Synapse SQL ile dış tabloları kullanma
Dış tablo Hadoop, Azure Depolama blobu veya Azure Data Lake Depolama bulunan verileri gösterir. Azure Depolama'da dosyalardan veri okumak veya dosyalara veri yazmak için dış tabloları kullanabilirsiniz.
Synapse SQL ile dış tabloları kullanarak ayrılmış SQL havuzu veya sunucusuz SQL havuzu kullanarak dış verileri okuyabilirsiniz.
Dış veri kaynağının türüne bağlı olarak, iki tür dış tablo kullanabilirsiniz:
- CSV, Parquet ve ORC gibi çeşitli veri biçimlerindeki verileri okumak ve dışarı aktarmak için kullanabileceğiniz Hadoop dış tabloları . Hadoop dış tabloları ayrılmış SQL havuzlarında kullanılabilir, ancak sunucusuz SQL havuzlarında kullanılamaz.
- CSV ve Parquet gibi çeşitli veri biçimlerinde verileri okumak ve dışarı aktarmak için kullanabileceğiniz yerel dış tablolar . Yerel dış tablolar sunucusuz SQL havuzlarında kullanılabilir ve ayrılmış SQL havuzlarında genel önizleme aşamasındadır. CETAS ve yerel dış tabloları kullanarak veri yazma/dışarı aktarma yalnızca sunucusuz SQL havuzunda kullanılabilir, ancak ayrılmış SQL havuzlarında kullanılamaz.
Hadoop ile yerel dış tablolar arasındaki temel farklar:
| Dış tablo türü | Hadoop | Yerel |
|---|---|---|
| Ayrılmış SQL havuzu | Kullanılabilir | Genel önizlemede yalnızca Parquet tabloları kullanılabilir. |
| Sunucusuz SQL havuzu | Kullanılamaz | Uygun |
| Desteklenen biçimler | Sınırlandırılmış/CSV, Parquet, ORC, Hive RC ve RC | Sunucusuz SQL havuzu: Sınırlandırılmış/CSV, Parquet ve Delta Lake Ayrılmış SQL havuzu: Parquet (önizleme) |
| Klasör bölümü eleme | Hayır | Bölüm eleme yalnızca Apache Spark havuzlarından eşitlenen Parquet veya CSV biçimlerinde oluşturulan bölümlenmiş tablolarda kullanılabilir. Parquet bölümlenmiş klasörlerinde dış tablolar oluşturabilirsiniz, ancak bölümleme sütunlarına erişilemez ve yoksayılır, ancak bölüm eleme uygulanmaz. Delta Lake klasörlerinde dış tablolar oluşturmayın çünkü bunlar desteklenmez. Bölümlenmiş Delta Lake verilerini sorgulamanız gerekiyorsa Delta bölümlenmiş görünümlerini kullanın. |
| Dosya eleme (koşul gönderimi) | Hayır | Sunucusuz SQL havuzunda evet. Dizenin aşağı itilmesi için, aşağı itme özelliğini etkinleştirmek için sütunlarda VARCHAR harmanlama kullanmanız Latin1_General_100_BIN2_UTF8 gerekir. Harmanlamalar hakkında daha fazla bilgi için Synapse SQL için desteklenen Harmanlama türlerine bakın. |
| Konum için özel biçim | Hayır | Evet, Parquet veya CSV biçimleri gibi /year=*/month=*/day=* joker karakterler kullanın. Özel klasör yolları Delta Lake'te kullanılamaz. Sunucusuz SQL havuzunda, başvuruda bulunılan klasörün altındaki herhangi bir alt klasördeki Parquet veya CSV dosyalarına başvurmak için özyinelemeli joker karakterler /logs/** de kullanabilirsiniz. |
| Özyinelemeli klasör taraması | Evet | Evet. Sunucusuz SQL havuzlarında konum yolunun sonunda belirtilmelidir /** . Ayrılmış havuzda klasörler her zaman özyinelemeli olarak taranır. |
| Depolama kimlik doğrulaması | Depolama Erişim Anahtarı(SAK), Microsoft Entra geçişi, Yönetilen kimlik, özel uygulama Microsoft Entra kimliği | Paylaşılan Erişim İmzası (SAS), Microsoft Entra geçişi, Yönetilen kimlik, Özel uygulama Microsoft Entra kimliği. |
