün.
- Tamamen yeni bir büyük veri ve gelişmiş analiz platformu (greenfield projesi) mi oluşturuyorsunuz?
- Şu anki ağrı noktalarınız nelerdir? Örneğin, ölçeklenebilirlik, performans veya esneklik.
- Hangi yeni iş gereksinimlerini desteklemeniz gerekiyor?
- Karşılamanız gereken SLA'lar nelerdir?
- İş yükleri ne olacak? Örneğin ETL, toplu işlem, akış işleme, makine öğrenmesi modeli eğitimi, analiz, raporlama sorguları veya etkileşimli sorgular?
- Projenin sahibi olacak kullanıcıların becerileri nelerdir (POC uygulanmalıdır)? Örneğin, PySpark ve Scala becerileri, not defteri ve IDE deneyimi.
POC hedef ayarına bazı örnekler aşağıda verilmiştir:
- Neden poc yapıyoruz?
- Büyük veri iş yükümüz için veri alımı ve işleme performansının yeni SLA'larımıza uygun olacağını bilmemiz gerekir.
- Gerçek zamanlıya yakın akış işlemenin mümkün olup olmadığını ve ne kadar aktarım hızını destekleyebileceğinizi bilmemiz gerekir. (İş gereksinimlerimizi destekleyecek mi?)
- Mevcut veri alımı ve dönüştürme süreçlerimizin uygun olup olmadığını ve iyileştirmelerin nerede yapılması gerektiğini bilmemiz gerekiyor.
- Veri tümleştirme çalışma sürelerimizi ne kadar kısaltıp kısaltamadığını bilmemiz gerekir.
- Veri bilimcilerimizin makine öğrenmesi modelleri oluşturup eğitip eğitemediğini ve Spark havuzunda gerektiğinde yapay zeka/ML kitaplıklarını kullanıp yararlanamadığını bilmemiz gerekir.
- Bulut tabanlı Synapse Analytics'e geçiş, maliyet hedeflerimizi karşılayacak mı?
- Bu POC'nin sonunda:
- Veri işleme performansı gereksinimlerimizin hem toplu hem de gerçek zamanlı akış için karşılanıp karşılanmayacağını belirlemek için gerekli verilere sahip olacağız.
- Kullanım örneklerimizi destekleyen tüm farklı veri türlerimizin (yapılandırılmış, yarı ve yapılandırılmamış) alımını ve işlenmesini test edeceğiz.
- Mevcut karmaşık veri işlemelerimizden bazılarını test edeceğiz ve veri tümleştirme portföyümüzü yeni ortama geçirmek için tamamlanması gereken işleri belirleyebiliriz.
- Veri alımını ve işlenmesini test ettik ve geçmiş verilerin ilk geçişi ve yükü için gereken çabayı tahmin etmek ve veri alımımızı (Azure Data Factory (ADF), Distcp, Databox veya diğerleri) geçirmek için gereken çabayı tahmin etmek için veri noktalarına sahip olacağız.
- Veri alımını ve işlenmesini test ettik ve ETL/ELT işleme gereksinimlerimizin karşılanıp karşılanmadığını belirleyebiliriz.
- Uygulama projesini tamamlamak için gereken çabayı daha iyi tahmin etmek için içgörü elde etmiş olacağız.
- Ölçeklendirme ve ölçeklendirme seçeneklerini test ettik ve platformumuzu daha iyi fiyat-performans ayarları için daha iyi yapılandırmak için veri noktalarına sahip olacağız.
- Daha fazla teste ihtiyaç duyabilecek öğelerin bir listesi olacak.
Projeyi planlama
Belirli testleri tanımlamak ve tanımladığınız çıkışları sağlamak için hedeflerinizi kullanın. Her hedefi ve beklenen çıkışı desteklemek için en az bir teste sahip olduğunuzdan emin olmak önemlidir. Ayrıca, belirli bir veri kümesini ve kod tabanını tanımlayabilmeniz için belirli veri alımını, toplu veya akış işlemeyi ve yürütülecek diğer tüm işlemleri tanımlayın. Bu belirli veri kümesi ve kod tabanı POC'nin kapsamını tanımlar.
Planlamada gereken ayrıntı düzeyine bir örnek aşağıda verilmiştir:
- Y. Hedef: Veri alımı ve toplu veri işleme gereksinimimizin tanımlı SLA'mız kapsamında karşılanıp karşılanamayacağını bilmemiz gerekir.
