Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu hızlı başlangıçta, web araçlarını kullanarak Azure Synapse'te sunucusuz Apache Spark havuzu oluşturmayı öğreneceksiniz. Ardından Apache Spark havuzuna bağlanmayı ve dosyalara ve tablolara karşı Spark SQL sorguları çalıştırmayı öğrenirsiniz. Apache Spark, bellek içi işlemeyi kullanarak hızlı veri analizi ve küme bilişimi sağlar. Azure Synapse'te Spark hakkında bilgi için bkz . Genel Bakış: Azure Synapse'te Apache Spark.
Önemli
Spark örnekleri için faturalandırma, kullansanız da kullanmasanız da dakika başına orantılı olarak ücretlendirilir. Spark örneğinizi kullanmayı tamamladıktan sonra kapatdığınızdan veya kısa bir zaman aşımı ayarladığınızdan emin olun. Daha fazla bilgi için bu makalenin Kaynakları temizleme bölümüne bakın.
Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun.
Önkoşullar
- Bir Azure aboneliğine sahip olmanız gerekir. Gerekirse ücretsiz bir Azure hesabı oluşturun
- Synapse Analytics çalışma alanı
- Sunucusuz Apache Spark havuzu
Azure portalında oturum açma
Azure portalınaoturum açın.
Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir Azure hesabı oluşturun.
Not defteri oluşturma
Not defteri, çeşitli programlama dillerini destekleyen etkileşimli bir ortamdır. Not defteri verilerinizle etkileşim kurmanıza, kodu markdown, metinle birleştirmenize ve basit görselleştirmeler gerçekleştirmenize olanak tanır.
Kullanmak istediğiniz Azure Synapse çalışma alanının Azure portalı görünümünde Synapse Studio'yu Başlat'ı seçin.
Synapse Studio başlatıldıktan sonra Geliştir'i seçin. Ardından yeni bir kaynak eklemek için "+" simgesini seçin.
Buradan Not Defteri'ni seçin. Yeni bir not defteri oluşturulur ve otomatik olarak oluşturulan bir adla açılır.

Özellikler penceresinde not defteri için bir ad belirtin.
Araç çubuğunda Yayımla'ya tıklayın.
Çalışma alanınızda yalnızca bir Apache Spark havuzu varsa, bu havuz varsayılan olarak seçilir. Hiçbiri seçili değilse doğru Apache Spark havuzunu seçmek için açılan listeyi kullanın.
Kod ekle'ye tıklayın. Varsayılan dil:
Pyspark. Pyspark ve Spark SQL'in bir karışımını kullanacaksınız, bu nedenle varsayılan seçenek uygundur. Desteklenen diğer diller Scala ve Spark için .NET'tir.Ardından, işlemek için basit bir Spark DataFrame nesnesi oluşturacaksınız. Bu durumda koddan oluşturursunuz. Üç satır ve üç sütun vardır:
new_rows = [('CA',22, 45000),("WA",35,65000) ,("WA",50,85000)] demo_df = spark.createDataFrame(new_rows, ['state', 'age', 'salary']) demo_df.show()Şimdi aşağıdaki yöntemlerden birini kullanarak hücreyi çalıştırın:
SHIFT + ENTER tuşlarına basın.
Hücrenin solundaki mavi oynatma simgesini seçin.
Araç çubuğunda Tümünü çalıştır düğmesini seçin.
Apache Spark havuz örneği zaten çalışmıyorsa otomatik olarak başlatılır. Apache Spark havuzu örneği durumunu, çalıştırdığınız hücrenin altında ve not defterinin altındaki durum panelinde görebilirsiniz. Havuzun boyutuna bağlı olarak, başlatma 2-5 dakika sürmelidir. Kodun çalışması tamamlandıktan sonra, hücrenin altındaki bilgiler çalıştırmanın ne kadar sürdüğünü ve yürütülmenin detaylarını gösterir. Çıkış hücresinde çıkışı görürsünüz.