| Sütun eşleme | Sıra - Dış tablo tanımındaki sütunlar, temel alınan Parquet dosyalarındaki sütunlara konuma göre eşlenir. | Sunucusuz havuz: ada göre. Dış tablo tanımındaki sütunlar, temel alınan Parquet dosyalarındaki sütunlara sütun adı eşleşmesine göre eşlenir. Ayrılmış havuz: sıralı eşleştirme. Dış tablo tanımındaki sütunlar, temel alınan Parquet dosyalarındaki sütunlara konuma göre eşlenir. |
| CETAS (dışarı aktarma/dönüştürme) | Evet | Hedef olarak yerel tablolara sahip CETAS yalnızca sunucusuz SQL havuzunda çalışır. Yerel tabloları kullanarak verileri dışarı aktarmak için ayrılmış SQL havuzlarını kullanamazsınız. |
Dekont
Yerel dış tablolar, genel olarak kullanılabildikleri havuzlarda önerilen çözümlerdir. Dış verilere erişmeniz gerekiyorsa, sunucusuz havuzlarda her zaman yerel tabloları kullanın. Ayrılmış havuzlarda, Ga'ya girdikten sonra Parquet dosyalarını okumak için yerel tablolara geçmeniz gerekir. Hadoop tablolarını yalnızca yerel dış tablolarda desteklenmeyen bazı türlere (örneğin , ORC, RC) erişmeniz gerekiyorsa veya yerel sürüm kullanılamıyorsa kullanın.
Ayrılmış SQL havuzu ve sunucusuz SQL havuzundaki dış tablolar
Dış tabloları kullanarak:
- Transact-SQL deyimleriyle Azure Blob Depolama ve Azure Data Lake 2. Nesil'i sorgula.
- CETAS kullanarak sorgu sonuçlarını Azure Blob Depolama veya Azure Data Lake Depolama'da depolayın.
- Azure Blob Depolama ve Azure Data Lake Depolama verileri içeri aktarıp ayrılmış bir SQL havuzunda depolayın (yalnızca ayrılmış havuzdaki Hadoop tabloları).
Dekont
CREATE TABLE AS SELECT deyimiyle birlikte kullanıldığında, dış tablodan seçim yapıldığında veriler ayrılmış SQL havuzu içindeki bir tabloya aktarılır.
Ayrılmış havuzlardaki Hadoop dış tablolarının performansı performans hedeflerinize uygun değilse COPY deyimini kullanarak dış verileri Datawarehouse tablolarına yüklemeyi göz önünde bulundurun.
Yükleme öğreticisi için bkz. Azure Blob Depolama'dan veri yüklemek için PolyBase kullanma.
Aşağıdaki adımları izleyerek Synapse SQL havuzlarında dış tablolar oluşturabilirsiniz:
- Dış Azure depolama alanına başvurmak ve depolama alanına erişmek için kullanılacak kimlik bilgilerini belirtmek için EXTERNAL DATA SOURCE OLUŞTURUN.
- CSV veya Parquet dosyalarının biçimini açıklamak için EXTERNAL FILE FORMAT OLUŞTURUN.
- Aynı dosya biçimine sahip veri kaynağına yerleştirilen dosyaların üzerinde EXTERNAL TABLE OLUŞTURUN.
Klasör bölümü eleme
Synapse havuzlarındaki yerel dış tablolar, sorgular için uygun olmayan klasörlere yerleştirilen dosyaları yoksayabiliyor. Dosyalarınız bir klasör hiyerarşisinde (örneğin - /year=2020/month=03/day=16) depolanıyorsa ve değerleri year, monthve day sütunları olarak gösteriliyorsa, gibi year=2020 filtreler içeren sorgular dosyaları yalnızca klasöre year=2020 yerleştirilen alt klasörlerden okur. Diğer klasörlere (year=2021 veya year=2022) yerleştirilen dosya ve klasörler bu sorguda yoksayılır. Bu eleme, bölüm eleme olarak bilinir.
Klasör bölümü eleme Synapse Spark havuzlarından eşitlenen yerel dış tablolarda kullanılabilir. Bölümlenmiş veri kümeniz varsa ve oluşturduğunuz dış tablolarla bölüm elemeden yararlanmak istiyorsanız, dış tablolar yerine bölümlenmiş görünümleri kullanın.