- Y Çıktısı: Toplu veri alımımızın ve işlememizin veri işleme gereksinimini ve SLA'yı karşılayıp karşılamadığını belirlemek için gerekli verilere sahip olacağız.
- Test A1: A, B ve C sorgularının işlenmesi, veri mühendisliği ekibi tarafından yaygın olarak yürütülen iyi performans testleri olarak tanımlanır. Ayrıca, genel veri işleme gereksinimlerini temsil ederler.
- Test A2: X, Y ve Z sorgularının işlenmesi, neredeyse gerçek zamanlı akış işleme gereksinimleri içerdiği için iyi performans testleri olarak tanımlanır. Ayrıca, genel olay tabanlı akış işleme gereksinimlerini temsil ederler.
- Test A3: Spark kümesinin farklı ölçeğinde (çalışan düğümlerinin sayısı, çalışan düğümlerinin boyutu (küçük, orta ve büyük gibi) bu sorguların performansını mevcut sistemden elde edilen karşılaştırmayla karşılaştırın. Azalan getiriler yasasını göz önünde bulundurun; daha fazla kaynak eklemek (ölçeği artırarak veya genişleterek) paralellik elde etmeye yardımcı olabilir, ancak paralelliği elde etmek için her senaryo için benzersiz olan belirli bir sınır vardır. Testinizde tanımlanan her kullanım örneği için en uygun yapılandırmayı keşfedin.
- Hedef B: Veri bilimcilerimizin bu platformda makine öğrenmesi modelleri oluşturup eğitemediğini bilmemiz gerekiyor.
- B Çıktısı: Bazı makine öğrenmesi modellerimizi Spark havuzundaki veya SQL havuzundaki veriler üzerinde eğiterek ve farklı makine öğrenmesi kitaplıklarından yararlanarak test etmiş olacağız. Bu testler, hangi makine öğrenmesi modellerinin yeni ortama geçirilebileceğini belirlemeye yardımcı olur
- Test B1: Belirli makine öğrenmesi modelleri test edilecek.
- Test B2: Spark (Spark MLLib) ile birlikte gelen temel makine öğrenmesi kitaplıklarının yanı sıra gereksinimi karşılamak için Spark'a yüklenebilen ek bir kitaplık (scikit-learn gibi) test edin.
- Hedef C: Veri alımını test etmiş olacağız ve veri noktalarına sahip olacağız:
- Data Lake'e ve/veya Spark havuzuna ilk geçmiş veri geçişi için harcanan çabayı tahmin edin.
- Geçmiş verileri geçirmek için bir yaklaşım planlayın.
- Çıkış C: Ortamımızda ulaşılabilen veri alma oranını test edip belirleyeceğiz ve veri alma oranımızın kullanılabilir zaman penceresinde geçmiş verileri geçirmek için yeterli olup olmadığını belirleyebiliriz.
- Test C1: Geçmiş veri geçişinin farklı yaklaşımlarını test edin. Daha fazla bilgi için bkz . Azure'a ve Azure'dan veri aktarma.
- Test C2: ExpressRoute'un ayrılmış bant genişliğini ve altyapı ekibi tarafından herhangi bir azaltma kurulumu olup olmadığını belirleyin. Daha fazla bilgi için bkz. Azure ExpressRoute nedir? (Bant genişliği seçenekleri).
- Test C3: Hem çevrimiçi hem de çevrimdışı veri geçişi için veri aktarım hızını test edin. Daha fazla bilgi için Kopyalama etkinliği performans ve ölçeklenebilirlik kılavuzuna bakın.
- Test C4: ADF, Polybase veya COPY komutunu kullanarak veri gölünden SQL havuzuna veri aktarımını test edin. Daha fazla bilgi için bkz . Azure Synapse Analytics'te ayrılmış SQL havuzu için veri yükleme stratejileri.
- Hedef D: Artımlı veri yüklemenin veri alma oranını test etmiş olacağız ve veri alımını ve veri gölüne ve/veya ayrılmış SQL havuzuna veri alma ve işleme zaman penceresini tahmin etmek için veri noktalarına sahip olacağız.
- D Çıktısı: Veri alımı oranını test etmiş olacağız ve belirlenen yaklaşımla veri alımı ve işleme gereksinimlerimizin karşılanıp karşılanmayacağını belirleyebiliriz.
- Test D1: Günlük güncelleştirme verilerinin alımını ve işlenmesini test edin.