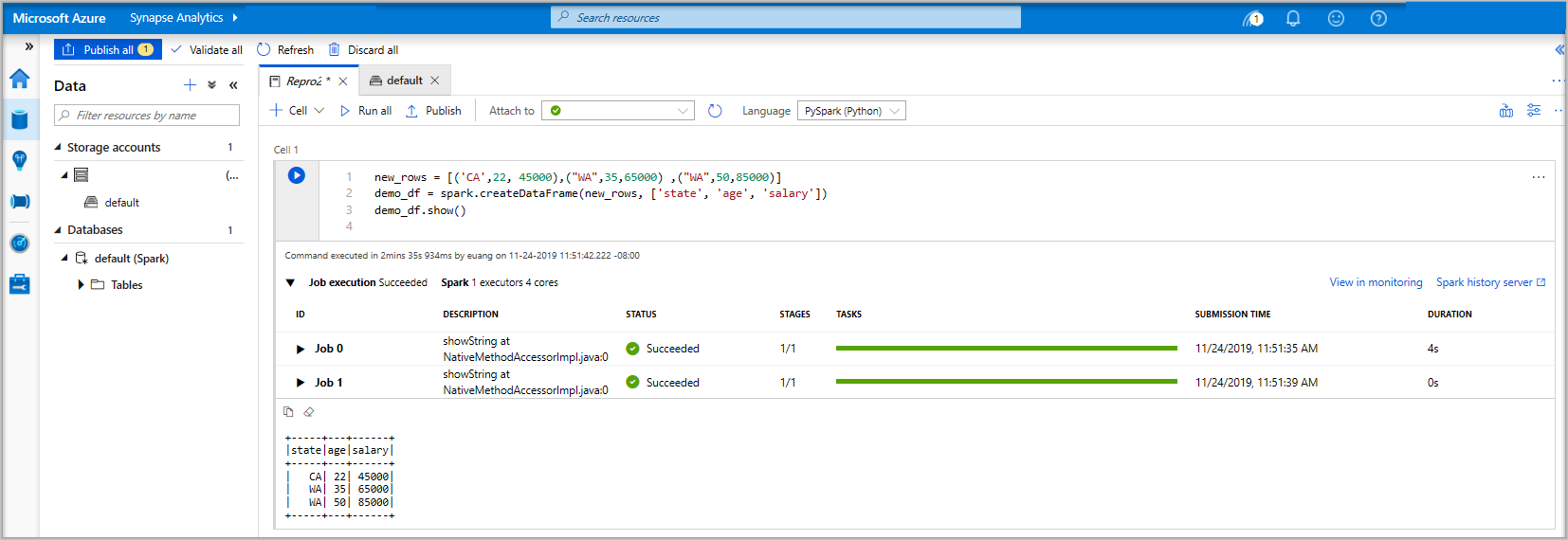
Veriler artık bir DataFrame'de yer alır ve verileri birçok farklı şekilde kullanabilirsiniz. Bu hızlı başlangıcın geri kalanında farklı biçimlerde buna ihtiyacınız olacak.
Aşağıdaki kodu başka bir hücreye girin ve çalıştırın; bu işlem bir Spark tablosu, CSV ve verilerin kopyalarını içeren bir Parquet dosyası oluşturur:
demo_df.createOrReplaceTempView('demo_df') demo_df.write.csv('demo_df', mode='overwrite') demo_df.write.parquet('abfss://<<TheNameOfAStorageAccountFileSystem>>@<<TheNameOfAStorageAccount>>.dfs.core.windows.net/demodata/demo_df', mode='overwrite')Depolama gezginini kullanıyorsanız, yukarıda kullanılan bir dosyayı yazmanın iki farklı yolunun etkisini görebilirsiniz. Hiçbir dosya sistemi belirtilmediğinde, bu örnekte
default>user>trusted-service-user>demo_dfvarsayılan kullanılır. Veriler belirtilen dosya sisteminin konumuna kaydedilir."Her iki 'csv' ve 'parquet' biçiminde, yazma işlemlerinde birçok bölümlenmiş dosyayla bir dizin oluşturulduğuna dikkat edin."