Dosya eleme
Parquet ve Delta gibi bazı veri biçimleri her sütun için dosya istatistikleri içerir (örneğin, her sütun için en küçük/en yüksek değerler). Verileri filtreleyen sorgular, gerekli sütun değerlerinin mevcut olmadığı dosyaları okumaz. Sorgu, gerekli verileri içermeyen dosyaları bulmak için önce sorgu koşulunda kullanılan sütunların en küçük/en yüksek değerlerini keşfeder. Bu dosyalar yoksayılır ve sorgu planından kaldırılır.
Bu teknik, filtre koşulu gönderimi olarak da bilinir ve sorgularınızın performansını artırabilir. Filtre gönderimi Parquet ve Delta biçimlerindeki sunucusuz SQL havuzlarında kullanılabilir. Dize türleri için filtre gönderimini kullanmak için harmanlama ile Latin1_General_100_BIN2_UTF8 VARCHAR türünü kullanın. Harmanlamalar hakkında daha fazla bilgi için Synapse SQL için desteklenen Harmanlama türlerine bakın.
Güvenlik
Kullanıcının verileri okuyabilmesi için dış tablo üzerinde izni olmalıdır SELECT .
Dış tablolar, aşağıdaki kuralları kullanarak veri kaynağında tanımlanan veritabanı kapsamlı kimlik bilgilerini kullanarak temel alınan Azure depolamaya erişer:
- Kimlik bilgisi olmayan veri kaynağı, dış tabloların Azure depolamada genel kullanıma açık dosyalara erişmesini sağlar.
- Veri kaynağı, dış tabloların SAS belirteci veya çalışma alanı Yönetilen Kimliği kullanarak yalnızca Azure depolamadaki dosyalara erişmesini sağlayan bir kimlik bilgilerine sahip olabilir - Örnekler için Depolama dosyaları depolama erişim denetimi geliştirme makalesine bakın.
CREATE EXTERNAL DATA SOURCE örneği
Aşağıdaki örnek, Azure Data Lake 2. Nesil için ayrılmış SQL havuzunda New York veri kümesini işaret eden bir Hadoop dış veri kaynağı oluşturur:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2018-03-28&ss=bf&srt=sco&sp=rl&st=2019-10-14T12%3A10%3A25Z&se=2061-12-31T12%3A10%3A00Z&sig=KlSU2ullCscyTS0An0nozEpo4tO5JAgGBvw%2FJX2lguw%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
Aşağıdaki örnek, Azure Data Lake 2. Nesil için genel kullanıma açık New York veri kümesine işaret eden bir dış veri kaynağı oluşturur:
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
CREATE EXTERNAL FILE FORMAT örneği
Aşağıdaki örnek, census dosyaları için bir dış dosya biçimi oluşturur:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Örnek CREATE EXTERNAL TABLE
Aşağıdaki örnek bir dış tablo oluşturur. İlk satırı döndürür:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Azure Data Lake'te bir dosyadan dış tablolar oluşturma ve sorgulama
Synapse Studio'nun Data Lake keşif özelliklerini kullanarak artık synapse SQL havuzunu kullanarak dosyaya basit bir sağ tıklamayla dış tablo oluşturabilir ve sorgulayabilirsiniz. ADLS 2. Nesil depolama hesabından dış tablo oluşturmak için tek tıklama hareketi yalnızca Parquet dosyaları için desteklenir.
Ön koşullar
Dosyaları sorgulamanızı sağlayan ADLS 2. Nesil hesabına veya Erişim Denetim Listelerine (ACL) erişim
Storage Blob Data Contributorrolüne sahip çalışma alanına erişiminiz olmalıdır.Synapse SQL havuzunda (ayrılmış veya sunucusuz) dış tablo oluşturmak ve dış tabloları sorgulamak için en azından izinleriniz olmalıdır.