- Test D2: Spark havuzundan ayrılmış SQL havuzu tablosuna işlenen veri yükünü test edin. Daha fazla bilgi için bkz . Apache Spark için Azure Synapse Ayrılmış SQL Havuzu Bağlayıcısı.
- Test D3: Son kullanıcı sorgularını çalıştırırken günlük güncelleştirme yükleme işlemini eşzamanlı olarak yürütür.
Birden çok test senaryosu ekleyerek testlerinizi daraltmaya özen gösterin. Azure Synapse, performansı ve davranışı karşılaştırmak için farklı ölçeği (değişen çalışan düğüm sayısı, küçük, orta ve büyük gibi çalışan düğümlerinin boyutunu) test etmek kolaylaştırır.
Bazı test senaryoları şunlardır:
- Spark havuzu testi A: Veri işlemeyi birden çok düğüm türünde (küçük, orta ve büyük) ve farklı sayıda çalışan düğümünde yürüteceğiz.
- Spark havuzu testi B: Bağlayıcıyı kullanarak işlenmiş verileri Spark havuzundan ayrılmış SQL havuzuna yükleyeceğiz/ayacağız.
- Spark havuzu testi C: İşlenen verileri Spark havuzundan Azure Synapse Link aracılığıyla Azure Cosmos DB'ye yükleyeceğiz/ayacağız.
POC veri kümesini değerlendirme
Tanımladığınız belirli testleri kullanarak testleri desteklemek için bir veri kümesi seçin. Bu veri kümesini gözden geçirmek için zaman ayır. Veri kümesinin içerik, karmaşıklık ve ölçek açısından gelecekteki işlemlerinizi yeterince temsil ettiğini doğrulamanız gerekir. Temsili performans sağlamayacağından çok küçük (1 TB'tan küçük) bir veri kümesi kullanmayın. Buna karşılık poc tam veri geçişi olmamalıdır çünkü çok büyük bir veri kümesi kullanmayın. Performans karşılaştırmaları için kullanabilmeniz için mevcut sistemlerden uygun karşılaştırmaları edindiğinizden emin olun.
Önemli
Verileri buluta taşımadan önce işletme sahiplerine engelleyicileri denetlediğinizden emin olun. Verileri buluta taşımadan önce yapılması gereken güvenlik veya gizlilik endişelerini veya veri gizleme gereksinimlerini belirleyin.
Üst düzey mimari oluşturma
Önerilen gelecekteki durum mimarinizin üst düzey mimarisine bağlı olarak, POC'nizin bir parçasını oluşturacak bileşenleri belirleyin. Gelecekteki üst düzey durum mimariniz büyük olasılıkla birçok veri kaynağı, çok sayıda veri tüketicisi, büyük veri bileşeni ve makine öğrenmesi ile yapay zeka (AI) veri tüketicileri içerir. POC mimariniz özellikle POC'nin parçası olacak bileşenleri tanımlamalıdır. Daha da önemlisi, POC testinin bir parçası olmayacak bileşenleri tanımlamalıdır.
Zaten Azure kullanıyorsanız, POC sırasında kullanabileceğiniz tüm kaynakları (Microsoft Entra ID, ExpressRoute ve diğerleri) tanımlayın. Ayrıca kuruluşunuzun kullandığı Azure bölgelerini de belirleyin. Şimdi ExpressRoute bağlantınızın aktarım hızını belirlemek ve diğer iş kullanıcılarıyla POC'nizin üretim sistemlerini olumsuz etkilemeden bu aktarım hızının bir kısmını tüketebileceğini denetlemek için harika bir zamandır.
Daha fazla bilgi için bkz . Büyük veri mimarileri.
POC kaynaklarını tanımlama
POC'nizi desteklemek için gereken teknik kaynakları ve zaman taahhütlerini özel olarak belirleyin. POC'niz için gerekenler:
- Gereksinimleri ve sonuçları denetlemek için bir iş temsilcisi.
- PoC verilerini kaynak olarak kullanan ve mevcut süreçler ve mantık hakkında bilgi sağlayan bir uygulama veri uzmanı.
- Apache Spark ve Spark havuzu uzmanı.
- POC testlerini iyileştirmek için uzman bir danışman.
- POC projenizin belirli bileşenleri için gerekli olan ancak POC süresi boyunca gerekli olması gerekmeyen kaynaklar. Bu kaynaklar arasında ağ yöneticileri, Azure yöneticileri, Active Directory yöneticileri, Azure portalı yöneticileri ve diğerleri yer alabilir.