Spark SQL deyimlerini çalıştırma
Yapılandırılmış Sorgu Dili (SQL), verileri sorgulamak ve tanımlamak için en yaygın ve yaygın kullanılan dildir. Bilinen SQL söz dizimini kullanan Spark SQL, yapısal verileri işleyen bir Apache Spark uzantısı olarak çalışır.
Aşağıdaki kodu boş bir hücreye yapıştırın ve kodu çalıştırın. komutu havuzdaki tabloları listeler.
%%sql SHOW TABLESAzure Synapse Apache Spark havuzunuzla bir Not Defteri kullandığınızda, Spark SQL kullanarak sorgu çalıştırmak için kullanabileceğiniz bir ön ayar
sqlContextelde edersiniz.%%sqlnot defterine sorguyu çalıştırmak için ön ayarısqlContextkullanmasını bildirir. Sorgu, varsayılan olarak tüm Azure Synapse Apache Spark havuzlarıyla birlikte gelen bir sistem tablosundan ilk 10 satırı alır.demo_dfkomutundaki verileri görmek için başka bir sorgu çalıştırın.%%sql SELECT * FROM demo_dfKod, biri veri sonuçlarını içeren diğeri ise iş görünümünü gösteren iki çıkış hücresi oluşturur.
Varsayılan olarak sonuçlar görünümü bir ızgara olarak gösterilir. Ancak, kılavuzun altında görünümün kılavuz ve grafik görünümleri arasında geçiş yapmasını sağlayan bir görünüm değiştirici vardır.

Görünüm değiştiricide Grafik'i seçin.
En sağ taraftaki Görünüm seçenekleri simgesini seçin.
Grafik türü alanında "çubuk grafik" öğesini seçin.
X ekseni sütun alanında "state" (durum) öğesini seçin.
Y ekseni sütun alanında "maaş" öğesini seçin.
Toplama alanında "AVG" seçeneğini seçin.
seçin, sonra daUygula'yı seçin.

Aynı SQL çalıştırma deneyimini dil değiştirmeden elde etmek mümkündür. Yukarıdaki SQL hücresini bu PySpark hücresiyle değiştirerek bunu yapabilirsiniz, görüntüleme komutu kullanıldığından çıkış deneyimi aynıdır:
display(spark.sql('SELECT * FROM demo_df'))Daha önce yürütülen hücrelerin her biri Geçmiş Sunucusu ve İzleme'ye gitme seçeneğine sahipti. Bağlantılara tıkladığınızda Kullanıcı Deneyimi'nin farklı bölümlerine ulaşabilirsiniz.
Uyarı
Apache Spark resmi belgelerinden bazıları, Synapse Spark'ta bulunmayan Spark konsolunu kullanmaya dayanır. Bunun yerine not defterini veya IntelliJ deneyimlerini kullanın.
Kaynakları temizleme
Azure Synapse verilerinizi Azure Data Lake Storage'a kaydeder. Spark örneği kullanımda olmadığında güvenli bir şekilde kapanmasına izin vekleyebilirsiniz. Sunucusuz Apache Spark havuzu kullanımda olmasa bile çalıştığı sürece ücretlendirilirsiniz.
Havuz ücretleri depolama ücretlerinden çok daha fazla olduğundan Spark örneklerinin kullanımda olmadığında kapanmasına izin vermek ekonomik bir anlam ifade eder.
Spark örneğinin kapalı olduğundan emin olmak için bağlı oturumları (not defterlerini) sonlandırın. Apache Spark havuzunda belirtilen boşta kalma süresine ulaşıldığında havuz kapatılır. Not defterinin alt kısmındaki durum çubuğundan oturumu sonlandır'ı da seçebilirsiniz.
Sonraki adımlar
Bu hızlı başlangıçta sunucusuz bir Apache Spark havuzu oluşturmayı ve temel bir Spark SQL sorgusu çalıştırmayı öğrendiniz.