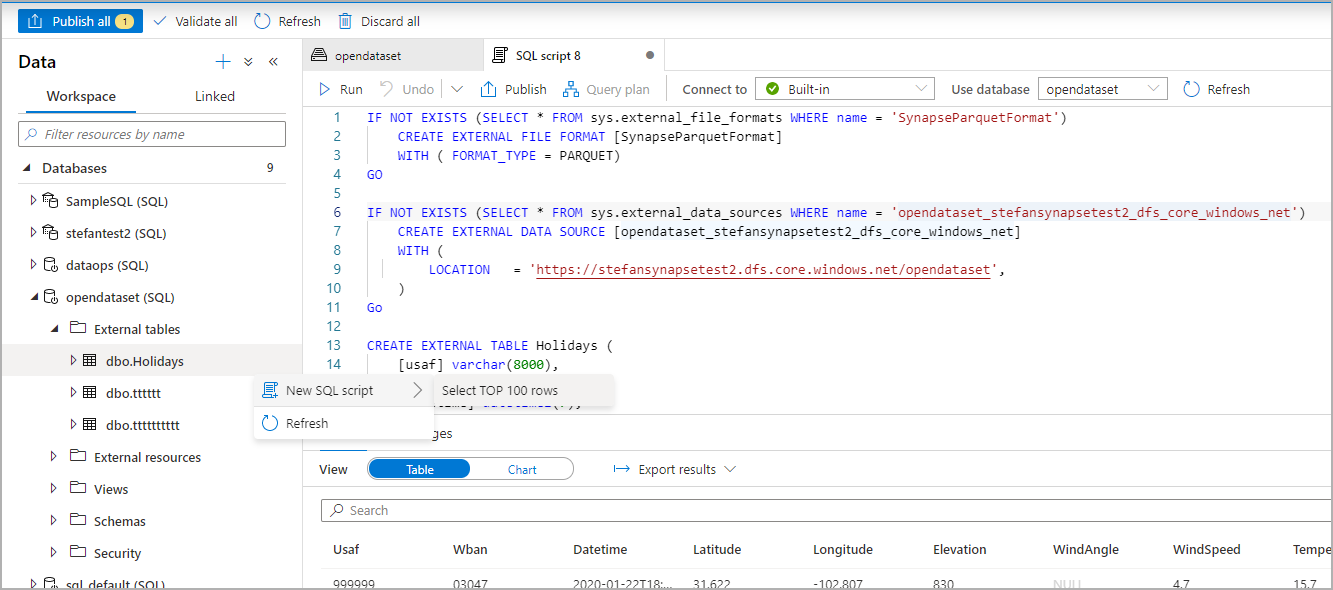
Veri panelinde dış tabloyu oluşturmak istediğiniz dosyayı seçin:
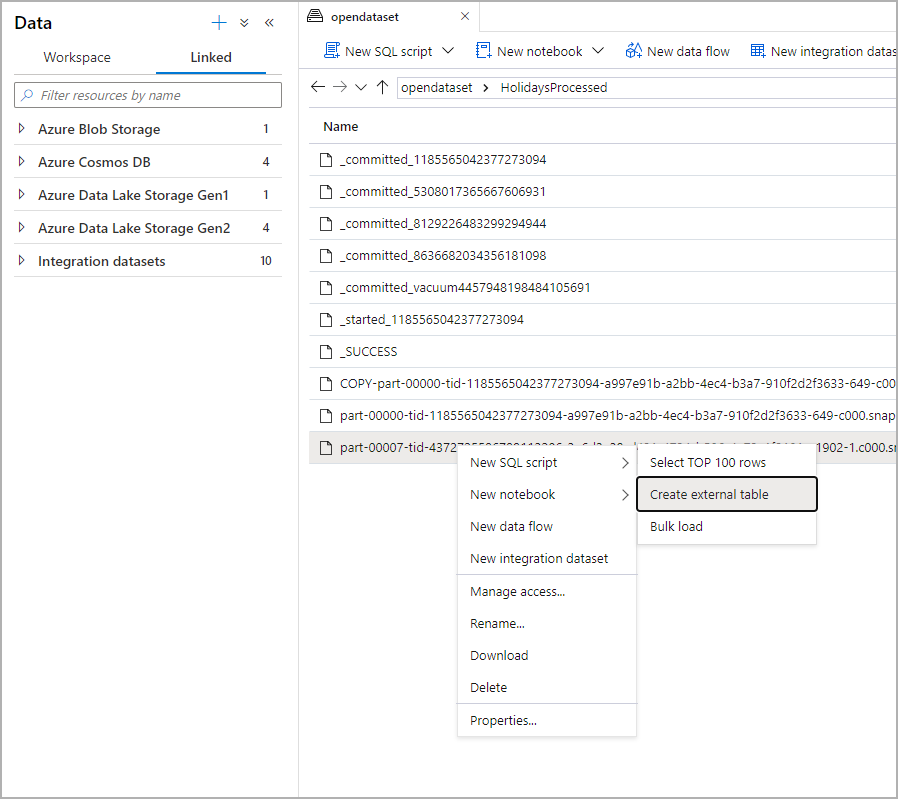
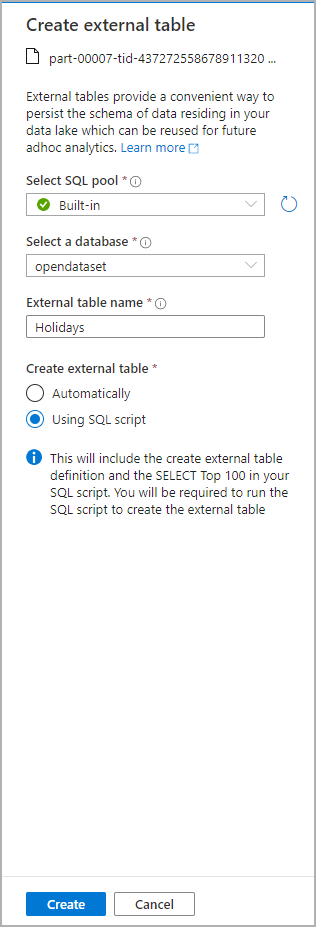
Bir iletişim kutusu penceresi açılır. Ayrılmış SQL havuzu veya sunucusuz SQL havuzu'nu seçin, tabloya bir ad verin ve betiği aç'ı seçin:
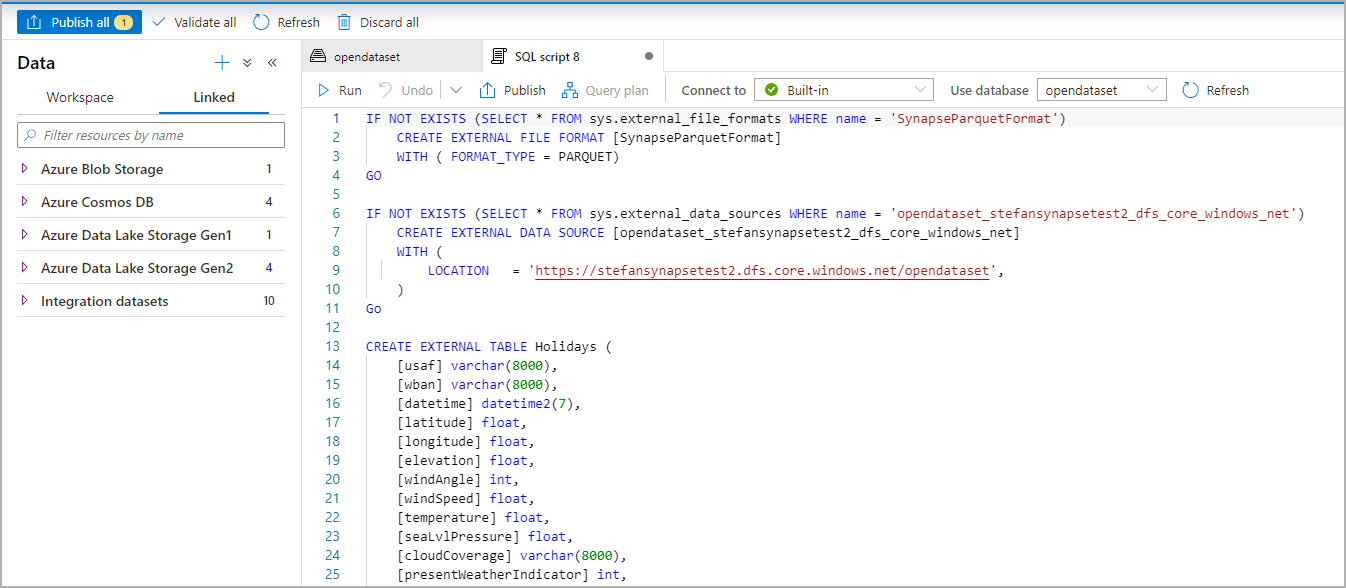
SQL Betiği, şema dosyasından çıkarılarak otomatik olarak oluşturulur:
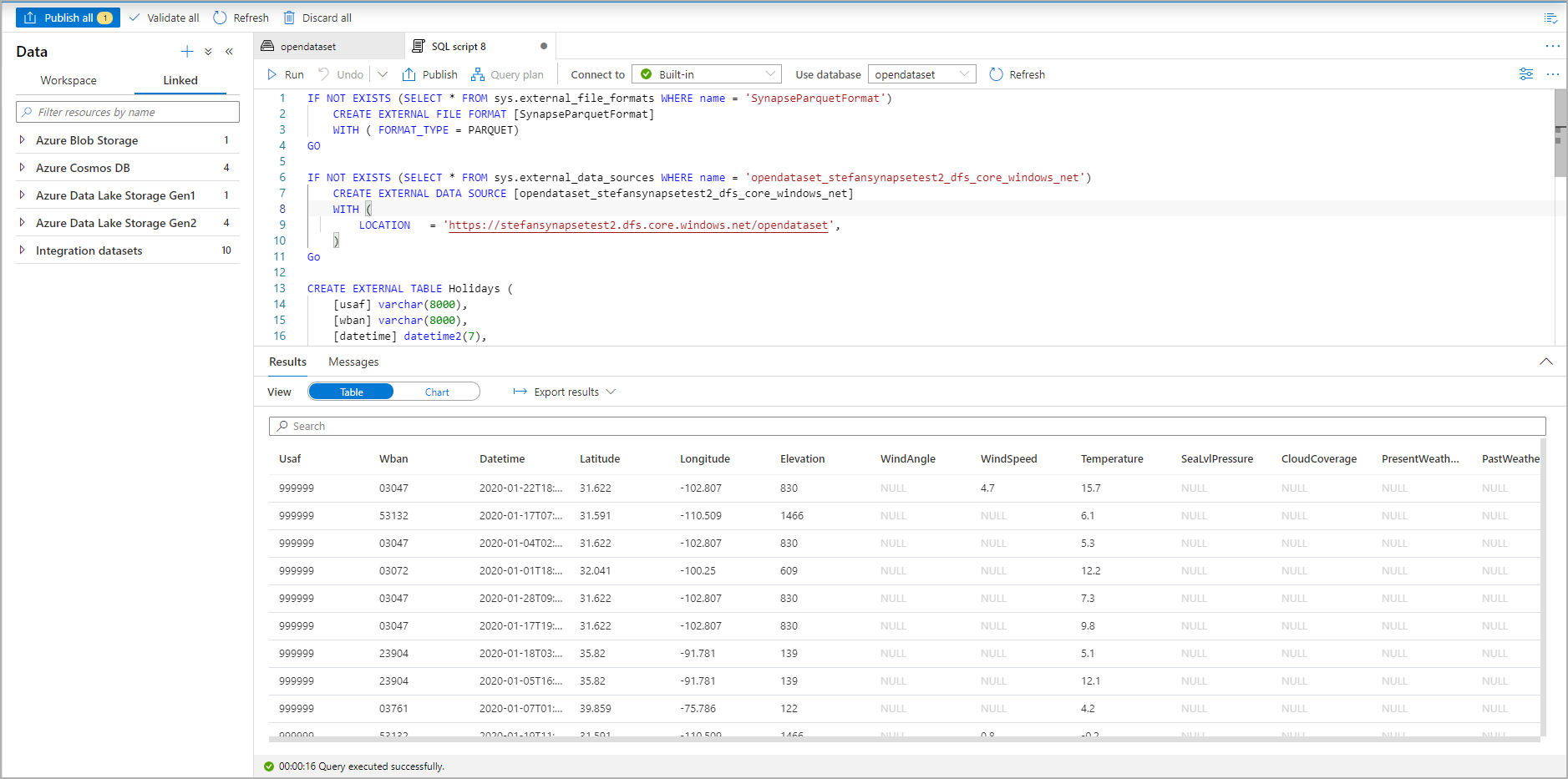
Betiği çalıştırın. Betik otomatik olarak İlk 100 Seç *.:
Dış tablo artık oluşturulur ve bu dış tablonun içeriğini daha sonra keşfetmek için kullanıcı bunu doğrudan Veri bölmesinden sorgulayabilir:
Sonraki adımlar
Azure Depolama'da sorgu sonuçlarını dış tabloya kaydetme hakkında CETAS makalesine bakın. İsterseniz Azure Synapse dış tabloları için Apache Spark'ı sorgulamaya da başlayabilirsiniz.