- Depolama hesaplarına erişim de dahil olmak üzere tüm gerekli Azure hizmetleri kaynaklarının sağlandığından ve gerekli erişim düzeyinin verildiğinden emin olun.
- POC kapsamındaki tüm veri kaynaklarından veri almak için gerekli veri erişim izinlerine sahip bir hesabınız olduğundan emin olun.
İpucu
POC'nize yardımcı olması için bir uzman danışmanıyla etkileşime geçilmesi önerilir. Microsoft'un iş ortağı topluluğu , Azure Synapse'i değerlendirmenize, değerlendirmenize veya uygulamanıza yardımcı olabilecek uzman danışmanların küresel kullanılabilirliğine sahiptir.
Zaman çizelgesini ayarlama
POC'nizin zaman dilimini belirlemek için POC planlama ayrıntılarınızı ve iş gereksinimlerinizi gözden geçirin. POC hedeflerini tamamlamak için gereken süreyle ilgili gerçekçi tahminler yapın. POC'nizi tamamlama süresi POC veri kümenizin boyutundan, testlerin sayısı ve karmaşıklığından ve test edilecek arabirim sayısından etkilenir. POC'nizin dört haftadan uzun süre çalışacağını tahmin ediyorsanız, en yüksek öncelikli hedeflere odaklanmak için POC kapsamını azaltmayı göz önünde bulundurun. Devam etmeden önce tüm müşteri aday kaynaklarından ve sponsorlardan onay ve taahhüt almayı unutmayın.
POC'yi uygulamaya alma
POC projenizi herhangi bir üretim projesinin disiplini ve titizliğiyle yürütmenizi öneririz. POC kapsamının kontrolsüz büyümesini önlemek için projeyi planlayın ve bir değişiklik isteği süreci yönetin.
Üst düzey görevlere bazı örnekler aşağıda verilmiştir:
PoC planında tanımlanan bir Synapse çalışma alanı, Spark havuzları ve ayrılmış SQL havuzları, depolama hesapları ve tüm Azure kaynakları oluşturun.
POC veri kümesini yükleme:
- Kaynaktan ayıklayarak veya Azure'da örnek veriler oluşturarak verileri Azure'da kullanılabilir hale getirin. Daha fazla bilgi için, şuraya bakın:
- Ayrılmış bağlayıcıyı Spark havuzu ve ayrılmış SQL havuzu için test edin.
Mevcut kodu Spark havuzuna geçirin:
- Spark'tan geçiş gerçekleştiriyorsanız, Spark havuzunun açık kaynak Spark dağıtımından yararlanması nedeniyle geçiş çabanız büyük olasılıkla kolay olacaktır. Ancak, temel Spark özelliklerinin üzerinde satıcıya özgü özellikleri kullanıyorsanız, bu özellikleri Spark havuzu özellikleriyle doğru bir şekilde eşlemeniz gerekir.
- Spark olmayan bir sistemden geçiş gerçekleştiriyorsanız, geçiş çabanız söz konusu karmaşıklık düzeyine göre değişir.
Testleri yürüt:
- Birçok test birden çok Spark havuzu kümesi arasında paralel olarak yürütülebilir.
- Sonuçlarınızı tüketilebilir ve kolayca anlaşılabilen bir biçimde kaydedin.
Sorun giderme ve performans için izleyin. Daha fazla bilgi için bkz.
Spark'ın geçmiş sunucusunun Tanılama sekmesini açarak veri dengesizliğini, zaman dengesizliğini ve yürütücü kullanım yüzdesini izleyin.
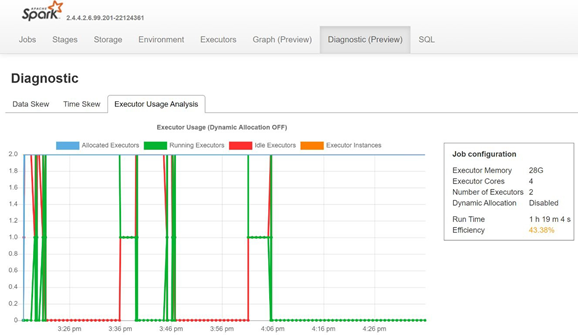
POC sonuçlarını yorumlama
Tüm POC testlerini tamamladığınızda sonuçları değerlendirirsiniz. POC hedeflerinin karşılanıp karşılanmadığını ve istenen çıkışların toplanıp toplanmadığını değerlendirerek başlayın. Daha fazla test gerekip gerekmediğini veya herhangi bir sorunun ele alınması gerekip gerekmediğini belirleyin.